TensorFlow 决策森林来啦!
Posted TensorFlow 社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了TensorFlow 决策森林来啦!相关的知识,希望对你有一定的参考价值。

发布人:Mathieu Guillame-Bert、Sebastian Bruch、Josh Gordon、Jan Pfeifer
我们很高兴开放 TensorFlow 决策森林 (TensorFlow Decision Forests,TF-DF) 源代码。TF-DF 是用于训练、解释并服务于决策森林模型(包括随机森林和梯度提升树)的最先进算法集,可用于生产环境。得益于 TensorFlow 和 Keras 的灵活性和可组合性,您现在可以将这些模型用于分类、回归和任务排序。
随机森林是一种主流的决策森林模型。在这个动图中,您可以看到决策森林中的树通过对结果投票的方式对示例进行分类
决策森林简介
决策森林是一类机器学习算法,其质量和速度堪比神经网络(并且通常优于神经网络),尤其是在处理表格式数据时。决策森林由多个决策树构成,因此易于使用和理解,并且现在还有大量的可解释性工具和技术供您使用。
TF-DF 为 TensorFlow 用户提供了这类模型以及整套量身定制的工具:
-
初学者会发现开发和解释决策森林模型更为轻松。无需显式列出或预处理输入特征(因为决策森林可以自然处理数字属性和分类属性),无需指定架构(例如,相较于神经网络,无需通过尝试不同的层组合来指定架构),也无需担心模型发散。训练好模型后,您就可以直接对其进行绘制,或使用易于解释的统计数据对其分析。
-
高级用户将从推理速度非常快的模型中受益(在多数情况下每个示例的推理时间为亚微秒级)。同时,该库为模型实验和研究提供了大量的可组合性。特别是,用户可以很轻松地将神经网络和决策森林结合起来。
如果您之前通过其他库使用决策森林,那么可以在此了解一下 TF-DF 的部分功能:
-
它提供一系列最先进的决策森林训练和应用算法,例如随机森林、梯度提升树、CART、(Lambda)MART、DART、极端随机树、Greedy Global Growth、Oblique Tree、单边采样、分类集学习、随机分类学习、包外评估、特征重要性以及结构特征重要性。
-
可连通丰富的 TensorFlow 生态系统,使您能够更轻松地将基于决策树的模型与各种 TensorFlow 工具、库以及 TFX 等平台集成。
-
如果你还没有接触过神经网络,则可以通过决策森林轻松入门 TensorFlow,并以此为起点,继续深入探索神经网络。
代码示例
详尽的示例胜过千言万语。因此,在本文中,我们将为您展示使用 TensorFlow 决策森林训练模型有多简便。访问 TF-DF 网站和 GitHub 页面,查看更多示例。您也可以观看我们在 2021 年 Google I/O 大会上的演讲。
训练模型
让我们从最小的示例开始。本例中,我们在表格式 Palmer's Penguins 数据集上训练随机森林模型。目的是根据动物的特征来预测其物种。该数据集包含数字和分类特征,并存储为 csv 文件。

上图为 Palmer's Penguins 数据集中的三个示例
我们一起来训练一个模型:
#安装 TensorFlow 决策森林
!pip install tensorflow_decision_forests
#加载 TensorFlow 决策森林
import tensorflow_decision_forests as tfdf
#使用 Pandas 加载训练数据集
import pandas
train_df = pandas.read_csv("penguins_train.csv")
#将 Pandas Dataframe 转换为 TensorFlow 数据集
train_ds = tfdf.keras.pd_dataframe_to_tf_dataset(train_df, label="species")
#训练模型
model = tfdf.keras.RandomForestModel()
model.fit(train_ds)请注意,我们没有在代码中提供输入特征或超参数。这意味着,TensorFlow 决策森林将自动检测来自该数据集的输入特征,并对所有超参数使用默认值。
评估模型
现在,让我们来评估模型的质量:
#加载测试数据集
test_df = pandas.read_csv("penguins_test.csv")
#将其转换为 TensorFlow 数据集
test_ds = tfdf.keras.pd_dataframe_to_tf_dataset(test_df, label="species")
#评估模型
model.compile(metrics=["accuracy"])
print(model.evaluate(test_ds))
# >> 0.979311
#注意:交叉验证更适合这样的小型数据集。
#另请参阅下方的“包外评估”。
#将模型导入 TensorFlow SavedModel
model.save("project/my_first_model")很简单,对吧?具有默认超参数的默认 RandomForest 模型为大多数问题确立了快速且良好的基准。总体而言,决策森林可针对中小型问题进行快速训练,与许多其他类型的模型相比,对超参数的调整较少,并且通常会得到出色的结果。
解释模型
现在,您已经了解所训练模型的准确性,接下来可以考虑其可解释性。如果您希望理解和解读正在建模的现象、调试模型或开始信任其决策,那么可解释性很重要。如上所述,我们提供了多种工具来解读经过训练的模型,首先从绘制开始。
tfdf.model_plotter.plot_model_in_colab(model, tree_idx=0)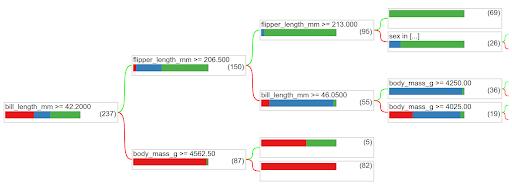
您可以直观地看到决策树结构。在该决策树中,第一个决策基于喙的长度。喙长超过 42.2mm 的企鹅很可能属于蓝色(巴布亚企鹅)或绿色(帽带企鹅)所表示的企鹅种类,而喙较短的企鹅很可能是红色(阿德利企鹅)所表示的企鹅种类。
对于第一组,决策树随后询问鳍状肢长度。鳍状肢长度超过 206.5mm 的企鹅很可能属于绿色(帽带企鹅)所表示的企鹅种类,而其余的很可能属于蓝色(巴布亚企鹅)所表示的企鹅种类。
模型统计数据是对绘图的一种补充。示例统计数据包括:
-
每个特征使用了多少次?
-
模型训练的速度有多快(按决策树的数量和时间)?
-
树结构中的节点是如何分布的(例如,大多数分支的长度是多少?)
这些问题以及更多此类查询的答案都包含在模型摘要中,并可在模型检查器中访问。
#打印关于模型的所有可用信息
model.summary()
>> Input Features (7):
>> bill_depth_mm
>> bill_length_mm
>> body_mass_g
>> ...
>> Variable Importance:
>> 1. "bill_length_mm" 653.000000 ################
>> ...
>> Out-of-bag evaluation: accuracy:0.964602 logloss:0.102378
>> Number of trees: 300
>> Total number of nodes: 4170
>> ...
#以数组形式获取特征的重要性
model.make_inspector().variable_importances()["MEAN_DECREASE_IN_ACCURACY"]
>> [("flipper_length_mm", 0.149),
>> ("bill_length_mm", 0.096),
>> ("bill_depth_mm", 0.025),
>> ("body_mass_g", 0.018),
>> ("island", 0.012)]在上述示例中,模型使用默认的超参数值完成训练。作为首个解决方案而言该方法它非常好,但是对超参数进行“调优”可以进一步提升模型的质量。具体可以按如下方式执行:
#列出所有其他可用的学习算法
tfdf.keras.get_all_models()
>> [tensorflow_decision_forests.keras.RandomForestModel,
>> tensorflow_decision_forests.keras.GradientBoostedTreesModel,
>> tensorflow_decision_forests.keras.CartModel]
#显示梯度提升树模型的超参数
? tfdf.keras.GradientBoostedTreesModel
>> A GBT (Gradient Boosted [Decision] Tree) is a set of shallow decision trees trained sequentially. Each tree is trained to predict and then "correct" for the errors of the previously trained trees (more precisely each tree predicts the gradient of the loss relative to the model output)..
...
Attributes:
num_trees: num_trees: Maximum number of decision trees. The effective number of trained trees can be smaller if early stopping is enabled. Default: 300.
max_depth: Maximum depth of the tree. `max_depth=1` means that all trees will be roots. Negative values are ignored. Default: 6.
...
#使用指定的超参数创建另一个模型
model = tfdf.keras.GradientBoostedTreesModel(
num_trees=500,
growing_strategy="BEST_FIRST_GLOBAL",
max_depth=8,
split_axis="SPARSE_OBLIQUE",
)
#评估模型
model.compile(metrics=["accuracy"])
print(model.evaluate(test_ds))
# >> 0.986851您的下一步
希望您喜欢这篇关于 TensorFlow 决策森林的简短展示文章,也希望您在使用这一新库和为其作出贡献的过程中,能感受到我们开发时的乐趣。
借助 TensorFlow 决策森林,您现在可以非常轻松地在 TensorFlow 中训练最先进的决策森林模型,同时达到最高的速度和质量。如果您喜欢探索,现在还可以将决策森林和神经网络相结合,创建新型混合模型。
如要详细了解 TensorFlow 决策森林库,请参考下列我们从大量资源整合并推荐的内容:
-
可以在初学者 Colab Notebook 中找到这篇文章的完整代码,也可以查看此处的中级 Notebook 和高级 Notebook。
-
观看 Google I/O 大会上的视频:Decision forests in TensorFlow | Session。
-
在 GitHub 上查看 TensorFlow 决策森林项目并 Star。
-
如果您已经在使用 TensorFlow 且有兴趣将决策森林添加到现有工作流程中,可阅读我们的迁移指南获取更多实用信息。
-
高级用户也可以关注 Yggdrasil Decision ForestsYggdrasil Decision Forest GitHub 项目,即由 C++ 引擎提供支持的 TensorFlow 决策森林,其中已经实现了该算法。
如有任何疑问,请使用标签“TFDF”在 discuss.tensorflow.org 上提问,我们将竭诚答疑解惑。再次感谢。
推荐阅读
一起看 I/O | TensorFlow 的最新资讯,一文全掌握
使用 MoveNet 和 TensorFlow.js 的下一代姿态检测
Google I/O 2021 云计算开发者指南
登陆官网或关注 TensorFlow 官方微信平台获取更多资讯。

以上是关于TensorFlow 决策森林来啦!的主要内容,如果未能解决你的问题,请参考以下文章