《Robust Consistent Video Depth Estimation》论文笔记
Posted m_buddy
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《Robust Consistent Video Depth Estimation》论文笔记相关的知识,希望对你有一定的参考价值。
主页与代码地址:robust_cvd
1. 概述
导读:这篇文章的目的是为了在视频场景下生成稳定的深度估计结果,其提出的算法可以在一个单目视频中估计出一致的深度图和相机位姿。文章首先会使用MiDas为视频中的单帧图像做初始深度估计(主要用于提供深度scale参数),以及使用Ceres Library上计算相机的初始位姿信息。之后再在输入的视频序列上使用在线finetune形式交替进行深度估计结果与相机位姿优化。在上面的finetune优化中使用到了一个几何优化过程去生成稳定平滑地相机移动轨迹(表征为相机关联的内外参数)与深度细节保存完好且稳定的深度结果。在上面提到的相机位姿优化与最后深度估计生成过程包含两个互补的技术(分别对低频区域和高频区域):
1)使用灵活的变化样条函数去实现图像内低频区域的区块对齐;
2)使用一个几何感知深度滤波器在不同的视频帧上去对齐高频的细节部分。
相比之前的方法(《Consistent Video Depth Estimation》),文章并不需要相机的位姿信息作为输入,在文章算法中对其进行预测。同时文章方法的设计是源自于上面论文的。
2. 方法设计
2.1 算法Pipline
文章的视频深度估计pipeline见下图所示:
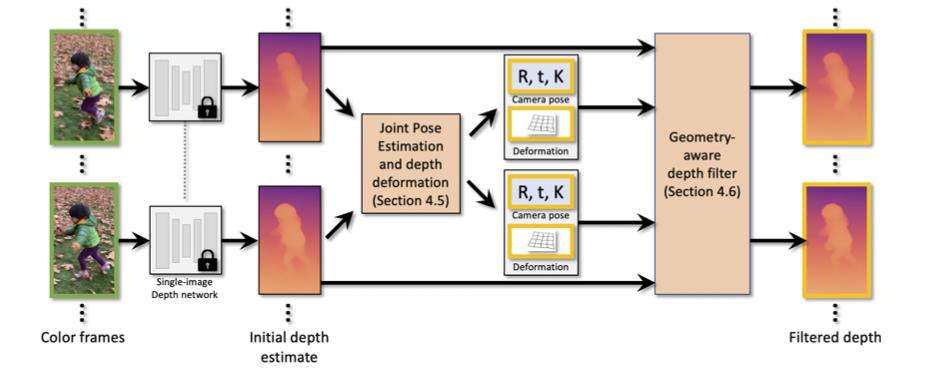
从图中可以看到文章的pipeline主要划分为个部分:
- 1)使用MiDas作为单帧深度估计方法,从而估计得到单帧图像的初始深度信息。使用Ceres Library从视频序列中去计算初始相机位姿;
- 2)使用finetune训练的形式从输入的视频序列中交替优化深度估计结果与相机位姿信息,在相机位姿估计过程中使用样条差值的形式实现深度对齐,从而使得相机位姿估计的结果稳定;
- 3)使用几何感知的深度滤波器在多帧之间进行滤波保留和优化深度估计中的高频信息;
2.2 准备工作
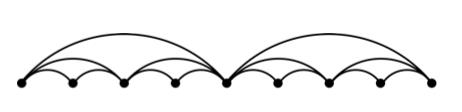
输入一个视频序列之后,除了上述中提到会使用MiDas计算一个初始深度和相机位姿之外,还会对视频进行不同间隔的采样得到一个视频帧对(图像对)的集合,其在视频序列上进行采样可以使用下面的式子进行描述:
P
=
{
(
i
,
j
)
∣
∣
i
−
j
∣
=
k
,
i
m
o
d
k
=
0
,
k
=
1
,
2
,
4
,
…
}
P=\\{(i,j)\\mid |i-j|=k,i\\ mod\\ k=0,k=1,2,4,\\dots\\}
P={(i,j)∣∣i−j∣=k,i mod k=0,k=1,2,4,…}
也就是下图表述的间隔采样的形式:
对于一个采样到的图像对
(
i
,
j
)
∈
P
(i,j)\\in P
(i,j)∈P文章会在其上使用RAFT计算光流
f
i
→
j
f_{i\\rightarrow j}
fi→j,之后通过前后光流的一致性得到二值掩膜
m
i
→
j
f
l
o
w
m_{i\\rightarrow j}^{flow}
mi→jflow。使用Mask RCNN取出图像中可能存在移动的目标(如行人/车辆等)掩膜
m
i
d
y
n
m_i^{dyn}
midyn。
接下来的过程是在给定视频序列基础上进行finetune(交替优化深度预测与相机位姿估计),从而在视频上得到深度一致的预测结果。其中深度估计和相机位姿式交替进行的,并且在相机位姿估计中增加了深度对齐,增加了稳定性。图3中的(d)是使用SFM预测相机位姿的结果,图3中(c)是使用深度信息去反推相机位姿的结果,没有深度对齐会对相机位姿的准确推断带来很大干扰。对此,文章将finetune中的交替优化过程参见下文。
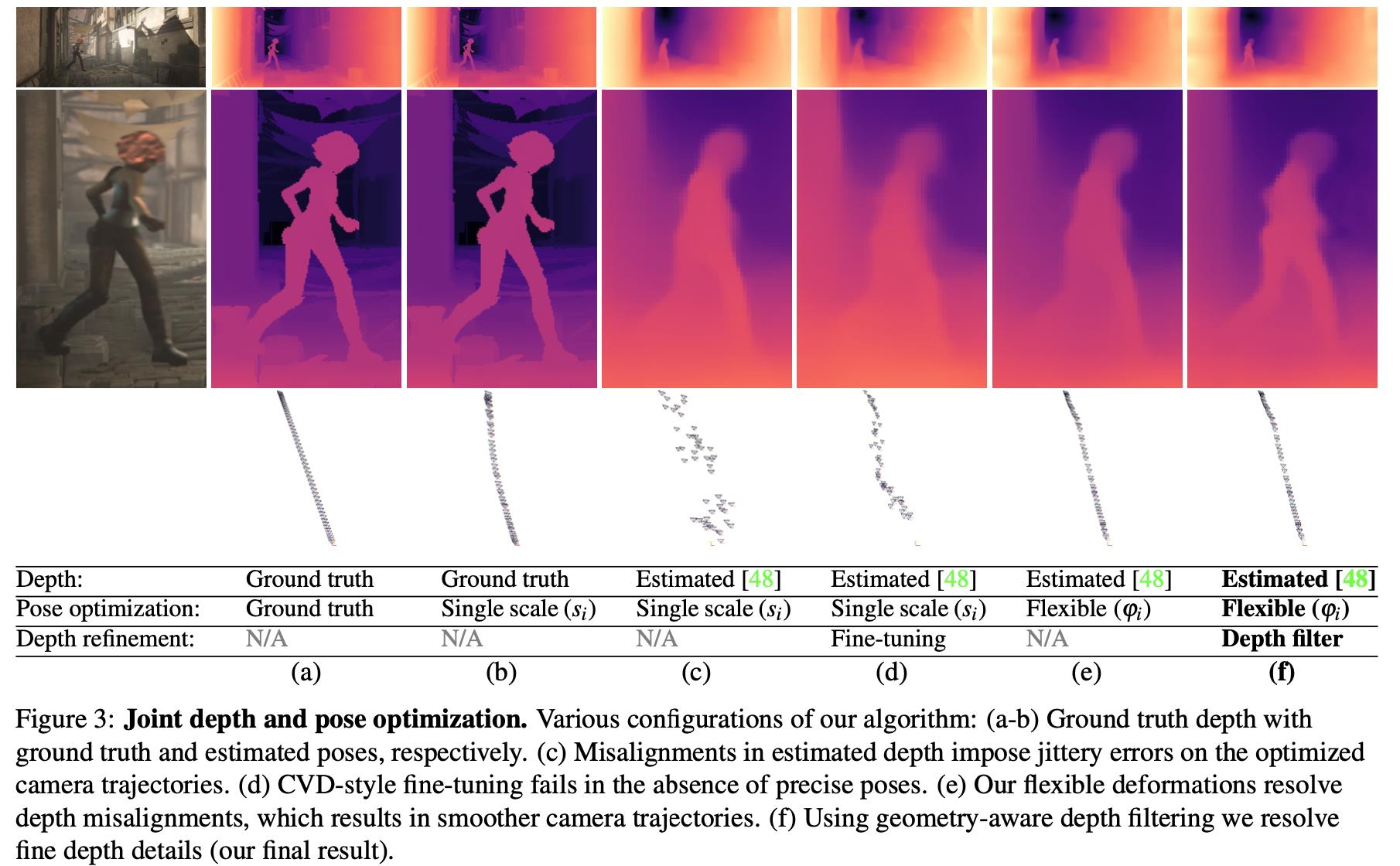
2.3 深度估计优化
2.3.1 光度构建约束
这里使用
s
i
s_i
si表示从MiDas中计算来的scale参数,将一个像素使用齐次坐标的形式表示
p
ˉ
=
[
p
x
,
p
y
,
1
]
T
\\bar{p}=[p_x,p_y,1]^T
pˉ=[px,py,1]T,
d
i
d_i
di是深度估计模型输出的深度结果。则将其映射到3D的相机坐标可以表示为:
c
i
(
p
)
=
s
i
d
i
(
p
)
p
ˉ
c_i(p)=s_id_i(p)\\bar{p}
ci(p)=sidi(p)pˉ
之后通过帧间的变换关系进行帧间的变换:
c
i
→
j
(
p
)
=
K
j
R
j
T
(
R
i
K
i
−
1
c
i
(
p
)
+
t
i
−
t
j
)
c_{i\\rightarrow j}(p)=K_jR_j^T(R_iK_i^{-1}c_i(p)+t_i-t_j)
ci→j(p)=KjRjT(RiKi−1ci(p)+ti−tj)
其中,
R
i
,
R
j
R_i,R_j
Ri,Rj和
t
i
,
t
j
t_i,t_j
ti,tj是帧
(
i
,
j
)
(i,j)
(i,j)的旋转平移参数,
K
i
,
K
j
K_i,K_j
Ki,Kj是对应的内参。则光度重重建误差可以描述为:
arg min
θ
d
e
p
t
h
∑
(
i
,
j
)
∈
P
∑
p
∈
m
i
→
j
f
l
o
w
L
i
→
j
r
e
p
r
o
,
s
.
t
.
f
i
x
e
d
θ
c
a
m
\\argmin_{\\theta^{depth}}\\sum_{(i,j)\\in P}\\sum_{p\\in m_{i\\rightarrow j}^{flow}}L_{i\\rightarrow j}^{repro},\\ s.t.\\ fixed\\ \\theta^{cam}
θdepthargmin(i,j)∈P∑p∈mi→jflow∑Li→jrepro, s.t. fixed θcam
其中,相机位姿的参数描述为
θ
c
a
m
=
{
R
i
,
t
i
,
K
i
,
s
i
}
\\theta^{cam}=\\{R_i,t_i,K_i,s_i\\}
θcam={Ri,ti,Ki,si}。上述的损失度量被定义为:
L
i
→
j
r
e
p
r
o
=
L
j
s
i
m
(
c
i
→
j
(
p
)
,
c
j
(
f
i
→
j
(
p
)
)
)
L_{i\\rightarrow j}^{repro}=L_j^{sim}(c_{i\\rightarrow j}(p),c_j(f_{i\\rightarrow j}(p)))
Li→jrepro=Ljsim(ci→j(p),cj(fi→j(p)))
注意上述的计算是在3维空间上做的,也就是
(
x
,
y
,
z
)
(x,y,z)
(x,y,z)上进行的。对于上述损失的度量文章将其取为:
L
s
i
m
(
a
,
b
)
=
L
s
p
a
t
i
a
l
(
a
,
b
)
+
L
r
a
t
i
o
(
a
,
b
)
L^{sim}(a,b)=L^{spatial}(a,b)+L^{ratio}(a,b)
Lsim(a,b)=Lspatial(a,b)+L以上是关于《Robust Consistent Video Depth Estimation》论文笔记的主要内容,如果未能解决你的问题,请参考以下文章