你想知道的HIVE知识,全在这里(建议收藏)
Posted 学而知之@
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了你想知道的HIVE知识,全在这里(建议收藏)相关的知识,希望对你有一定的参考价值。
1、What's Hive
1.1 Hive的简介
Hive 是由 Facebook 开源的基于 Hadoop 的数据仓库工具,用于解决海量结构化日志的数据统计。
可以将结构化的数据文件映射为一张数据库二维表,并提供类SQL查询功能
其本质是将SQL转换为MapReduce的任务进行运算,底层由HDFS来提供数据的存储支持。
说白了hive可以理解为一个将SQL转换为MapReduce任务的工具,甚至更进一步可以说hive就是一个MapReduce的客户端。
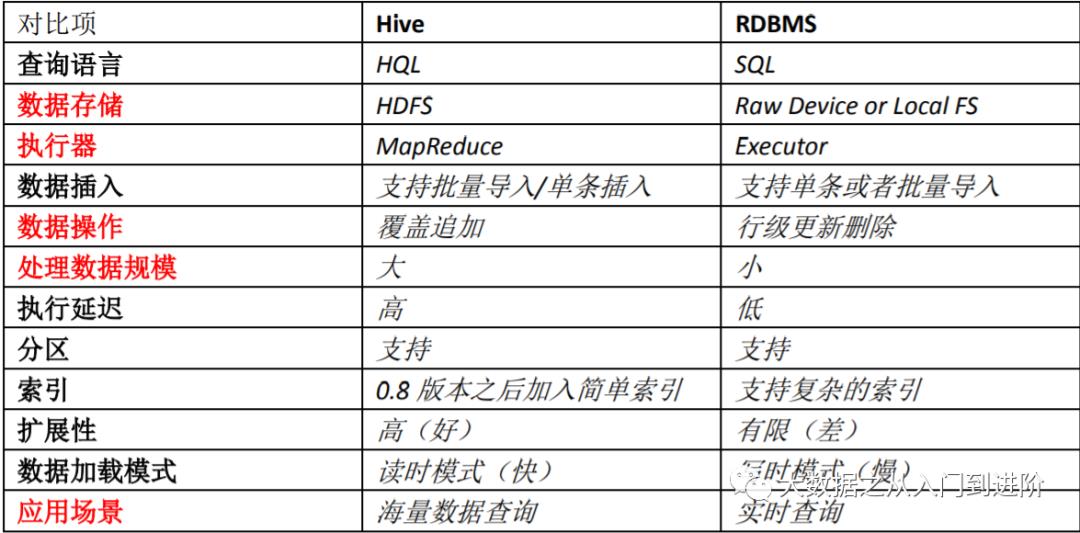
1.2 Hive与数据库的区别
1.3 Hive的优缺点
优点:
操作接口采用类SQL语法,提供快速开发的能力(简单、容易上手)
避免了去写MapReduce,减少开发人员的学习成本
Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数
缺点:
Hive 的查询延迟很严重
SQL语法与标准协议有一定差异,需要一点学习成本
优化是开发任务中比重很大的工作
1.4 Hive架构原理
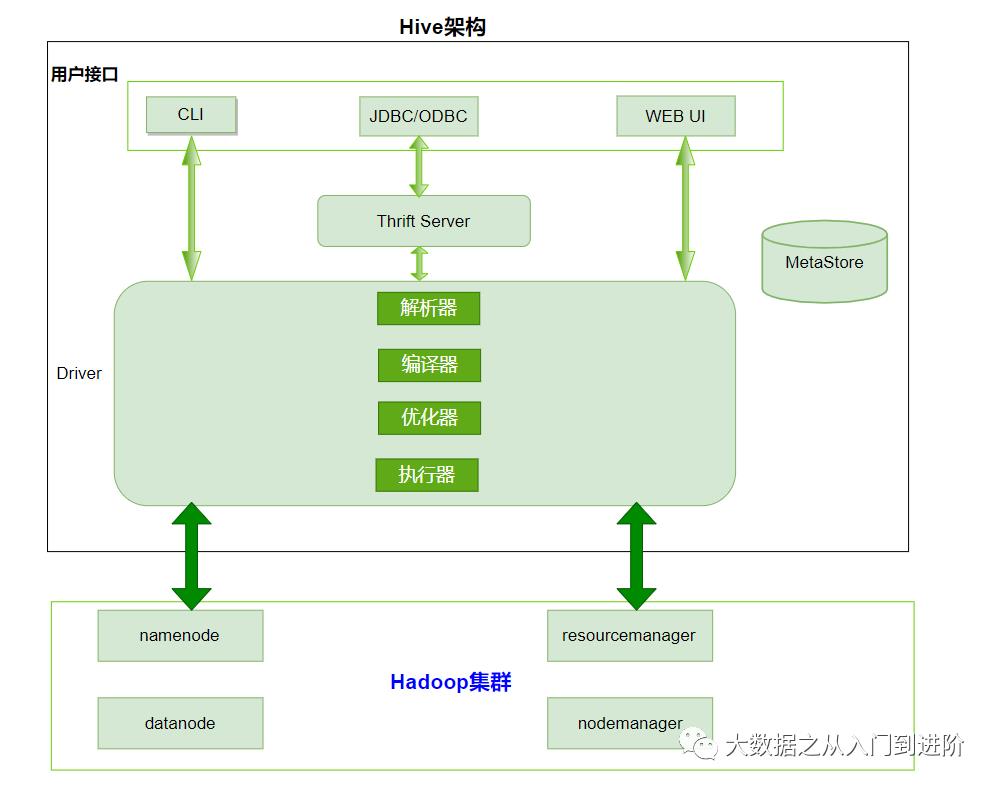
1、用户接口:Client:Hive shell
2、元数据:Metastore:
元数据包括:表名、表所属的数据库(默认是default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等 默认存储在自带的derby数据库中,生产中都使用mysql存储Metastore3、Hadoop集群
使用HDFS进行存储,使用MapReduce进行计算4、Driver:驱动器
解析器(SQL Parser):将SQL字符串转换成抽象语法树AST、对AST进行语法分析,比如表是否存在、字段是否存在、SQL语义是否有误 编译器(Physical Plan):将AST编译生成逻辑执行计划 优化器(Query Optimizer):对逻辑执行计划进行优化 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于Hive来说默认就是mapreduce任务
1.5 Hive的交互方式
Hive的交互方式主要有三种,使用Hive之前需要启动Hadoop集群和Mysql服务。当然这些服务在生产中是7*24运行的,也就不用再担心了。
在任意路径运行hive
[hadoop@node03 ~]$ hive
Hive JDBC服务
启动hiveserver2服务,前台启动与后台启动方式二选一
[hadoop@node03 ~]$ hive --service hiveserver2后台启动
[hadoop@node03 ~]$ nohup hive --service hiveserver2 &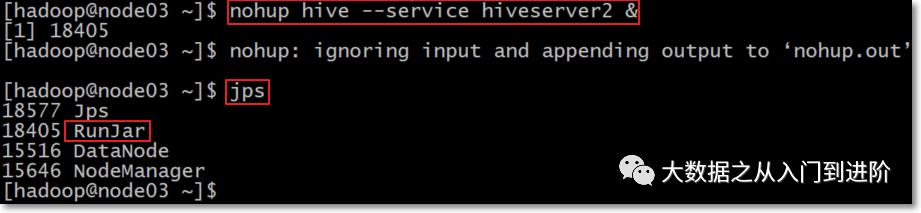
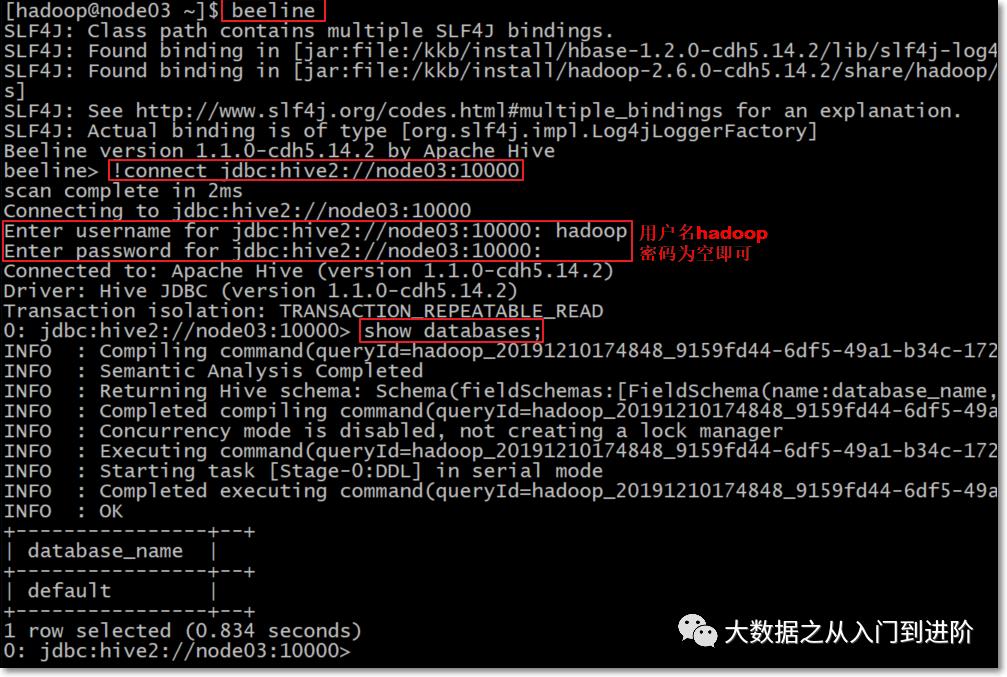
beeline连接hiveserver2服务
若是前台启动hiveserver2,请再开启一个新会话窗口,然后使用beeline连接hive
[hadoop@node03 ~]$ beeline --color=true
beeline> !connect jdbc:hive2://node03:1000
1.5 Hive的数据类型
基本数据类型
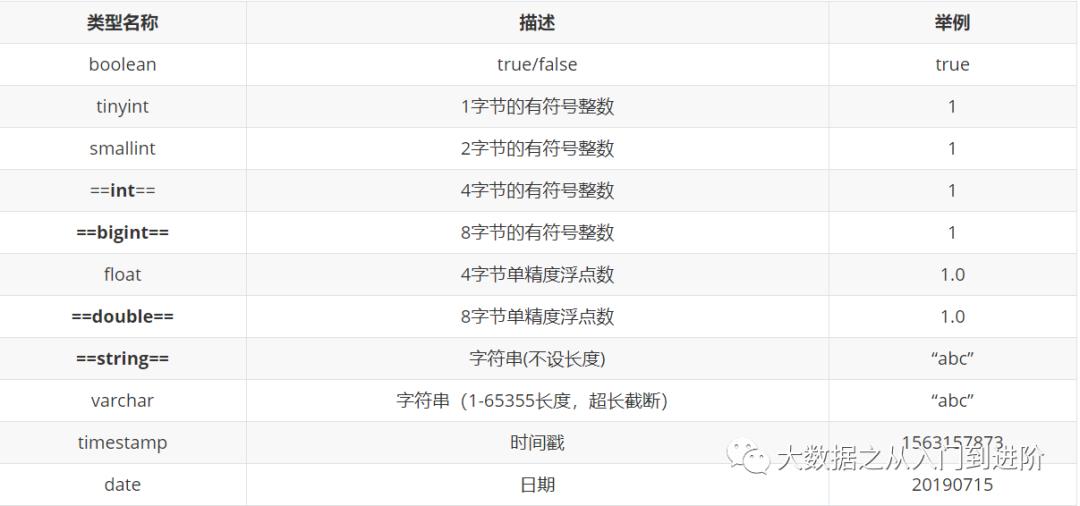
复合数据类型

2、How to use Hive
2.1 数据库的DDL
创建数据库
hive> create database db_hive;
# 或者
hive> create database if not exists db_hive;
--注:数据库在HDFS上的默认存储路径是 /user/hive/warehouse/数据库名.db
显示所有的数据库
hive> show databases;
查询数据库
hive> show databases like 'db_hive*';
查看数据库详情
hive> desc database myhive;
显示数据库的详细信息
hive> desc database extended db_hive;
切换当前数据库
hive> use db_hive;
删除数据库
# 删除为空的数据库
hive> drop database db_hive;
# 如果删除的数据库不存在,最好采用if exists 判断数据库是否存在
hive> drop database if exists db_hive;
# 如果数据库中有表存在,这里需要使用cascade强制删除数据库
hive> drop database if exists db_hive cascade;
2.2 表的DDL语句
建表语法
CREATE [EXTERNAL] TABLE [IF NOT EXISTS] table_name
[(col_name data_type [COMMENT col_comment], ...)]
[COMMENT table_comment]
[PARTITIONED BY (col_name data_type [COMMENT col_comment], ...)] 分区
[CLUSTERED BY (col_name, col_name, ...) 分桶
[SORTED BY (col_name [ASC|DESC], ...)] INTO num_buckets BUCKETS]
[ROW FORMAT row_format] row format delimited fields terminated by “分隔符”
[STORED AS file_format]
[LOCATION hdfs_path
注:官网地址:https://cwiki.apache.org/confluence/display/Hive/LanguageManual+DDL
字段解释和说明
- CREATE TABLE 创建一个指定名字的表
- EXTERNAL 创建一个外部表,在建表的同时指定一个指向实际数据的路径(LOCATION),指定表的数据保存在哪里
- COMMENT 为表和列添加注释
- PARTITIONED BY 创建分区表
- CLUSTERED BY 创建分桶表
- SORTED BY 按照字段排序(一般不常用)
- ROW FORMAT 指定每一行中字段的分隔符
- row format delimited fields terminated by '\\t'
- STORED AS 指定存储文件类型
- 常用的存储文件类型:SEQUENCEFILE(二进制序列文件)、TEXTFILE(文本)、ORCFILE(列式存储格式文件)
- 如果文件数据是纯文本,可以使用STORED AS TEXTFILE。如果数据需要压缩,使用 STORED AS SEQUENCEFILE
- LOCATION 指定表在HDFS上的存储位置。
创建内部表
-- 注:直接使用标准的SQL即可
use myhive;
create table stu(id int, name string);
创建外部表
-- 注:外部表和内部表有所不同,外部表内部的区别咱们日后再具体唠
create external table myhive.teacher (t_id string, t_name string)
row format delimited fields terminated by '\\t';
2.3 分桶表
原理:
分桶是相对分区进行更细粒度的划分,Hive表或者分区表可进一步的分桶
分桶是将整个数据内容按照某个列取hash值,对桶的个数取模的方式决定该条记录存放在哪个桶当中;具有相同hash值的数据进入到同一个文件中
作用:
取样sampling更高效,没有分桶的话需要扫描整个数据集
提升某些查询操作效率,例如map side join
创建分桶表:
use myhive;
set hive.enforce.bucketing=true;
set mapreduce.job.reduces=4;
-- 创建分桶表
create table myhive.user_buckets_demo(id int, name string)
clustered by(id)
into 4 buckets
row format delimited fields terminated by '\\t';
-- 创建普通表
create table user_demo(id int, name string)
row format delimited fields terminated by '\\t';
2.4 Hive数据导入
直接向表中插入数据(强烈不推荐使用)
hive (myhive)> create table score3 like score;
hive (myhive)> insert into table score3 partition(month ='201807') values ('001','002','100');
通过load加载数据(必须得会)
hive> load data [local] inpath 'dataPath' [overwrite] into table student [partition (partcol1=val1,…)];
hive (myhive)> load data local inpath '/kkb/hivedatas/score.csv' overwrite into table score partition(month='201806');
通过查询加载数据(必须得会)
INSERT OVERWRITE TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...) [IF NOT EXISTS]] select_statement1 FROM from_statement;
INSERT INTO TABLE tablename1 [PARTITION (partcol1=val1, partcol2=val2 ...)] select_statement1 FROM from_statement;
-- 例子
hive (myhive)> create table score5 like score;
hive (myhive)> insert overwrite table score5 partition(month = '201806') select s_id,c_id,s_score from score;
查询语句中创建表并加载数据
hive (myhive)> create table score6 as select * from score;
2.5 Hive的静态分区和动态分区
静态分区:
表的分区字段的值需要开发人员手动给定
创建分区表
use myhive; create table order_partition( order_number string, order_price double, order_time string ) partitioned BY(month string) row format delimited fields terminated by '\\t';准备数据
cd /kkb/hivedatas vim order.txt 10001 100 2019-03-02 10002 200 2019-03-02 10003 300 2019-03-02 10004 400 2019-03-03 10005 500 2019-03-03 10006 600 2019-03-03 10007 700 2019-03-04 10008 800 2019-03-04 10009 900 2019-03-04加载数据到分区表
load data local inpath '/kkb/hivedatas/order.txt' overwrite into table order_partition partition(month='2019-03');
动态分区
按照需求实现把数据自动导入到表的相应分区中,不需要手动指定分区字段的值
需求:根据分区字段不同的值,自动将数据导入到分区表不同的分区中
创建表
--创建普通表 create table t_order( order_number string, order_price double, order_time string )row format delimited fields terminated by '\\t'; --创建目标分区表 create table order_dynamic_partition( order_number string, order_price double )partitioned BY(order_time string) row format delimited fields terminated by '\\t';准备数据
cd /kkb/hivedatas vim order_partition.txt 10001 100 2019-03-02 10002 200 2019-03-02 10003 300 2019-03-02 10004 400 2019-03-03 10005 500 2019-03-03 10006 600 2019-03-03 10007 700 2019-03-04 10008 800 2019-03-04 10009 900 2019-03-04向普通表t_order 加载数据
load data local inpath '/kkb/hivedatas/order_partition.txt' overwrite into table t_order;动态加载数据到分区中
-- 要想进行动态分区,需要设置参数 -- 开启动态分区功能 hive> set hive.exec.dynamic.partition=true; -- 设置hive为非严格模式 hive> set hive.exec.dynamic.partition.mode=nonstrict; hive> insert into table order_dynamic_partition partition(order_time) select order_number, order_price, order_time from t_order;查看分区
hive> show partitions order_dynamic_partition;


扫描二维码,获取更多精彩


以上是关于你想知道的HIVE知识,全在这里(建议收藏)的主要内容,如果未能解决你的问题,请参考以下文章