论文泛读147ELMo 上下文嵌入的跨语言对齐
Posted 及时行樂_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了论文泛读147ELMo 上下文嵌入的跨语言对齐相关的知识,希望对你有一定的参考价值。
贴一下汇总贴:论文阅读记录
论文链接:《Cross-lingual alignments of ELMo contextual embeddings》
一、摘要
为特定的 NLP 任务构建机器学习预测模型需要足够的训练数据,这对于低资源语言来说可能很难获得。跨语言嵌入将词嵌入从低资源语言映射到高资源语言,这样在高资源语言的数据上训练的预测模型也可以用于低资源语言。为了生成最近上下文嵌入的跨语言映射,嵌入空间之间的锚点必须是相同上下文中的单词。我们使用一种为跨语言上下文对齐创建数据集的新方法来解决这个问题。基于此,我们为 ELMo 嵌入提出了新颖的跨语言映射方法。我们的线性映射方法在上下文 ELMo 嵌入上使用现有的 vecmap 和 MUSE 对齐。我们新的非线性 ELMoGAN 映射方法基于 GAN,不假设同构嵌入空间。我们使用两个下游任务,NER 和依赖解析,评估了在九种语言上提出的映射方法。ELMoGAN 方法在 NER 任务上表现良好,与某些语言的直接训练相比,跨语言损失较低。在依赖解析中,线性对齐变体更成功。
二、结论
我们提出了ELMoGAN,一种新的跨语言映射方法,用于上下文ELMO嵌入。该方法不假设同构嵌入空间,而是使用遗传神经网络来计算比对。为了构建映射,我们必须为11种语言对构建上下文嵌入数据集。我们从平行语料库和双语词典中为每个语言对和每个ELMo层构建了一组匹配的上下文单词嵌入。我们使用这些新的数据集,用提出的非线性映射方法ELMoGAN来训练映射。
ELMoGAN对训练参数的值很敏感,主要是学习速率和迭代次数,但与同构映射相比,它可能会带来更好的性能,尤其是在对齐更远的语言对时。为了找到一组性能良好的超参数,这种方法必须针对每个任务进行仔细的微调。埃尔默根方法在NER任务上优于线性映射,但在动态规划任务上表现较差。由于这种方法还不够成熟,在为每个任务选择正确的迭代次数的方法上仍然存在未解决的问题;我们目前在内部使用的字典归纳任务对于NER任务很有效,但是对于依赖分析任务似乎不合适,因为依赖分析任务更强调语言的句法属性(而不是像NER任务那样强调单词)。
在进一步的工作中,我们打算研究一种稳健的方法来寻找超参数。我们打算测试更多的氮化镓架构,以找到一个更强大的映射。另一个值得研究的问题是多词术语,它不包含在当前的上下文映射数据集中,但在需要联合识别的任务中非常有用。
三、model
句子对齐的两种生成模式:
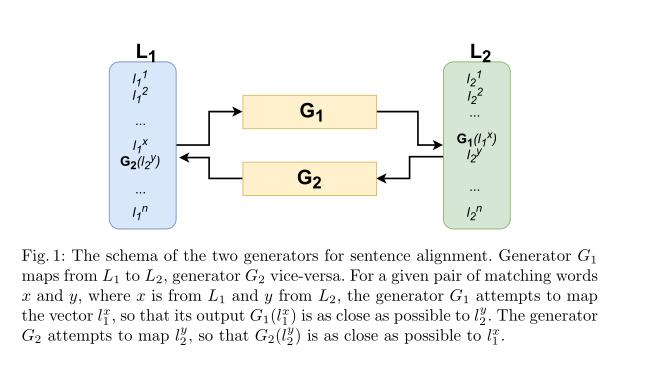
句子对齐的两种判别式:

第一个版本(ELMoGAN-10k)针对每对语言的每一层进行了固定次数的10000次迭代。
对于第二个版本(ELMoGAN-O),我们用几个不同的迭代次数来训练模型。
以上是关于论文泛读147ELMo 上下文嵌入的跨语言对齐的主要内容,如果未能解决你的问题,请参考以下文章