RocketMQ—基础篇
Posted 敲代码的小小酥
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了RocketMQ—基础篇相关的知识,希望对你有一定的参考价值。
前言
RocketMQ最初是cooy的Kafka,改成了java语言。所以,RocketMQ中充斥着Kafka的影子。学习RocketMQ前,最好学习Kafka知识。
RocketMQ需要占用的内存较大。默认的配置中,配置到了8G的内存。所以想玩RocketMQ,必须保证有足够的运行内存。
一、物理架构
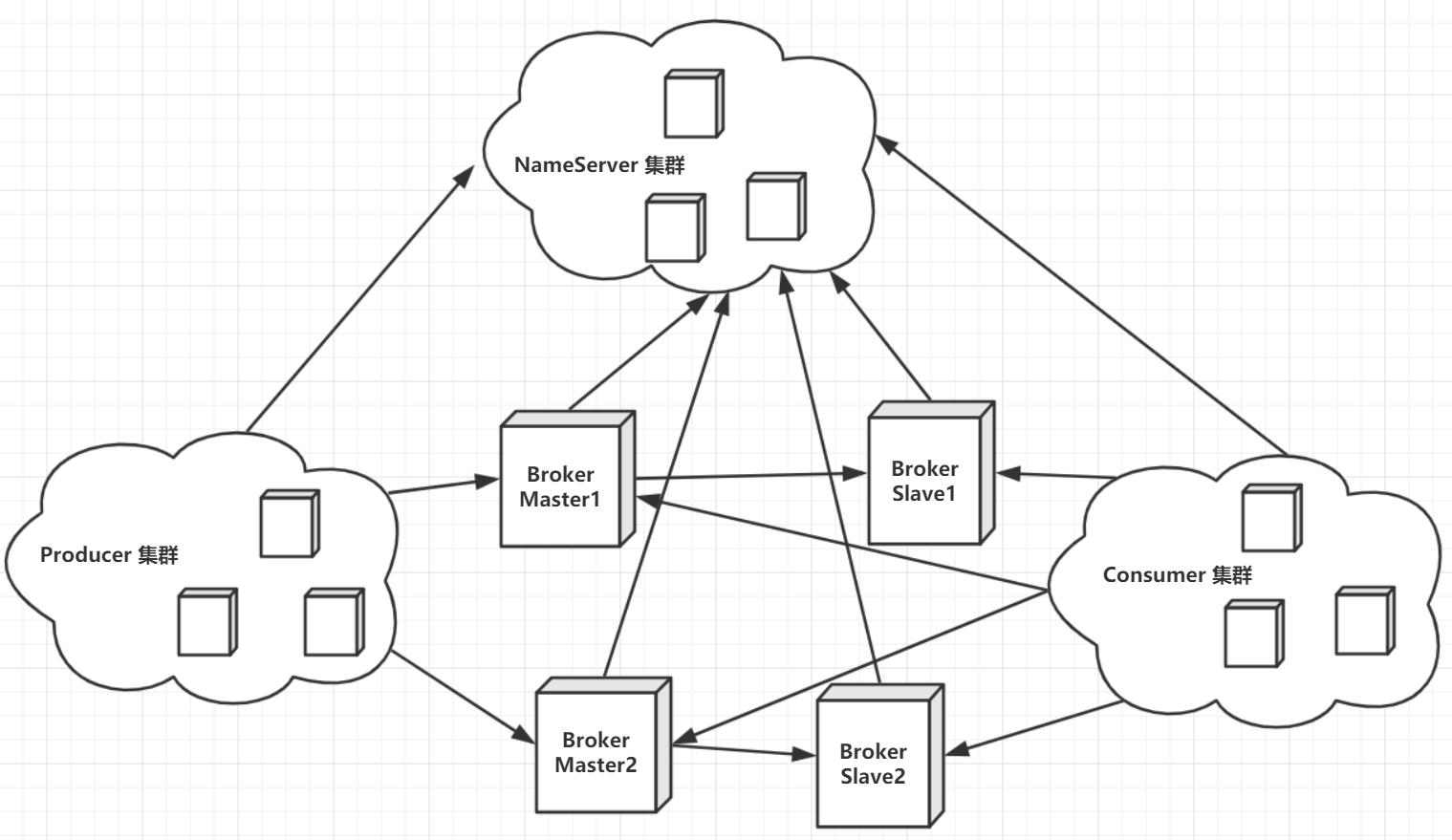
NameServer:
NameServer类似于Kafka中的Zookeeper,是RocketMQ的服务注册中心,所以启动RocketMQ需要先启动NameServer再启动Broker。
Broker在启动时向所有NameServer注册服务器地址等信息,生产者在发送消息之前先从NameServer获取Broker服务器地址列表(消费者一样),然后根据负载均衡算法从列表中选择一台服务器进行消息发送。
NameServer与每台Broker服务保持长连接,间隔30S检查Broker是否存活,如果宕机,则从路由注册表中将其移出。
二、核心概念
分组(Group)
生产者:标识发送同一类消息的Producer,发送普通消息时,仅标识使用。主要用作事务消息。
消费者:标识一类Consumer的集合,这类Consumer通常消费一类消息,且消费逻辑一致。同一个Consumer Group下的各个实例共同消费topic的消息,起到负载均衡的作用。这句话的意思是,同一类的Consumer Group,共同订阅并消费某一个topic,且他们的处理逻辑都一样。
Consumer Group 和Kafka中的消费者群组类似,一个群组内的消费者共同消费一个主题,偏移量是共享的。不同群组的消费者消费一个主题,偏移量是各自群组的。
主题(Topic)
RocketMQ中的主题,引入了标签(Tag) 概念,消息发送时,给消息打Tag,在消费时,再指定Tag,那么消费者就只能消费这个主题中携带这个Tag的消息。
消息队列(Message Queue)
类似于Kafka中分区的概念。消息的物理管理单位。一个Topic可以有多个Queue。若一个Topic创建在 不同的Broker上,则不同的Broker上都有若干个Queue,消息将物理地址存储落在不同Broker节点上。这样可以提高消费者的消费速度,提高并发度。
生产者和消费者,最终交互的,都是topic下的Queue。这和Kafka的模式一样。
偏移量(Offset)
RocketMQ 中,有很多 offset 的概念。一般我们只关心暴露到客户端的 offset。不指定的话,就是指 Message Queue 下面的 offset。
Message queue 是无限长的数组。一条消息进来下标就会涨 1,而这个数组的下标就是 offset,Message queue 中的 max offset 表示消息的最大 offset。
offset实际上表示的是下次拉取的 offset 位置。
和Kafka中分区偏移量意思类似。
消息(Message)
Message 是 RocketMQ 消息引擎中的主体。messageId 是全局唯一的。MessageKey 是业务系统(生产者)生成的,所以如果要结合业务,可以使用 MessageKey 作为业务系统的唯一索引。
三、零拷贝与MMAP
以上是关于RocketMQ—基础篇的主要内容,如果未能解决你的问题,请参考以下文章