分布式训练---参数服务器训练(飞桨paddle1.8)
Posted 汀、
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式训练---参数服务器训练(飞桨paddle1.8)相关的知识,希望对你有一定的参考价值。
1.参数服务器训练简介
参数服务器训练是分布式训练领域普遍采用的编程架构,主要解决以下两类问题:
- 模型参数过大:单机内存空间不足,需要采用分布式存储。
- 训练数据过多:单机训练太慢,需要加大训练节点,来提高并发训练速度。
如图所示,参数服务器主要包含Server和Worker两个部分,其中Server负责参数的存储和更新,而Worker负责训练。简单来说,参数服务器训练的基本思路:当训练数据过多,一个Worker训练太慢时,可以引入多个Worker同时训练,这时Worker之间需要同步模型参数。直观想法是,引入一个Server,Server充当Worker间参数交换的媒介。当模型参数过大以至于单机存储空间不足时或Worker过多导致一个Server是瓶颈时,就需要引入多个Server。
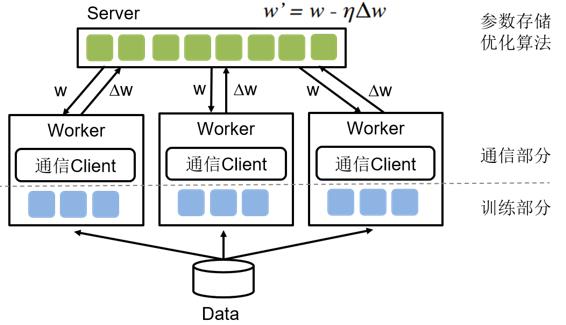
参数服务器训练的具体流程如下:
- 将训练数据均匀的分配给不同的Worker。
- 将模型参数分片,存储在不同的Server上。
- Worker端:读取一个minibatch训练数据,从Server端拉取最新的参数,计算梯度,并根据分片上传给不同的Server。
- Server端:接收Worker端上传的梯度,根据优化算法更新参数。根据Server端每次参数更新是否需要等待所有Worker端的梯度,分为同步训练和异步训练两种机制。
飞桨的参数服务器框架也是基于这种经典的参数服务器模式进行设计和开发的,同时在这基础上进行了SGD(Stochastic Gradient Descent)算法的创新(GEO-SGD)。目前飞桨支持3种模式,分别是同步训练模式、异步训练模式、GEO异步训练模式,三者之间的差异如下图所示。
当前经过大量的实验验证,最佳的方案是每台机器上启动Server和Worker两个进程,而一个Worker进程中可以包含多个用于训练的线程。
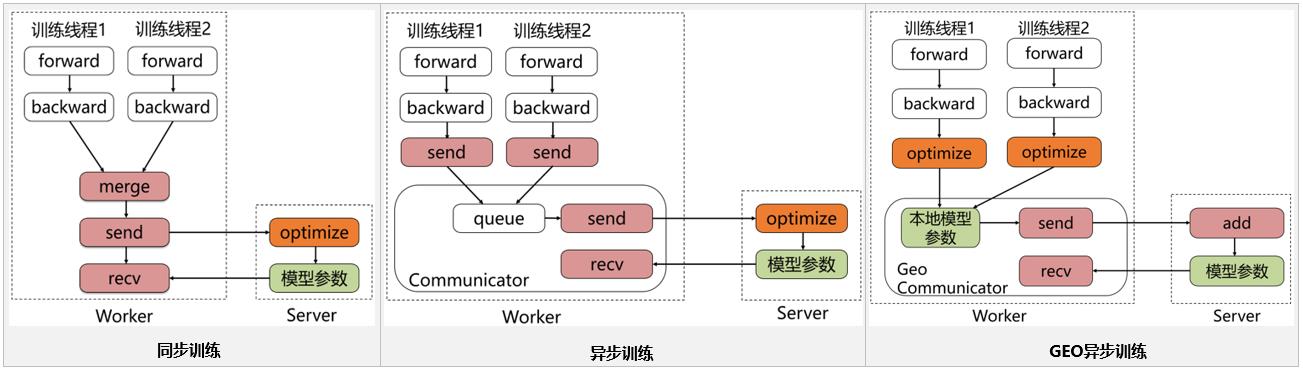
同步训练
Worker在训练一个batch的数据后,会合并所有线程的梯度发给Server, Server在收到所有节点的梯度后,会统一进行梯度合并及参数更新。同步训练的优势在于Loss可以比较稳定的下降,缺点是整个训练速度较慢,这是典型的木桶原理,速度的快慢取决于最慢的那个线程的训练计算时间,因此在训练较为复杂的模型时,即模型训练过程中神经网络训练耗时远大于节点间通信耗时的场景下,推荐使用同步训练模式。
异步训练
在训练一个batch的数据后,Worker的每个线程会发送梯度给Server。而Server不会等待接收所有节点的梯度,而是直接基于已收到的梯度进行参数更新。异步训练去除了训练过程中的等待机制,训练速度得到了极大的提升,但是缺点也很明显,那就是Loss下降不稳定,容易发生抖动。建议在个性化推荐(召回、排序)、语义匹配等数据量大的场景使用。
尤其是推荐领域的点击率预估场景,该场景可能会出现千亿甚至万亿规模的稀疏特征,而稀疏参数也可以达到万亿数量级,且需要小时级或分钟级流式增量训练。如果使用异步训练模式,可以很好的满足该场景的online-learning需求。
GEO异步训练
GEO(Geometric Stochastic Gradient Descent)异步训练是飞桨自研的异步训练模式,其最大的特点是将参数的更新从Server转移到Worker上。每个Worker在本地训练过程中会使用SGD优化算法更新本地模型参数,在训练若干个batch的数据后,Worker将发送参数更新信息给Server。Server在接收后会通过加和方式更新保存的参数信息。所以显而易见,在GEO异步训练模式下,Worker不用再等待Server发来新的参数即可执行训练,在训练效果和训练速度上有了极大的提升。但是此模式比较适合可以在单机内能完整保存的模型,在搜索、NLP等类型的业务上应用广泛,推荐在词向量、语义匹配等场景中使用。
运行策略的详细描述可以参考文档PaddlePaddle Fluid CPU分布式训练(Transplier)使用指南
2.单机训练转参数服务器训练
单机训练包含:网络定义、优化器定义、数据读取和模型保存。
根据以上参数服务器架构图可知,从单机到分布式,需要考虑以下几个问题:
- 怎么启动多个节点;哪些节点是Worker、哪些节点是Server
- 要采用哪种分布式训练模式
- 如何初始化Worker和Server
- 训练数据怎么划分给不同的Worker
- 每个Server上都有部分参数,怎么保存成一个模型文件
2.1 单机转参数服务器具体步骤
针对这些问题,飞桨在release/1.5.0之后新增了高级分布式API Fleet,只需数行代码便可将单机训练转换为分布式训练。
1. 每个节点需要扮演不同的角色
提交任务时,集群会分配节点(集群需要按照用户需求分配节点,每个节点扮演Worker、Server中的一种角色)。
示例:
role=PaddleCloudRoleMaker()
fleet.init(role)
用户首先会根据集群环境创建RokerMaker,然后调用fleet.init初始化训练节点的环境和角色。
RoleMaker接口定义了不同运行环境下,每个节点的编号和扮演的角色是Server还是Worker。
其中运行环境相关的RoleMaker包括PaddleCloudRoleMaker、UerDefineRoleMaker<用户自定义环境>、MPIRoleMaker<MPI运行环境>。
RoleMaker会根据环境配置获取节点列表(ip地址、端口号、节点编号)、给节点分配角色、定义节点之间的通信机制。
用户可以通过fleet.is_worker和fleet.is_server来判断节点角色,运行不同的流程:
- 单机训练中,程序需要完成从
数据读取->前向loss计算->反向梯度计算->参数更新的完整流程。 - 参数服务器训练中,
Worker节点完成数据读取->前向loss计算->反向梯度计算的步骤,而Server节点完成参数更新的步骤,两者分工协作,解决了单机不能训练大数据和大模型的问题。
2. 需要指定分布式训练的模式
DistributedStrategy接口定义了不同的训练模式:同步Sync、异步Async、GEO-SGD等。不同的场景,选择合适的训练模式会得到更好的训练速度和训练效果。
用户设置训练模式后,调用fleet.distributed_optimizer接口根据用户配置的训练模式来生成Worker端和Server端要执行的OP计算图,其中Worker端主要生成包含数据读取->前向loss计算->反向梯度计算的步骤的计算图, Pserver端主要包含参数更新相关的计算图, 并且会根据训练模式插入参数服务器训练所需的通信相关的计算图。
3. 启动、关闭、初始化Worker和Server
fleet.init_worker、fleet.init_server, 会进行节点初始化,比如初始化模型参数、创建RPC连接。
fleet.run_server(),会启动server,比如监听及响应Worker端请求。
fleet.stop_worker(),关闭训练节点
4. 训练数据需要分配到各个节点上
fleet.split_files接口,输入值是文件目录列表,输出是当前节点的训练数据文件列表,功能是将训练数据文件均匀的分配到各个节点上。(如果用户使用的集群环境已经将训练所需的数据预先分配好,则不需调用此步骤)
5. 模型保存
fleet.save_persistables和fleet.save_inference_model接口进行全量参数的保存及预测模型保存,分别对应单机的fluid.io.save_persistable和fluid.io.save_inference_model, 参数服务器的分布式训练模式只建议用户使用0号Worker保存参数。
具体示例:
if fleet.is_first_worker():
fleet.save_persistables(/* 模型保存相关的配置 */)
fleet.save_inference_model(/* 模型保存相关的配置 */)
2.2 参数服务器训练代码示例
假设用户设置N个节点,外层提交任务的脚本之后,则开启参数服务器训练,所需步骤如下:
- 首先,执行fleet.init, 生成RokerMaker,并从环境变量中获取节点IP、端口;根据配置启动N+M个进程(N个Worker,M个server), 一般按照一个节点一个Worker进程,一个Server进程,来对进程进行角色划分。
- 接着,执行distributed_optimizer minimize,根据用户设置的训练模式,生成Worker端和Server端要执行的子图。
异步模式下,Worker端子图包含Reader OP、前向OP、反向OP、参数切分OP、参数发送OP、参数接收OP、参数merge OP、barrier OP等; Server端子图包含监听OP、参数merge OP、参数更新OP等。 - Server端,执行init_server初始化模型参数、run_server会执行Server端的子图;之后所有的操作都是由Worker向Server主动发起。
- Worker端,执行exe.run(startup_program)初始化模型参数、切分数据split_files、train_from_dataset执行Worker端子图、保存模型。
下面是一个包含参数服务器所有配置的代码示例。
# 1. 通过RoleMaker定义环境, 包括PaddleCloudRoleMaker、UerDefineRoleMaker<用户自定义环境>、MPIRoleMaker<MPI运行环境>
role = PaddleCloudRoleMaker()
fleet.init(role)
# 2. 分布式训练根据通信策略可以分为:同步模式、异步模式、GEO-SGD模式等。
# 当前配置的是异步训练模式
strategy = DistributedStrategy.create_async_strategy()
# distributed_optimizer会根据不同训练模式来生成Worker和Server需要执行的流程
optimizer = fluid.optimizer.SGD(learning_rate=base_lr)
optimizer = fleet.distributed_optimizer(optimizer, strategy)
optimizer.minimize(avg_cost)
# 3. 启动Pserver端,如果需要从某个模型热启,在训练开始之前加载某次训练得到的参数,则只需将初始化模型路径传入init_server()函数
if fleet.is_server():
fleet.init_server()
fleet.run_server()
# 启动Worker 启动训练节点
elif fleet.is_worker():
# 执行init_worker()来完成节点初始化
fleet.init_worker()
# 执行fleet.startup_program,从服务器端同步参数的初始化
exe.run(fleet.startup_program)
dataset = fluid.DatasetFactory().create_dataset()
dataset.set_use_var([datas[0],datas[1],datas[2]])
dataset.set_batch_size(batch_size)
dataset.set_pipe_command("python pairwise_file_reader.py")
filelist = ["train_raw/%s" % x for x in os.listdir("train_raw")]
# 4. Fleet提供了split_files()的接口,输入值是一个稳定的目录List,随后该函数会根据节点自身的编号拿到相应的数据文件列表
# 如果是本地训练,需要使用split_files()来进行文件切分, 如果是用的其它分布式系统,数据已经预先切分好的,则不用调用此方法
file_list = fleet.split_files(file_list)
dataset.set_filelist(filelist)
dataset.set_thread(4)
for i in range(3):
exe.train_from_dataset(program=fleet.main_program, dataset=dataset)
# 5. 针对与参数服务器的分布式训练,需要使用跟单机保存模型不同的接口进行参数的保存
if fleet.worker_index() == 0:
fleet.save_persistables(exe, model_path, fleet.main_program)
# 执行fleet.stop_worker()关闭训练节点
fleet.stop_worker()
3 基于分类模型单机训练示例
本文档以二分类模型举例,介绍单机训练和参数服务器训练(异步模式)两种模式的详细代码,方便用户快速了解两种模式的具体差异。
本教程涉及的所有源码,可通过此链接获取:https://github.com/PaddlePaddle/Fleet/blob/develop/examples/distribute_ctr
建议亲手操作,毕竟只有亲手敲过的代码才真正是你自己的。
3.1 环境准备
训练前,请确保:
- 已正确安装飞桨最新版本。安装操作请参见飞桨。
- 运行环境基于Linux,示例代码支持Unbuntu及CentOS。
- 运行环境中Python版本高于2.7。
3.2 数据处理
数据集采用Display Advertising Challenge所用的Criteo数据集。该数据集包括两部分:训练集和测试集。训练集包含一段时间内Criteo的部分流量,测试集则对应训练数据后一天的广告点击流量。
数据预处理共包括两步:
- 将原始训练集按9:1划分为训练集和验证集。
- 数值特征(连续特征)需进行归一化处理,但需要注意的是,对每一个特征
<integer feature i>,归一化时用到的最大值并不是用全局最大值,而是取排序后95%位置处的特征值作为最大值,同时保留极值。
3.3 模型设计
模型属于二分类模型,网络结构如下图所示。输入是N类稀疏特征,比如词的id。通过查取embedding表(字典大小xM维的向量表),变换成N个M维向量。将所有NxM维向量连接在一起融合为一个向量。网络由多个输入数据层(fluid.layers.data)、多个共享参数的嵌入层(fluid.layers.embedding),若干个全连接层(fluid.layers.fc),以及相应的分类任务的Loss计算和auc计算。经过多层全连接层+激活函数(relu)后,进行0/1分类。

# 数据输入声明
# Criteo数据集分连续数据与离散(稀疏)数据,整体而言,数据输入层包括三个,分别是:`dense_input`用于输入连续数据,维度由超参数`dense_feature_dim`指定,数据类型是归一化后的浮点型数据。`sparse_input_ids`用于记录离散数据,在Criteo数据集中,共有26个slot,所以我们创建了名为`C1~C26`的26个稀疏参数输入,并设置`lod_level=1`,代表其为变长数据,数据类型为整数;最后是每条样本的`label`,代表了是否被点击,数据类型是整数,0代表负样例,1代表正样例。
# 在飞桨中数据输入的声明使用`paddle.fluid.layers.data()`,会创建指定类型的占位符,数据IO会依据此定义进行数据的输入
def input_data(self, params):
dense_input = fluid.layers.data(name="dense_input",
shape=[params.dense_feature_dim],
dtype="float32")
sparse_input_ids = [
fluid.layers.data(name="C" + str(i),
shape=[1],
lod_level=1,
dtype="int64") for i in range(1, 27)
]
label = fluid.layers.data(name="label", shape=[1], dtype="int64")
inputs = [dense_input] + sparse_input_ids + [label]
return inputs
def net(self, inputs, params):
# Embedding层
# Embedding层的组网方式:`Embedding`层的输入是`sparse_input`,shape由超参的`sparse_feature_dim`和`embedding_size`定义
# 指定`is_sprase=True`后,计算图会将该参数视为稀疏参数,反向更新以及分布式通信时,都以稀疏的方式进行,会极大的提升运行效率,同时保证效果一致。
def embedding_layer(input):
return fluid.layers.embedding(
input=input,
is_sparse=params.is_sparse,
size=[params.sparse_feature_dim, params.embedding_size],
param_attr=fluid.ParamAttr(
name="SparseFeatFactors",
initializer=fluid.initializer.Uniform()),
)
sparse_embed_seq = list(map(embedding_layer, inputs[1:-1]))
# 各个稀疏的输入通过Embedding层后,将其合并起来,置于一个list内,以方便进行concat的操作
concated = fluid.layers.concat(sparse_embed_seq + inputs[0:1], axis=1)
# 将离散数据通过embedding查表得到的值,与连续数据的输入进行`concat`操作,合为一个整体输入,作为全链接层的原始输入。我们共设计了3层FC,每层FC的输出维度都为400,每层FC都后接一个`relu`激活函数,每层FC的初始化方式为符合正态分布的随机初始化,标准差与上一层的输出维度的平方根成反比。
fc1 = fluid.layers.fc(
input=concated,
size=400,
act="relu",
param_attr=fluid.ParamAttr(initializer=fluid.initializer.Normal(
scale=1 / math.sqrt(concated.shape[1]))),
)
fc2 = fluid.layers.fc(
input=fc1,
size=400,
act="relu",
param_attr=fluid.ParamAttr(initializer=fluid.initializer.Normal(
scale=1 / math.sqrt(fc1.shape[1]))),
)
fc3 = fluid.layers.fc(
input=fc2,
size=400,
act="relu",
param_attr=fluid.ParamAttr(initializer=fluid.initializer.Normal(
scale=1 / math.sqrt(fc2.shape[1]))),
)
predict = fluid.layers.fc(
input=fc3,
size=2,
act="softmax",
param_attr=fluid.ParamAttr(initializer=fluid.initializer.Normal(
scale=1 / math.sqrt(fc3.shape[1]))),
)
# Loss及Auc计算
# 预测的结果通过一个输出shape为2的FC层给出,该FC层的激活函数softmax,会给出每条样本分属于正负样本的概率。
# 每条样本的损失由交叉熵给出,交叉熵的输入维度为[batch_size,2],数据类型为float,label的输入维度为[batch_size,1],数据类型为int。该batch的损失`avg_cost`是各条样本的损失之和
# 同时还会计算预测的auc,auc的结果由`fluid.layers.auc()`给出,该层的返回值有三个,分别是全局auc: `auc_var`,当前batch的auc: `batch_auc_var`,以及auc_states: `auc_states`,auc_states包含了`batch_stat_pos, batch_stat_neg, stat_pos, stat_neg`信息。
cost = fluid.layers.cross_entropy(input=predict, label=inputs[-1])
avg_cost = fluid.layers.reduce_sum(cost)
auc_var, batch_auc_var, _ = fluid.layers.auc(input=predict,
label=inputs[-1])
return avg_cost, auc_var, batch_auc_var
3.4模型训练
def train(params):
# 引入模型的组网
ctr_model = CTR()
inputs = ctr_model.input_data(params)
avg_cost, auc_var, batch_auc_var = ctr_model.net(inputs,params)
# 选择反向更新优化策略
optimizer = fluid.optimizer.Adam(params.learning_rate)
optimizer.minimize(avg_cost)
# 创建训练的执行器
exe = fluid.Executor(fluid.CPUPlace())
exe.run(fluid.default_startup_program())
# 引入数据读取
dataset = get_dataset(inputs,params)
# 开始训练
for epoch in range(params.epochs):
# 启动pyreader的异步训练线程
# PyRreader是飞桨提供的简洁易用的数据读取API接口,支持同步数据读取及异步数据读取,用户自行定义数据处理的逻辑后,以迭代器的方式传递给PyReader,完成训练的数据读取部分
reader.start()
batch_id = 0
try:
while True:
# 获取网络中,所需的输出,如loss、auc等
loss_val, auc_val, batch_auc_val = exe.run(
program=compiled_prog,
fetch_list=[
avg_cost.name, auc_var.name, batch_auc_var.name
])
loss_val = np.mean(loss_val)
auc_val = np.mean(auc_val)
batch_auc_val = np.mean(batch_auc_val)
# 每隔10个Batch打印一次输出
if batch_id % 10 == 0 and batch_id != 0:
logger.info(
"TRAIN --> pass: {} batch: {} loss: {} auc: {}, batch_auc: {}"
.format(epoch, batch_id,
loss_val / params.batch_size, auc_val,
batch_auc_val))
batch_id += 1
except fluid.core.EOFException:
# 一次训练完成后,要调用reset来将Reader恢复为初始状态,为下一轮训练准备
reader.reset()
if params.test:
model_path = (str(params.model_path) + "/"+"epoch_" + str(epoch))
fluid.io.save_persistables(executor=exe, dirname=model_path)
logger.info("Train Success!")
4. 参数服务器训练示例
对于参数服务器训练来说,训练前也需要完成环境准备、数据处理、模型设计工作。其中,数据处理和模型设计与单机训练完全相同,可以直接拿来使用。
4.1 环境准备
执行模型训练前,需要确保运行环境满足以下要求:
- 飞桨参数服务器模式的训练,目前只支持在
Liunx环境下运行,推荐使用ubuntu或CentOS - 飞桨参数服务器模式的Python环境支持
python 2.7及python 3.5+, 安装和运行前请检查版本是否符合要求 - 使用飞桨的参数服务器分布式训练,请确保各自之间可以通过
ip:port的方式访问rpc服务,使用http/https代理会导致通信失败 - 参数服务器使用RPC通信完成整个训练流程,因此训练节点存在于同一个机房、IDC会获得更好的速度
- 飞桨的参数服务器训练支持多种训练环境的启动和运行,包括kubernetes/MPI/其他自定义环境等。
4.2 数据处理
参数服务器训练的数据处理与单机训练完全相同,这里不再重复赘述。
4.3 模型设计
参数服务器训练的模型设计与单机训练完全相同,这里不再重复赘述。
4.4模型训练
飞桨的参数服务器中存在Worker和PServer两种角色,下面会结合2X2的实际情况讲述启动流程。
飞桨的参数服务器的训练分为3个阶段, 一是将PServer全部启动, PServer会根据用户定义的监听端口启动监听服务,等待Worker连接;二是启动全部Worker节点,Worker节点会根据配置的Pserver的端口号跟每一个PServer进行连接检查,确保能够顺利连接后,进行参数的初始化和同步;三是启动训练流程,通过跟多个PServer的通信完成整个训练流程。
假设我们有两台机器,想要在每台机器上分别启动一个server进程以及一个worker进程,完成2x2(2个参数服务器,2个训练节点)的参数服务器模式分布式训练,按照如下步骤操作。
启动server
机器A,IP地址是10.89.176.11,通信端口是36000,配置如下环境变量后,运行训练的入口程序:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=PSERVER
export POD_IP=10.89.176.11 # node A:10.89.176.11
export PADDLE_PORT=36000
export PADDLE_TRAINERS_NUM=2
python -u train.py --is_cloud=1
应能在日志中看到如下输出:
I0318 21:47:01.298220 188592128 grpc_server.cc:470] Server listening on 127.0.0.1:36000 selected port: 36000
查看系统进程
8624 | ttys000 | 0:02.31 | python -u train.py --is_cloud=1
查看系统进程及端口占用:
python3.7 | 8624 | paddle | 8u | IPv6 | 0xe149b87d093872e5 | 0t0 | TCP | localhost:36000 (LISTEN)
也可以看到我们的server进程8624的确在36000端口开始了监听,等待worker的通信。
机器B,IP地址是10.89.176.12,通信端口是36000,配置如下环境变量后,运行训练的入口程序:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=PSERVER
export POD_IP=10.89.176.12 # node B: 10.89.176.12
export PADDLE_PORT=36000
export PADDLE_TRAINERS_NUM=2
python -u train.py --is_cloud=1
也可以看到相似的日志输出与进程状况。(进行验证时,请务必确保IP与端口的正确性)
启动worker
接下来我们分别在机器A与B上开启训练进程。配置如下环境变量并开启训练进程:
机器A:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=TRAINER
export PADDLE_TRAINERS_NUM=2
export PADDLE_TRAINER_ID=0 # node A:trainer_id = 0
python -u train.py --is_cloud=1
机器B:
export PADDLE_PSERVERS_IP_PORT_LIST="10.89.176.11:36000,10.89.176.12:36000"
export TRAINING_ROLE=TRAINER
export PADDLE_TRAINERS_NUM=2
export PADDLE_TRAINER_ID=1 # node B: trainer_id = 1
python -u train.py --is_cloud=1
运行该命令时,若Pserver还未就绪,可在日志输出中看到如下信息:
server not ready, wait 3 sec to retry…
not ready endpoints:[‘10.89.176.11:36000’, ‘10.89.176.12:36000’]
Worker进程将持续等待,直到Pserver开始监听,或等待超时。
当Pserver都准备就绪后,可以在日志输出看到如下信息:
I0317 11:38:48.099179 16719 communicator.cc:271] Communicator start
I0317 11:38:49.838711 16719 rpc_client.h:107] init rpc client with trainer_id 0
至此,分布式训练启动完毕,开始训练。
参数服务器训练数据切分
飞桨的参数服务器训练目前主要是数据并行模式。也就是说, 我们是通过增加训练节点来提高训练数据的并行度的, 因此需要对数据进行划分,即将全部的训练数据均匀的分成Worker个数份,每一个Worker需要分配全部训练数据中的一份,每个Worker节点训练自己的一份数据,参数由PServer端完成聚合和更新。我们要确保每个节点都能拿到数据,并且希望每个节点的数据同时满足:各个节点数据无重复和各个节点数据数量均匀。
Fleet提供了split_files()的接口,输入值是一个稳定的目录List,随后该函数会根据节点自身的编号拿到相应的数据文件列表,训练数据在同一个目录下,使用该接口,给各个进程(扮演不同的训练节点)分配不同的数据文件。
file_list = [
str(args.train_files_path) + "/%s" % x
for x in os.listdir(args.train_files_path)
]
# 请确保每一个训练节点都持有不同的训练文件
# 当我们用本地多进程模拟分布式时,每个进程需要拿到不同的文件
# 使用 fleet.split_files 可以便捷的以文件为单位分配训练样本
files= fleet.split_files(file_list)
基于得到的files, 每个节点开始独立进行数据读取和训练。如果数据在HDFS上,可以根据files列表将数据下载会本地进行读取。如果数据在本地,则可直接根据files列表进行读取。
详细训练代码示例
异步模式分布式训练代码的详细说明如下所示。
# 根据环境变量确定当前机器/进程在分布式训练中的角色分配Worker/PSERVER
# 然后使用 fleet api的 init()方法初始化这个节点
role = role_maker.PaddleCloudRoleMaker()
fleet.init(role)
# 设置分布式运行模式为异步(async),同时将参数进行切分,以分配到不同的节点
strategy = StrategyFactory.create_async_strategy()
ctr_model = CTR()
inputs = ctr_model.input_data(params)
avg_cost, auc_var, batch_auc_var = ctr_model.net(inputs, params)
optimizer = fluid.optimizer.Adam(params.learning_rate)
# 配置分布式的optimizer,传入指定的strategy,构建program
optimizer = fleet.distributed_optimizer(optimizer, strategy)
optimizer.minimize(avg_cost)
# 根据节点角色,分别运行不同的逻辑
if fleet.is_server():
# 初始化及运行参数服务器节点
fleet.init_server()
fleet.run_server()
elif fleet.is_worker():
# 初始化工作节点
fleet.init_worker()
exe = fluid.Executor(fluid.CPUPlace())
# 初始化含有分布式流程的fleet.startup_program
exe.run(fleet.startup_program)
for epoch in range(params.epochs):
# 启动pyreader的异步训练线程
# PyRreader是飞桨提供的简洁易用的数据读取API接口,支持同步数据读取及异步数据读取,用户自行定义数据处理的逻辑后,以迭代器的方式传递给PyReader,完成训练的数据读取部分
reader.start()
batch_id = 0
try:
while True:
# 获取网络中,所需的输出,如loss、auc等
loss_val, auc_val, batch_auc_val = exe.run(
program=compiled_prog,
fetch_list=[
avg_cost.name, auc_var.name, batch_auc_var.name
])
loss_val = np.mean(loss_val)
auc_val = np.mean(auc_val)
batch_auc_val = np.mean(batch_auc_val)
# 每以上是关于分布式训练---参数服务器训练(飞桨paddle1.8)的主要内容,如果未能解决你的问题,请参考以下文章