HDFS中的block
Posted 大数据熊猫人
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了HDFS中的block相关的知识,希望对你有一定的参考价值。
Hadoop中的HDFS组件是专门存储数据的。
分布式存储
原理可以参考之前写的一篇文章:
HDFS存储数据在DataNode节点,而datanode节点里是分为一个个block存数据的。
Block的意义:
因为,读磁盘需要寻道时间,随机读会造成寻道的时间比真正读出磁盘内容的时间占比过大。人们发现规律,读取当前数据时候,很大可能会读取前后附近的数据。这不如直接就读出一大片数据算了。一整块数据读到内存里只要寻道一次,还高效。
而且大文件数据可能一个地方放不下,需要被拆开一块一块放多个电脑存储。所以block的的出现是很有现实意义的。
那Block设置该多大多小合适?
BlockSize设置过小:
Hdfs的block存储目的在于减小磁盘寻道时间,使得数据传输时间占据总时间的绝大部分,而磁盘寻道时间占据很小部分,比如1%;
假如1T文件存储进hdfs,默认128M一个block。
该文件所需要的block数量:1T/128M=1024*1024M/128M=8096
MapReduce的map任务中通常一次只处理一个块中数据(切片大小默认等于block大小)
那么就存在8096个map任务,map任务个数太多影响处理效率(mapreduce 中的 `map 和 reduce 都是 jvm 进程,每次启动都需要重新申请资源,启动时间大概1s`;想象一下如果是8096个block,那么单独启动map进程事件就需要8096秒)。
而且namenode作为存储block的描述信息(元数据),block过多,namenode要记录很多数据,压力也大。
这时候就可以将blocksize设置更大些,比如256M或者512M。
BlockSize设置过大
同样以1T的文件为例,如果将blocksize设置为128G,那么:
该文件所需要的block数量:1T/128G=1024G/128G=8
那么就存在8个map任务(如果小于计算节点数量),map任务个数太少,集群资源无法充分利用,影响处理效率。
从2.点几往后的版本开始block size的默认大小为128M,之前版本的默认值是64M.
这个block的大小是可以个性化调节的。
看我们存一个大文件进去hdfs,是什么效果。
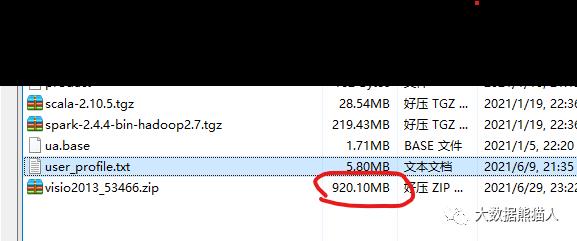
命令:hdfs dfs -put /usr/local/src/visio2013_53466.zip /hadoop_test
传文件到hdfs
50070端口看hdfs的web界面
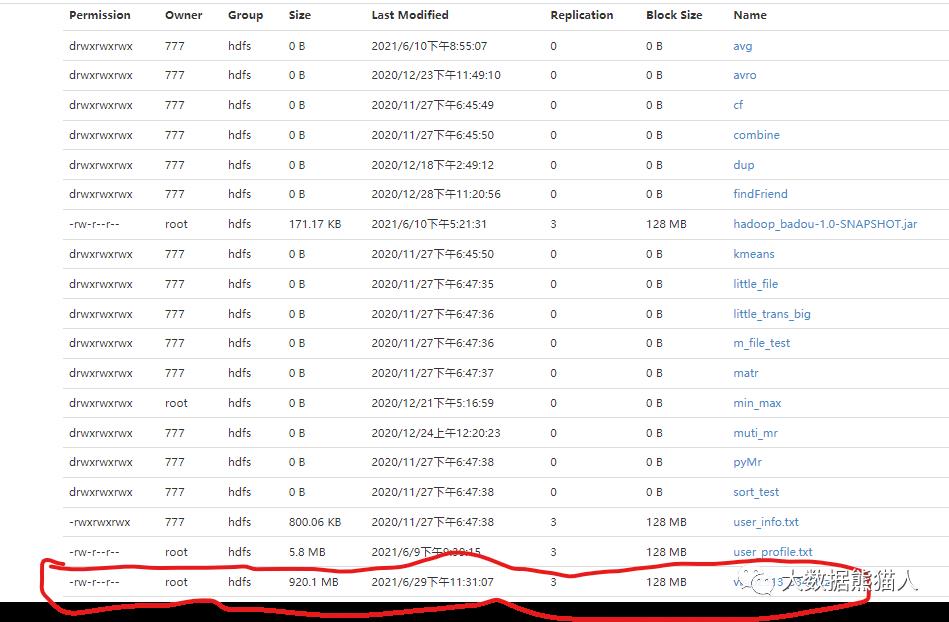
上传了,发现blockSize是默认的128M,size(实际文件大小)为920.1M.
继续点开visio这个文件看看详细
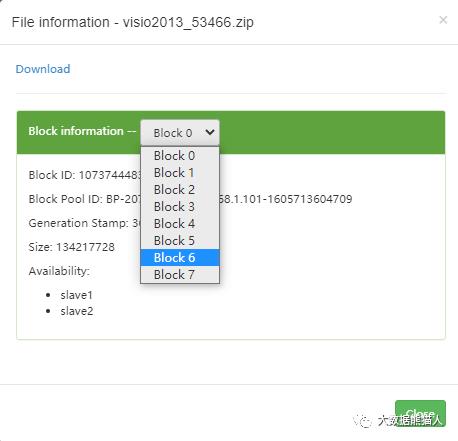
Block信息显示是有8个block
算一下,128M*8=1024M
1024刚好可以装下920.1M的内容。
为什么是8个呢。
当存满一个block,hdfs就把剩下的装到下一个block,依次类推。
到装满7个block的时候128M*7=896M
896M<920.1M
还不够,那就再存到下一个block
所以第8个block存的是920.1-896=24.1M内容。
看第1个0号block
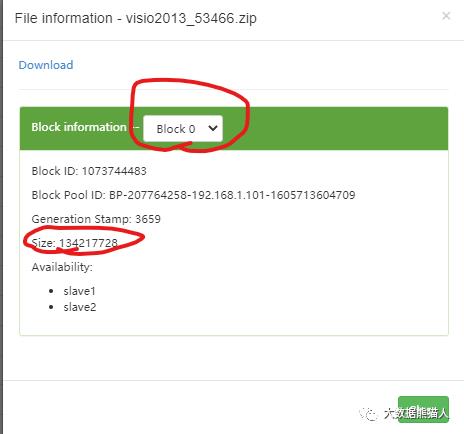
看第7个6号block
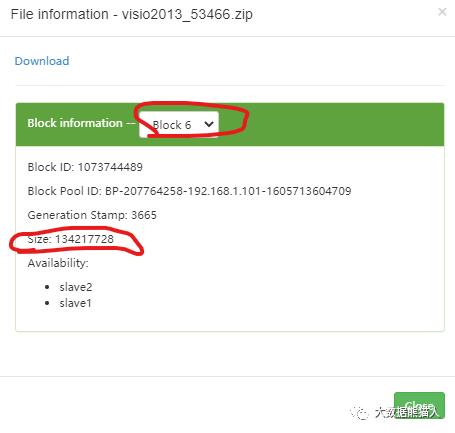
看最后一个7号block
第一个一直到第七个block都装满了,一样的size。而第八个就是装剩下的,size比较小。
实际占存储空间是由谁决定的?
920.1,用了8个128M的block。
实际存储空间是用了920.1M,而非128*8=1024M
第8个block的24.1M,代表实际存储容量就24.1,而非128M。
BlockSize 128M只是个标记,代表当一个block装满到128M的限度了就触发用一个新的block来存储。
往期文章
关注我
以上是关于HDFS中的block的主要内容,如果未能解决你的问题,请参考以下文章