打怪升级之小白的大数据之旅(七十四)<初识Kafka>
Posted GaryLea
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了打怪升级之小白的大数据之旅(七十四)<初识Kafka>相关的知识,希望对你有一定的参考价值。
打怪升级之小白的大数据之旅(七十四)
初识Kafka
引言
学完Flume之后,接下来将为大家带来Kafka相关的知识点,在工作中,Kafka和Flume经常会搭配使用,那么Kafka究竟是什么呢?让我们开始今天的内容吧
Kafka地图
惯例,首先介绍kafka整个知识点的脉络,然后再详细为大家带来详细的知识点
- kafka概述
- kafka是什么?有什么应用场景,它的架构是什么?
- kafka常用shell指令
- 如何操作kafka
- kafka原理
- kafka它究竟是怎么实现的
- 消息发送流程
- kafka消息是怎么发送的
kafka概述
kafka是什么
按照官方的描述:kafka是基于发布/订阅的消息队列

想象上图中,这些人都预定今日头条的报纸,那么当今天的报纸印刷后,就会给每个人都发送一份,如果有人没有订阅该报纸,当然他就不会得到这份报纸,这就是发布/订阅的消息队列
kafka应用场景
kafka的应用场景主要有两大类
- 用于实时场景,当有高并发场景时,可以通过kafka进行削峰
- 举个栗子,秒杀活动中,可能同时会有海量的数据进来,此时服务器压力会很大,如果我们购买大量的服务器来解决这个高并发问题,等秒杀活动结束后,就会有大量服务器处于闲置状态
- 用于离线场景,通常配合Flume用于缓冲
- Flume的channel容量有限,当有大量数据通过source进行获取时,可能会造成channel容量溢出,所以可以通过kafka来减少flume的压力
kafka基础架构
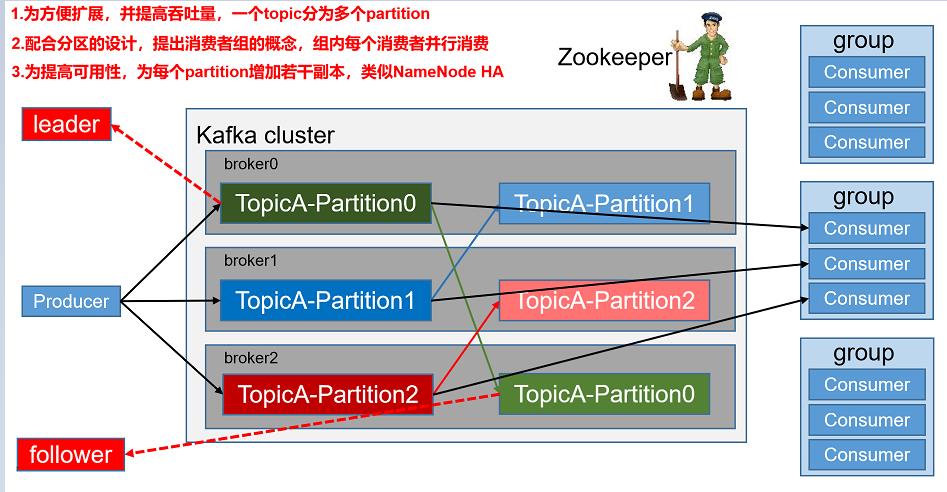
kafka架构
-
Producer: 生产者
- 向Topic写入消息
-
Topic:主题
- 消息存储在Topic中,在工作中一般是一个业务一个主题
-
Partition:分区
- topic的一个分段,topic为了实现分布式存储,将一个Topic划分为多个partition,每个分区存储在不同的节点上
- 好处:
1、实现topic的分布式存储
2、提高的生产者、消费者的并发度 - 一个partition只能被消费者组中一个消费者所消费
-
副本:
- 因为partition存储在不同节点,为了防止因节点宕机导致数据丢失,保证数据的完整性,提供了副本机制
-
ConsumerGroup 消费者组
- 消费者组中有多个消费者。组中消费者的个数最好 = topic分区数
- 如果消费者组中消费者个数>topic分区数,此时有个别消费者没有分区可以消费
- 如果消费者组中消费者个数<topic分区数,此时有个别消费者需要消费多个分区的数据
-
Consumer
- 消费者,向kafka拉取数据
-
broker kafka节点
- 用于存储分区数据
-
leader: 副本中的一个角色,
- produer写入数据以及消费者消费数据都找分区的leader
-
follower: 副本中的一个角色
- follower同步leader的数据,如果leader宕机,会选举出一个新leader
-
zookeeper:
- 后续kafka通过zk监听broker状态,leader选举等都依赖zk
-
offset: 偏移量
- offset是每个分区数据的唯一标识,后续消费者组消费分区数据之后会记录下一次应该从哪个offset拉取数据
kafka安装
kafka下载地址:http://kafka.apache.org/downloads
因为是分布式,所以我们需要配置kafka集群
集群配置
第一步:下载安装包完成后,将安装包存储到服务器中,我这里还是存储到 /opt/modult/software中
第二步:安装kafka,直接解压即可
tar -zxvf kafka安装包名称 -C /opt/module
第三步:修改kafka名称[可以选择不改]
mv /opt/module/kafka带版本号的名称 kafka
第四步:设置环境变量
sudo vim /etc/profile.d/my_env.sh
#KAFKA_HOME
export KAFKA_HOME=/opt/module/kafka
export PATH=$PATH:$KAFKA_HOME/bin
第五步:分发配置文件并重置环境变量
sudo /home/garylea/bin/xsync /etc/profile.d/my_env.sh
hadoop113、114节点分别执行
source /etc/profile.d/my_env.sh
第六步:配置kafka集群参数
#修改配置参数
vim /opt/module/kafka/config/server.properties
# 修改broker.id
broker.id=2
# 修改kafka数据保存路径
log.dirs=/opt/module/kafka/data
# 修改kafka zk的节点连接ip,指定kafka在zookeeper的存储节点名称
zookeeper.connect=hadoop112:2181,hadoop113:2181,hadoop114:2181/kafka
第七步:分发kafka到其他节点,并修改对应的broker.id
xsync /opt/module/kafka
# hadoop113的broker.id
vim /opt/module/kafka/config/server.properties
broker.id=3
# hadoop114的broker.id
vim /opt/module/kafka/config/server.properties
broker.id=4
第八步:测试启动kafka
分别启动kafka
bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties
第九步:编写一键启动脚本
- 因为启动kafka集群需要在每一台节点都运行启动命令,所以我们可以通过shell脚本来完成一键启动kafka集群
# 编写一键启动脚本
vim /home/garylea/bin/mykafka
# 编写完毕后,添加权限
chmod +x /home/garylea/bin/mykafka
#! /bin/bash
#1、判断参数是否传入
if [ $# -lt 1 ]
then
echo "必须传入参数...."
exit
fi
#2、根据参数匹配执行
case $1 in
"start")
for host in hadoop112 hadoop113 hadoop114
do
echo "=============================$host========================="
ssh $host "/opt/module/kafka/bin/kafka-server-start.sh -daemon /opt/module/kafka/config/server.properties"
done
;;
"stop")
for host in hadoop112 hadoop113 hadoop114
do
echo "=============================$host========================="
ssh $host "/opt/module/kafka/bin/kafka-server-stop.sh"
done
;;
"status")
for host in hadoop112 hadoop113 hadoop114
do
pid=$(ssh $host "ps -ef | grep server.properties | grep -v grep")
[ "$pid" ] && echo "$host kafka进程正常" || echo "$host kafka不存在或者异常"
done
;;
*)
echo "参数输入错误....."
;;
esac
kafka常用指令
通过shell指令来操作kafka,当然了,实际开发中,我们使用的API来操作kafka
topic相关
# 1、创建topic:
bin/kafka-topics.sh --create --boostrap-server borker主机:9092,broker主机:9092,.. --partitions 分区数 --replication-factor 副本数 --topic topic名称
# 2、查看集群所有的topic:
bin/kafka-topics.sh --list --boostrap-server borker主机:9092,broker主机:9092,..
# 3、查看某个topic详细信息:
bin/kafka-topics.sh --describe --boostrap-server borker主机:9092,broker主机:9092,.. --topic topic名称
# 4、修改topic[只能修改分区数,只能增大分区]:
bin/kafka-topics.sh --alter --topic topic名称 --boostrap-server borker主机:9092,broker主机:9092,.. --partitions 分区数
# 5、删除topic:
bin/kafka-topics.sh --delete --topic topic名称 --boostrap-server borker主机:9092,broker主机:9092,..
生产者相关
bin/kafka-console-producer.sh --broker-list borker主机:9092,broker主机:9092,.. --topic topic名称
消费者相关:
bin/kafka-console-consumer.sh --boostrap-server borker主机:9092,broker主机:9092,.. --topic topic名称 [--from-beginning] [--group 消费者组id] --from-beginning : 代表消费者从最开始的offset开始消费
总结
本章介绍了kafka的基本概念、安装以及shell相关操作指令,下一章,为大家带来kafka的原理介绍
以上是关于打怪升级之小白的大数据之旅(七十四)<初识Kafka>的主要内容,如果未能解决你的问题,请参考以下文章