面试官灵魂拷问:什么是MySQL索引?为什么需要索引?
Posted 程序员二黑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了面试官灵魂拷问:什么是MySQL索引?为什么需要索引?相关的知识,希望对你有一定的参考价值。
大家好,我是二黑,这里赠送一套软件测试相关资源:
- 软件测试相关工具
- 软件测试练习集
- 深入自动化测试
- Python学习手册
- Python编码规范大厂面试题和简历模板
关注我公众号:【程序员二黑】即可免费领取!
交流群:642830685
目录
5.索引在存储的时候,需要什么信息?需要存储存储什么字段值?
7.mysql索引系统中不是按照刚刚说的格式存储的,为什么?
为什么需要学mysql?
我们每天都在访问各种⽹站、APP,如微信、QQ、抖⾳、今⽇头条、腾讯新闻等,这些 东西上⾯都存在⼤量的信息,这些信息都需要有地⽅存储,存储在哪呢?数据库。
所以如果我们需要开发⼀个⽹站、app,数据库我们必须掌握的技术,常⽤的数据库有 mysql、oracle、sqlserver、db2等。
上⾯介绍的⼏个数据库,oracle性能排名第⼀,服务也是相当到位的,但是收费也是⾮常 ⾼的,⾦融公司对数据库稳定性要求⽐较⾼,⼀般会选择oracle。
mysql是免费的,其他⼏个⽬前暂时收费的,mysql在互联⽹公司使⽤率也是排名第⼀, 资料也⾮常完善,社区也⾮常活跃,所以我们主要学习mysql。
篇幅所限,本文只详写了MySQL索引
一、什么是索引?
索引就好比字典的目录一样 我们通常都会先去目录查找关键偏旁或者字母再去查找 要比直接翻查字典查询要快很多
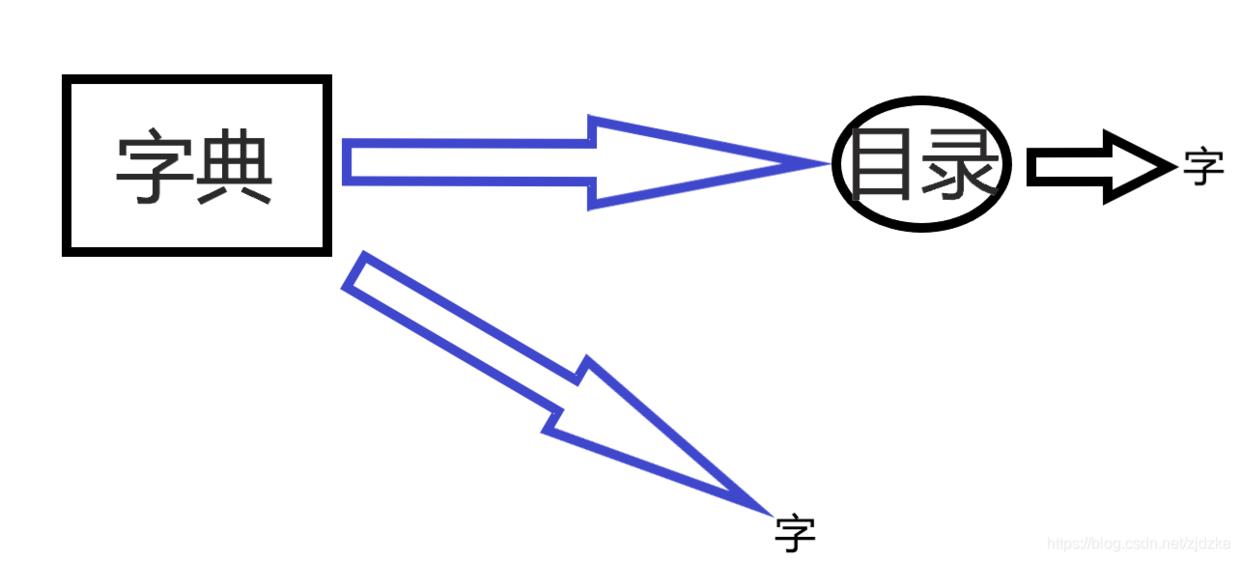
二、为什么要有索引?
然而我们在使用mysql数据库的时候也像字典一样有索引的情况下去查询,肯定速度要快很多
2.1问题:
1.mysql数据存储在什么地方?
磁盘
2.查询数据慢,一般卡在哪?
IO
3.去磁盘读取数据,是用多少读取多少吗?
磁盘预读
局部性原理:数据和程序都有聚集成群的倾向,同时之前被访问过的数据很可能再次被查询,空间局部性,时间局部性
磁盘预读:内存和磁盘发生数据交互的时候,一般情况下有一个最小的逻辑单元,页。 页一般由操作系统觉得大小,4k或8k,而我们在进行数据交互的时候,可以取页的整数倍来读取。
关注公众号:北游学Java 即可获取一份578页PDF文档的MySQL学习笔记
innodb存储引擎每次读取数据,读取16k
4.索引存储在哪?
磁盘,查询数据的时候会优先将索引加载到内存中
5.索引在存储的时候,需要什么信息?需要存储存储什么字段值?
key:实际数据行中存储的值
文件地址
offset:偏移量
6.这种格式的数据要使用什么样的数据结构来进行存储?
key-values
哈希表,树(二叉树、红黑树、AVL树、B树、B+树)
7.mysql索引系统中不是按照刚刚说的格式存储的,为什么?
OLAP:联机分析处理----对海量历史数据进行分析,产生决策性的策略----数据仓库—Hive
OLTP:联机事务处理----要求很短时效内返回对应的结果----数据库—关系型数据库(mysql、oracle)
三、mysql的索引数据结构
3.1哈希表:
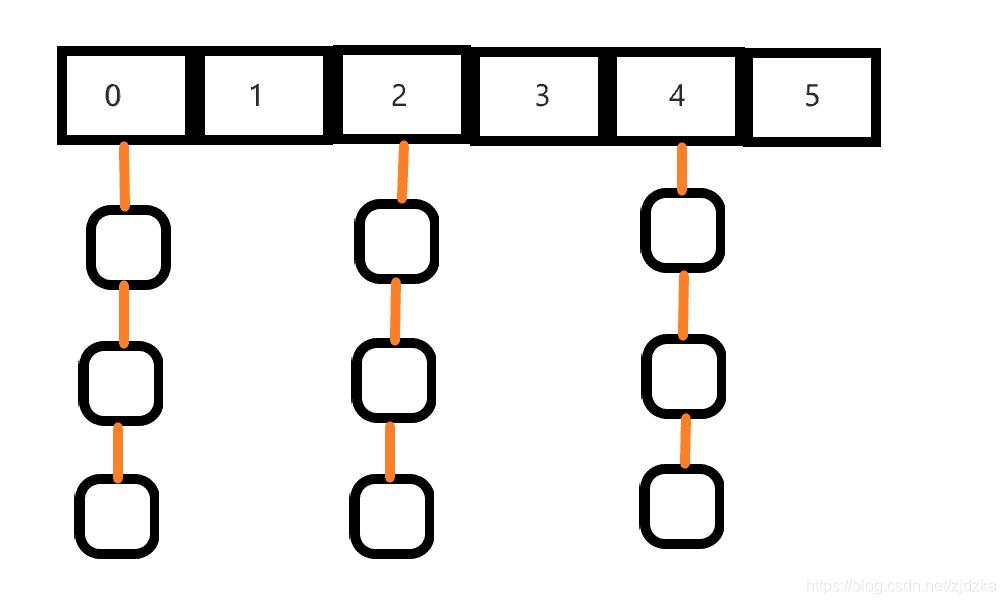
HashMap数组加链表的结构,不适合作为索引的原因:
1.哈希冲突会造成数据散列不均匀,会产生大量的线性查询,比较浪费时间
2.不支持范围查询,当进行范围查询的时候,必须挨个遍历
3.对于内存空间的要求比较高
优点: 如果是等值查询,非常快
在mysql中有没有hash索引?
1.memory存储引擎使用的是hash索引
2.innodb支持自适应hash
create table test(id int primary key,name varchar(30))
engine='innodb/memory/myisam'
-- 5.1之后默认innodb
3.2树:
树这种数据结构有很多,我们常见的有: 二叉树、BST、AVL、红黑树、B树、B+树
①二叉树:无序插入
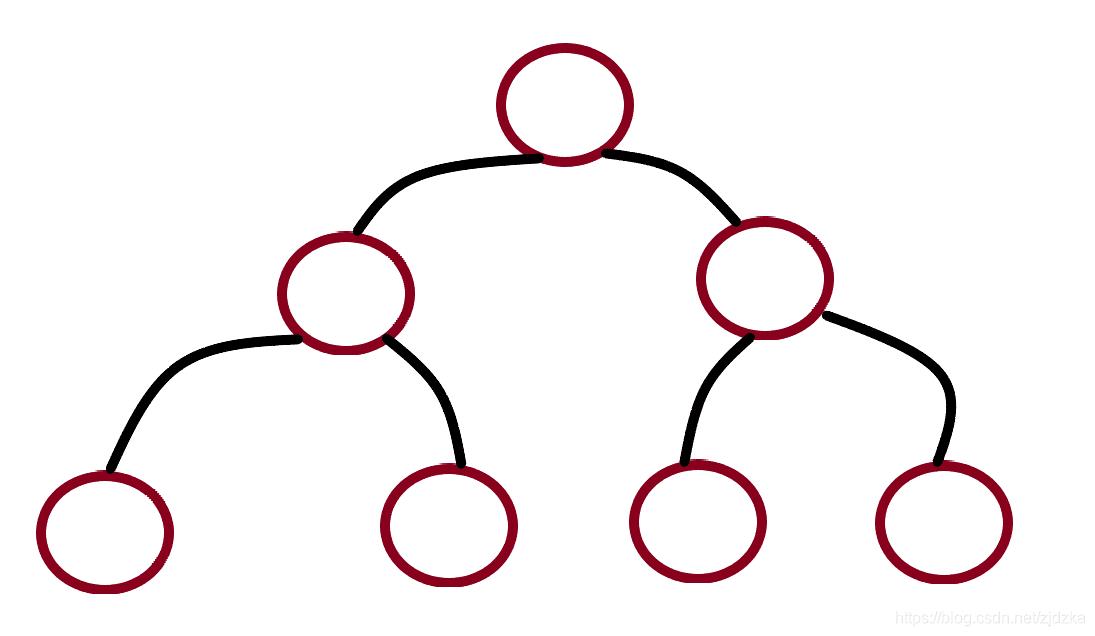
这就是我们的树的结构图,但是二叉树的数据插入是无序的,也就是说当需要查找的时候,还是得一个一个挨着去遍历查找
②BST(二叉搜索树): 插入的数据有序,左子树必须小于根节点,右子树必须大于根节点--------使用二分查找来提高效率
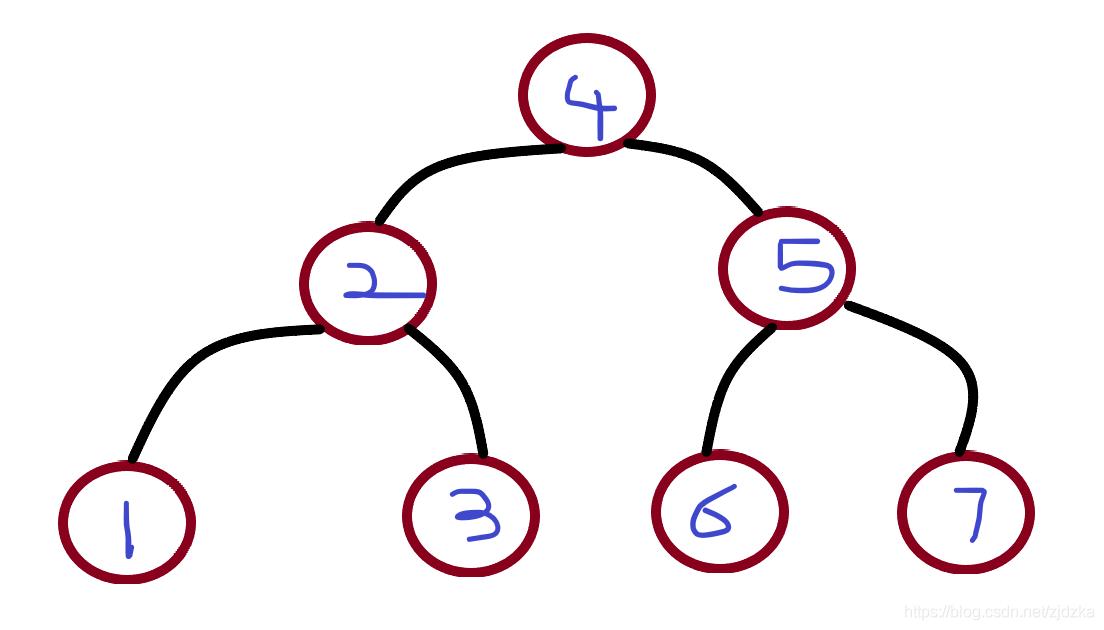
这样的话如果要查询数据,可以通过二分查找,快速缩小范围,减少了时间复杂度 **但是如果插入的顺序是升序或者降序的话,树的形状会变成如下:
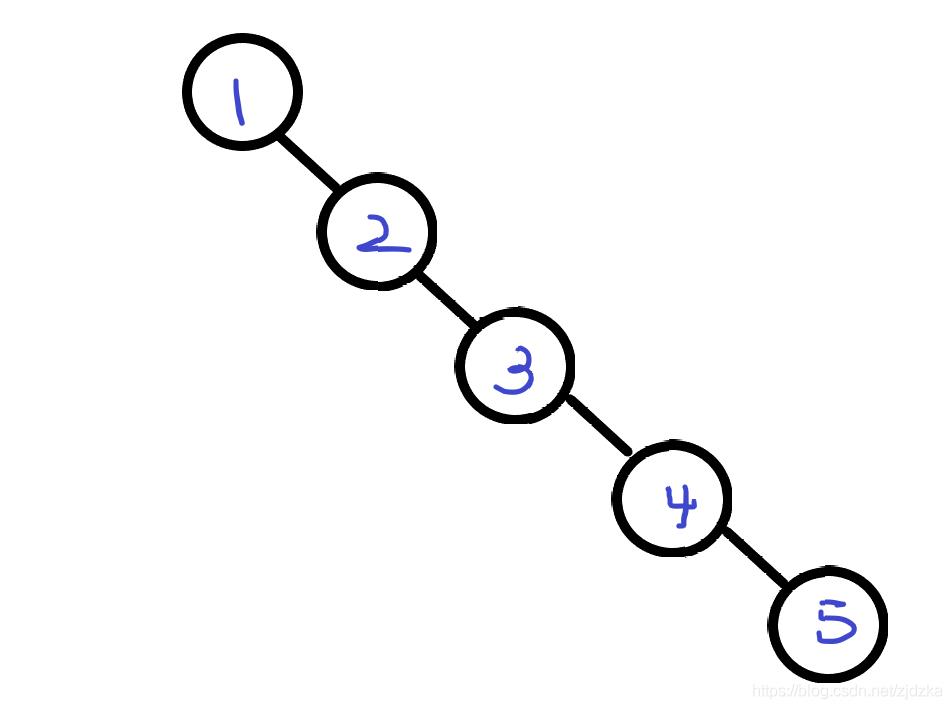
此时二叉搜索树就会退化成链表,时间复杂度又会变成O(n)
③AVL:平衡二叉树 为了解决上述问题,通过左旋转或右旋转让树平衡 最短子树跟最长子树高度只差不能超过1
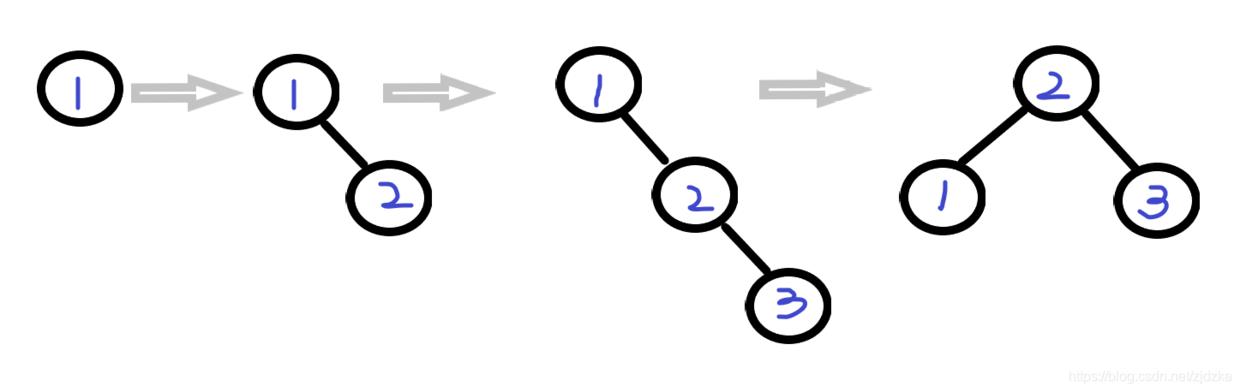
由图我们可以看到,当顺序插入的时候,会自动的进行旋转,以达到平衡 但是会通过插入性能的损失来弥补查询性能的提升 当我们插入的数据很多时候,而查询很少的时候,由于插入数据会旋转同样会消耗很多时间
④红黑树(解决了读写请求一样多) 同样是经过左右旋让树平衡起来,还要变色的行为 最长子树只要不超过最短子树的两倍即可
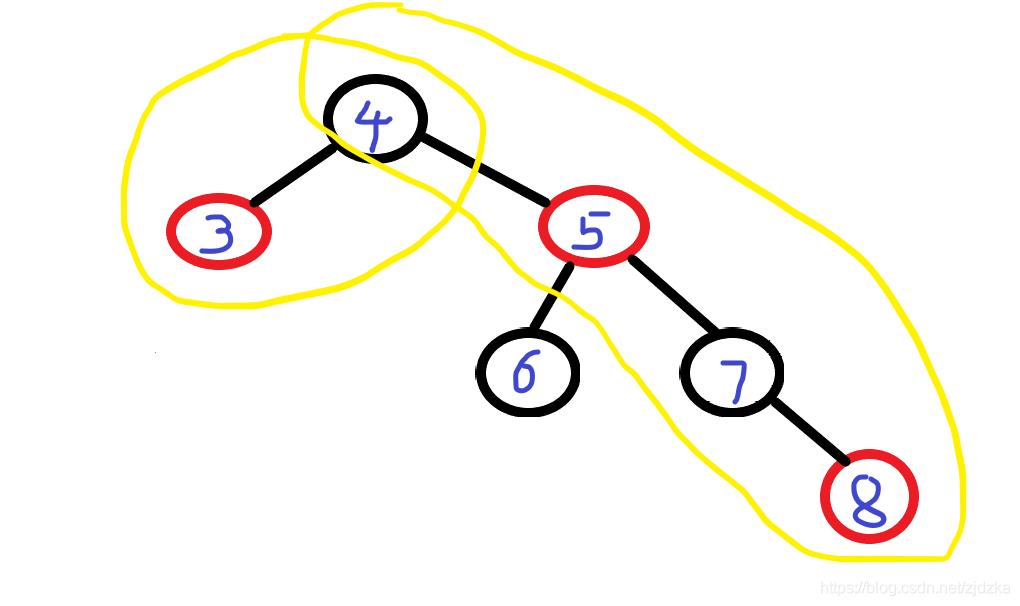
查询性能和插入性能近似取得平衡 但是随着数据的插入、发现树的深度会变深,树的深度会越来越深,意味着IO次数越多,影响数据读取的效率
⑤ B树 为了解决上述数据插入过多,树深度变深的问题,我们采用B树 把原来的有序二叉树变成有序多叉树
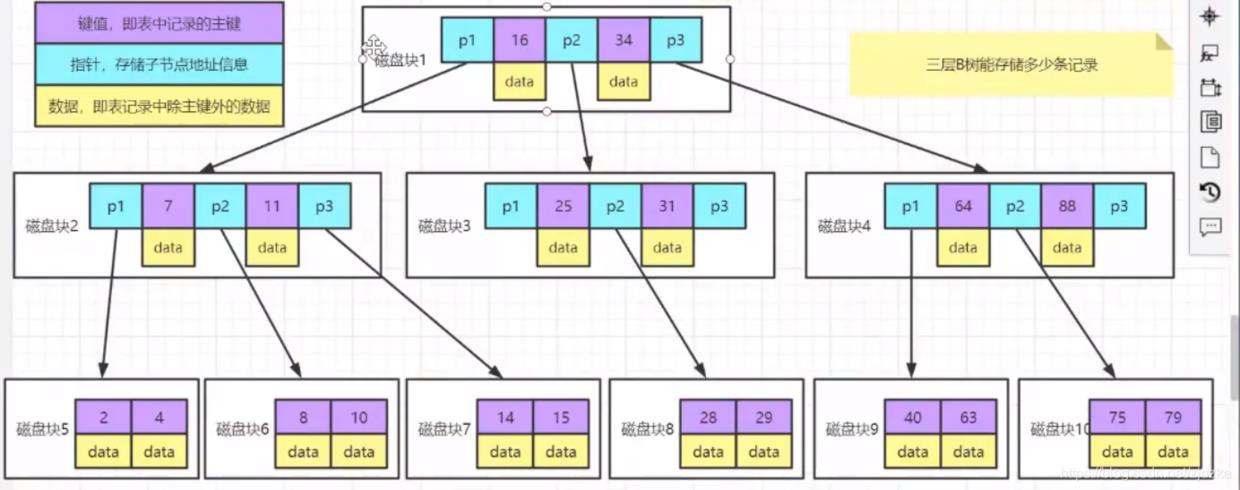
举例: 如果要查询select * from table where id=14?
- 第一步,将磁盘一加载到内存中,发现14<16,寻找地址磁盘2
- 第二步,将磁盘二加载到内存中,发现14>11,寻找地址磁盘7
- 第三步,将磁盘七加载到内存中,发现14=14,读取data,取出data,结束 思考:B树就是完美的嘛?
问题1:
B树不支持范围查询的快速查找,如果我们查询一个范围的数据,查找到范围一个边界时,需要回到根节点重新遍历查找,需要从根节点进行多次遍历,即便找到范围的另一个边界,查询效率会降低。
问题2:
如果data存储的是行记录,行的大小随着列数的增多,所占空间会变大。这时,一个页中可存储的数据量就会变少,树相应就会变高,磁盘IO次数就会变大。 思考2:三层B树能够存储多少条记录?
答: 假设一个data为1k,innodb存储引擎一次读取数据为16k,三层即161616=4096; 但是往往在开发中,一个表的数据要远远大于4096,难道要继续加层,这样岂不就加大了IO
四、为什么使用B+树?
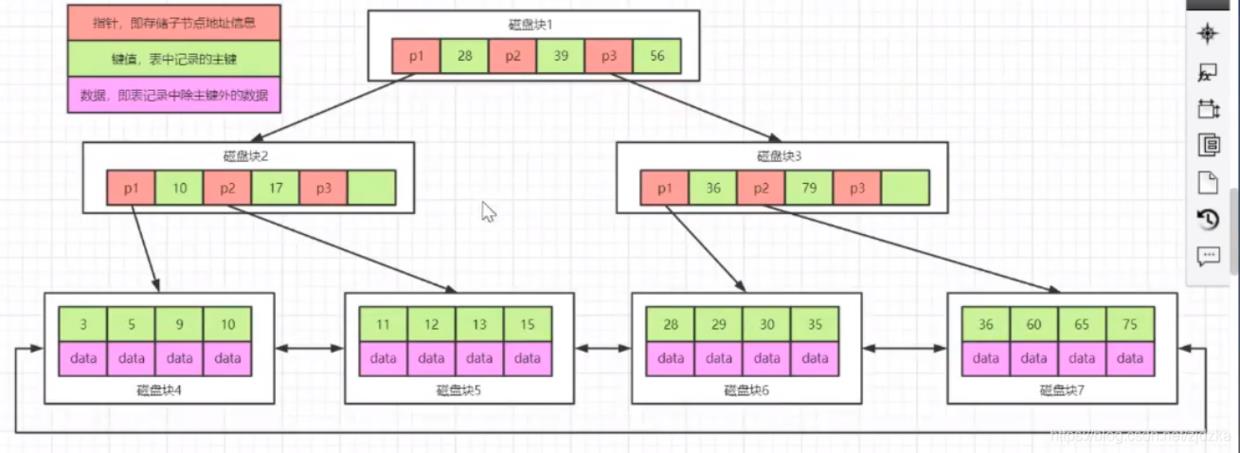
实际存储表数据的时候,怎么存储呢? key 完整的数据行 改造B+树
B+树对B树进行了改进,把数据全放在了叶子节点中,叶子节点之间使用双向指针连接,最底层的叶子节点形成了一个双向有序链表。
例如:
查询范围 select * from table where id between 11 and 35?
- 第一步,将磁盘一加载到内存中,发现11<28,寻找地址磁盘2
- 第二步,将磁盘二加载到内存中,发现10>11>17,寻找地址磁盘5
- 第三步,将磁盘五加载到内存中,发现11=11,读取data
- 第四步,继续向右查询,读取磁盘5,发现35=35,读取11-35之间数据,结束 由此可见,这样的范围查询比B树速度提高了不少
对比B树和B+树?
-
叶子节点中才放数据
-
非叶子节点中不存储数据
-
B+树每个节点包含更多个节点,这样做的好处,可以降低树的高度,同时将数据范围变成多个区间,区间越多查询越快
问题: 创建索引时用int还是varchar?
答:视情况而定,但是记住一定让key越小越好
五、索引的创建
在创建索引之前,我先说一下存储引擎 存储引擎: 表示不同的数据在磁盘的不同表现形式 大家去观察mysql的磁盘文件会发现 innodb: innodb的数据和索引都存储在一个文件下.idb myisam: myisam的索引存储在.MYI文件中,数据存储在.MYD中
5.1聚簇索引和非聚簇索引
概念:判断是否是聚簇索引就看数据和索引是否在一个文件中 innodb:
- 只能有一个聚簇索引,但是有很多非聚簇索引
- 向innodb插入数据的时候,必须要包含一个索引的key值
- 这个索引的key值,可以是主键,如果没有主键,那么就是唯一键,如果没有唯一键,那么就是一个自生成的6字节的rowid
myisam: 非聚簇索引
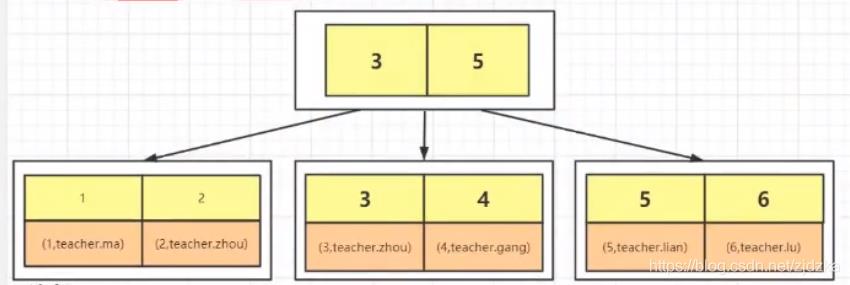
MySQL—innodb----B+树 索引和数据存储在一起,找到索引即可读取对应的数据
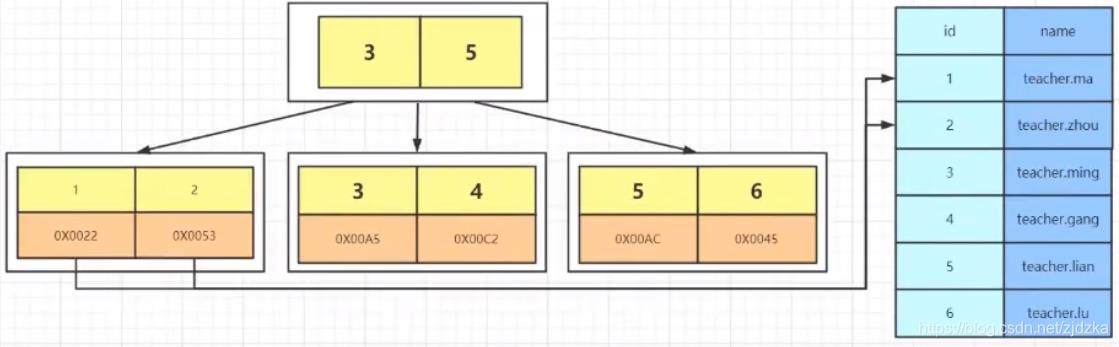
MySQL—myisam----B+树 索引和存储数据的地址在一起,找到索引得到地址值,再通过地址找到对应的数据
5.2回表
接下来,我会创建一张案例表给大家展示
CREATE TABLE user_test(
id INT PRIMARY KEY AUTO_INCREMENT,-- id为主键
uname VARCHAR(20) ,
age INT,
gender VARCHAR(10),
KEY `idx_uname` (`uname`) -- 索引选择为名字
)ENGINE = INNODB;
INSERT INTO user_test VALUES(1,'张三',18,'男');
INSERT INTO user_test VALUES(NULL,'马冬梅',19,'女');
INSERT INTO user_test VALUES(NULL,'赵四',18,'男');
INSERT INTO user_test VALUES(NULL,'王老七',22,'男');
INSERT INTO user_test VALUES(NULL,'刘燕',16,'女');
INSERT INTO user_test VALUES(NULL,'万宝',26,'男');
select * from user_test where uname = '张三';
-- 当我们表中有主键索引的时候,我们再去设置一个uname为索引,那么此时这条sql语句的查询过程应该如下:
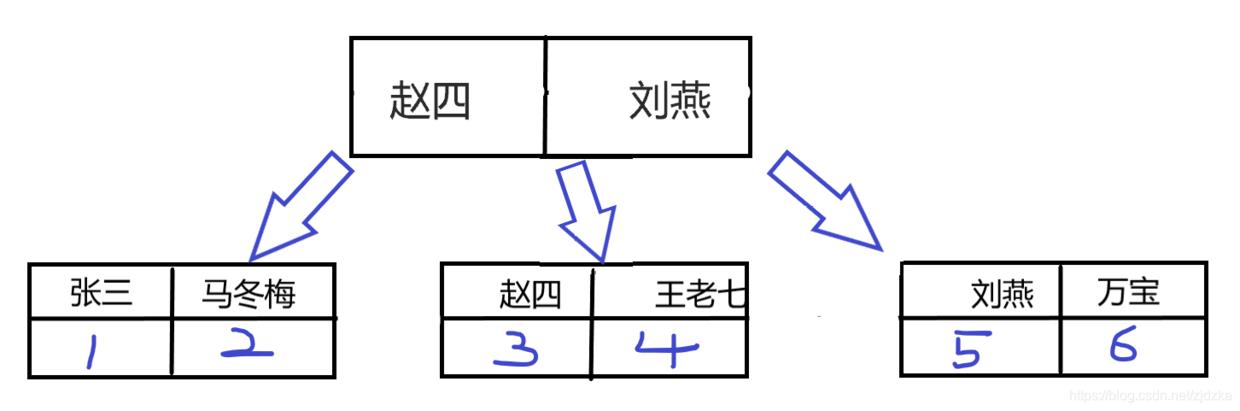
首先先根据uname查询到id,再根据id查询到行的信息 这样的操作走了两棵B+树,就是回表 当根据普通索引查询到聚簇索引的key值之后,再根据key值在聚簇索引中获取数据 我们可以发现这样的操作是很浪费时间的,因此我们日常操作的时候,尽量减少回表的次数
5.3覆盖索引
select id,uname from table where uname = '张三';
-- 根据uname 可以直接查询到id,uname两个列的值,直接返回即可
-- 不需要从聚簇索引查询任何数据,此时叫做索引覆盖
5.4最左匹配
在说最左匹配之前,我们先聊一下几个名词 主键(一般为一个列)-------->联合主键(多个列) 索引-------->联合索引(可能包含多个索引列)
-- 假设有一张表,有id,name,age,gender四个字段,id是主键,name,age是组合索引列
-- 组合索引使用的时候必须先匹配name,然后匹配age
select * from table where name = ? and age = ? ;-- 生效
select * from table where name = ?;-- 生效
select * from table where age = ? ;-- 不生效
select * from table where age = ? and name = ? ;-- 生效
--在mysql内部有优化器会调整对应的顺序
5.5索引下推
mysql5.7之后,默认支持的一个特点 举一个例子:
select * from table where name = ? and age = ? ;
-- mysql里的三层架构:
-- 客户端:JDBC
-- 服务端:server
-- 存储引擎:数据存储
在没有索引下推之前,根据name从存储引擎中获取符合规则的数据,在server层对age进行过滤
有索引下推之后,根据name、age两个条件从存储引擎中获取对应的数据
分析:有索引下推的好处,如果我们有50条数据,我们通过过滤会得到10条数据,如果没有索引下推,会先获取50条再去排除得到10条,而有了下推之后,我们会直接在存储引擎就过滤成了10条
为方便大家学习测试,特意给大家准备了一份13G的超实用干货学习资源,涉及的内容非常全面。
包括,软件学习路线图,50多天的上课视频、16个突击实战项目,80余个软件测试用软件,37份测试文档,70个软件测试相关问题,40篇测试经验级文章,上千份测试真题分享,还有2021软件测试面试宝典,还有软件测试求职的各类精选简历,希望对大家有所帮助……
关注我公众号:【程序员二黑】即可获取这份资料了!
以上是关于面试官灵魂拷问:什么是MySQL索引?为什么需要索引?的主要内容,如果未能解决你的问题,请参考以下文章