[linux] Linux进程控制超详细解析
Posted 哦哦呵呵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[linux] Linux进程控制超详细解析相关的知识,希望对你有一定的参考价值。
在上篇文章中,我们了解了进程中的相关概念,在这篇文章中,就要对进程的控制做一详解
目录
1. 进程创建
1.1 fork()函数
关于fork函数的详解已经在这篇文章中做了详细解释,可以点击此链接查看第4部分 —>>> 进程概念。
1.2 关于写时拷贝
当父进程创建出子进程,父子进程中间的虚拟地址空间都指向了同一块物理地址,当父子进程没有修改相应的内容,父子进程也就一直指向同一块空间,如果有一方修改了内容,则修改方会建立一块地址,修改放会重新指向该地址。
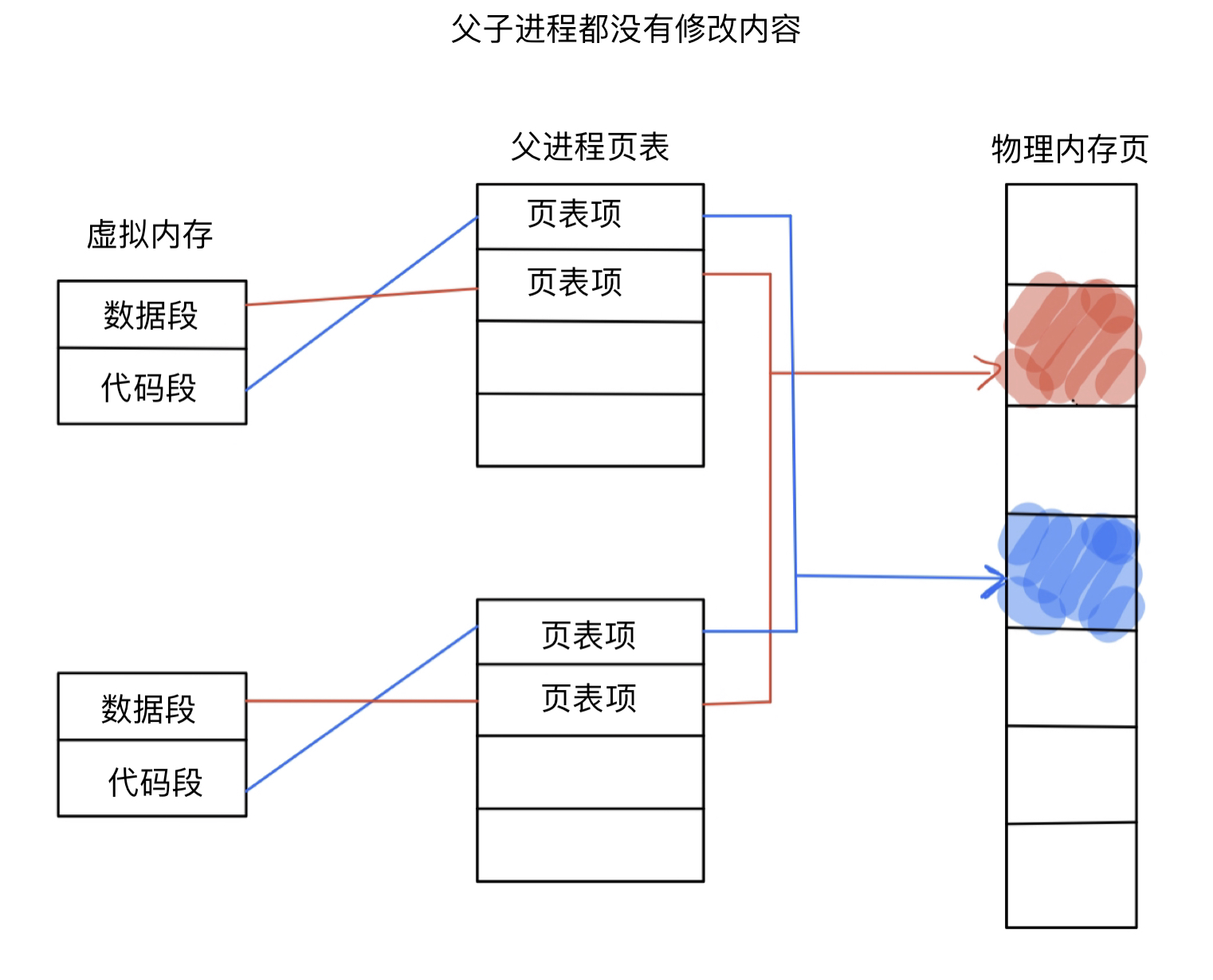
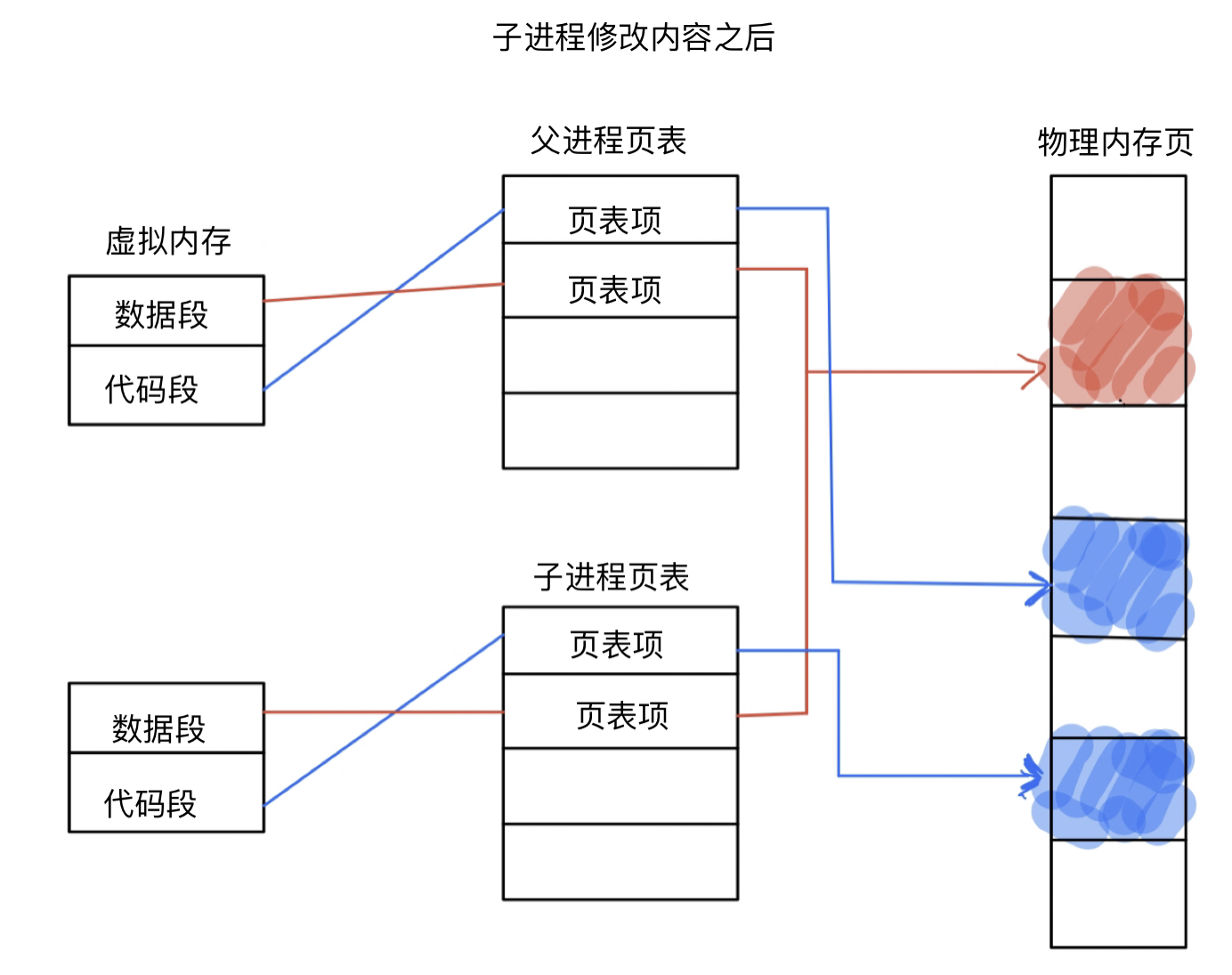
结论
父子进程代码共享,数据独有,当任意一方试图写入时,便以写时拷贝的方式拷贝一份副本。
2. 进程终止
2.1 进程退出的场景
- 代码运行完毕,结果正确
- 代码运行完毕,结果不正确
- 代码异常终止
2.2 常见的退出方法
2.2.1 main函数中return
此种方法,退出的场景是,程序正常运行完毕,并且程序没有错误的出现。
2.2.2 使用exit或_exit函数退出
1. 使用_exit函数退出
函数原型
/**
* 参数:
* status:定义了进程的终止状态,父进程通过wait来获取该值
* 作用:
* 在哪里调用该函数,就在哪里退出
*/
void _exit(int status)
注意:该函数为系统调用,不会刷新缓冲区。
2. 使用exit函数退出
函数原型
/**
* 参数:
* status:定义了进程的终止状态,父进程通过wait来获取该值
* 作用:
* 在哪里调用该函数,就在哪里退出
*/
void exit(int status)
原理
exit函数是库函数,在内部封装了_exit函数,并且该函数在退出进程时,要比_exit()多做两件事。
多做的两件事情
- 执行用户自定义的清理函数
- 刷新缓冲区:该缓冲区是c运行库维护的一块内存,将所有缓存数据进行写入。
缓冲区验证
// exitflush.c
int main()
{
printf("hello");
exit(0);
return 0;
}
// exitflush.c
int main()
{
printf("hello");
_exit(0);
return 0;
}
输出结果
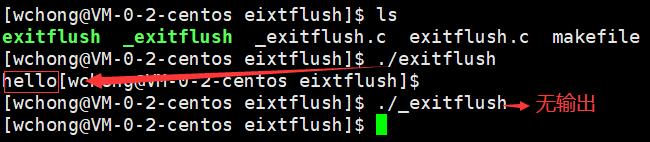
2.2.3 exit和_exit的区别
- exit会冲刷缓冲区,_exit函数不会冲刷缓冲区
- 回调函数
exit函数在结束时会调用用户自定义的清理函数,该函数时atexit()函数。
atexit()函数
原型
/**
* 参数:
* 函数指针类型,接收一个函数的地址,函数返回值为void,参数也为void
* 作用:
* 1.atexit函数是注册了一个函数mycallback,注册并不是调用
* 2.在main函数结束之后,才会调用刚才注册的mycallback函数
*/
int atexit(void (*fun)(void))
执行顺序验证
#include <stdio.h>
#include <stdlib.h>
#include <unistd.h>
void mycallback(void)
{
printf("i am mycallback\\n");
}
int main()
{
atexit(mycallback);
printf("hello bite\\n");
sleep(1);
return 0;
}
有图片可看出,先注册后,程序结束时才会调用

2.3 刷新缓冲区的方法
- main函数的return返回之后会刷新缓冲区
- fflush()函数 强制刷新
- printf(“xxx\\n”); '\\n’会刷新缓冲区
- exit() 函数
3. 进程等待
3.1 什么是进程等待
- 如果子进程退出,父进程不做处理,那么会造成僵尸进程,从而导致内存泄露
- 进程如果变成了僵尸进程,则就刀枪不入,没有办法去杀死该僵尸进程
- 以上操作,我们不知子进程如何运行的,我们不知道子进程运行结果如何,是正常退出还是异常退出。
综合上述原因,要避免上述情况的出现,所以要是父进程通过等待的方式,等待子进程运行完毕,回收子进程资源,获取子进程的退出信息,避免僵尸进程的出现。
3.2 进程等待的方法
3.3.1 wait()函数
原理
调用wait函数时,如果子进程没有退出,则wait函数不会返回,会一直等待子进程运行,直到子进程运行完毕,才会退出函数,防止僵尸进程的产生,而不是等待子进程变成僵尸进程后被shell接管释放掉。
函数原型
/**
* 参数:
* 输出型参数,将wait函数内部计算的结果通过status返回给调用者
* 参数使用:
* 在此函数中,只使用到了该参数的后两个字节。
* 高一个字节:退出码
* 低一个字节:
* 高一位:coredump标志位,产生coerdump文件
* 低七位:退出信号
* 返回值:
* 成功返回被等待的pid,失败返回-1
*/
pid_t wait(int* status);
参数status
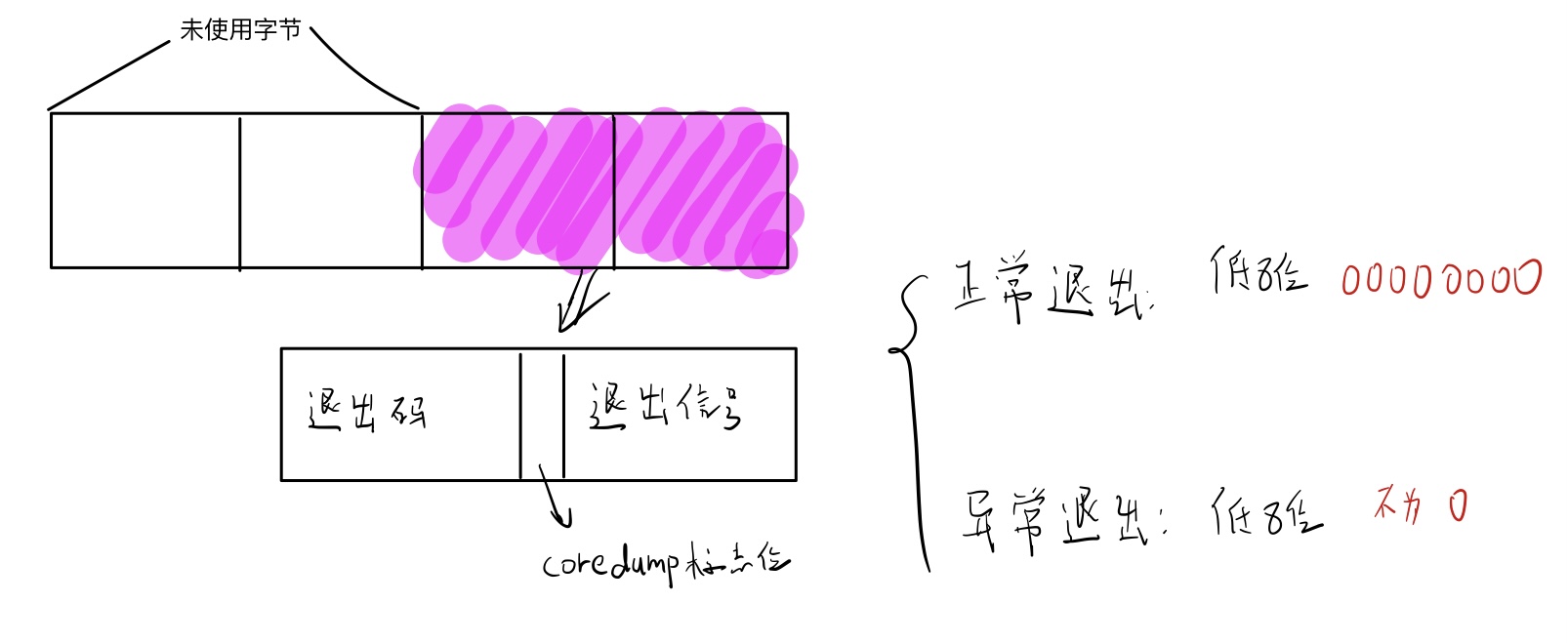
如何根据参数判断程序退出状态
1.程序正常退出:只用到了退出码,第一个字节内容全0
2.程序异常退出:看coredump标志位及退出信号
不能使用coredump标志位作为判断条件,因为coredum标志位产生是有条件的。
使用退出信号进行判断status & 111 1111判断是否为0。为0则正常退出,不为0则异常退出。
代码测试
1.创建子进程
2.模拟产生僵尸进程
3.父进程调用wait函数,再看是否产生了僵尸进程
4.阻塞:再调用结果返回之前,当前进程会被挂起,并在的到结果之后进行返回
#include <sys/wait.h>
#include <stdio.h>
#include <stdlib.h>
#include <string.h>
#include <errno.h>
int main()
{
pid_t pid;
if ((pid=fork()) == -1)
perror("fork"),exit(1);
if ( pid == 0 )
{
sleep(20);
exit(10);
}
else
{
int st;
int ret = wait(&st);
if (ret > 0 && (st & 0X7F) == 0)
{
// 正常退出
printf("child exit code:%d\\n", (st>>8)&0XFF);
}
else if(ret > 0)
{
// 异常退出
printf("sig code : %d\\n", st&0X7F );
}
}
}
3.3.2 waitpid()函数
函数原型
pid_t waitpid(pid_t pid, int* status, int options)
/**
* 参数:
* pid:
* > 0, 等待与其进程ID与pid相等的子进程
* = -1, 等待任一子进程,与wait函数等效
* status:与wait函数等效
* options:0 ->阻塞状态
* WNOHANG ->非阻塞模式
* 返回值:
* 当正常返回时,waitpid返回收集到的子进程的进程ID
* 如果设置了选项WHONG,而调用中waitpid发现没有已退出的进程可手机,则返回0
* 如果调用中出错,则返回-1,这时error会设置成相应的值以指示错误所在
*/
两个函数的相同点
- 如果子进程已经退出,调用wait/waitpid时,wait/waitpid会立即返回,并且释放资源,获得子进程退出信息
- 如果在任意时刻调用wait/waitpid函数,子进程存在且正常运行,则进程可能会发生阻塞。
- 如果不存在该子进程,则立即出错返回
4. 进程程序替换
4.1 进程替换原理
用fork创建子进程后执行的是和父进程相同的程序(有可能是不同的代码分支),子进程往往要调用一种exec函数以执行另一个程序。当进程调用一种exec函数时,该进程的用户空间代码和数据完全被新程序替换,从新程序的启动例程开始执行。调用exec并不创建新进程,所以调用exec前后的进程并未改变。
通俗的来讲就是,替换正在运行的程序,在正在运行的进程执行其它程序。
替换掉当前进程的代码段和数据段为新的程序,并且更新堆栈。
4.2 进程替换函数
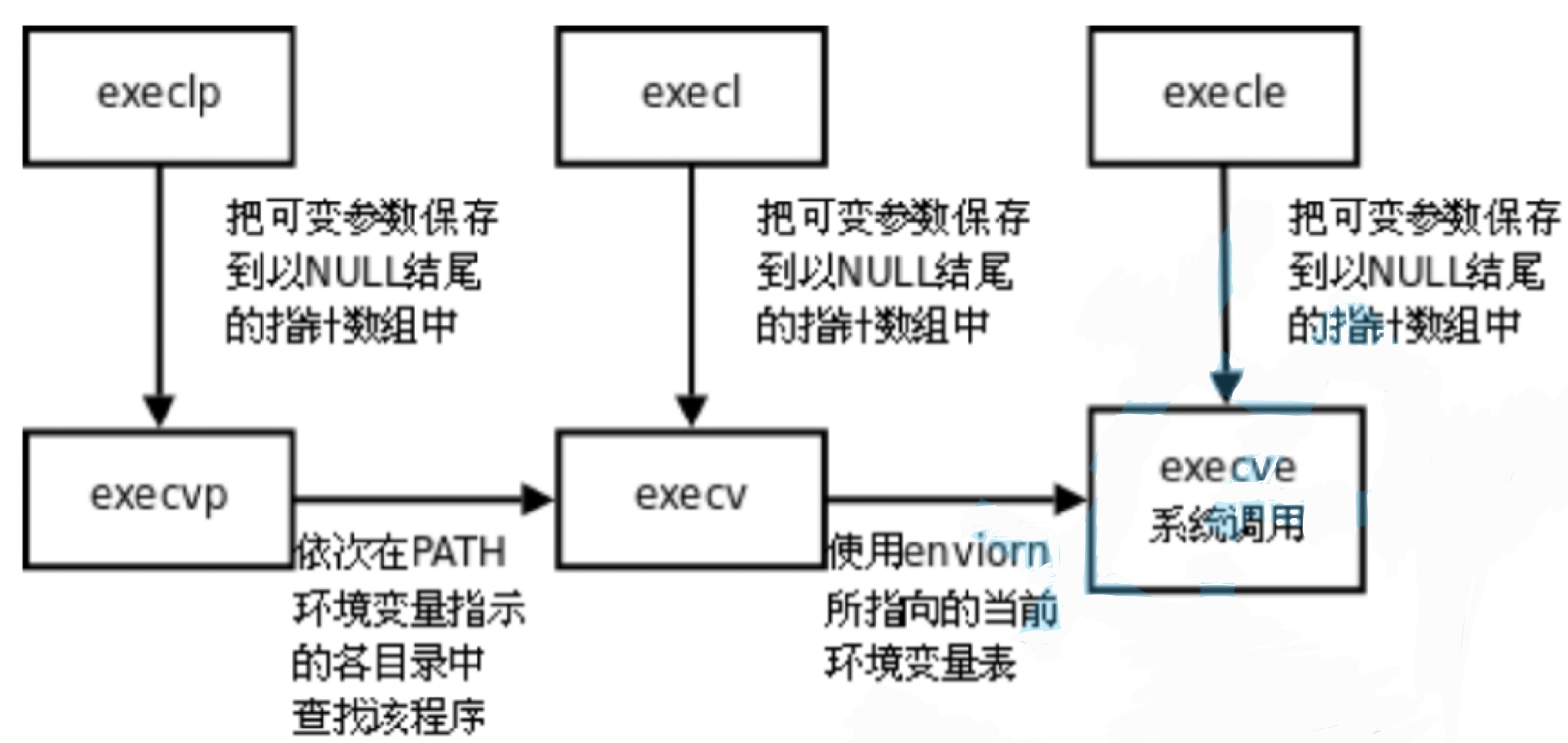
exec函数,共6中进程替换函数:
int execl(const char* path, const char* arg, ...);
int execlp(const char* file, const char* arg, ...);
int execle(const char* path, const char* arg, ..., char* const envp[]);
int execv(const char* path, char* const argv[]);
int execvp(const char* file, char* const argv[]);
int execve(const char* path, char* const argv[]);
函数解释
- 这些函数如果调用成功则加载新的程序从启动代码开始执行,不再返回
- 如果调用出错返回-1
- exec函数只有出错的返回值而没有成功的返回值
观察上述函数,发现函数原型基本相同,有的区别只是函数名与参数列表的区别,并且其中有一定的规律。
命名规则的解释
- l(list), 表示参数采用参数列表的形式
- v(vector), 表示参数采用数组的形式
- p(path), 函数名含有p,则代表自动搜索环境变量path,没有则需要指定具体的路径
- e(envior), 表示需要程序员自己维护环境变量
参数列表的解释
- path: 表示待要替换的可执行的程序,需要指定该程序在哪个路径下
- arg: 给可执行程序传递的命令行参数,该参数为可执行的文件的名字
- …: 可变参数列表,以NULL结尾
- file: 待要替换的可执行程序,可以不用给定具体路径,因为会在环境变量下进行搜索
- envp: 表示需要程序员自己组织的环境变量
函数名中的区别
1.带p和不带p的区别
如果函数名称中带有p,则表示会自动搜索环境变量。如果函数名中不带p,则表示不会自动搜索环境变量。说明execl函数在替换时,一定要给代替换程序带上路径的原因。
2.带e和不带e的区别
如果函数名中带有e,则表示程序员需要自己组织环境变量。函数名中不带有e则相反。
3.带l和不带l的区别
如果函数名带有l,则表示函数的参数为可变参数列表的形式。
代码示例
#include <stdio.h>
#include <unistd.h>
int main()
{
printf("begin exec...\\n");
//execl("/usr/bin/pwd", "/usr/bin/pwd", NULL);
//execlp("/usr/bin/pwd", "/usr/bin/pwd", NULL);
//extern char** environ;
//execle("/usr/bin/pwd", "/usr/bin/pwd", NULL, environ);
//perror("execlp");
//
char* argv[10] = {NULL};
argv[0] = "/usr/bin/ls";
argv[1] = "-l";
argv[2] = NULL;
//execv("/usr/bin/ls", argv);
//execvp("ls", argv);
extern char** environ;
execve("/usr/bin/ls", argv, environ);
printf("exec failed\\n");
return 0;
}
5. 进程替换的场景
- bash的应用场景,我们运行的指定通过bash进行解释,它的子进程就是我们输入的指令。让其子进程继承程序替换为程序员在命令行当中输入的程序,子进程创建出来就进行了进程替换
- 守护进程:启动业务进程时,不直接启动业务程序,而是启动守护进程,让守护进程创建一个子进程,让子进程程序替换称为业务进程。守护进程和业务进程进行进程间通信,让守护进程得知业务进程的情况,若业务进程正常则守护进程不做处理,业务进程崩溃或异常,则守护进程重新拉起一个子进程,让子进程进行程序替换。
以上是关于[linux] Linux进程控制超详细解析的主要内容,如果未能解决你的问题,请参考以下文章