机器学习-白板推导系列(三十一)-生成对抗网络(GAN,Generative Adversarial Network)
Posted Paul-Huang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习-白板推导系列(三十一)-生成对抗网络(GAN,Generative Adversarial Network)相关的知识,希望对你有一定的参考价值。
31. 生成对抗网络(GAN,Generative Adversarial Network)
31.1 什么是Generative Adversarial Network?
什么是生成对抗网络(tive Adversarial Network,GAN)?顾名思义,首先它是一种生成模型,它的核心是对样本数据建模。下面举个例子来详细的说明一下什么是GAN。
-
举例说明
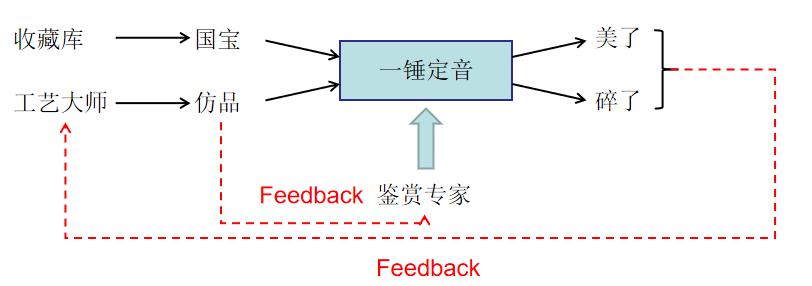
假设我是一个收藏家,但是,我最终的目标不仅仅是一个收藏家。我想高仿东西,成为工艺品大师(做仿品)。我要不惜一切代价的成为这方面的大师。但是,我做出来的东西不能只是我自己分辨不出来就够了(那就只能放在家里看),它需要接受大师们的检验,各位专家都看不出来这是仿品,就比较成功了。我把我做出的东西,放到“一锤定音”节目现场,这个平台将鉴别出为假的东西就砸了,鉴别出为真的东西就拿去估值,就美了。节目流程如下所示:

我们的目标是成为高水平的可以做“以假乱真”的高质量仿品的大师,有如下两个要求:- 高 专 家 \\color{red}高专家 高专家:鉴赏专家的水平足够高。
- 高 大 师 \\color{red}高大师 高大师:作假的水平足够高。
-
有三个量: 国 宝 本 身 , 鉴 赏 专 家 的 水 平 \\color{red}国宝本身,鉴赏专家的水平 国宝本身,鉴赏专家的水平和 作 假 的 水 平 \\color{red}作假的水平 作假的水平。
- 国宝是古人做的,静态的,不可能发生变化的。
- 而鉴赏专家的水平和作假的水平是变化的。
因此三者中,国宝是静态的,其他的都是可变化的。
-
目标: 高 做 假 的 水 平 \\color{red}高做假的水平 高做假的水平;手段: 高 水 平 的 鉴 赏 专 家 \\color{red}高水平的鉴赏专家 高水平的鉴赏专家。
-
对抗生成网络和生成模型之间的关系:如果一个仿品可以和国宝做的一模一样,不就相当于学到了真实数据的分布,可以完全模拟出真实数据。下一步则是,想办法将模型用数学语言描述。
31.2 数学语言描述
-
模型表示
通过训练,工艺大师和鉴赏专家的水平会不断的提高,最终我们会培养一个高水平的工艺大师和一个高水平的鉴赏家。而最终的目的是培养一个高水平的工艺大师,而不是一个高水平的鉴赏家。鉴赏家只是衍生品,最终将达到两个目的,1. 足够的以假乱真;2. 真正的专家看不出来。
所以需要加一些feedback,令工艺大师收到专家给出的反馈。并且鉴赏大师也要从工艺大师那里知道真实的情况来提升自己的水平。如下图所示:
因此假设:- 国宝设为
P
data
\\color{red}P_{\\text{data}}
Pdata,
{
x
i
}
i
=
1
N
\\{x_i\\}_{i=1}^N
{xi}i=1N,实际就是经验分布,通常我们将经验分布视为数据分布。
(Q:经验分布和数据分布之间的区别。)
- 自己做的工艺品,是从一个模型分布
P
g
\\color{red}P_g
Pg(g待变
g
e
n
e
r
a
t
e
r
generater
generater)采样出来的,
P
g
(
x
;
θ
g
)
\\color{red}P_g(x;\\theta_g)
Pg(x;θg)。
注:
- 我们本身不对 P g P_g Pg建模,而是用一个神经网络来逼近 P g P_g Pg。
- 因为神经网络不具备随机性,所以需要添加“
噪
声
\\color{red}噪声
噪声”。用假设
z
z
z来自一个简单分布,并增加噪声,
z
∼
P
z
(
z
)
\\color{red}z\\sim P_z(z)
z∼Pz(z)。其中,
x
=
G
(
z
;
θ
g
)
x=G(z;\\theta_g)
x=G(z;θg)

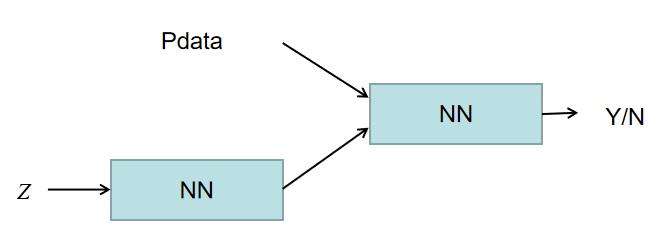
- 鉴赏专家输出的是一个概率分布,同样也是一个神经网络,
D
(
x
,
θ
d
)
\\color{red}D(x,\\theta_d)
D(x,θd)(D代表
d
i
s
c
r
i
m
i
n
a
t
i
v
e
discriminative
discriminative),其代表的是输入一个物品
x
x
x,判断其为国宝的概率。
D
→
1
\\color{red}D\\to 1
D→1是国宝,
D
→
0
\\color{red}D\\to 0
D→0是工艺品。模型如下所示:
- 国宝设为
P
data
\\color{red}P_{\\text{data}}
Pdata,
{
x
i
}
i
=
1
N
\\{x_i\\}_{i=1}^N
{xi}i=1N,实际就是经验分布,通常我们将经验分布视为数据分布。
-
目标表示
-
高专家:
高水平的专家可以正确的分辨国宝和赝品。
{ if x is from P d a t a then D ( x ) ↑ if x is from P g then 1 − D ( x ) ↑ (31.2.1) \\left\\{ \\begin{array}{ll} \\text{if $x$ is from $P_{data}$ then $D(x)$ $\\uparrow$ } & \\\\ \\text{if $x$ is from $P_{g}$ then $1-D(x)$ $\\uparrow$ } & \\\\ \\end{array} \\right.\\tag{31.2.1} {if x is from Pdata then D(x) ↑ if x is from Pg then 1−D(x) ↑ (31.2.1)
其中,我们将用对数似然函数的形式来进行表达。而 1 − D ( x ) \\color{red}1-D(x) 1−D(x)中的 x \\color{red}x x是来自 G ( z ) \\color{red}G(z) G(z)的,那么,高专家部分的目标函数为:
max D E x ∼ P d a t a [ log D ( x ) ] ⏟ 1 N ∑ i = 1 N log D ( x i ) + E x ∼ P z [ log ( 1 − D ( G ( z ) ) ) ] (31.2.2) \\color{red}\\max_D \\underbrace{\\mathbb{E}_{x\\sim P_{data}}[\\log D(x)]}_{\\frac{1}{N} \\sum_{i=1}^N \\log D(x_i)} + \\mathbb{E}_{x\\sim P_{z}}[\\log (1-D(G(z)))]\\tag{31.2.2} DmaxN1∑i=1NlogD(xi) Ex∼Pdata[logD(x)]+Ex∼Pz[log(1−D(G(z)))](31.2.2) -
高大师:
高水平的大师的目的就是要造成高水平的鉴赏专家分辨不出来的工艺品,可以表示为:
if x is from P g then log ( 1 − D ( G ( z ) ) ) ↑ (31.2.3) \\text{if $x$ is from $P_g$ then $\\log(1-D(G(z)))$ $\\uparrow$}\\tag{31.2.3} if x is from Pg then log(1−D(G(z))) ↑(31.2.3)
此目标表达为数学语言即为:
m i n G E以上是关于机器学习-白板推导系列(三十一)-生成对抗网络(GAN,Generative Adversarial Network)的主要内容,如果未能解决你的问题,请参考以下文章
-