Redis 开发与运维Redis Cluster 集群
Posted 木兮同学
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Redis 开发与运维Redis Cluster 集群相关的知识,希望对你有一定的参考价值。
一、集群伸缩
原理
- Redis 集群提供了灵活的节点扩容和收缩方案,其中的原理可以抽象为
槽和对应数据在不同节点之间灵活移动。
扩容
-
准备新节点
- 新节点建议跟集群内的节点配置保持一致,便于管理统一。
- 启动后的新节点作为孤儿节点运行,并没有其他节点与之通信。
-
加入集群
- 新节点依然采用
cluster meet命令加入到现有集群中。在集群任意节点执行 cluster meet 命令让新节点加入进来。 - 新节点刚开始都是主节点状态,但是
由于没有负责的槽,所以不能接受任何读写操作。
- 新节点依然采用
-
迁移槽和数据
- 加入集群后需要
为新节点迁移槽和相关数据,槽在迁移过程中集群可以正常提供读写服务,迁移过程是集群扩容最核心的环节 槽迁移计划:槽是 Redis 集群管理数据的基本单位,首先需要为新节点制定槽的迁移计划,确定原有节点的哪些槽需要迁移到新节点迁移数据:数据迁移过程是逐个槽进行的
- 加入集群后需要
收缩
- 收缩集群意味着缩减规模,需要从现有集群中安全下线部分节点,流程说明:
- 首先需要确定
下线节点是否有负责的槽,如果是,需要把槽迁移到其他节点,保证节点下线后整个集群槽节点映射的完整性。 - 当下线节点不再负责槽或者本身是从节点时,就可以通知
集群内其他节点忘记下线节点,当所有的节点忘记该节点后可以正常关闭。
- 首先需要确定
- 下线迁移槽
- 下线节点需要把自己负责的槽迁移到其他节点。
- 忘记节点
- 由于集群内的节点不停地通过 Gossip 消息彼此交换节点状态,因此
需要通过一种健壮的机制让集群内所有节点忘记下线的节点。 - 也就是说让其他节点不再与要下线节点进行 Gossip 消息交换,Redis 提供了
cluster forget {downNodeId}命令实现该功能。 - 线上操作不建议直接使用 cluster forget 命令下线节点,需要跟大量节点命令交互,实际操作起来过于繁琐并且容易遗漏 forget 节点。建议使用
redis-trib.rb del-node {host:port} {downNodeId}命令。
- 由于集群内的节点不停地通过 Gossip 消息彼此交换节点状态,因此
二、请求路由
请求重定向
- 在集群模式下,Redis 接收任何键相关命令时首先计算键对应的槽,再根据槽找出所对应的节点,如果节点是自身,则处理键命令;否则回复 MOVED 重定向错误,通知客户端请求正确的节点。这个过程称为
MOVED 重定向。 重定向信息包含了键所对应的槽以及负责该槽的节点地址,根据这些信息客户端就可以向正确的节点发起请求。- 键命令执行步骤主要分两步:计算槽,查找槽所对应的节点。
- 计算槽
- Redis 首先需要计算键所对应的槽。根据键的有效部分使用 CRC16 函数计算出散列值,再取对 16383 的余数,使每个键都可以映射到 0 ~ 16383 槽范围内。
- 键内容包含
{和}大括号字符,则计算槽的有效部分是括号内的内容,否则采用键的全内容计算槽。其中大括号包含的内容又叫做hash_tag,它提供不同的键可以具备相同 slot 的功能,常用于 Redis IO 优化。 - 例如
在集群模式下使用 mget 等命令优化批量调用时,键列表必须具有相同的 slot,否则会报错。这时可以利用 hash_tag 让不同的键具有相同的 slot 达到优化的目的。 Pipeline 同样可以受益于 hash_tag,由于 Pipeline 只能向一个节点批量发送执行命令,而相同 slot 必然会对应到唯一的节点,降低了集群使用 Pipeline 的门槛。
- 槽节点查找
- Redis 计算得到键对应的槽后,需要查找槽所对应的节点。
集群内通过消息交换每个节点都会知道所有节点的槽信息。
- Redis 计算得到键对应的槽后,需要查找槽所对应的节点。
客户端原理
- 大多数开发语言的 Redis 客户端都采用 Smart 客户端支持集群协议。
- Smart 客户端通过在内部维护
slot -> node的映射关系,本地就可实现键到节点的查找,从而保证 IO 效率的最大化,而MOVED 重定向负责协助 Smart 客户端更新 slot -> node 映射。 - 以 Java 的 Jedis 为例,说明 Smart 客户端操作集群的流程。
- 1)首先在 JedisCluster 初始化时会
选择一个运行节点,初始化槽和节点映射关系,使用 cluster slots 命令完成。 - 2)JedisCluster 解析 cluster slots 结果缓存在本地,并
为每个节点创建唯一的 JedisPool 连接池。映射关系在 JedisClusterInfoCache 类中。 - 3)JedisCluster 执行键命令的过程有些复杂,理解这个过程对于我们分析定位问题非常有帮助,部分代码如下:
- 1)首先在 JedisCluster 初始化时会
public abstract class JedisClusterCommand<T> {
// 集群节点连接处理器
private JedisClusterConnectionHandler connectionHandler;
// 重试次数,默认 5 次
private int maxAttempts;
// 模板回调方法
public abstract T execute(Jedis connection);
public T run(String key) {
if (key == null) {
throw new JedisClusterException("No way to dispatch this command to Redis Cluster.");
}
return runWithRetries(SafeEncoder.encode(key), this.maxAttempts, false, false);
}
...
// 利用重试机制运行键命令
private T runWithRetries(byte[] key, int attempts, boolean tryRandomNode, boolean asking) {
if (attempts <= 0) {
throw new JedisClusterMaxRedirectionsException("Too many Cluster redirections?");
}
Jedis connection = null;
try {
if (asking) {
connection = askConnection.get();
connection.asking();
asking = false;
} else {
if (tryRandomNode) {
// 随机获取活跃节点连接
connection = connectionHandler.getConnection();
} else {
// 使用 slot 缓存获取目标节点连接
connection = connectionHandler.getConnectionFromSlot(JedisClusterCRC16.getSlot(key));
}
}
return execute(connection);
} catch (JedisNoReachableClusterNodeException jnrcne) {
throw jnrcne;
} catch (JedisConnectionException jce) {
// 出现连接错误使用随机连接重试
return runWithRetries(key, attempts - 1, tryRandomNode, asking);
} catch (JedisRedirectionException jre) {
if (jre instanceof JedisMovedDataException) {
// 如果出现 MOVED 重定向错误,在连接上执行 cluster slots 命令重新初始化 slot 缓存
this.connectionHandler.renewSlotCache(connection);
}
// 初始化后重试命令
return runWithRetries(key, attempts - 1, false, asking);
} finally {
releaseConnection(connection);
}
}
...
}
-
键命令执行流程:
1)计算 slot 并根据 slots 缓存获取目标中节点连接,发送命令。
2)如果出现连接错误,使用随机连接重新执行键命令,每次命令重试对 redi-rections 参数减 1 。
3)捕获到 MOVED 重定向错误,使用 cluster slots 命令更新 slots 缓存(renew SlotCache 方法)。
4)重复执行 1~ 3 步,直到命令执行成功或者当 redirections <= 0 时抛出 JedisClusterMaxRedirectionsException 异常。
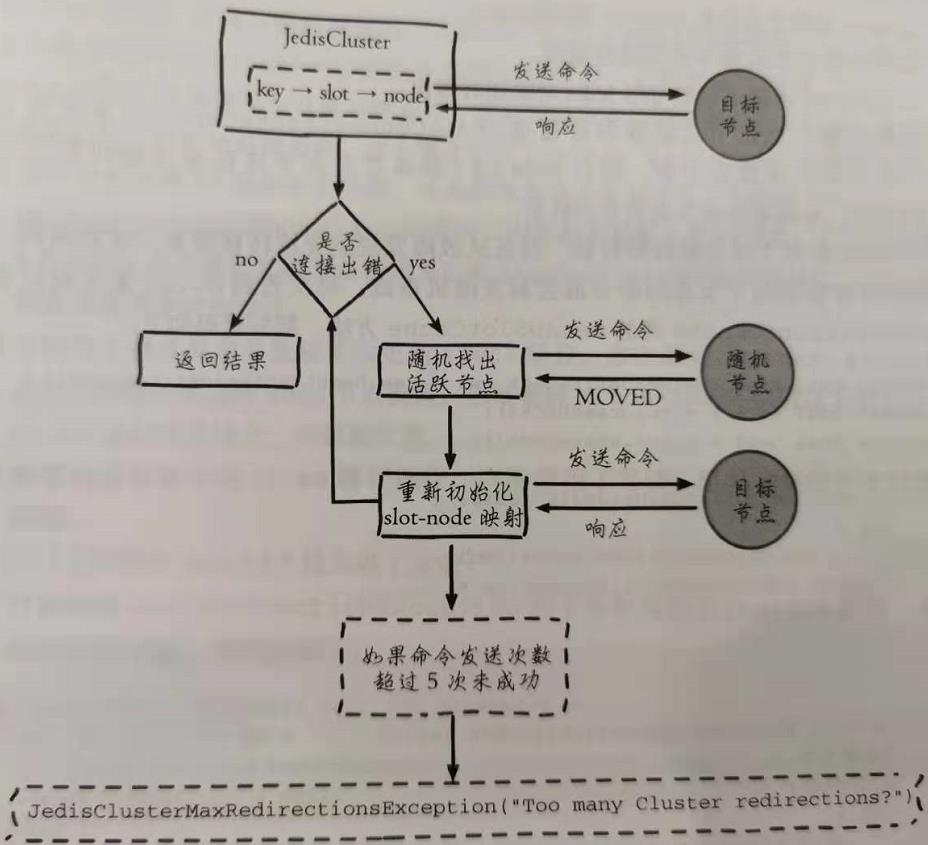
-
从命令执行流程中发现,
客户端需要结合异常和重试机制时刻保证跟 Redis 集群的 slots 同步,因此 Smart 客户端相比单机客户端有了很大的变化和实现难度。下面对 Smart 客户端成本和可能存在的问题进行分析:- 1)客户端内部维护 slots 缓存表,并且针对每个节点维护连接池,当集群规模非常大时,客户端会维护非常多的连接并消耗更多的内存。
- 2)使用 Jedis 操作常见抛出如下错误,这经常会引起开发人员的疑惑,他隐藏了内部错误细节,原因是节点宕机或请求超时都会抛出 JedisConnectionException,导致触发了随机重试,当重试次数耗尽抛出这个错误。
throw new JedisClusterMaxRedirectionsException("Too many Cluster redirections?");- 3)当出现 JedisConnectionException 时,Jedis 认为可能是集群节点故障需要随机重试来更新 slots 缓存,因此了解哪些错误触发该异常变得非常重要,有如下几种情况:
- Jedis 连接节点发生 socket 错误时抛出
- 所有命令 /Lua 脚本读写超时抛出
- JedisPool 连接池获取可用 Jedis 对象超时抛出
- 4)Redis 集群支持自动故障转移,但是从故障发现到完成转移需要一定的时间,节点宕机期间所有指向这个节点的命令都会触发随机重试,每次
收到 MOVED 重定向后会调用 JedisClusterInfoCache 类的 renewSlotCache 方法。
JedisCluster
- JedisCluster 的定义
public JedisCluster(Set<HostAndPort> jedisClusterNode, int connectionTimeout, int soTimeout,
int maxAttempts, final GenericObjectPoolConfig poolConfig) {
...
}
- 初始化方法如上,其中包含 5 个参数:
Set<HostAndPort> jedisClusterNode:所有 Redis Cluster 节点信息(也可以是一部分,因为客户端可以通过 cluster slots 自动发现)int connectionTimeout:连接超时int soTimeout:读写超时int maxAttempts:重试次数GenericObjectPoolConfig poolConfig:连接池参数,JedisCluster 会为 Redis Cluster 的每个节点创建连接池
// 初始化所有节点(例如6个节点)
Set<HostAndPort> jedisClusterNode = new Hashs set<HostAndPort>();
jedisClusterNode.add(new HostAndPort("10.10.xx.1", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.2", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.3", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.4", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.5", 6379));
jedisClusterNode.add(new HostAndPort("10.10.xx.6", 6379));
// 初始化commnon-pool连接池,并设置相关参数
Generic0bjectPoolConfig poolConfig = new GenericObjectPoolConfig(); //初始化 JedisCluster
JedisCluster jedisCluster = new JedisCluster(jedisClusterNode, 1000, 1000, 5, poolConfig);
-
对于 JedisCluster 的使用需要注意以下几点:
- JedisCluster 包含了所有节点的连接池(JedisPool),所以建议 JedisCluster 使用单例
- JedisCluster 每次操作完成后,不需要管理连接池的借还,它在内部已经完成
- JedisCluster 一般不要执行 close() 操作,他会将所有 JedisPool 执行 destroy 操作
-
多节点命令和操作,Redis Cluster 虽然提供了分布式的特性,但是有些命令或者操作,
诸如 keys、flushall、删除指定模式的键,需要遍历所有节点才可以完成。 -
批量操作的方法,Redis Cluster中,由于 key 分布到各个节点上,会造成无法实现 mget、mset 等功能。但是可以利用 CRC16 算法计算出 key 对应的slot,以及 Smart 客户端 保存了slot 和节点对应关系的特性,将属于同一个 Redis 节点的 key 进行归档,然后分别对每个节点对应的子 key 列表执行 mget 或者 pipeline 操作,可以参考 【Redis 开发与运维】缓存设计 里的无底洞优化一节。
-
使用 Lua、事务等特性的方法,Lua 和事务需要所操作的 key 必须在一个节点上,不过 Redis Cluster 提供了 hashtag,如果开发人员确实要使用 Lua 或者事务,可以将所要要操作的 key 使用一个 hashtag。
来源:《Redis 开发与运维》第 10 章 集群
以上是关于Redis 开发与运维Redis Cluster 集群的主要内容,如果未能解决你的问题,请参考以下文章