Kubernetes 1.16.15升级到1.17.17
Posted saynaihe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes 1.16.15升级到1.17.17相关的知识,希望对你有一定的参考价值。
背景:
线上kubernetes环境使用kubeadm搭建.当时应该是1.15的kubeadm搭建的。稳定运行了近两年的时间。其中升级了一次大版本从1.15升级到1.16。进行过多次小版本升级。现在的版本为1.16.15。中间也曾想升级过版本到更高的版本,但是升级master的时候出现异常了,还好是三节点的master集群,就恢复到了1.16的版本。一直没有进行更高版本的升级。昨天总算是对集群下手升级了…
集群配置
| 主机名 | 系统 | ip |
|---|---|---|
| k8s-vip | slb | 10.0.0.37 |
| k8s-master-01 | centos7 | 10.0.0.41 |
| k8s-master-02 | centos7 | 10.0.0.34 |
| k8s-master-03 | centos7 | 10.0.0.26 |
| k8s-node-01 | centos7 | 10.0.0.36 |
| k8s-node-02 | centos7 | 10.0.0.83 |
| k8s-node-03 | centos7 | 10.0.0.40 |
| k8s-node-04 | centos7 | 10.0.0.49 |
| k8s-node-05 | centos7 | 10.0.0.45 |
| k8s-node-06 | centos7 | 10.0.0.18 |
Kubernetes升级过程
1. 参考官方文档
参照:https://kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
https://v1-17.docs.kubernetes.io/zh/docs/tasks/administer-cluster/kubeadm/kubeadm-upgrade/
kubeadm 创建的 Kubernetes 集群从 1.16.x 版本升级到 1.17.x 版本,以及从版本 1.17.x 升级到 1.17.y ,其中 y > x
2. 确认可升级版本与升级方案
yum list --showduplicates kubeadm --disableexcludes=kubernetes
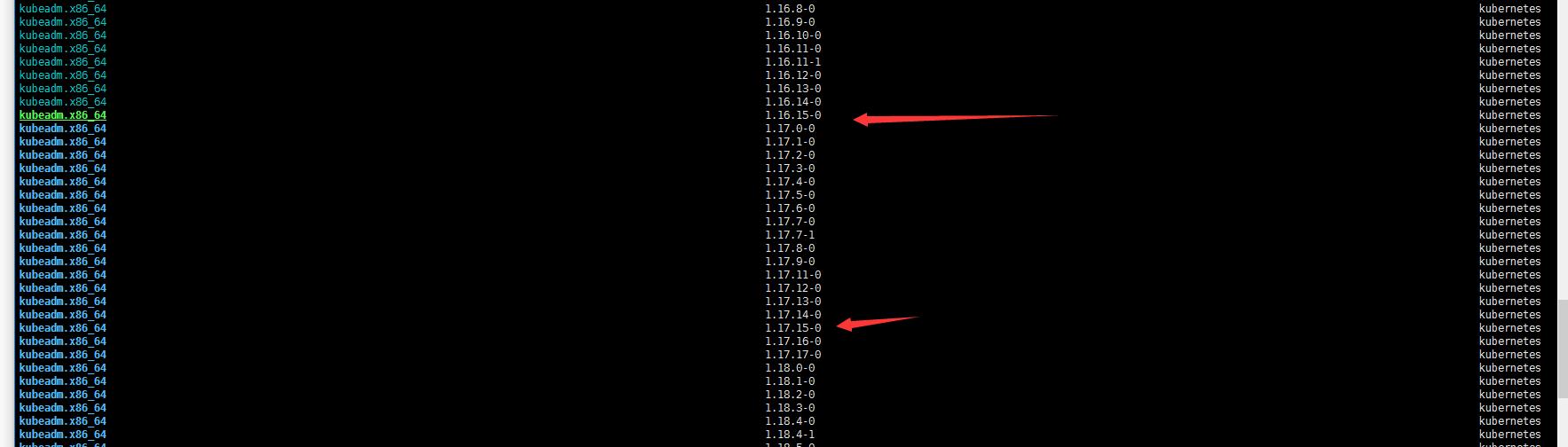
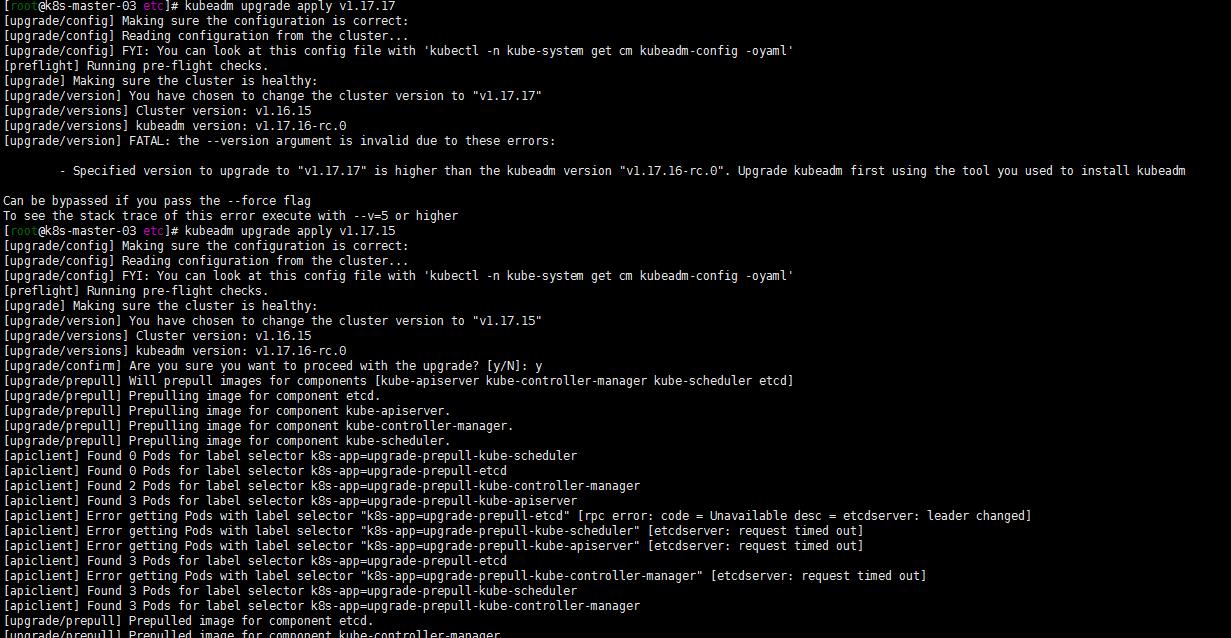
由于我的kubeadm版本是1.16.15 那我只能先升级到1.17.15 然后从1.17.15升级到1.17.17(先不考虑升级更高版本)。master节点有k8s-master-01 k8s-master-02 k8s-master-03三个节点,个人习惯一般不喜欢先动第一个,就直接从第三个节(sh-master-03)点入手了…
3. 升级k8s-master-03节点控制平面
yum install kubeadm-1.17.15-0 --disableexcludes=kubernetes
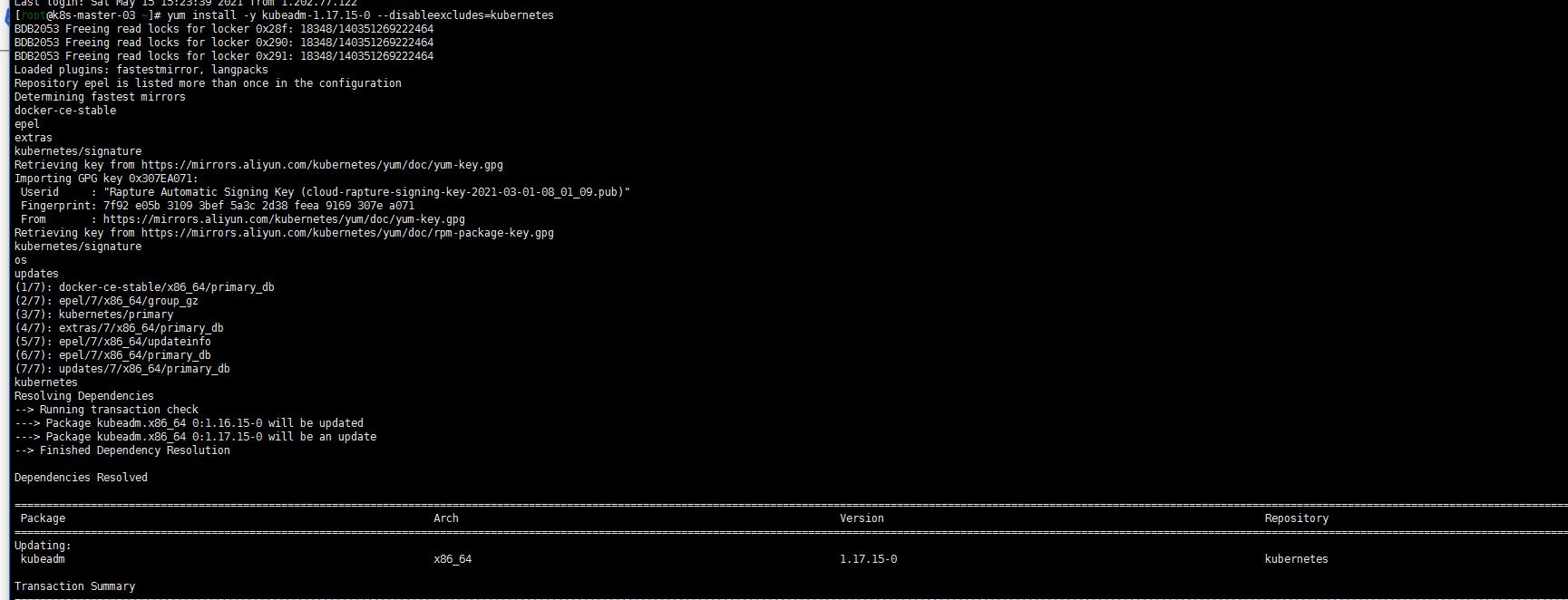
sudo kubeadm upgrade plan
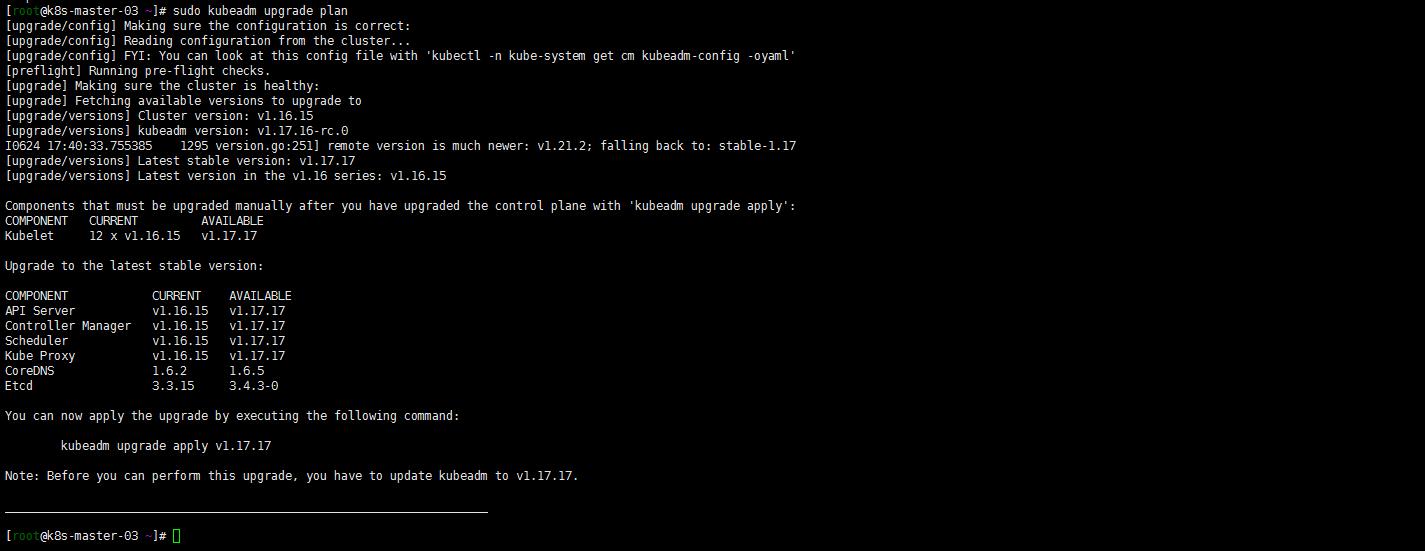
嗯 可以升级到1.17.17?试一下
kubeadm upgrade apply v1.17.17
不能升级到1.17.17 但是可以到1.17.16?但是要先升级kubeadm。怎么会是这样呢?如下是可以1.y到1.y+1版本的。

kubeadm upgrade apply v1.17.15
yum install -y kubelet-1.17.15-0 kubectl-1.17.15-0 --disableexcludes=kubernetes
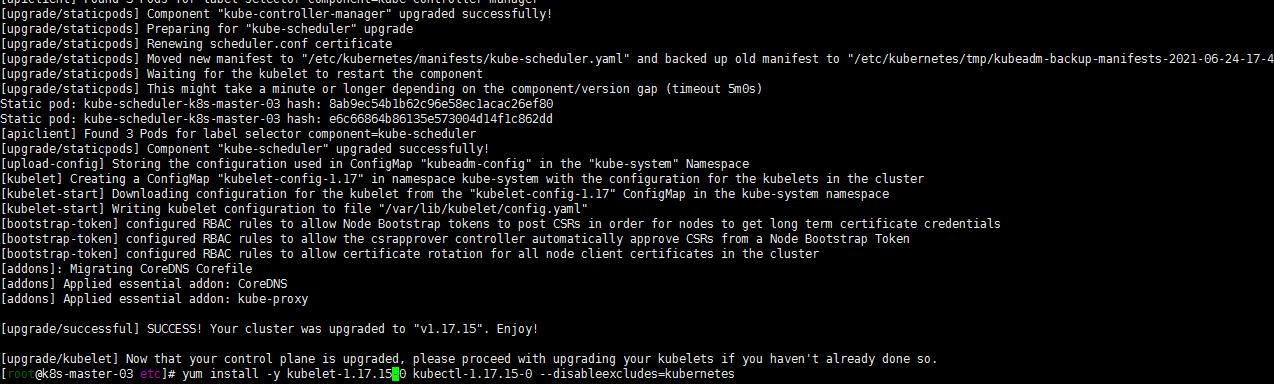
systemctl daemon-reload
sudo systemctl restart kubelet
嗯还是没有搞明白怎么就还是到1.17.16版本了,无伤大雅了。就先这样了!
注:当然了为了防止出现问题,应该是先把 /etc/kubernetes文件路径下配置文件备份一下!
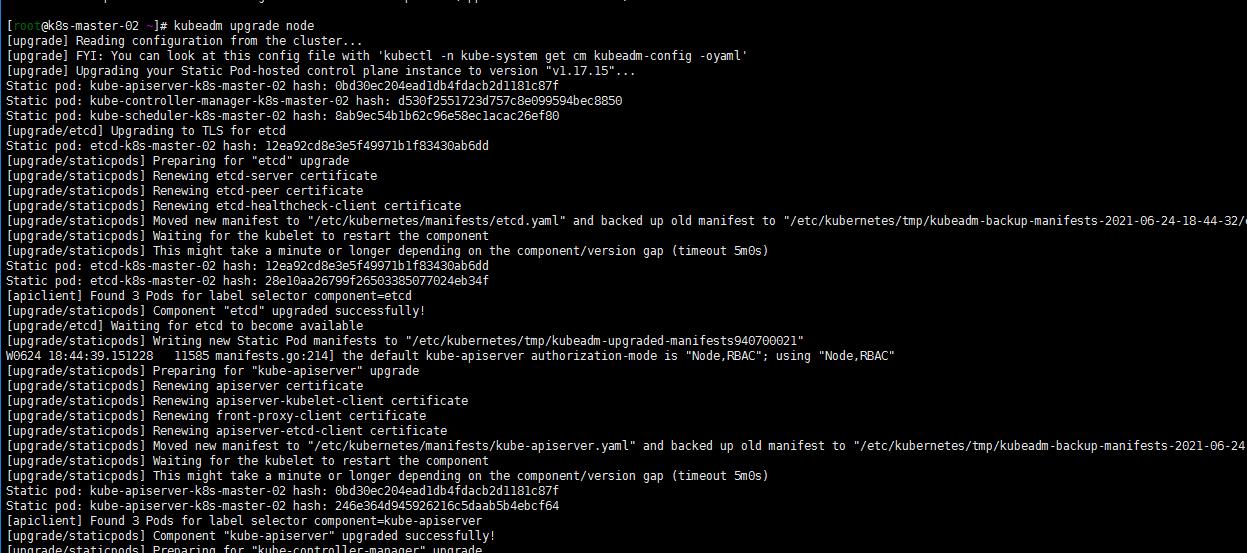
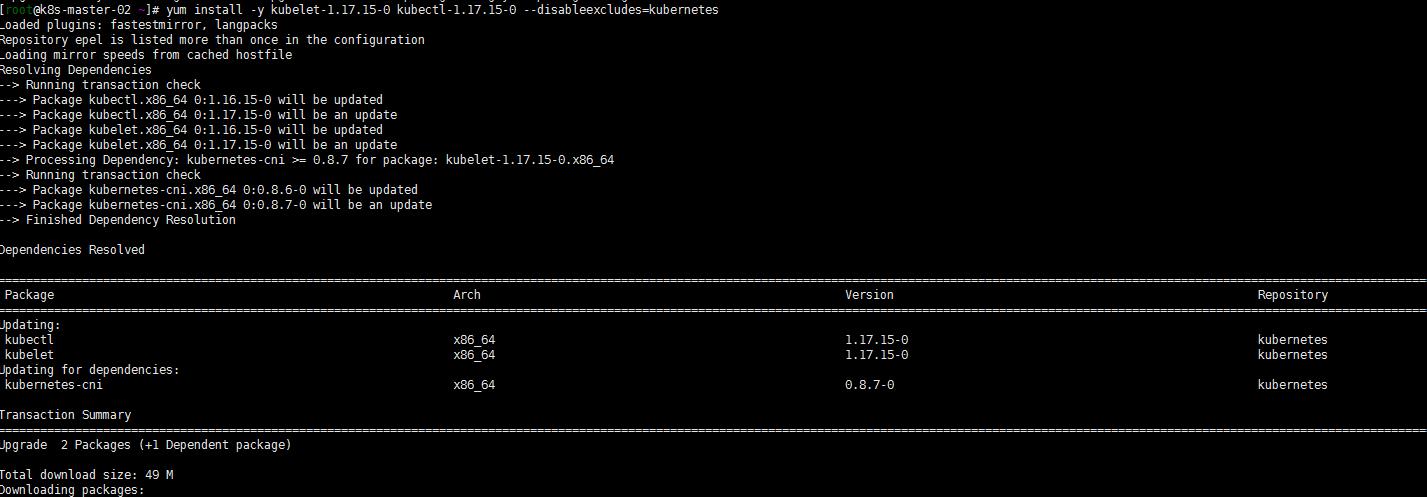
4. 升级其他控制平面(k8s-master-02 k8s-master-01)
其他两个master节点都执行一下命令:
yum install -y kubeadm-1.17.15-0 --disableexcludes=kubernetes
kubeadm upgrade node
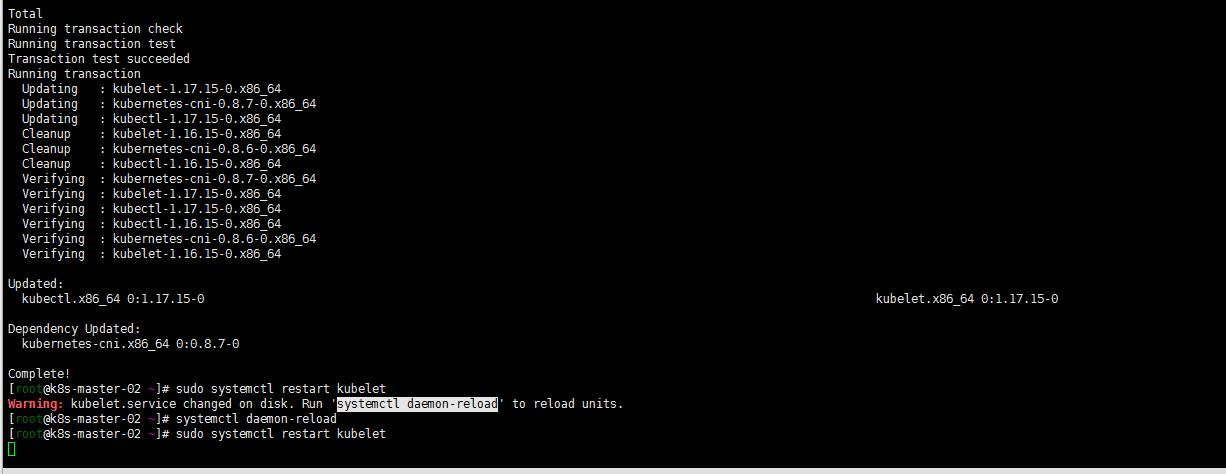
yum install -y kubelet-1.17.15-0 kubectl-1.17.15-0 --disableexcludes=kubernetes
systemctl daemon-reload
sudo systemctl restart kubelet
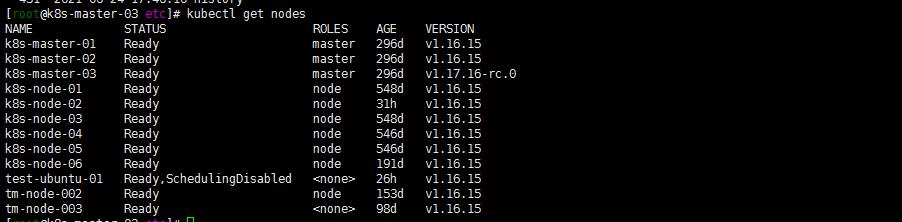
登陆任意一台master节点:
[root@k8s-master-03 ~]# kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master-01 Ready master 297d v1.17.15
k8s-master-02 Ready master 297d v1.17.15
k8s-master-03 Ready master 297d v1.17.16-rc.0
k8s-node-01 Ready node 549d v1.16.15
k8s-node-02 Ready node 2d5h v1.16.15
k8s-node-03 Ready node 549d v1.16.15
k8s-node-04 Ready node 547d v1.16.15
k8s-node-05 Ready node 547d v1.16.15
k8s-node-06 Ready node 192d v1.16.15
test-ubuntu-01 Ready,SchedulingDisabled <none> 47h v1.16.15
tm-node-002 Ready node 154d v1.16.15
tm-node-003 Ready <none> 99d v1.16.15
5. 继续升级小版本到1.17.17
同理,重复以上的步骤,小版本升级到1.17.17
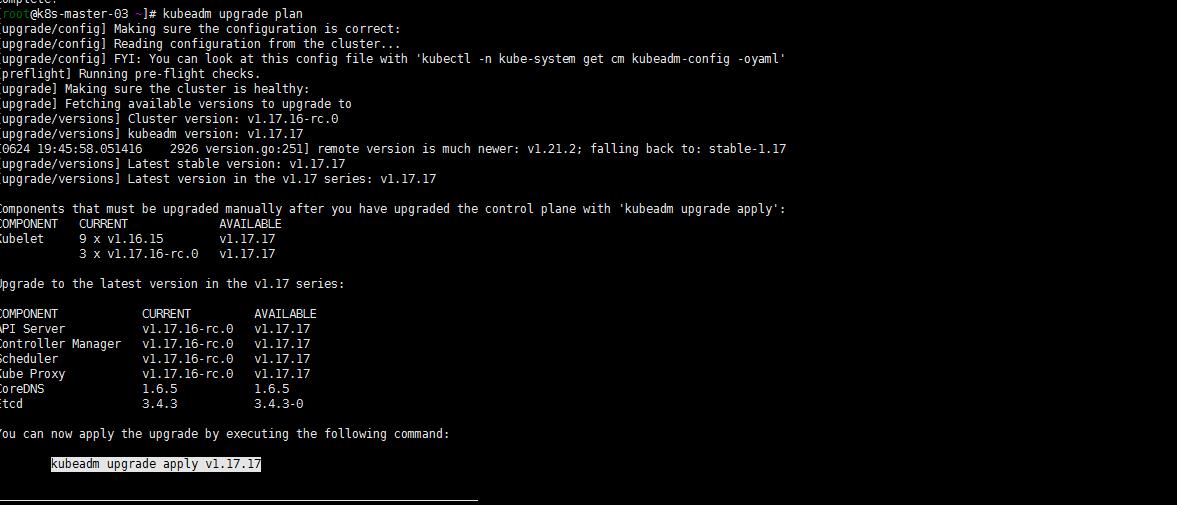
kubectl get nodes -o wide

注意:以上master-02 master-03控制平面节点升级忽略了腾空节点步骤
6. work节点的升级
所有work节点执行:
注:演示在k8s-node-03节点执行
yum install kubeadm-1.17.17 kubectl-1.17.17 kubelet-1.17.17 --disableexcludes=kubernetes
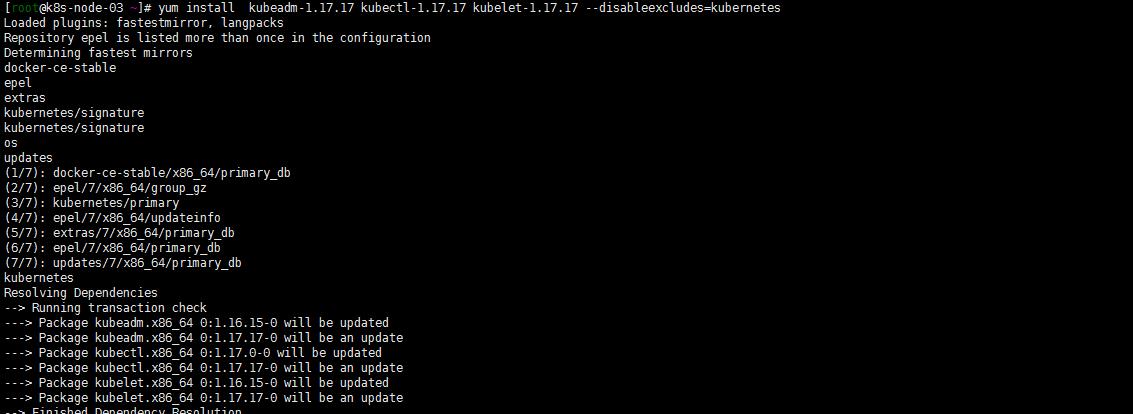
将节点设置为不可调度,并腾空节点:
kubectl drain k8s-node-03 --ignore-daemonsets
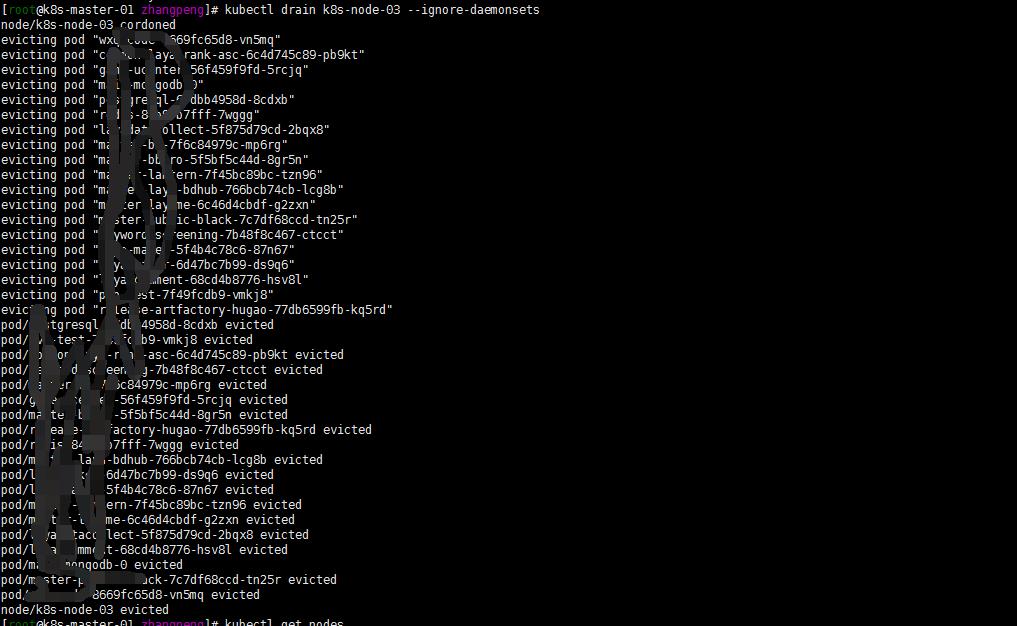
kubeadm upgrade node
sudo systemctl daemon-reload
sudo systemctl restart kubelet

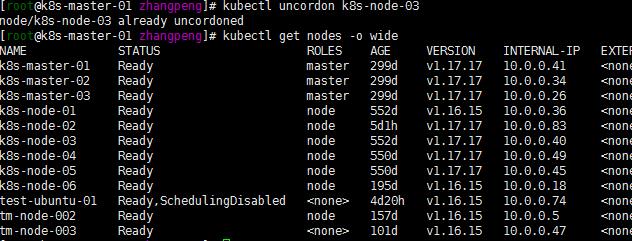
kubectl uncordon k8s-node-03
kubectl get nodes -o wide
注:后截的图already忽略,就看结果…,就先升级几个节点了。其他几点节点有时间再进行升级,估计也差不多,如有什么异常再进行整理分析!
7. 升级与使用中出现的一些小问题
1. clusterrole
还是有些小异常,比如:我的controller-manager的clusterrole system:kube-controller-manager的权限怎么就有问题了?

不知道当时是不是因为只升级了两个节点k8s-master-01节点造成的。在出现这个问题的时候我是升级了k8s-master-01节点,然后删除了clusterrole system:kube-controller-manager,然后把我kubernetes1.21的clusterrole搞过来apply了
kubectl get clusterrole system:kube-controller-manager -o yaml > 1.yaml
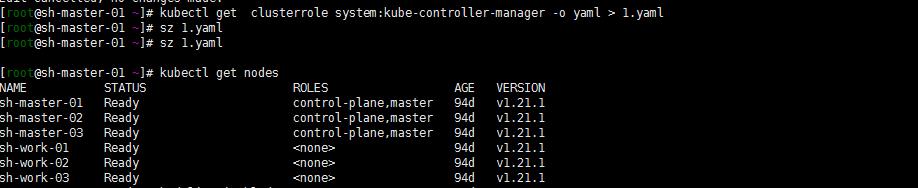
kubectl get clusterrole system:kube-controller-manager -o yaml >clusterrole.yaml
kubectl apply -f 1.yaml
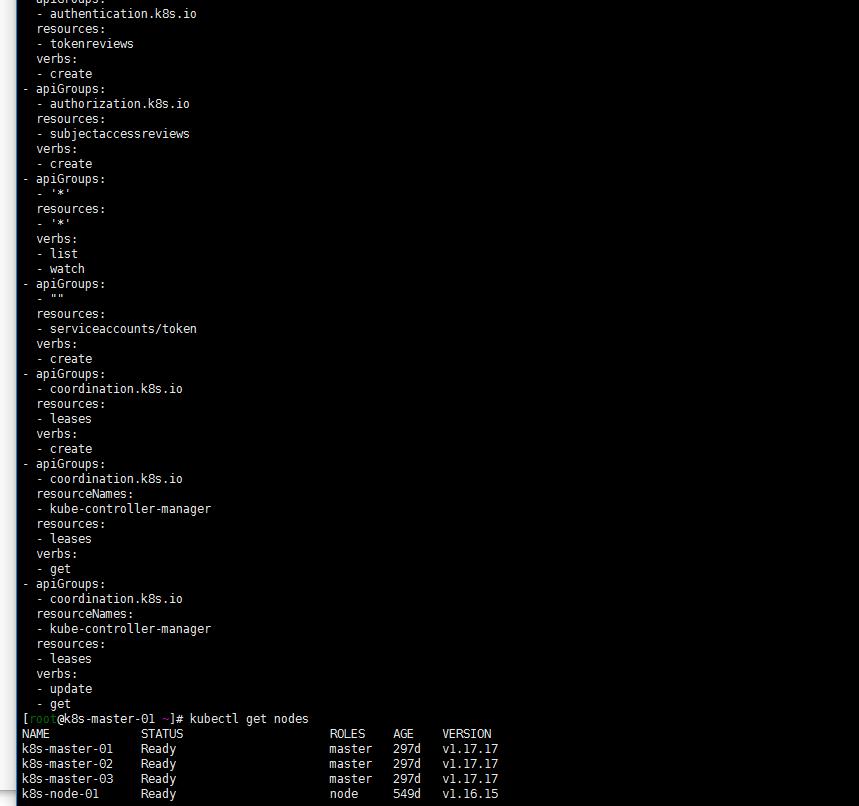
反正貌似就是解决了…clusterrole这东西看看仔细整一下。最近反正是有点懵了…
2. flannel的异常
还有一个问题是flannel的:
我的集群是1.15升级上来的。一直是没有问题的,但是新增加work节点后,分配到新节点的带探针的就会有各种诡异的问题.,要么探测不通过,要么重启反正各种问题…怎么回事呢?
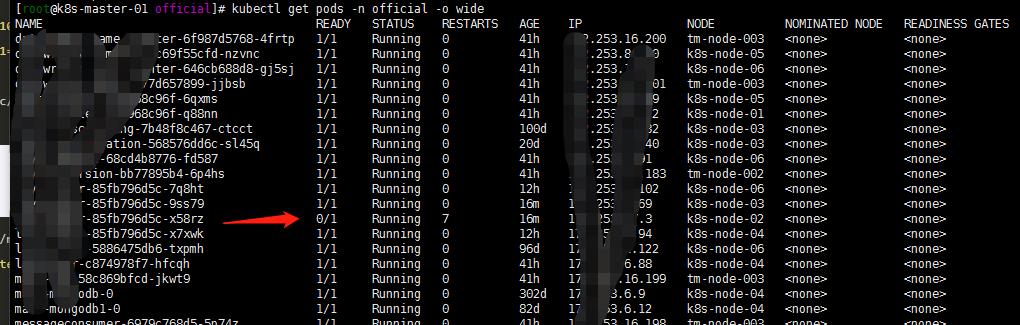
怀疑了一下flannel.登陆github flannel仓库看了一下:
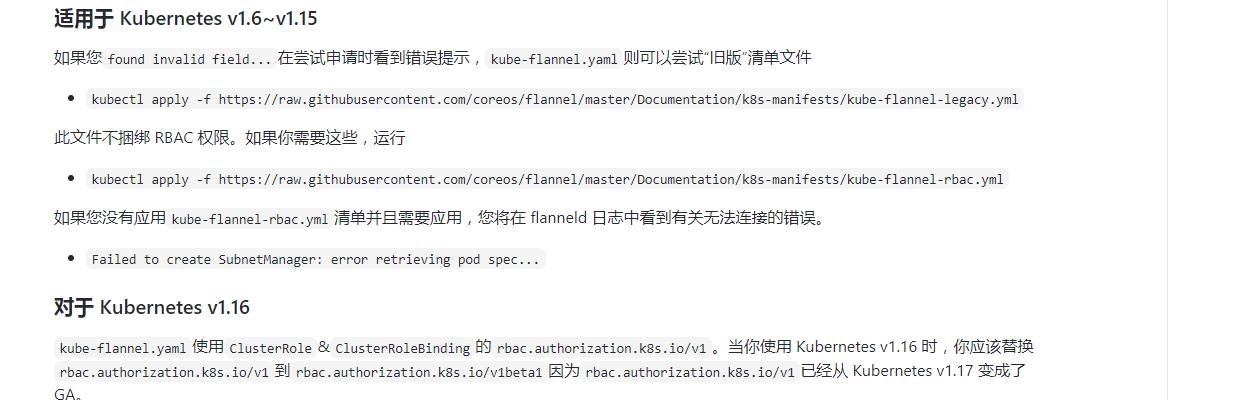
看了一下我的集群的flannel版本还都是v0.11。不管他了先升级一下flannel吧…
kubectl delete -f XXX.yaml(老的flannel插件配置文件)
官方下载kube-flannel.yaml文件
修改network

注:当然了如果还是1.16也要修改一下rbac的 apiversion.
kubectl apply -f kube-flannel.yaml
修改后是基本没有出现以往探针失败重启的现象了。
3. Prometheus的报错
kubernetes版本对应Prometheus的版本:
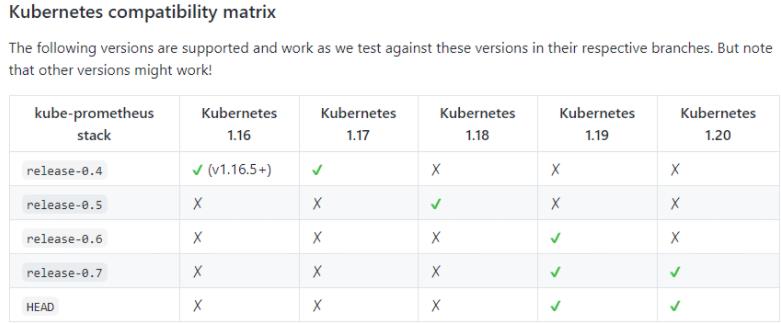
嗯我的是早期的0.4分支,kubernetes1.17还可以用。不过control-manager scheduler的报警都出现异常问题了…参照https://duiniwukenaihe.github.io/2021/05/14/Kubernetes-1.20.5-upgrade1.21.0%E5%90%8E%E9%81%97%E7%97%87/修改kube-controller-manage kube-scheduler配置文件。当然了。我如果升级到1.18或者更高的版本就刺激了…的切换分支进行重新配置还是什么呢?
后记:
- 尽量去参考官方文档
- 记得升级网络组件
- api如有变化,记得修改相关组件version或者配置文件
以上是关于Kubernetes 1.16.15升级到1.17.17的主要内容,如果未能解决你的问题,请参考以下文章