《我想进大厂》之JVM夺命连环10问
Posted Javachichi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了《我想进大厂》之JVM夺命连环10问相关的知识,希望对你有一定的参考价值。
1. 说说 JVM 的内存布局?

Java 虚拟机主要包含几个区域:
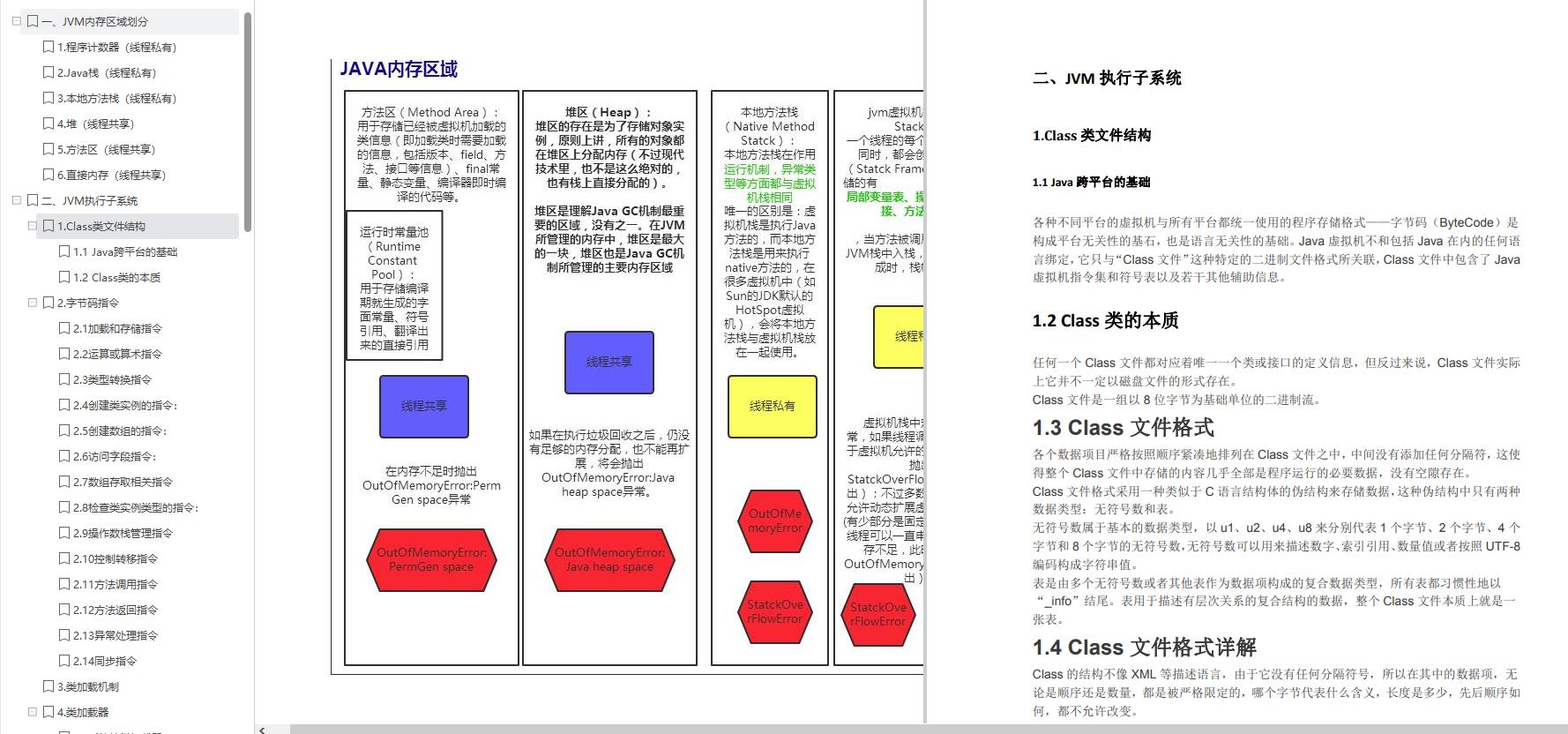
堆:堆是 Java 虚拟机中最大的一块内存,是线程共享的内存区域,基本上所有的对象实例数组都是在堆上分配空间。堆区细分为 Young 区年轻代和 Old 区老年代,其中年轻代又分为 Eden、S0、S1 3个部分,他们默认的比例是 8:1:1 的大小。
栈:栈是线程私有的内存区域,每个方法执行的时候都会在栈创建一个栈帧,方法的调用过程就对应着栈的入栈和出栈的过程。每个栈帧的结构又包含局部变量表、操作数栈、动态连接、方法返回地址。
局部变量表用于存储方法参数和局部变量。当第一个方法被调用的时候,它的参数会被传递至从0开始的连续的局部变量表中。
操作数栈用于一些字节码指令从局部变量表中传递至操作数栈,也用来准备方法调用的参数以及接收方法返回结果。
动态连接用于将符号引用表示的方法转换为实际方法的直接引用。
元数据:在 Java1.7 之前,包含方法区的概念,常量池就存在于方法区(永久代)中,而方法区本身是一个逻辑上的概念,在1.7之后则是把常量池移到了堆内,1.8之后移出了永久代的概念(方法区的概念仍然保留),实现方式则是现在的元数据。它包含类的元信息和运行时常量池。
class 文件就是类和接口的定义信息。
运行时常量池就是类和接口的常量池运行时的表现形式。
本地方法栈:主要用于执行本地 native 方法的区域。
程序计数器:也是线程私有的区域,用于记录当前线程下虚拟机正在执行的字节码的指令地址。
2. 知道 new 一个对象的过程吗?

当虚拟机遇见 new 关键字时候,实现判断当前类是否已经加载。如果类没有加载,首先执行类的加载机制,加载完成后再为对象分配空间、初始化等。
-
首先校验当前类是否被加载,如果没有加载,执行类加载机制;
-
加载:就是从字节码加载成二进制流的过程;
-
验证:当然加载完成之后,当然需要校验 class 文件是否符合虚拟机规范,跟我们接口请求一样,第一件事情当然是先做个参数校验了;
-
准备:为静态变量、常量赋默认值;
-
解析:把常量池中符号引用(以符号描述引用的目标)替换为直接引用(指向目标的指针或者句柄等)的过程;
-
初始化:执行 static 代码块 (cinit) 进行初始化,如果存在父类,先对父类进行初始化。
注意:静态代码块是绝对线程安全的,只能隐式被 Java 虚拟机在类加载过程中初始化调用!(此处该有问题:static 代码块线程安全吗?)
当类加载完成之后,紧接着就是对象分配内存空间和初始化的过程:
-
首先为对象分配合适大小的内存空间;
-
接着为实例变量赋默认值;
-
设置对象的头信息,对象 hashcode、GC 分代年龄、元数据信息等;
-
执行构造函数 (init) 初始化。
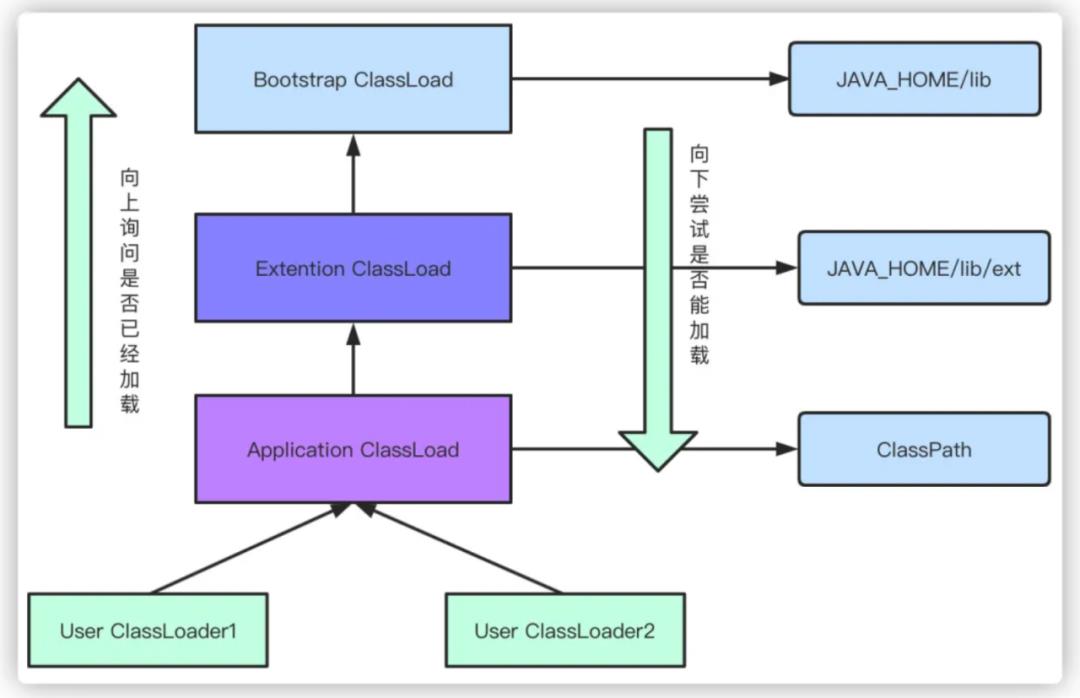
3. 知道双亲委派模型吗?
类加载器自顶向下分为:
-
Bootstrap ClassLoader(启动类加载器):默认会去加载 JAVA_HOME/lib 目录下的 jar;
-
Extention ClassLoader(扩展类加载器):默认去加载 JAVA_HOME/lib/ext 目录下的 jar;
-
Application ClassLoader(应用程序类加载器):比如我们的 Web 应用,会加载 Web 程序中 ClassPath 下的类;
-
User ClassLoader(用户自定义类加载器):由用户自己定义。
当我们在加载类的时候,首先都会向上询问自己的父加载器是否已经加载。如果没有则依次向上询问;如果没有加载,则从上到下依次尝试是否能加载当前类,直到加载成功。
4. 说说有哪些垃圾回收算法?
标记-清除
统一标记出需要回收的对象,标记完成之后统一回收所有被标记的对象。而由于标记的过程需要遍历所有的 GC ROOT,清除的过程也要遍历堆中所有的对象,所以标记-清除算法的效率低下,同时也带来了内存碎片的问题。
复制算法
为了解决性能的问题,复制算法应运而生。它将内存分为大小相等的两块区域,每次使用其中的一块。当一块内存使用完之后,将还存活的对象拷贝到另外一块内存区域中,然后把当前内存清空。这样性能和内存碎片的问题得以解决。但是同时带来了另外一个问题,可使用的内存空间缩小了一半!
因此,诞生了我们现在的常见的年轻代+老年代的内存结构:Eden+S0+S1 组成。因为根据 IBM 的研究显示,98%的对象都是朝生夕死,所以实际上存活的对象并不是很多,完全不需要用到一半内存浪费,所以默认的比例是 8:1:1。
这样,在使用的时候只使用 Eden 区和 S0、S1 中的一个,每次都把存活的对象拷贝另外一个未使用的 Survivor 区,同时清空 Eden 和使用的 Survivor,这样下来内存的浪费就只有10%了。
如果最后未使用的 Survivor 放不下存活的对象,这些对象就进入 Old 老年代了。
注意:所以有一些初级点的问题会问你,为什么要分为 Eden 区和2个 Survior 区?有什么作用?就是为了节省内存和解决内存碎片的问题。这些算法都是为了解决问题而产生的,如果理解原因你就不需要死记硬背了。
标记-整理
针对老年代再用复制算法显然不合适,因为进入老年代的对象都存活率比较高了,这时候再频繁的复制对性能影响就比较大,而且也不会再有另外的空间进行兜底。所以针对老年代的特点,通过标记-整理算法,标记出所有的存活对象,让所有存活的对象都向一端移动,然后清理掉边界以外的内存空间。
5. 什么是 GC ROOT?有哪些 GC ROOT?
上面提到的标记的算法,怎么标记一个对象是否存活?简单的通过引用计数法,给对象设置一个引用计数器,每当有一个地方引用他,就给计数器+1,反之则计数器-1,但是这个简单的算法无法解决循环引用的问题。
Java 通过可达性分析算法来达到标记存活对象的目的,定义一系列的 GC ROOT 为起点。从起点开始向下开始搜索,搜索走过的路径称为引用链。当一个对象到 GC ROOT没有任何引用链相连的话,则对象可以判定是可以被回收的。
而可以作为 GC ROOT 的对象包括:
-
栈中引用的对象;
-
静态变量、常量引用的对象;
-
本地方法栈 native 方法引用的对象。
6. 垃圾回收器了解吗?年轻代和老年代都有哪些垃圾回收器?

年轻代的垃圾收集器包含有 Serial、ParNew、Parallell。老年代则包括 Serial Old 老年代版本、CMS、Parallel Old 老年代版本和 JDK11 中全新的 G1 收集器。
Serial:单线程版本收集器,进行垃圾回收的时候会 STW(Stop The World),也就是进行垃圾回收的时候其他的工作线程都必须暂停。
ParNew:Serial 的多线程版本,用于和 CMS 配合使用。
Parallel Scavenge:可以并行收集的多线程垃圾收集器。
Serial Old:Serial 的老年代版本,也是单线程。
Parallel Old:Parallel Scavenge 的老年代版本。
CMS(Concurrent Mark Sweep):CMS 收集器是以获取最短停顿时间为目标的收集器。相对于其他的收集器 STW 的时间更短暂,可以并行收集是它的特点,同时它基于标记-清除算法。整个 GC 过程分为4步:
-
初始标记:标记 GC ROOT 能关联到的对象,需要 STW;
-
并发标记:从 GCRoots 的直接关联对象开始遍历整个对象图的过程,不需要 STW;
-
重新标记:为了修正并发标记期间,因用户程序继续运作而导致标记产生改变的标记,需要 STW;
-
并发清除:清理删除掉标记阶段判断的已经死亡的对象,不需要 STW。
从整个过程来看,并发标记和并发清除的耗时最长,但是不需要停止用户线程。而初始标记和重新标记的耗时较短,但是需要停止用户线程。总体而言,整个过程造成的停顿时间较短,大部分时候是可以和用户线程一起工作的。
G1(Garbage First):G1 收集器是 JDK9 的默认垃圾收集器,不再区分年轻代和老年代进行回收。
7. G1的原理了解吗?

G1 作为 JDK9 之后的服务端默认收集器,不再区分年轻代和老年代进行垃圾回收。
把内存划分为多个 Region,每个 Region 的大小可以通过 -XX:G1HeapRegionSize 设置,大小为1~32M。
对于大对象的存储则衍生出 Humongous 的概念。超过 Region 大小一半的对象会被认为是大对象,而超过整个 Region 大小的对象被认为是超级大对象,将会被存储在连续的 N 个 Humongous Region 中。
G1 在进行回收的时候会在后台维护一个优先级列表,每次根据用户设定允许的收集停顿时间优先回收收益最大的 Region。
G1 的回收过程分为以下四个步骤:
-
初始标记:标记 GC ROOT 能关联到的对象,需要 STW;
-
并发标记:从 GCRoots 的直接关联对象开始遍历整个对象图的过程,扫描完成后还会重新处理并发标记过程中产生变动的对象;
-
最终标记:短暂暂停用户线程,再处理一次,需要 STW;
-
筛选回收:更新 Region 的统计数据,对每个 Region 的回收价值和成本排序,根据用户设置的停顿时间制定回收计划。再把需要回收的 Region 中存活对象复制到空的 Region,同时清理旧的 Region。需要 STW。
总的来说除了并发标记之外,其他几个过程也还是需要短暂的 STW。G1 的目标是在停顿和延迟可控的情况下尽可能提高吞吐量。
8. 什么时候会触发 YGC 和 FGC?对象什么时候会进入老年代?
当一个新的对象来申请内存空间的时候,如果 Eden 区无法满足内存分配需求,则触发 YGC。使用中的 Survivor 区和 Eden 区存活对象送到未使用的 Survivor 区。
如果 YGC 之后还是没有足够空间,则直接进入老年代分配。如果老年代也无法分配空间,触发 FGC,FGC 之后还是放不下则报出 OOM 异常。

YGC 之后,存活的对象将会被复制到未使用的 Survivor 区。如果 S 区放不下,则直接晋升至老年代。
而对于那些一直在 Survivor 区来回复制的对象,通过 -XX:MaxTenuringThreshold 配置交换阈值,默认15次。如果超过次数同样进入老年代。
此外,还有一种动态年龄的判断机制,不需要等到 MaxTenuringThreshold 就能晋升老年代。如果在 Survivor 空间中相同年龄所有对象大小的总和大于 Survivor 空间的一半,年龄大于或等于该年龄的对象就可以直接进入老年代。
9. 频繁 FullGC 怎么排查?
这种问题最好的办法就是结合有具体的例子举例分析,如果没有就说一般的分析步骤。发生 FGC 有可能是内存分配不合理,比如 Eden 区太小,导致对象频繁进入老年代,这时候通过启动参数配置就能看出来,另外有可能就是存在内存泄露,可以通过以下的步骤进行排查:
1. jstat -gcutil 或者查看 gc.log 日志,查看内存回收情况。

-
S0、S1 分别代表两个 Survivor 区占比;
-
E 代表 Eden 区占比,图中可以看到使用了78%;
-
O 代表老年代,M 代表元空间,YGC 发生54次,YGCT 代表 YGC 累计耗时,GCT 代表 GC 累计耗时。

-
[GC 或 [FGC 开头代表垃圾回收的类型;
-
PSYoungGen: 6130K->6130K(9216K)] 12274K->14330K(19456K), 0.0034895 secs 代表 YGC 前后内存使用情况;
-
Times: user=0.02 sys=0.00, real=0.00 secs:user 表示用户态消耗的 CPU 时间,sys 表示内核态消耗的 CPU 时间,real 表示各种墙时钟的等待时间;
-
这两张图只是举例并没有关联关系。比如你从图里面看能到是否进行 FGC、FGC 的时间花费多长;GC 后老年代,年轻代内存是否有减少;得到一些初步的情况来做出判断。
2. dump 出内存文件在具体分析。
比如通过 jmap 命令 jmap -dump:format=b,file=dumpfile pid。导出之后再通过 Eclipse Memory Analyzer 等工具进行分析,定位到代码、修复。
这里还会可能存在一个提问的点,比如 CPU 飙高,同时 FGC 怎么办?办法比较类似:
-
找到当前进程的 pid,top -p pid -H 查看资源占用,找到问题线程;
-
printf “%x\\n” pid,把线程 pid 转为16进制,比如 0x32d;
-
jstack pid|grep -A 10 0x32d 查看线程的堆栈日志,还找不到问题继续下一步;
-
dump 出内存文件用 MAT 等工具进行分析,定位到代码、修复。
10. JVM调优有什么经验吗?
要明白一点,所有的调优的目的都是为了用更小的硬件成本达到更高的吞吐,JVM 的调优也是一样。通过对垃圾收集器和内存分配的调优达到性能的最佳。
简单的参数含义
首先,需要知道几个主要的参数含义。
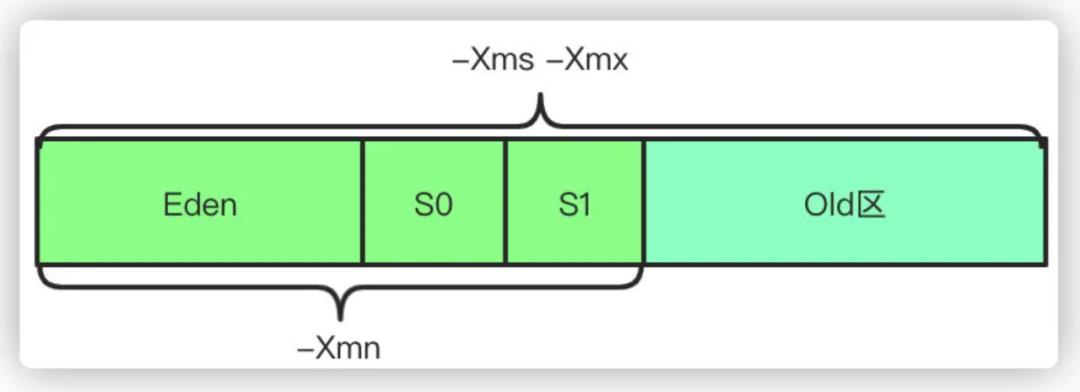
-
-Xms 设置初始堆的大小,-Xmx 设置最大堆的大小;
-
-XX:NewSize 年轻代大小,-XX:MaxNewSize 年轻代最大值,-Xmn 则是相当于同时配置 -XX:NewSize 和 -XX:MaxNewSize 为一样的值;
-
-XX:NewRatio 设置年轻代和年老代的比值。如果为3,表示年轻代与老年代比值为 1:3,默认值为2;
-
-XX:SurvivorRatio 年轻代和两个 Survivor 的比值。默认值为8,代表比值为 8:1:1;
-
-XX:PretenureSizeThreshold 当创建的对象超过指定大小时,直接把对象分配在老年代;
-
-XX:MaxTenuringThreshold 设定对象在 Survivor 复制的最大年龄阈值,超过阈值转移到老年代;
-
-XX:MaxDirectMemorySize 当 Direct ByteBuffer 分配的堆外内存到达指定大小后,即触发 Full GC。
调优
-
为了打印日志方便排查问题最好开启GC日志。开启GC日志对性能影响微乎其微,但是能帮助我们快速排查定位问题。-XX:+PrintGCTimeStamps -XX:+PrintGCDetails -Xloggc:gc.log
-
一般设置 -Xms=-Xmx。这样可以获得固定大小的堆内存,减少 GC 次数和耗时,可以使得堆相对稳定;
-
-XX:+HeapDumpOnOutOfMemoryError 让 JVM 在发生内存溢出的时候自动生成内存快照,方便排查问题;
-
-Xmn 设置新生代的大小。太小会增加 YGC,太大会减小老年代大小,一般设置为整个堆的1/4到1/3;
-
设置 -XX:+DisableExplicitGC 禁止系统 System.gc()。防止手动误触发 FGC 造成问题。
最后
其实不同成长阶段会有不同的技术能力要求,就像JVM,只有达到一定的职业高度,才会有它很重要的认知,只有弄清楚虚拟机底层原理,才能走向更高的境界。所以掌握JVM是逐渐成长为高级Java工程师的过程中不可或缺的一部分,想要升职涨薪、跳槽大厂面试加分,就必须弄清JVM的原理与调优。
在面试中,常会问一些JVM调优的面试题,其中包括内存泄漏、字符串、垃圾回收等方面。尤其是大厂,十分爱考察求职者对底层执行原理的掌握,看你到底水平有多高,如果没有对JVM进行深入的了解以及实践,那你就有很大几率会在面试中“out”,而且在要薪酬上也比较吃亏。
那么如何才能快速掌握JVM的原理与应用呢?又该怎样在面试环节拿下JVM相关的面试题,让面试官刮目相看?
学习JVM,可以让你更深入理解Java语言,还可以让你学会用基础的知识解决难题,提高工作效率。
学习完JVM可以落地的知识:
- 根据自己的业务场景选择适合自己的GC实现
- 观察gc频率优化内存的分配策略
- 根据dump日志来分析程序瓶颈位置或找出崩溃原因
- 根据JIT编译优化流程、代码
此外,还能让你的代码在写法上,更安全、更高效,避免内存溢出的问题。随着对JVM的掌握越来越多,你的收入水平以及技术能力都逐渐向高级开发工程师迈进。
适合这样的你
如果你:
- 很想掌握JVM,学会解决JVM内存溢出、内存泄露、JVM调优等问题
- 想对Java有更深入的理解,提升Java性能
- 希望面试时能够从容应对JVM的相关问题
- 想要突破25k月薪的门槛
- 正在向高级开发工程师发展进阶

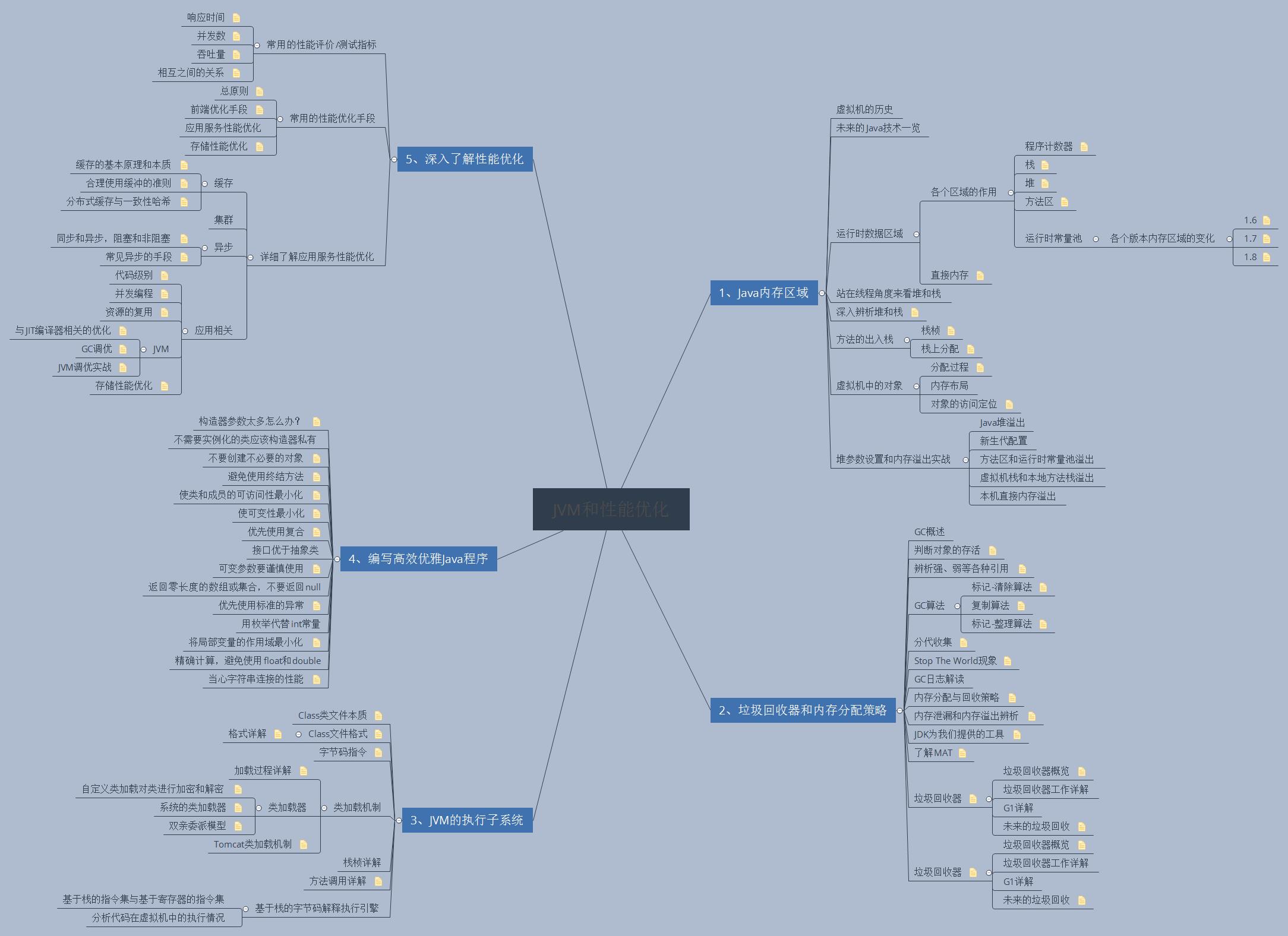
一、JVM内存区域划分
二、JVM执行子系统

三.垃圾回收器和内存分配策略

四、编写高效优雅Java程序
五、性能优化

JVM面试题总结

程序员必备书单
《Java核心知识点合集(283页)》
内容涵盖:Java基础、JVM、高并发、多线程、分布式、设计模式、Spring全家桶、Java、MyBatis、ZooKeeper、Dubbo、Elasticsearch、Memcached、MongoDB、Redis、mysql、RabbitMQ、Kafka、Linux、Netty、Tomcat、数据库、云计算等
《Java中高级核心知识点合集(524页)》
《Java高级架构知识点整理》
《1000道 互联网Java工程师面试题 (485页)》
Java各知识点综合面试专题(1000+题)
这套题库里面中包含了以下很多个模块(都有单独的PDF文档):并发编程,多线程,集合框架,设计模式,数据库,性能优化,RabbitMQ消息中间件,ActiveMQ消息中间件,Dubbo,JVM,Kafka,MongoDB,MyBatis,MySQL,Netty,nginx,Redis,Tomcat,Zookeeper,Spring,SpringBoot,SpringCloud,SpringMVC,…….
最后
小编在这里分享些我自己平时的学习资料,由于篇幅限制,pdf文档的详解资料太全面,细节内容实在太多啦,所以只把部分知识点截图出来粗略的介绍,每个小节点里面都有更细化的内容!有需要的程序猿(媛)可以在文章末尾获取免费领取方式!
程序员代码面试指南 IT名企算法与数据结构题目最优解
这是” 本程序员面试宝典!书中对IT名企代码面试各类题目的最优解进行了总结,并提供了相关代码实现。针对当前程序员面试缺乏权威题目汇总这一-痛点, 本书选取将近200道真实出现过的经典代码面试题,帮助广“大程序员的面试准备做到万无一失。 “刷”完本书后,你就是“题王”!
《TCP-IP协议组(第4版)》
本书是介绍TCP/IP协议族的经典图书的最新版本。本书自第1版出版以来,就广受读者欢迎。
本书最新版进行」护元,以体境计算机网络技不的最新发展,全书古有七大部分共30草和7个附录:第一部分介绍一些基本概念和基础底层技术:第二部分介绍网络层协议:第三部分介绍运输层协议;第四部分介绍应用层协议:第五部分介绍下一代协议,即IPv6协议:第六部分介绍网络安全问题:第七部分给出了7个附录。
Java开发手册(嵩山版)
这个不用多说了,阿里的开发手册,每次更新我都会看,这是8月初最新更新的**(嵩山版)**
MySQL 8从入门到精通
本书主要内容包括MySQL的安装与配置、数据库的创建、数据表的创建、数据类型和运算符、MySQL 函数、查询数据、数据表的操作(插入、更新与删除数据)、索引、存储过程和函数、视图、触发器、用户管理、数据备份与还原、MySQL 日志、性能优化、MySQL Repl ication、MySQL Workbench、 MySQL Utilities、 MySQL Proxy、php操作MySQL数据库和PDO数据库抽象类库等。最后通过3个综合案例的数据库设计,进步讲述 MySQL在实际工作中的应用。
Spring5高级编程(第5版)
本书涵盖Spring 5的所有内容,如果想要充分利用这一领先的企业级 Java应用程序开发框架的强大功能,本书是最全面的Spring参考和实用指南。
本书第5版涵盖核心的Spring及其与其他领先的Java技术(比如Hibemate JPA 2.Tls、Thymeleaf和WebSocket)的集成。本书的重点是介绍如何使用Java配置类、lambda 表达式、Spring Boot以及反应式编程。同时,将与企业级应用程序开发人员分享一些见解和实际经验,包括远程处理、事务、Web 和表示层,等等。
JAVA核心知识点+1000道 互联网Java工程师面试题
企业IT架构转型之道 阿里巴巴中台战略思想与架构实战
本书讲述了阿里巴巴的技术发展史,同时也是-部互联网技 术架构的实践与发展史。
因为文章内容实在是太多了,不能够给大家一一体现出来,每个章节都有更加细化的内容。大家需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于《我想进大厂》之JVM夺命连环10问的主要内容,如果未能解决你的问题,请参考以下文章