一张思维图教你们GetBean流程源码解析《记得收藏哦!》
Posted 苏州程序大白
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了一张思维图教你们GetBean流程源码解析《记得收藏哦!》相关的知识,希望对你有一定的参考价值。
一张思维图教你们GetBean流程源码解析《记得收藏哦!》
🏳️🌈目录
在文章讲解之前感谢C站的完美的工程学博主。让我可以采用他的文章给大家讲解😊开讲啦!!!!

gitte地址:https://gitee.com/duchenxi/total-war
需要了解的可以用微信关注完美的工程学
工欲善其事,必先利其器!
getBean方法是spring ioc的核心,阅读getBean方法的源码也是理解spring容器工作原理所必须要做的事情!
我们先来看一下getBean方法,getBean的具体实现逻辑在AbstractBeanFactory类里面的doGetBean方法中。
首先简略地介绍一下整体的执行流程:
-
1.根据传入beanName获取bean的别名
-
2.尝试从缓存中获取之前被实例化过了的单例bean
-
3.根据上面获取到的实例进一步获取bean(因为获取到的可能是一个工厂bean)
-
4.如果上面的步骤之后没有获取到bean那么就需要创建bean了
-
5.先根据缓存判断一下当前的bean是否正在被创建,如果是的话表示依赖循环了
-
6.尝试获取当前工厂的父工厂并从当前工厂的bean定义缓存中获取bean定义委托父工厂去生成
-
7.如果当前要获取的bean只是为了进行类型检查就标记bean已经被创建
-
8.同当前bean的父类合并bean的定义,并检查获取到的bean定义是不是抽象的
-
9.通过上面获取到的bean定义找到当前bean的依赖bean并递归调用getBean方法获取依赖bean
-
10.判断bean的scope是单例的还是原型的或者是其他的创建bean
-
11.根据要求返回的bean类型通过convertService来对bean进行转换

上面是整体流程的简述,接下来我们细细地研究一下每个步骤的执行过程。
🍇1、beanName转换
在doGetBean方法逻辑开始的时候就对传入的beanName进行了处理,调用了transformedBeanName方法,这个方法的主要处理逻辑是去掉当前beanName的工厂bean前缀,也就是"&",去掉了工厂名前缀之后就去aliasMap也就是别名和bean规范名map中去获取当前bean的规范名。关于工厂bean前缀比如用户想获取一个叫teaFactory的FactoryBean的实例,那么在getBean方法的参数中就需要传入&teaFactory,之后容器就会实例化这个工厂bean给调用者,而不是返回这个工厂bean所产生的bean对象。
🍈2、 三级缓存中获取单例
这个方法算是整个流程中比较重要的方法了,先尝试从三级缓存中获取bean的单例对象,所谓三级缓存就是三个等级的map。一级缓存是singletonObjects这个存放的就是初始化可以直接使用的bean对象,二级缓存earlySingletonObjects是早期对象是还在初始化过程中对象已经创建了但是还需要进一步处理的bean,三级缓存是singletonFactories这里存放的是获取当前bean的工厂。
具体的流程是先尝试从一级缓存中获取bean对象如果获取到了就直接返回,如果没有获取到bean对象的话就判断当前的bean对象是否正在被创建,这个过程是通过查询singletonsCurrentlyInCreation这个缓存map中是否有当前要获取的bean,如果有的话表示当前的bean正在被创建也就是说在二级或者三级缓存中可能会获取到bean。之后如果当前bean允许早期依赖的话就会进一步去二三级缓存中去获取bean,在接下来的过程中会先对一级缓存加锁,防止别的线程对一级缓存进行了修改。之后会去二级缓存中尝试获取早期对象,如果没有获取到的话就通过三级缓存存放的ObjectFactory去获取bean对象,如果通过ObjectFactory获取到了bean的话就将这个bean放到二级缓存中,并清除三级缓存中的这个ObjectFactory对象。

🍉3、根据bean的实例获取bean对象
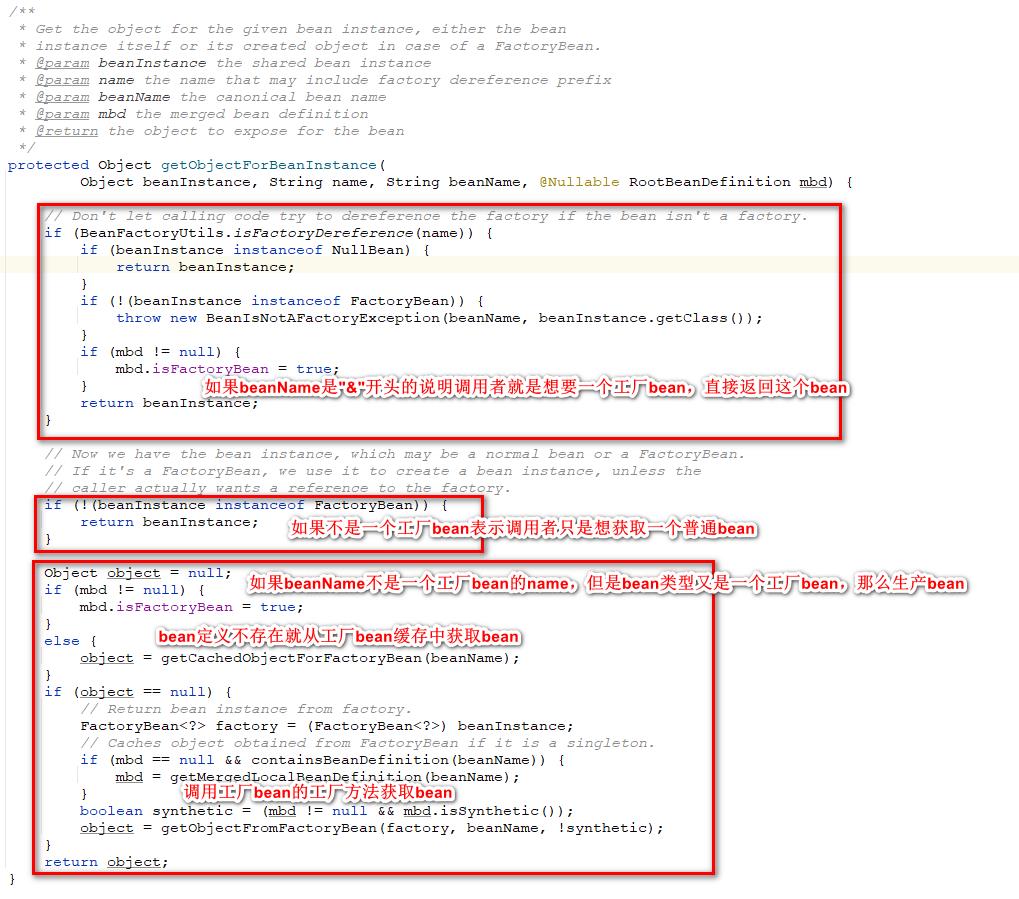
将bean在缓存中获取到了之后还要通过调用getObjectForBeanInstance方法来对获取的bean进一步进行处理。这个方法的干的事情很简单,从方法上面的注释就可以知道如果这个bean就是一个普通的bean那么很简单就只是返回bean本身,如果当前bean是一个工厂bean如果调用者就是想要一个工厂bean那么就直接把这个工厂bean返回给调用者,如果不是就通过这个工厂bean生产一个bean给调用者。
具体的处理逻辑是先判断传入的beanName是不是有工厂bean的前缀也就是"&"。如果是的话就表示调用者就是想获取工厂bean,之后在判断这个bean的类型是不是FactoryBean类型如果不是的话就抛出异常,是的话就返回这个bean。
如果根据beanName判断用户不是想获取工厂bean的话就判断一下bean的类型是不是不为工厂bean,如果是的话就返回这个普通的bean。
如果当前的beanName是一个普通的bean但是bean的类型却是一个工厂bean的类型,那么就通过这个工厂bean去生产bean再返回给调用者。
下面我们来看一下spring是怎么通过工厂bean来获取bean的。我们点开getObjectFromFactoryBean方法,这个方法的处理逻辑也很清晰,处理的方式分为两种,一种是单例一种不是单例,对于单例的bean的创建首先要锁住单例池防止别的线程也在创建这个bean而产生了多个bean的实例。之后会在factoryBeanObjectCache这个缓存中检查当前的这个工厂bean有没有在之前被调用过而产生过bean,这里也是为了防止单例的多实例。如果没有的话就会调用doGetObjectFromFactoryBean方法通过我们传入的工厂bean来获取一个bean的实例,这个方法我们接下来会说到。
在使用工厂bean创建完了bean对象之后会再去检查一遍doGetObjectFromFactoryBean缓存看看有没有其他线程在我们当前线程创建bean的时候也通过工厂创建了bean,如果创建了的话就直接使用那个线程创建的bean,这也是防止单例的多实例。完成上面的步骤之后我们的bean对象还不算是完全符合我们的预期的,这时候我们需要判断一下当前的bean是否需要被后置处理,如果需要的话会调用bean的后置处理器来对bean进行处理,而需要注意的是在对bean调用后置处理器之前以及之后会分别调用两个方法,将当前bean正在被创建的状态放到缓存中去,防止别的线程也同时对这个bean进行了后置处理。

点开beforeSingletonCreation方法我们可以看到这个保证只有一个线程调用bean的后置处理器的处理方式很简单,就是先判断一下inCreationCheckExclusions这个缓存中有没有当前的beanName同时判断并将beanName添加到singletonsCurrentlyInCreation缓存中,之后在bean后置处理器调用完成之后会在singletonsCurrentlyInCreation缓存中移除beanName,这样就保证了当前的bean只会被一个线程去处理而且只会被处理一次。

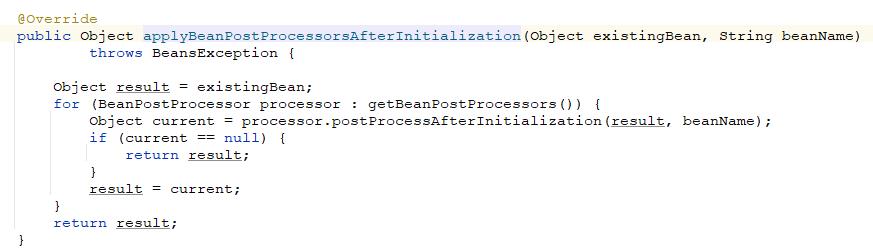
而调用后置处理器的逻辑就很简单了,只是从beanPostProcessors缓存中获取我们之前容器中注册到容器的bean后置处理器再依次执行就完成了,具体的后置处理器的实现逻辑就看具体的后置处理器的逻辑了,我们也可以通过实现BeanPostProcessor接口,实现postProcessBeforeInitialization和postProcessAfterInitialization两个方法来定制化地实现自己的对bean的特殊处理逻辑,关于bean的后置处理器我之后会详细的讲解。
我们回到getObjectFromFactoryBean方法,在完成了对bean的后置处理之后bean就算被创建完成了,这时候我们需要将这个bean放到单例缓存中,老规矩为了防止单例bean的多实例这里会先判断一下单例缓存中是否有别的线程将bean先我们一步放到单例缓存中了,如果没有的话就将当前的bean放到缓存中。
以上是针对于单例bean的处理方式,而对于非单例的bean的处理方式就简单粗暴多了,逻辑更加简单直接调用我们doGetObjectFromFactoryBean方法去获取一个bean对象,之后再调用后置处理器。
以上就是通过spring通过工厂bean来获取bean对象的整体流程了,在这里我们介绍一下工厂bean,工厂bean也就是FactoryBean,通过FactoryBean类提供的工厂方法getObject我们可以获取订制化的bean对象。有兴趣的同学可以点开FactoryBean这个类看一下里面就定义了三个方法getObjectType:获取生成的bean的类型;getObject获取bean对象;isSingleton:是否是单例,默认返回的是true。至于getObject的逻辑要看具体的子类的实现逻辑了。
关于doGetObjectFromFactoryBean方法处理逻辑也很简单就是调用一个factoryBean的getObject方法去获取一个bean,如果返回的是一个null的话就创建一个NullBean类型的bean返回,逻辑很简单这里就不展开说了。
🍊4、判断原型bean的依赖循环
以上的流程就是关于单例bean已经或者正在被创建或者是单例的工厂被已经或正被创建对其的处理工作,如果当前的bean第一次被创建呢?或者当前的bean不是一个单例的bean的呢?所以接下来的代码是针对于当前bean的第一次创建。接下来的这个步骤就是对原型bean的依赖循环做判断。
通过这段代码上的注释我们可以知道这部分的代码是判断原型模式的bean是否正在被创建的,如果正在被创建那么我们很可能就陷入原型模式的依赖循环了,这里会直接抛出异常。针对于原型模式的任何类型的循环依赖spring都会直接抛出异常。因为原型模式的循环依赖由于bean不能保证单例那么假如是这样的依赖循环A->B->C->A,如果A是原型bean的话那么两个A的对象根本就不是同一个对象就谈不上依赖了。而针对与单例模式的bean,spring是可以处理setter注入的bean的但是处理不了构造器注入的bean,这个会在后面的部分详细说明。

关于这里是怎么判断当前的原型bean正在被创建的,其实处理逻辑很简单,点开isPrototypeCurrentlyInCreation方法我们可以看到这里是去判断prototypesCurrentlyInCreation获取到的存放beanName的set中有没有我们当前的beanName,这里的prototypesCurrentlyInCreation其实是一个存放Set类型的ThreadLocal。所以很明显这里的判断只对当前的线程有效,也就是所如果发生了存在beanName的情况必然是当前线程之前在生成这个bean的时候又依赖到当前bean了,也就是说发生依赖循环了。

🍋5、委托上一层次的工厂生成bean
我们继续doGetBean方法的主流程继续往下看,接下来的流程就是bean第一次被初始化需要执行的创建流程。这一部分的代码是委托父工厂来获取当前的bean,为什么要委托父工厂来生产我们要获取的bean的?因为 容器的各个层次是相互隔离的 ,当前的beanFactory中不一定能够找到我们要生产的bean的定义,因为有些bean的定义可能会被注册到上一层次的容器中去。
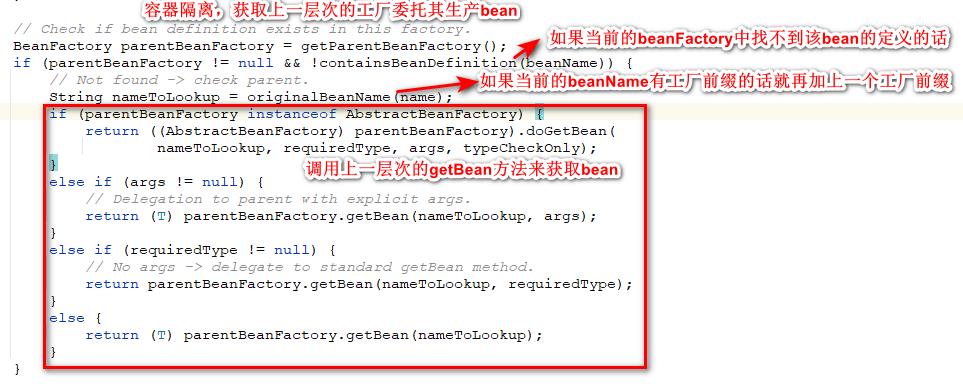
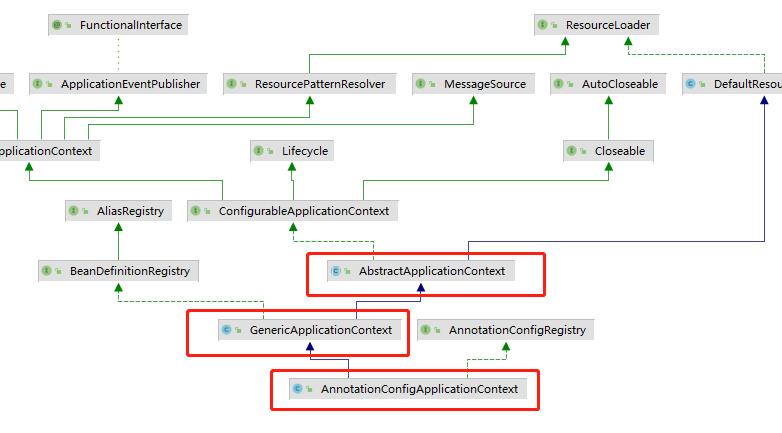
我们可以看一下相关容器的类图,通过这张类图我们可以很清楚地看到各个容器之间的测试结构,比如我们使用的AnnotationConfigApplicationContext上面就有GenericApplicationContext和AbstractApplicationContext。而不同的容器中会注册不同的beanDefinition,当我们通过AnnotationConfigApplicationContext去获取注册在AbstractApplicationContext容器中的bean的时候,就会执行上面的逻辑,因为在当前的容器里面找不到我们需要的beanDefinition所以就会获取上一层次的beanFactory来帮助我们获取bean对象,当然当前层次容器获取到的bean对象也只会存放到当前层次的容器当中。而调用上层次的容器的方法其实就是getBean方法。当然这 是在我们当前容器中找不到指定bean的定义的时候才会委托上层次的工厂来获取 。
🍌6、类型检查
接下来是标记这个bean是否只是用作类型检查而不是真正地想使用这个bean。

这里传入的参数是typeCheckOnly,这个参数是doGetBean方法传入的,我们看一下源码上对这个参数的注释:标记这个实例是为了类型检查而获取还是为了实际的使用而获取。

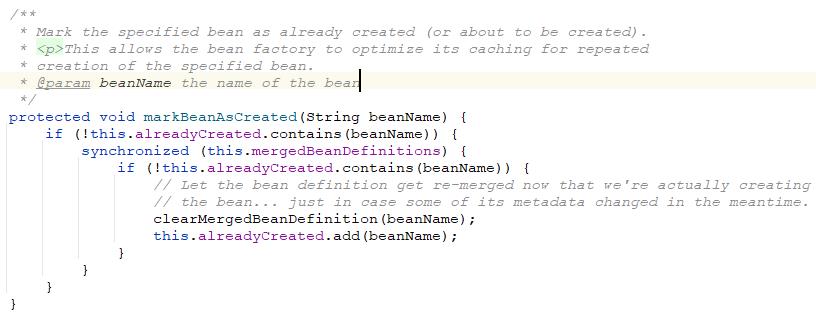
如果是用作类型检查的话,我们点开markBeanAsCreated方法查看一下里面的逻辑:如果当前的bean没有被创建或者正在被创建的话就锁住合并的bean定义缓存池,再判断一下当前的bean是否还没有被创建,然后标记当前的bean的合并定义需要被re-merged也就是重新获取,之后将这个beanName放到bean定义合并缓存池中标记当前bean正在被创建。这里之所以让之后的bean实例化需要重新获取bean的合并定义是为了防止类的元数据信息被修改了(比如反射),从而导致当前获取的bean合并定义过期了。
🍍7、合并父子类的beanDefinition
如果流程执行到这里来了就表示 当前要获取的bean的定义在本层次的容器里面,同时当前的bean也没有工厂bean来帮助我们来创建,这时候下面的流程就是根据beanDefinition来创建一个bean了 。在doGetBean方法里面对应的代码片段如下,先合并当前要获取bean的父子类的beanDefinition,然后再检查一下获取到的合并的定义。比如我们当前的bean继承了一个抽象类或者是实现了一个接口,那么在这里就需要将父类的属性或者方法或者依赖和我们当前的bean定义合并,通过合并来生成一个新的beanDefinition,通过当前的beanName将这个定义缓存到map中。
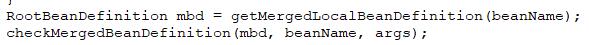
我们点开getMergedLocalBeanDefinition方法,这里面的逻辑就是先从合并定义缓存中尝试获取当前bean的合并定义,如果获取到了的话就判断一下当前的这个定义是否需要被刷新(前面说到的类型检查),如果不需要的话就直接返回。如果没获取到或者bean定义需要刷新的话就调用getMergedBeanDefinition方法去获取合并的定义。
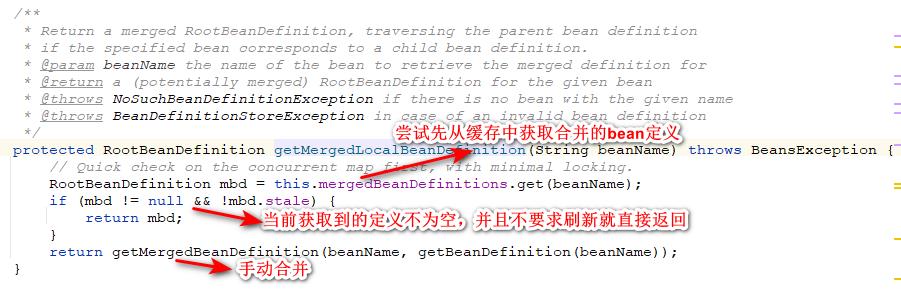
我们点看getMergedBeanDefinition方法详细地看一下代码的处理流程。首先会将mergedBeanDefinitions这个缓存锁住,然后先尝试从这个缓存中获取bean的合并定义,如果获取到了就直接返回,如果没有获取到就要自己去获取了。
如果缓存中没有获取到或者是要求被刷新那么就尝试从容器中获取当前bean的父bean定义。如果没有获取到的话就调用transformedBeanName来获取bean的别名之后再用这个别名跟beanName做比较如果不一样的话根据这个bean的别名递归调用当前的方法去获取父类beanDefinition。如果一样的话可能当前bean的父类bean的定义不在当前的容器里面,这时就尝试获取上一层次的工厂,通过上一层次的工厂的getMergedBeanDefinition方法来获取当前bean的父类beanDefinition。
-
获取到父类的bean定义之后通过深拷贝复制一个对象,之后通过overrideFrom这个方法来对当前类和父类的属性进行复制。
-
之后如果合并的bean定义没有设置scope的话就设置一个默认的单例作用域。
-
之后再判断当前的类是否是原型地并且包含一个内部类,如果是的话就设置其内部类的scope为原型。
-
之后将合并的bean定义放到mergedBeanDefinitions这个缓存中。
-
最后会根据之前未合并父bean定义设置合并过的bean定义。
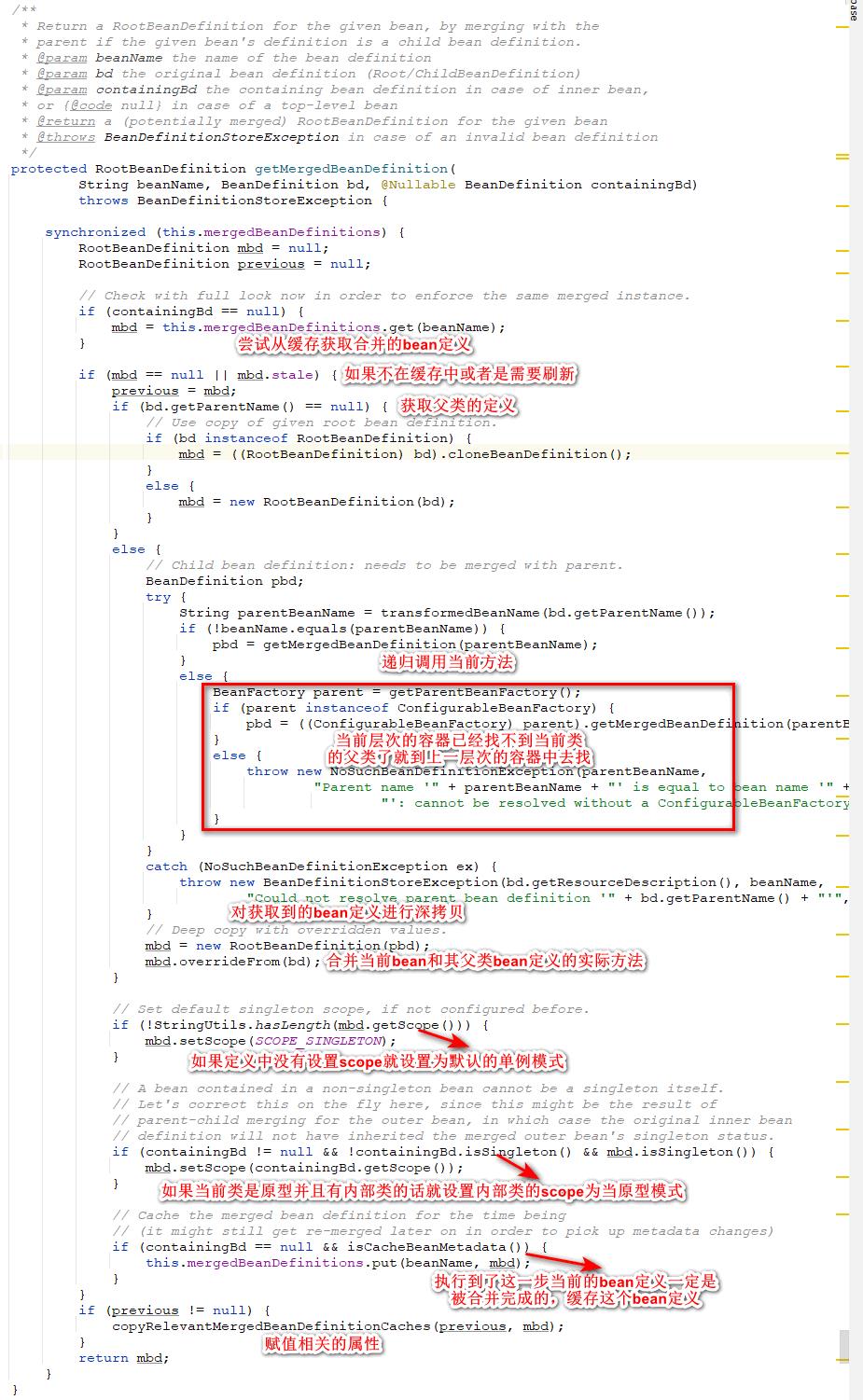
关于overrideFrom这个合并父子类bean定义的实际方法里面的逻辑十分简单这里我就不说了,只是非常详细地把一个BeanDefinition中所有能复制的属性都复制了一遍,比较重要的例如:类的元数据、是否懒加载、属性、方法、依赖等等。
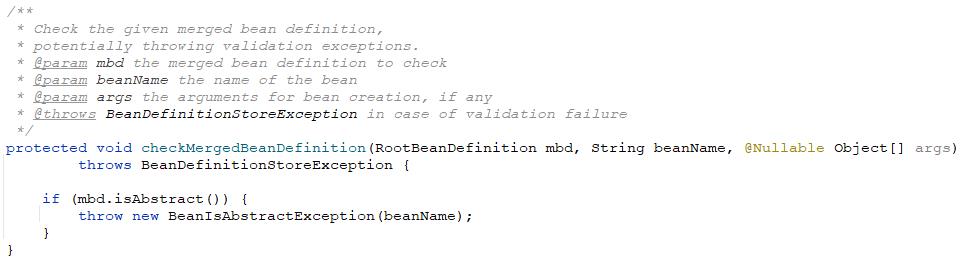
🥭8、检查bean定义
让我们继续回到doGetBean方法的主流程继续往下看,获取到了合并的bean定义之后需要对这个bean定义进行检查,检查的内容就是判断这个类是不是抽象的,如果是的话就抛出异常。
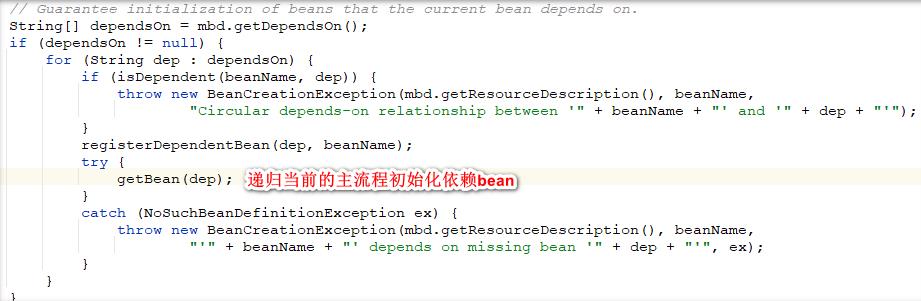
🍎9、判断依赖循环并初始化依赖的bean
继续我们的主流程,在获取并检查完成合并的bean定义之后,接下来的步骤就是初始化bean了。接下来的这个流程很重要,在我们初始化我们需要的bean之前,我们会从bean定义中获取当前bean的依赖的bean的name数组,之后依次初始化所有的依赖bean。这里有一个地方特别重要就是图中的isDependent方法,这个方法控制了bean的依赖循环,如果当前bean的依赖存在循环依赖的话那么就抛出BeanCreationException异常。
在调用getBean方法去创建依赖的bean之前,需要先将这个beanName注册到缓存中,提供给之后的依赖bean的依赖循环检查。

这里isDependent方法很重要,这里我着重地讲一下,首先我们看一下方法的入参,beanName是当前要创建的bean的name,dependentBeanName是当前bean正准备初始化的beanName。这里再整个逻辑开始之间先锁住当前层次的dependentBeanMap。
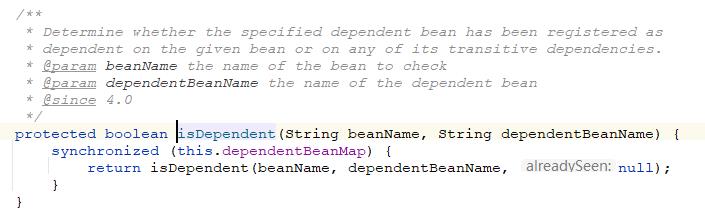
这个dependentBeanMap是存放当前beanName和这个bean所有的依赖的bean的name的Set的数据结构。这里就存放了当前bean依赖了哪些bean,比如A->B,A->C那么在这个缓存中关于beanA存放的信息就是A->Set(B, C)。

我们点开isDependent的实际处理方法,这个方法是spring判断单例bean是否依赖循环的比较核心的方法,同时这个方法第一次读源码的时候也不容易理解。
首先这个方法是会被自己递归调用的这个要清楚,这个方法的入参有三个,一个是当前的beanName,一个是当前的bean的其中一个依赖的beanName,还有一个记录当前的整个递归流程中已经出现过的beanName的Set。
代码流程中首先会去判断alreadySeen中有没有出现当前的beanName如果出现的话就表示依赖循环。
首先判断一下当前bean的依赖Set里面是否包含我们传入的依赖beanName,如果包含的话就依赖循环了,因为我们回顾一下主流程,当前的依赖bean在实例化之前会被注册到dependentBeanMap中去同时符合beanName->Set(dependentBeanName)的形式,所以如果在这个方法的这个判断里面的当前bean的被注册的依赖bean的Set里面存在了我们传入的依赖的beanName的话表示创建的bean依赖了两个相同的bean,这个应该不算依赖循环了应该说是代码错误了。
之后遍历这个依赖beanName的Set递归调用isDependent方法。

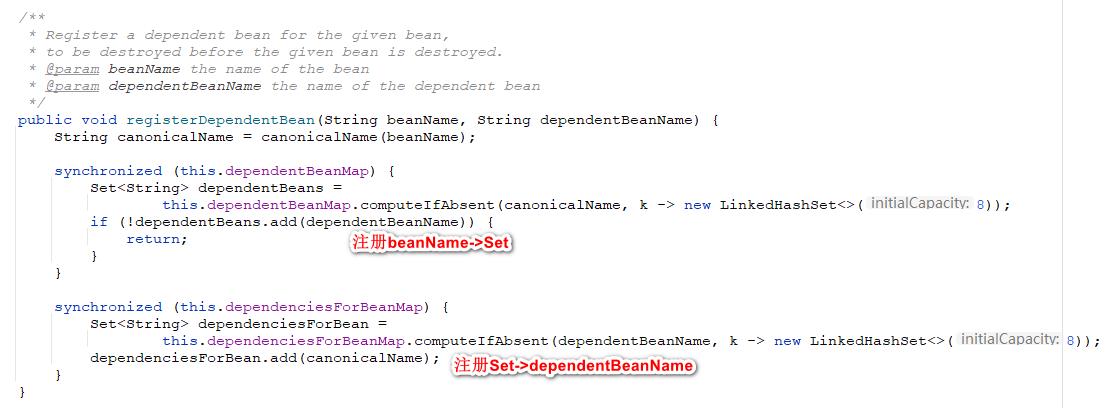
🍏10、 注册将要被创建的依赖bean
在完成了依赖循环的检测之后在依赖对象被创建之前需要将这个依赖bean注册到缓存中,也就是我们上面依赖循环检测用到的缓存。执行的逻辑也十分简单,首先是根据beanName映射一个这个bean依赖的beanName的set到map里面也就是dependentBeanMap,之后再将依赖的beanName放到set里面。
11、递归getBean主流程初始化依赖bean
在判断依赖的bean被允许创建并且被注册到缓存中之后,就是初始化依赖bean的时候了。这里的初始化方式是调用getBean方法来初始化这个bean。
🍐12、创建bean
完成了这么多前置的步骤我们终于来到了创建当前bean的流程了。这里调用的是createBean方法来创建bean的实例,和上面获取缓存中的单例一样,这里也是在获取到实例之后调用了getObjectForBeanInstance方法来对实例进行进一步的处理。

让我们一起来看一下创建bean的方法createBean,通过这个方法上面的注释我们可以知道这个方法是整个AbstractAutowireCapableBeanFactory类的核心方法,而这个方法主要干什么呢?注释上面也写了: 创建bean实例、填充属性到bean实例、调用后置处理器等等 。我认为这个方法也是整个spring框架的核心和基础,因为对bean的处理是整个spring框架最基础的依赖,没有了IOC的话spring提供的别的功能比如AOP等等都是空谈。
我们先来看一下这个方法的整体执行流程。
-
首先是获取bean的运行时类,然后将这个运行时类设置到beanDefinition里面。
-
之后会去校验bean的重写的方法,并且判断这些重写方法有没有重载,如果没有的话就设置这个方法不需要进行参数检查。
-
在bean在被实例化之前调用后置处理器,允许后置处理器这个时候返回一个代理对象,这里很重要。
-
最后是调用doCreateBean方法,这也是实际创建bean的方法,之前的都是准备工作。

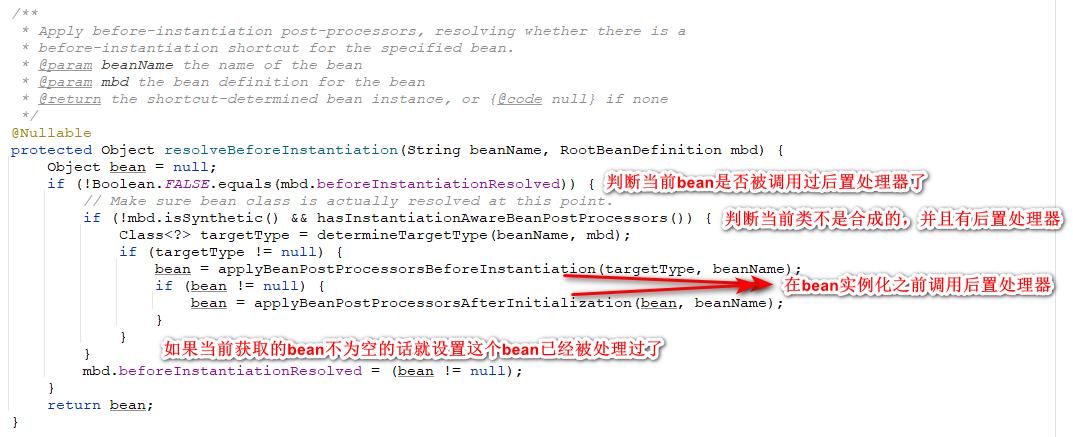
🍑12.1、创建bean实例之前调用后置处理器
这里我们详细看一下resolveBeforeInstantiation方法,这里首先通过beforeInstantiationResolved这样的标记状态来判断当前的bean有没有执行过当前的后置处理流程,如果处理过了的话就不处理了。之后判断当前这个类是不是合成的以及是否存在bean后置处理器,bean是合成的大致的意思就是当前的运行时类和实际的class文件加载出来的结果不一样,这时候spring不对其在创建之前做后置处理。之后就是调用后置处理器来进行处理了,这里的后置处理器的作用是返回一个我们期望的当前bean的代理对象,之后的创建流程都是针对于这个代理对象来完成,比如AOP的实现就是通过在这里返回bean的代理对象实现的AOP功能。
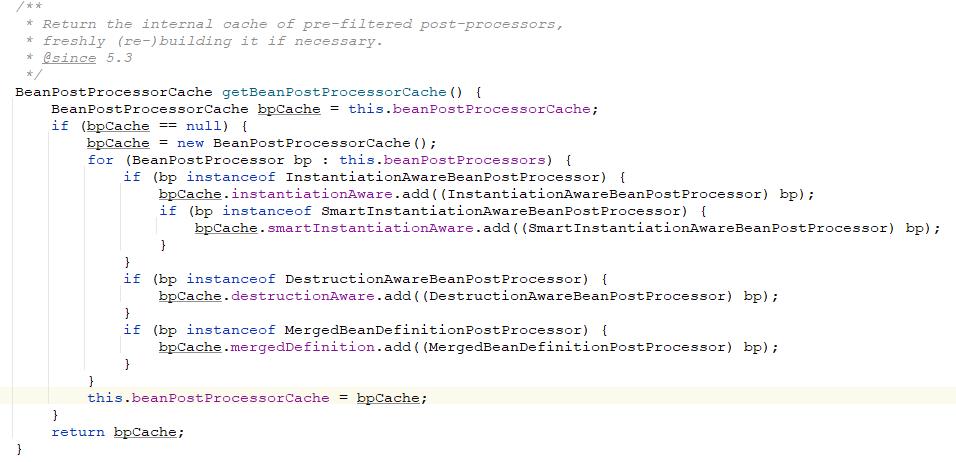
我们来看一下获取bean后置处理器的方法。在这里通过工厂内部的一个缓存的内部类BeanPostProcessorCache来存放所有的注册到当前容器中的后置处理器。可以看到这个内部类中有四种类型的bean后置处理器, 而获取这四种类型的bean后置处理器的方式是通过从之前容器启动的流程中保存当前容器所有的bean后置处理器的缓存beanPostProcessor中获取所有的注册了的beanProcessor,之后根据对这些后置处理器类型做判断就可以将这些后置处理器分成四类,然后分别放到各自所属的缓存中。而我们在创建bean实例之前我们使用的是InstantiationAwareBeanPostProcessor类型的bean后置处理器 。
调用后置处理器的逻辑十分简单,只是从缓存中获取beanPostProcessor然后循环执行即可,同时只要有一个后置处理器的执行结果不为空那么就直接返回即返回了一个代理对象或者是其他的对象 (注意我们在容器启动的时候就已经对bean后置处理器进行过排序了) ,在这里就不过多赘述了。
由这里可以知道spring针对于bean后置处理器的套路总结一下就是: 容器启动的时候将所有的bean后置处理器排序并保存到缓存中,在使用的时候从这个缓存中拿出所有bean后置处理器根据类型进行分类并放到指定的缓存中,最后根据实际的功能需求进行指定种类的后置处理器的调用。
休息一会加个微信

🍒13、 doCreateBean创建bean实例
需要注意的是如果经过上面的后置处理器处理之后已经返回了一个bean实例,那么就执行不到这里了。
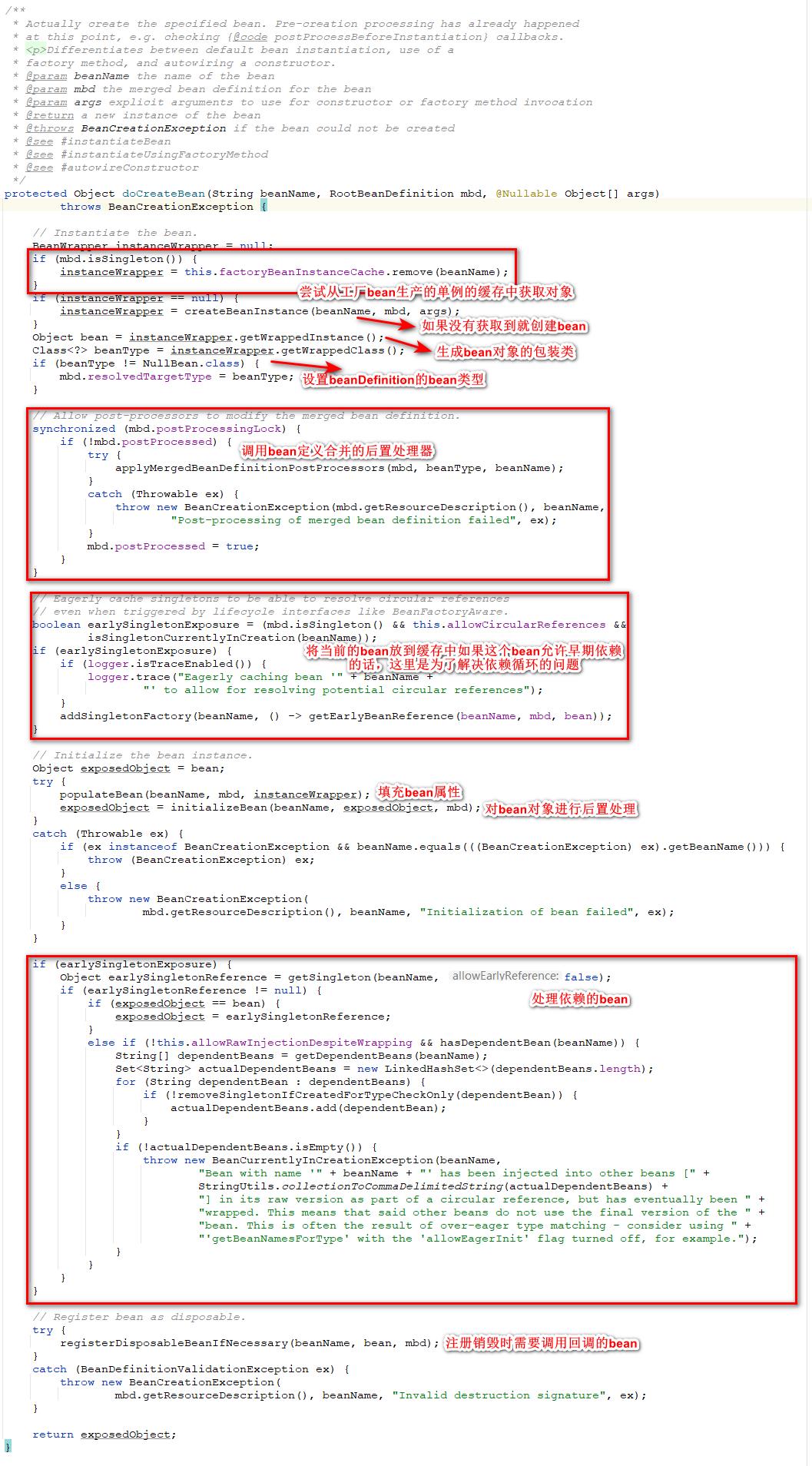
doCreateBean这个方法十分重要,主要的功能有:获取bean实例、填充bean属性、调用bean后置处理器、调用bean定义合并后置处理器、暴露早期对象、处理依赖的bean、注册销毁时需要调用回调的bean。这个方法可以返回一个真正可以被使用的bean(当然后面还有类型转换)。
-
下面我们看一下这个方法的主要的执行流程。首先会从factoryBeanInstanceCache这个我们之前经常提到的工厂bean生产的对象的缓存中尝试获取我们需要的bean对象,因为在这个流程中可能有别的线程调用了之前的工厂bean生产bean的流程。如果我们在这个缓存中获取不到对象的话,我们就需要老老实实的自己去创建一个bean了,这里调用的是createBeanInstance方法。
-
通过上面的两个步骤我们能够得到一个bean对象,但是这个bean对象还不是可以被使用的,里面的属性还没有被填充以及一些后置处理还没有被执行。在获取到bean对象之后会去设置当前的bean定义中的bean的类型为当前bean的类型,之后会获取bean对象的包装类也就是Wrapper类。
-
在上面的步骤完成之后会去调用bean合并定义修改的后置处理器,也就是mergedBeanDefinitionPostProcessors,这个的调用流程就和我们前面说到的bean实例化后置处理器类似,也是从缓存中获取之前被注册的后置处理器再循环执行即可,这里就不再赘述。
-
接下来的步骤就比较重要了spring会去判断这个bean是否允许被早期依赖,什么是早期依赖呢?spring在处理依赖循环的时候,都是通过对***依赖对象的引用进行依赖***,也就是说在这个对象被实例化(对象只是被创建但是还没有被填充属性等等)之后这个依赖bean就可以被依赖。而这里还将bean交给了AOP来处理如果当前bean需要被代理的话,这里会将AOP的代理对象返回作为这个bean的早期依赖对象。
-
之后会对bean进行属性填充,并且调用bean的后置处理器等等回调来对bean进行完善。
-
最后就是处理当前bean依赖的bean,以及如果这个bean需要在销毁的时候调用回调的话就将这个bean注册到缓存中。
🙈13.1、createBeanInstance创建bean的早期实例
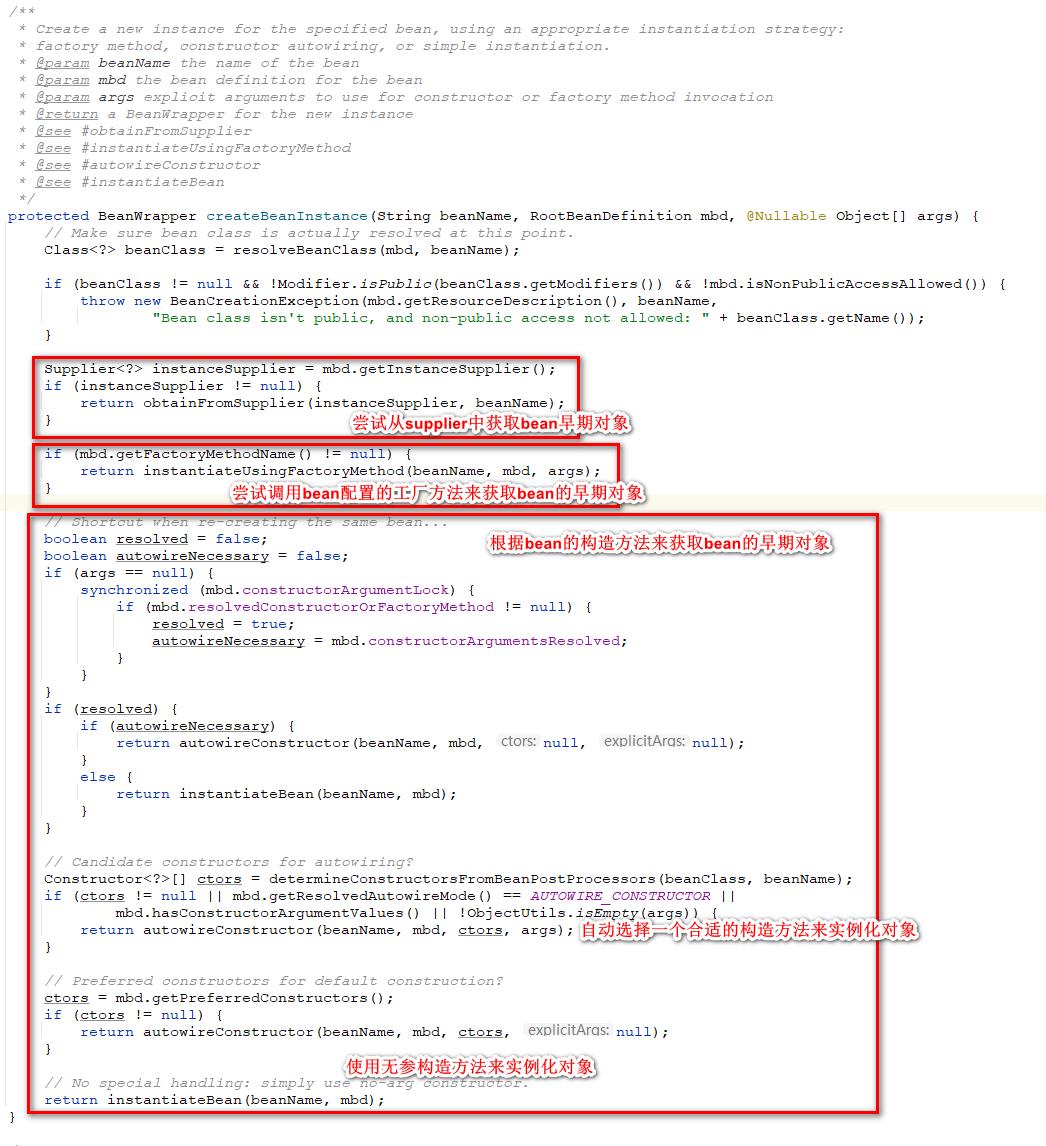
这里是spring真正创建bean实例的方法,在这个方法里面的主要流程是:
- 尝试通过supplier来获取bean对象,supplier类似于一个工厂,Supplier接口只有一个get方法,子类通过实现这个接口来获取特定的bean对象。在这里会先去尝试获取beanDefinition里面配置supplier。
- 尝试通过工厂方法来获取bean对象。
- 通过构造方法来获取bean对象。
🙉13.2、暴露早期对象
在完成了bean的实例化以及后置处理器的处理之后,需要将这个早期对象暴露到缓存中,从而可以解决依赖循环的问题。
- 首先会去判断当前的bean是否允许早期依赖,判断的条件是是否是单例、是否允许环形依赖、是否正在被创建。
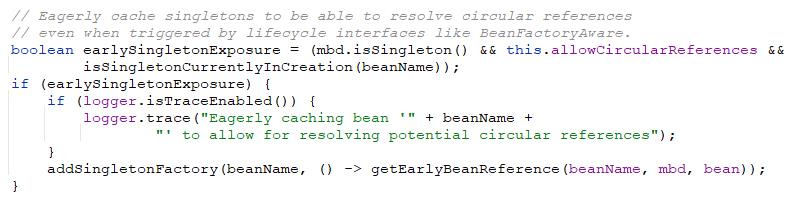
我们点开getEarlyBeanReference方法,这个方法可以获取当前bean需要被暴露的早期对象的引用,为什么不直接暴露bean的引用呢?因为有些场景,我们在早期对象生成之后可能最后返回的并不是这个早期对象而是代理对象,比如AOP就可以在这个地方调用其InstantiationAwareBeanPostProcessors类型的bean初始化后置处理器,返回一个bean的包装类,而之后spring处理依赖的时候就会依赖于这个代理的包装类。

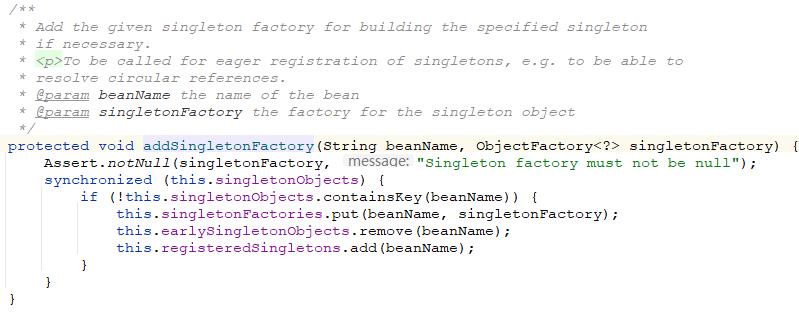
在获得了早期bean的引用之后会把这个bean暴露到缓存中,在下面的代码中可以看到,如果单例池中不存在这个bean对象的话,就把这个对象放到三级缓存(singletonFactories)中以及放到被注册的单例缓存(registeredSingletons)中,然后删除二级缓存(earlySingletonObjects)中的对象。
🙊13.3、填充bean属性
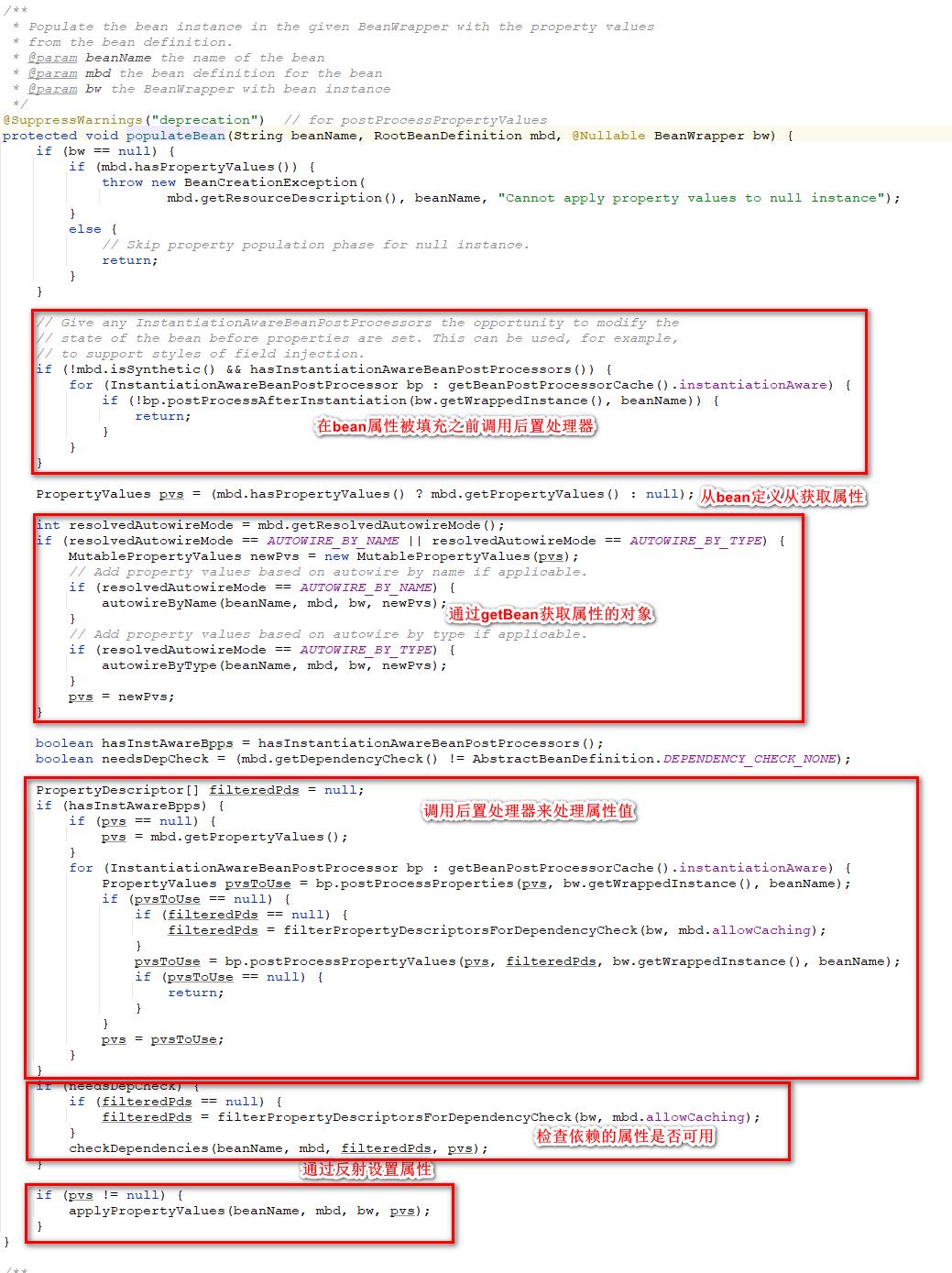
在完成了bean的实例化之后,当前bean中的一些注入是没有被处理的,所以在这个步骤中对bean的属性进行了注入。
- 首先会调用InstantiationAwareBeanPostProcessors类型的后置处理器,这个处理器执行的目的是在bean的属性被设置之前修改bean属性注入的方式。
- 之后通过判断依赖的注入方式是byName还是byType来对依赖进行处理,主要是调用getBean方法生成依赖的bean并且将这个beanName注册到当前bean的依赖缓存中。
- 再次调用InstantiationAwareBeanPostProcessor类型的后置处理器修改要注入的属性的值。
- 进行属性的可用性检查。
- 使用反射注入属性。
🐵13.4、初始化bean
这里的初始化bean是指在bean已经被实例化以及属性已经被填充之后,通过调用工厂的回调或者是初始化方法以及后置处理器来对bean进行进一步的处理。
- 调用invokeAwareMethod方法来对bean的包装对象进行进一步的属性设置。
- 在调用初始化方法之前调用缓存中的bean后置处理器来对bean进行处理。
- 调用bean定义中配置的初始化方法。
- 在初始化方法调用完成之后调用bean后置处理器对bean进行处理。

🐒13.5检查依赖bean
这里会先判断一下当前的bean是不是代理bean,判断的方式就是根据当前的bean对象和单例池中的bean对象进行引用的比较,如果不一样的话就需要进一步去检查判断当前bean的依赖bean是否都是用作类型检查的,如果是的话就抛出异常。
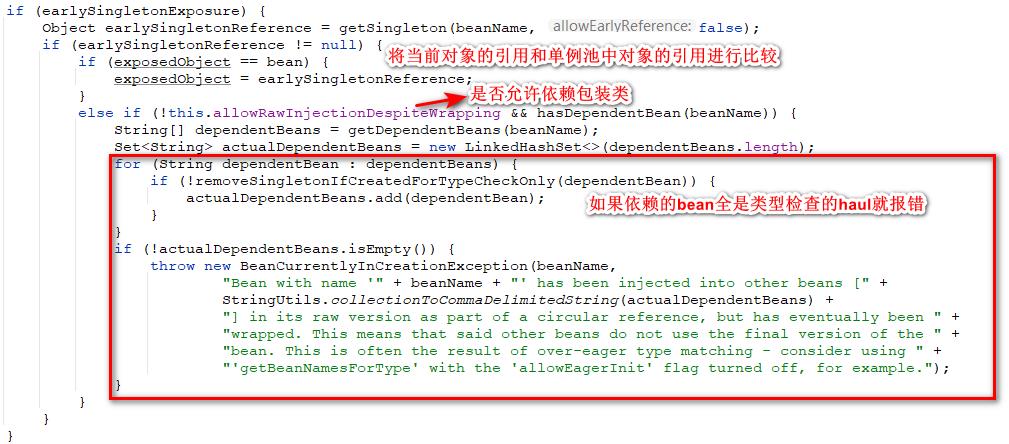
🦍13.6、注册销毁时需要调用回调的bean
这个步骤会判断当前bean时候配置了DestroyMethod或者是DestructionAwareBeanPostProcessor或者是destructionAware,如果是的话表示在这个bean在销毁的时候需要调用这些方法。在这里的处理方式是如果需要调用这些方法那么就将bean对象注册到disposableBeans缓存中。
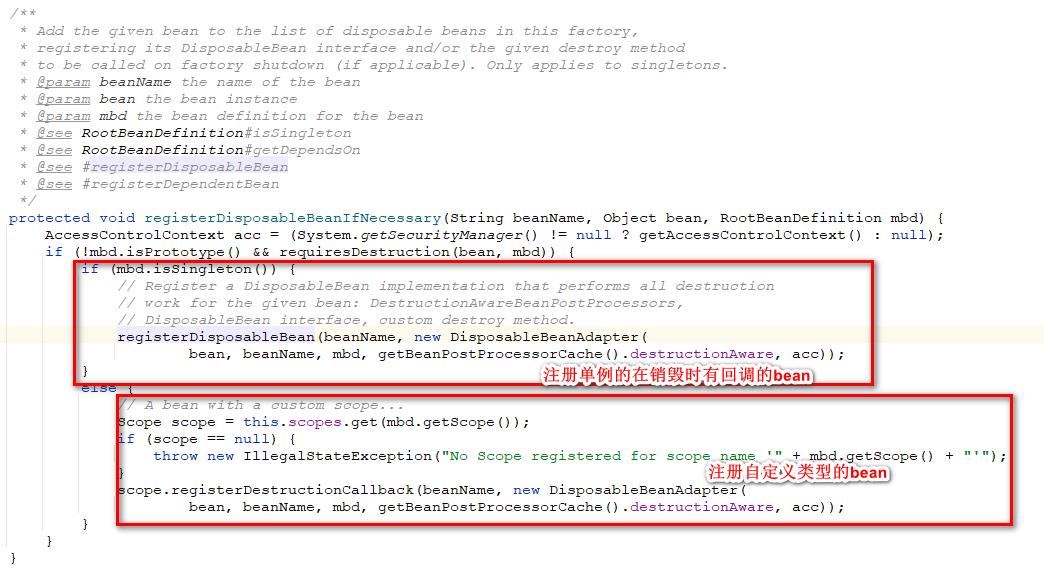
🍓14、 类型转换
在获得了完成的bean对象之后需要检查bean的实际被使用的类型,因为我们的创建过程中最终获取的是一个Object类型的对象。这里的处理方式根据bean的运行时类获取bean类型然后获取spring配置的TypeConverter对bean对象的类型进行转换。
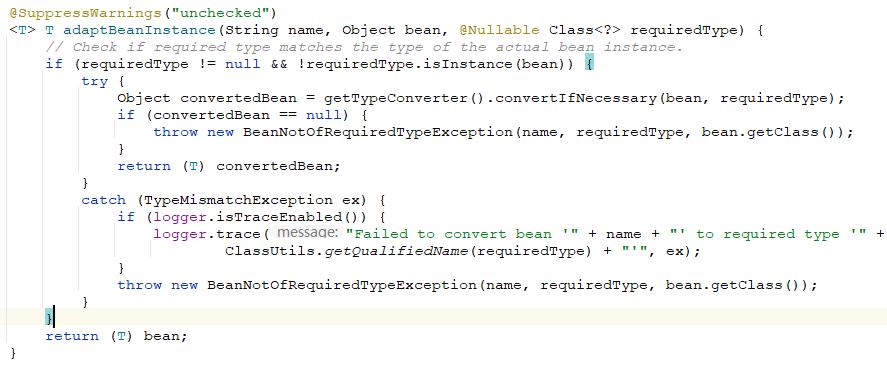
n在销毁的时候需要调用这些方法。在这里的处理方式是如果需要调用这些方法那么就将bean对象注册到disposableBeans缓存中。
🥝15、类型转换
在获得了完成的bean对象之后需要检查bean的实际被使用的类型,因为我们的创建过程中最终获取的是一个Object类型的对象。这里的处理方式根据bean的运行时类获取bean类型然后获取spring配置的TypeConverter对bean对象的类型进行转换。

关注苏州程序大白,持续更新技术分享。谢谢大家支持

以上是关于一张思维图教你们GetBean流程源码解析《记得收藏哦!》的主要内容,如果未能解决你的问题,请参考以下文章