Kubernetes集群添加运行containerd runtime的 work节点
Posted saynaihe
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Kubernetes集群添加运行containerd runtime的 work节点相关的知识,希望对你有一定的参考价值。
背景:
kuberadm搭建的1.15的初始集群,参见:2020-07-22-腾讯云-slb-kubeadm高可用集群搭建
,嗯后面进行了持续的升级:2019-09-23-k8s-1.15.3-update1.16.0,1.16版本最后持续小版本升级到了1.16.15(小版本升级唯写升级过程)。最后升级版本到了1.17.17:Kubernetes 1.16.15升级到1.17.17。计划后面还是会持续升级到最新的1.21的。只不过最近线上有项目在测试。升级部分先暂停,近期准备先扩容一下集群。由于搭建1.20.5集群测试的时候使用了containerd跑了下也还好。就想添加一个containerd的 work节点了。后面有时间逐步替换环境内的模块。当然了节点替换主要是早期的work节点都采用了8核心16G内存的腾讯云cvm。开始的时候资源还是能满足的,到了现在了pod的资源经过压测和各种测试都逐步调高了资源的request 和 limit。相应的,资源的调度优化方面节点就有些超卖oom的问题了,就准备添加下16核心32G内存的cvm节点!当然了master节点和其他work节点的docker runtime节点还没有进行替换!
work节点基本信息:
| 系统 | ip | 内核 |
|---|---|---|
| centos8.2 | 10.0.4.48 | 4.18 |
1. work节点初始化:
基本参照:centos8+kubeadm1.20.5+cilium+hubble环境搭建完成系统的初始化。
1. 更改主机名:
hostnamectl set-hostname sh02-node-01
先说一下自己的集群和命名:各种环境位于腾讯云上海区。线上kubernetes环境位于私网下上海3区,命名规则是k8s-node-0x。这次的10.0.4.48位于上海2区。区分下区域命名吧…就sh02-node-0x命名吧。以后不同区域的就直接sh0x去区分吧。还是有必要区分下区域的(过去太集中与上海3区了,现在也必要打乱下区域,增加一些容灾的可能性…但是腾讯云的网络貌似没有什么用,之前出问题也基本都出问题了…以后如果能业务量上来还是搞一下啊多地域或者多云的环境)。
2. 关闭swap交换分区
swapoff -a
sed -i 's/.*swap.*/#&/' /etc/fstab
3. 关闭selinux
setenforce 0
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=enforcing/SELINUX=disabled/g" /etc/selinux/config
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/sysconfig/selinux
sed -i "s/^SELINUX=permissive/SELINUX=disabled/g" /etc/selinux/config
4. 关闭防火墙
systemctl disable --now firewalld
chkconfig firewalld off
5. 调整文件打开数等配置
cat> /etc/security/limits.conf <<EOF
* soft nproc 1000000
* hard nproc 1000000
* soft nofile 1000000
* hard nofile 1000000
* soft memlock unlimited
* hard memlock unlimited
EOF
6. yum update
yum update
yum -y install gcc bc gcc-c++ ncurses ncurses-devel cmake elfutils-libelf-devel openssl-devel flex* bison* autoconf automake zlib* fiex* libxml* ncurses-devel libmcrypt* libtool-ltdl-devel* make cmake pcre pcre-devel openssl openssl-devel jemalloc-devel tlc libtool vim unzip wget lrzsz bash-comp* ipvsadm ipset jq sysstat conntrack libseccomp conntrack-tools socat curl wget git conntrack-tools psmisc nfs-utils tree bash-completion conntrack libseccomp net-tools crontabs sysstat iftop nload strace bind-utils tcpdump htop telnet lsof
7. ipvs添加(centos8内核默认4.18.内核4.19不包括4.19的是用这个)
:> /etc/modules-load.d/ipvs.conf
module=(
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
br_netfilter
)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
内核大于等于4.19的
:> /etc/modules-load.d/ipvs.conf
module=(
ip_vs
ip_vs_rr
ip_vs_wrr
ip_vs_sh
nf_conntrack
br_netfilter
)
for kernel_module in ${module[@]};do
/sbin/modinfo -F filename $kernel_module |& grep -qv ERROR && echo $kernel_module >> /etc/modules-load.d/ipvs.conf || :
done
加载ipvs模块
systemctl daemon-reload
systemctl enable --now systemd-modules-load.service
查询ipvs是否加载
# lsmod | grep ip_vs
ip_vs_sh 16384 0
ip_vs_wrr 16384 0
ip_vs_rr 16384 0
ip_vs 172032 6 ip_vs_rr,ip_vs_sh,ip_vs_wrr
nf_conntrack 172032 6 xt_conntrack,nf_nat,xt_state,ipt_MASQUERADE,xt_CT,ip_vs
nf_defrag_ipv6 20480 4 nf_conntrack,xt_socket,xt_TPROXY,ip_vs
libcrc32c 16384 3 nf_conntrack,nf_nat,ip_vs
8. 优化系统参数(不一定是最优,各取所需)
注:嗯 特别强调最好把ipv6关闭了…反正我后面是吃了这个亏了。
cat <<EOF > /etc/sysctl.d/k8s.conf
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
net.ipv4.neigh.default.gc_stale_time = 120
net.ipv4.conf.all.rp_filter = 0
net.ipv4.conf.default.rp_filter = 0
net.ipv4.conf.default.arp_announce = 2
net.ipv4.conf.lo.arp_announce = 2
net.ipv4.conf.all.arp_announce = 2
net.ipv4.ip_forward = 1
net.ipv4.tcp_max_tw_buckets = 5000
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_max_syn_backlog = 1024
net.ipv4.tcp_synack_retries = 2
# 要求iptables不对bridge的数据进行处理
net.bridge.bridge-nf-call-ip6tables = 1
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-arptables = 1
net.netfilter.nf_conntrack_max = 2310720
fs.inotify.max_user_watches=89100
fs.may_detach_mounts = 1
fs.file-max = 52706963
fs.nr_open = 52706963
vm.overcommit_memory=1
vm.panic_on_oom=0
vm.swappiness = 0
EOF
sysctl --system
9. containerd安装
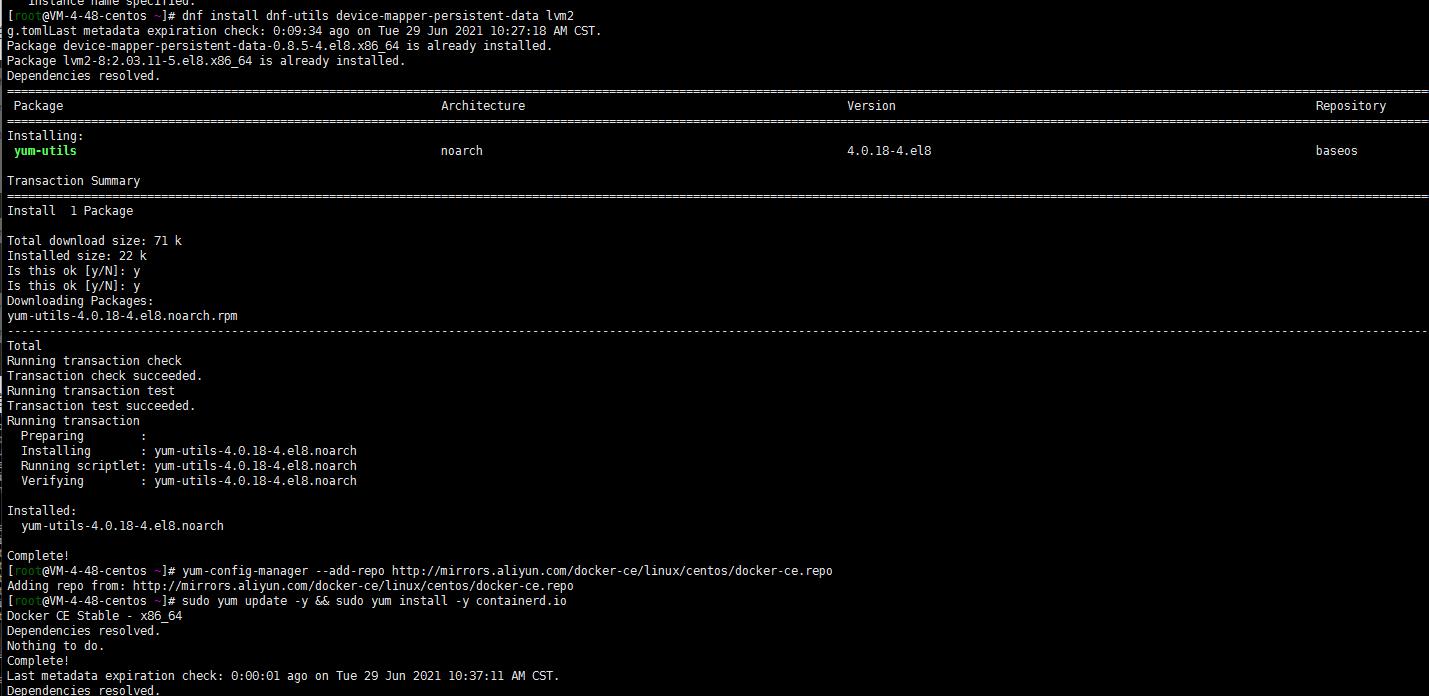
dnf install dnf-utils device-mapper-persistent-data lvm2
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sudo yum update -y && sudo yum install -y containerd.io
containerd config default > /etc/containerd/config.toml
# 替换 containerd 默认的 sand_box 镜像,并将SystemdCgroup设置为true。编辑 /etc/containerd/config.toml
sandbox_image = "registry.aliyuncs.com/google_containers/pause:3.2"
[plugins."io.containerd.grpc.v1.cri".containerd.runtimes.runc.options]
SystemdCgroup = true
# 重启containerd
$ systemctl daemon-reload
$ systemctl restart containerd
10. 配置 CRI 客户端 crictl
cat <<EOF > /etc/crictl.yaml
runtime-endpoint: unix:///run/containerd/containerd.sock
image-endpoint: unix:///run/containerd/containerd.sock
timeout: 10
debug: false
EOF

11. 安装 Kubeadm(centos8没有对应yum源使用centos7的阿里云yum源)
cat <<EOF > /etc/yum.repos.d/kubernetes.repo
[kubernetes]
name=Kubernetes
baseurl=http://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64
enabled=1
gpgcheck=0
repo_gpgcheck=0
gpgkey=http://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg http://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg
EOF
# 删除旧版本,如果安装了
yum remove kubeadm kubectl kubelet kubernetes-cni cri-tools socat
# 查看所有可安装版本 下面两个都可以啊
# yum list --showduplicates kubeadm --disableexcludes=kubernetes
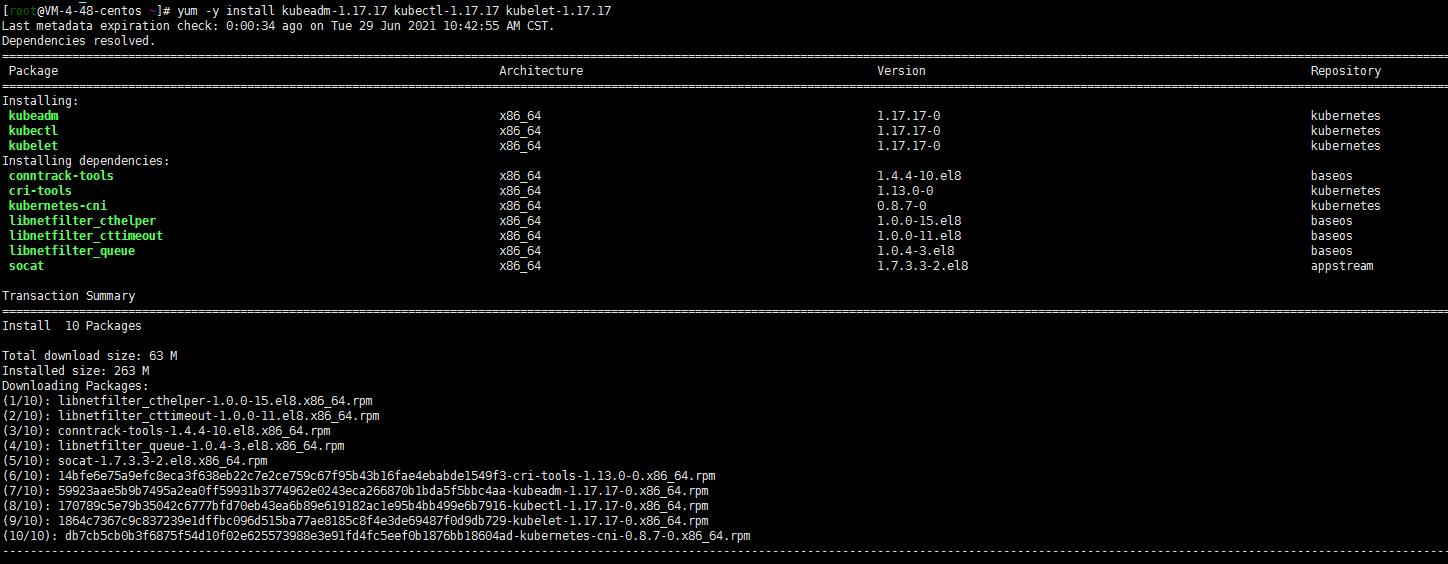
# 安装指定版本用下面的命令
# yum -y install kubeadm-1.17.17 kubectl-1.17.17 kubelet-1.17.17
# 开机自启
systemctl enable kubelet.service
12. 修改kubelet配置
vi /etc/sysconfig/kubelet
KUBELET_EXTRA_ARGS= --cgroup-driver=systemd --container-runtime=remote --container-runtime-endpoint=/run/containerd/containerd.sock
13 . journal 日志相关避免日志重复搜集,浪费系统资源(根据个人需求设置)
sed -ri 's/^\\$ModLoad imjournal/#&/' /etc/rsyslog.conf
sed -ri 's/^\\$IMJournalStateFile/#&/' /etc/rsyslog.conf
sed -ri 's/^#(DefaultLimitCORE)=/\\1=100000/' /etc/systemd/system.conf
sed -ri 's/^#(DefaultLimitNOFILE)=/\\1=100000/' /etc/systemd/system.conf
sed -ri 's/^#(UseDNS )yes/\\1no/' /etc/ssh/sshd_config
journalctl --vacuum-size=200M
2. master节点生成token与token-ca-cert-hash(任一控制平面节点)
[root@k8s-master-01 ~]# kubeadm token create
W0629 13:59:57.505803 16857 validation.go:28] Cannot validate kube-proxy config - no validator is available
W0629 13:59:57.505843 16857 validation.go:28] Cannot validate kubelet config - no validator is available
8nyjtd.xeza5fz4yitj62sx
[root@k8s-master-01 ~]# kubeadm token list
TOKEN TTL EXPIRES USAGES DESCRIPTION EXTRA GROUPS
8nyjtd.xeza5fz4yitj62sx 23h 2021-06-30T13:59:57+08:00 authentication,signing <none> system:bootstrappers:kubeadm:default-node-token
[root@k8s-master-01 ~]# openssl x509 -pubkey -in /etc/kubernetes/pki/ca.crt | openssl rsa -pubin -outform der 2>/dev/null | openssl dgst -sha256 -hex | sed 's/^.* //'
56ccafb865957c0692f5737cd8778553910c1049ef238a7781b7a39f5fd3a99a
3. 将work节点加入集群
kubeadm join 10.0.0.37:6443 --token 8nyjtd.xeza5fz4yitj62sx --discovery-token-ca-cert-hash sha256:56ccafb865957c0692f5737cd8778553910c1049ef238a7781b7a39f5fd3a99a
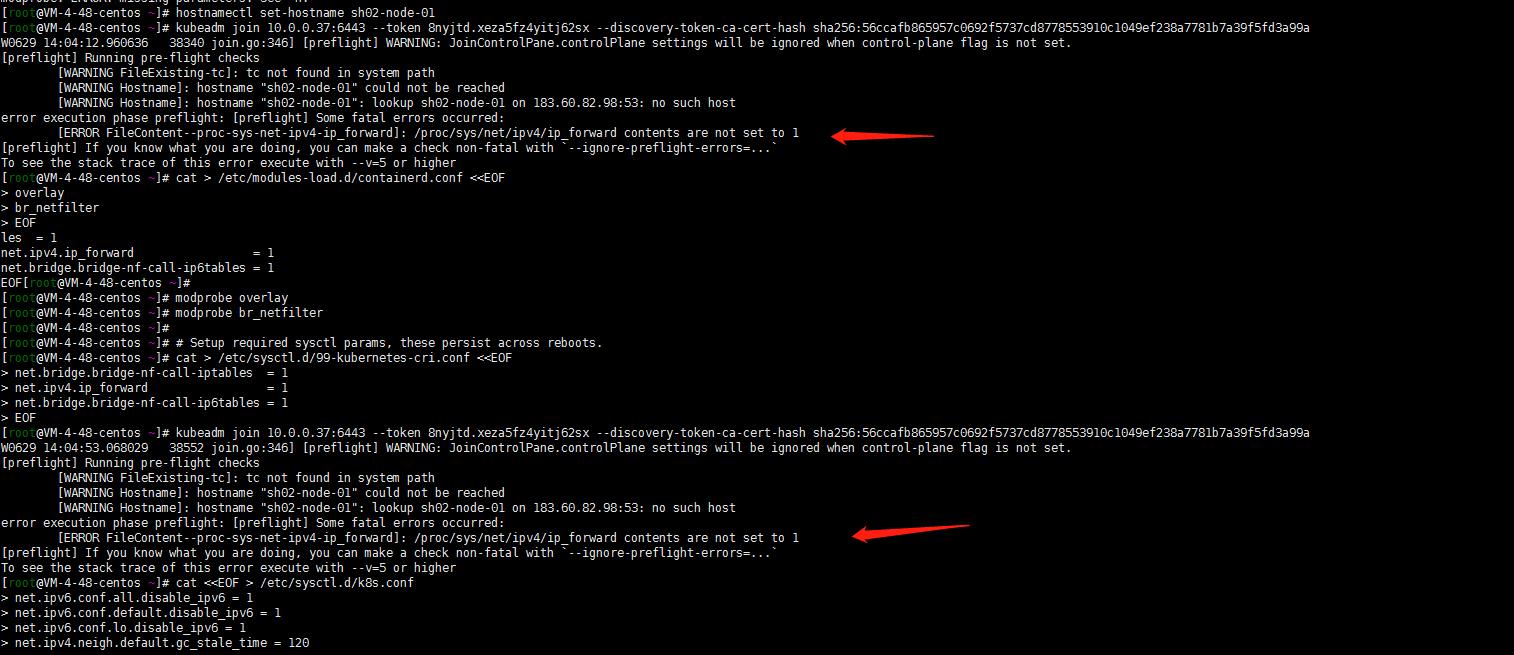
特意强调一下ipv4转发开启!当然了还有屏蔽了ipv6(当然了我这里没有先更改主机名和优化系统参数。执行了前面的步骤不会出这样的问题的!)
最终work节点如下:
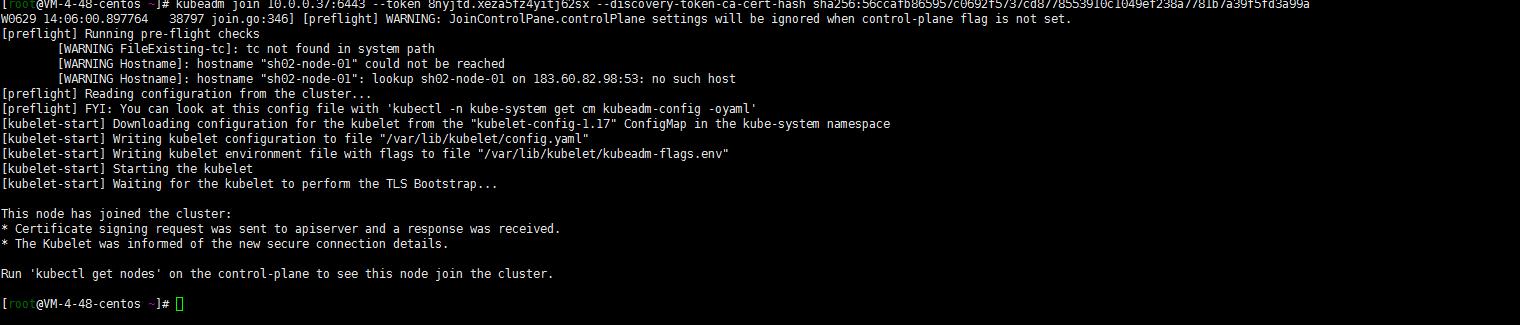
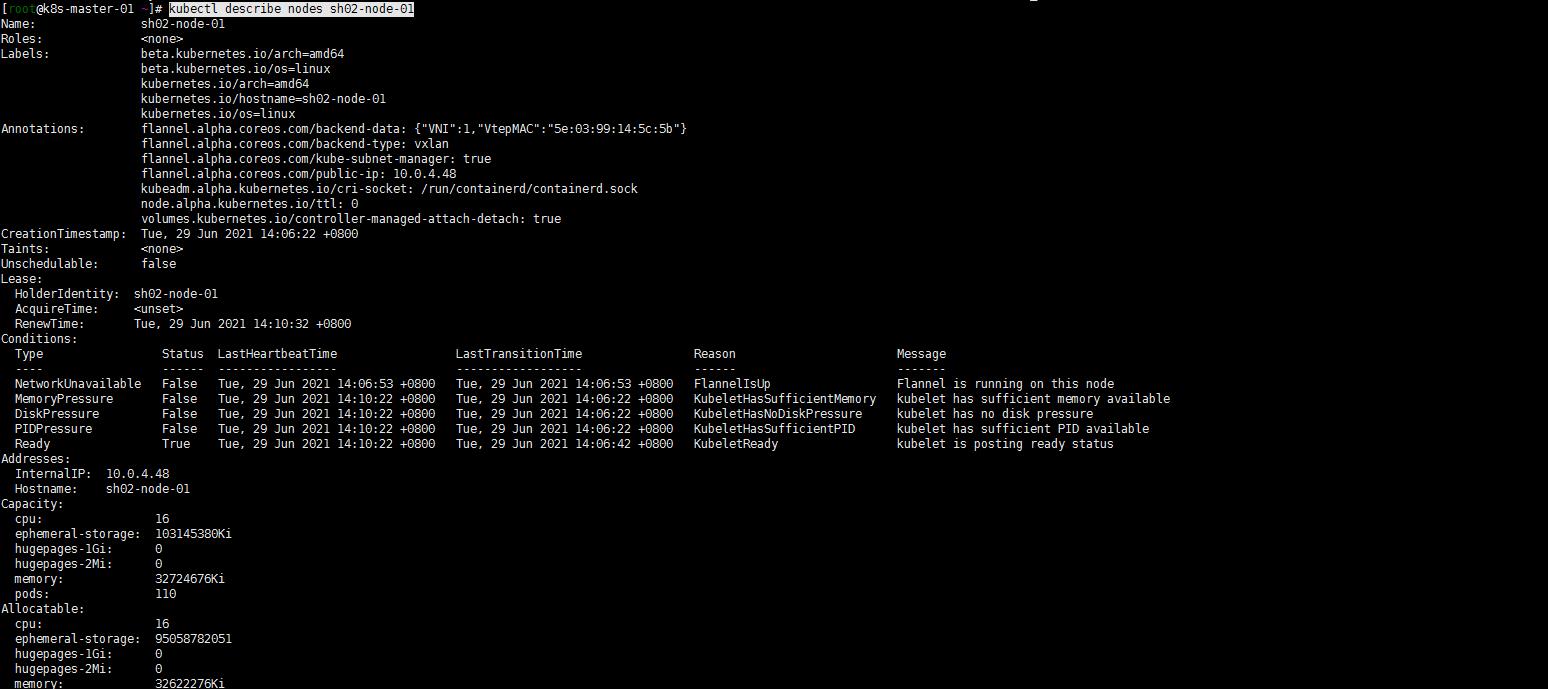
4. master节点验证sh02-node-01节点加入
kubectl get nodes -o wide
kubectl describe nodes sh02-node-01

5. 接下来的:
1. 将tm-node-002节点踢出集群
我的tm-node-002节点是临时加的4核心8g内存,嗯先把他设置为不可调度然后把他踢出集群
[root@k8s-master-01 ~]# kubectl cordon tm-node-002
node/tm-node-002 cordoned

test-ubuntu-01忽略只是为了让开发能直接连kubernetes集群网络的
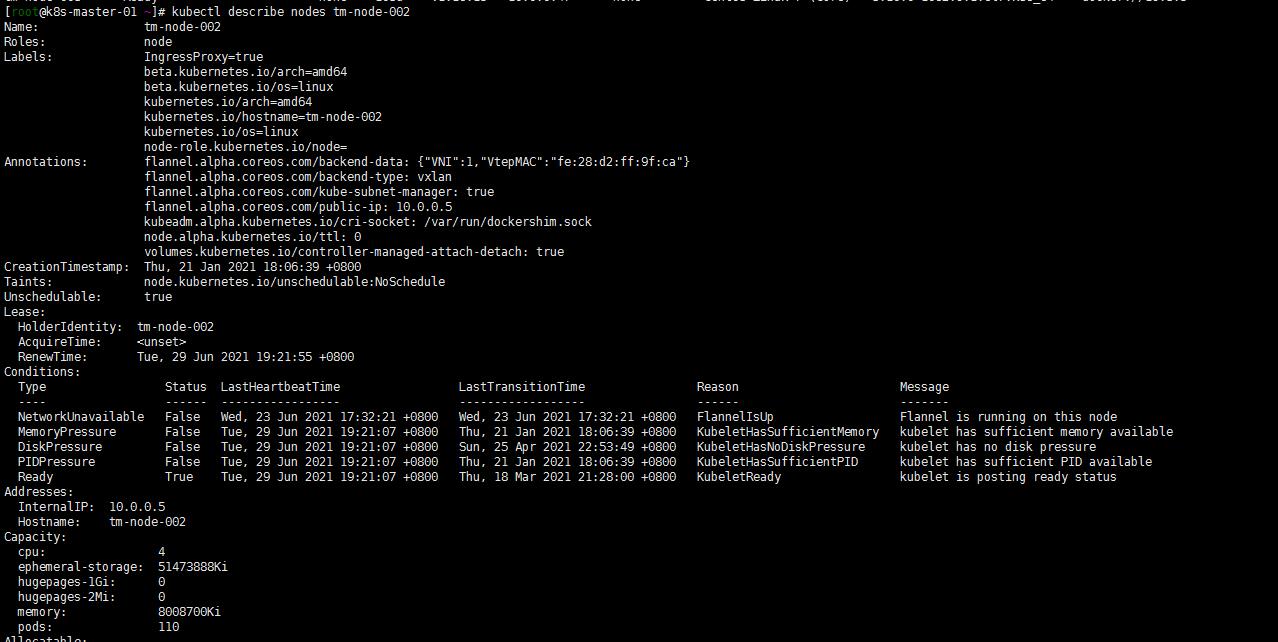
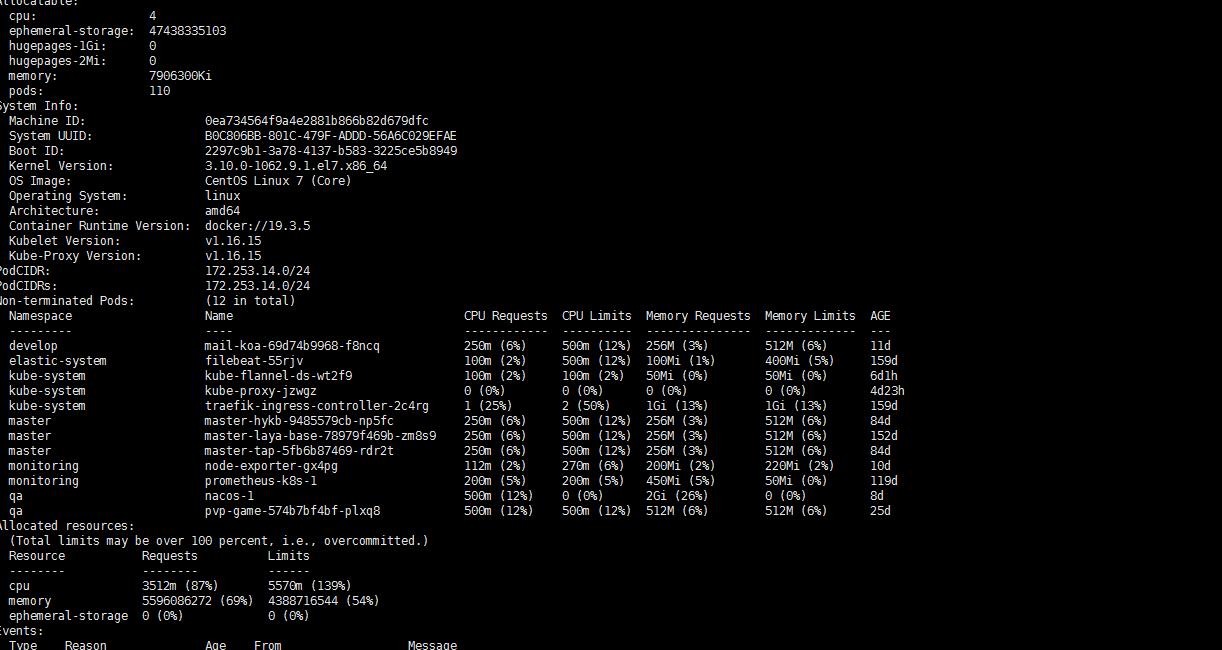
然后查看tm-node-002节点的pod分布:
kubectl describe node sh02-node-01
2. 重新调度一个pod
1. 重新调度一个pod(nacos-1 pod)
就讲nacos pod杀掉重新调度下吧(其他节点资源都分配较多了,调度策略怎么样也会分配到我新加入的sh02-node-01节点吧?)
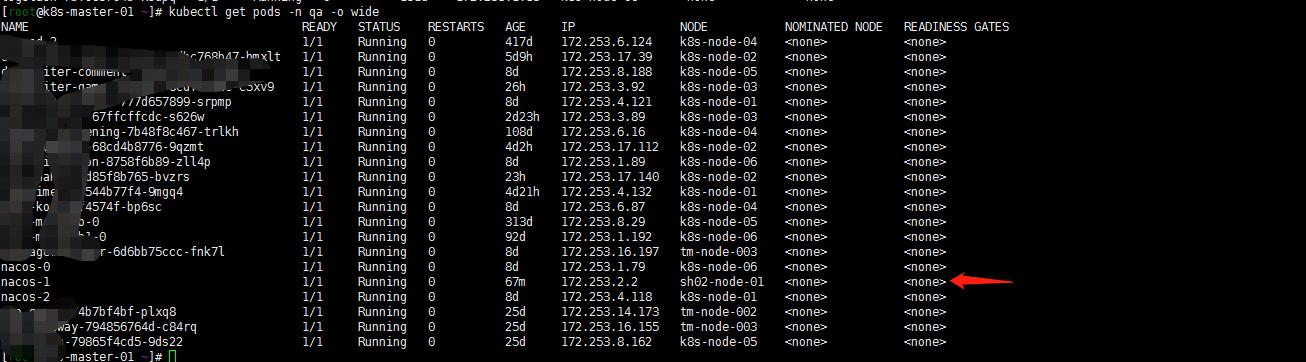
[root@k8s-master-01 ~]# kubectl delete pods nacos-1 -n qa
pod "nacos-1" deleted
[root@k8s-master-01 ~]# kubectl get pods -n qa -o wide
2. nfs-client的遗忘
看到 nacos-1调度到了sh02-node-01节点。但是开始并没有能running。怎么回事呢? 我的storageclass用的是nfs。sh02-node-01并没有能安装nfs客户端,故未能调度挂载pvc:
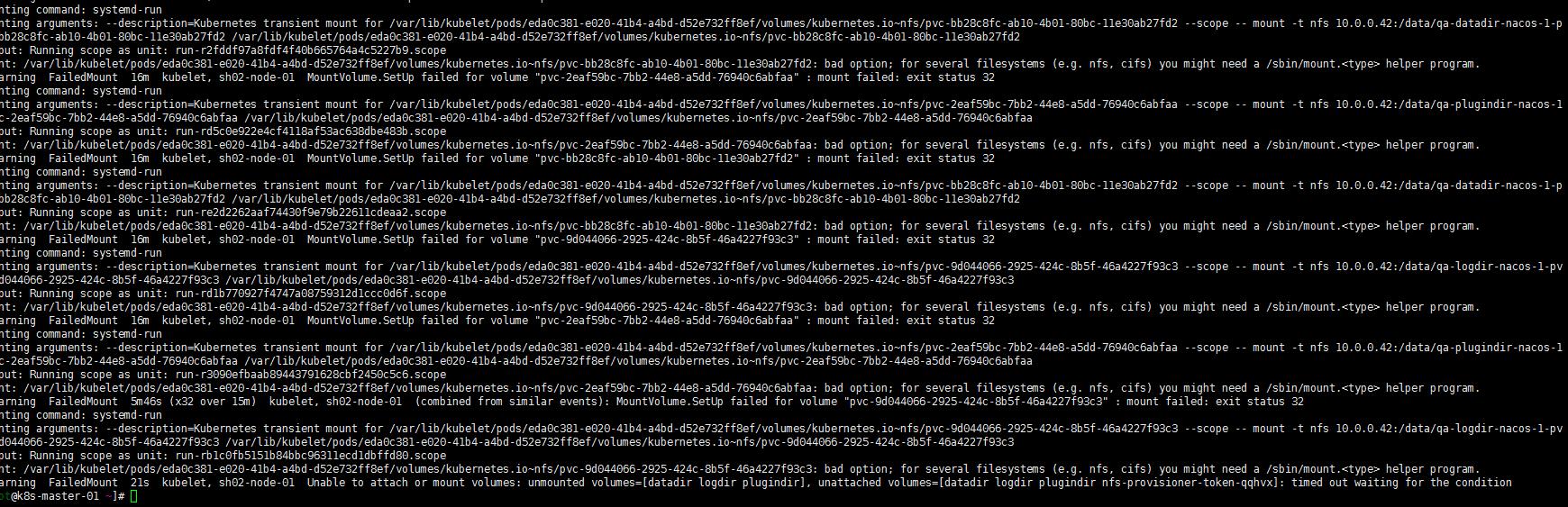
[root@sh02-node-01 ~] yum install nfs-*
[root@sh02-node-01 ~] systemctl restart kubelet
注:反正我重启了一下kubelet。因为开始安装上nfs-client插件还是不管用,重启了kubelet就好了。
3. iptables的问题
kubectl logs -f nacos-01 -n qa
但是紧接着看了一眼nacos-1日志还是有报错。仔细看了眼怀疑iptables问题…嗯sh02-node-1开启了iptables
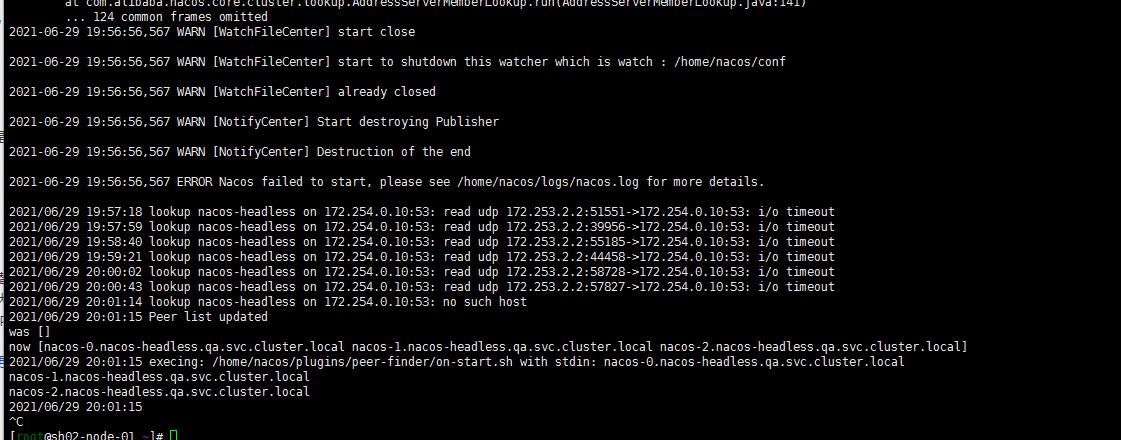
systemctl stop iptables
chkconfig iptables off
后记:
1. 验证一下docker 与containerd同时使用
2. 熟悉使用下ctr命令
3.还要持续升级,争取到1.21版本
4. storageclass看看有时间整成腾讯云的cbs(在其他环境中已验证过)
5. elasticsearch的存储我怎么能快速迁移呢?还是使用cos备份吗?没有想好
6. 当然了最终还是要containerd替换docker的
以上是关于Kubernetes集群添加运行containerd runtime的 work节点的主要内容,如果未能解决你的问题,请参考以下文章