数据流中的中位数,我轻敌了
Posted Big sai
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了数据流中的中位数,我轻敌了相关的知识,希望对你有一定的参考价值。
前言
大家好,我是bigsai。最近轻敌了一个高频问题,分享给大家。
最近面试时候遇到一个非常有意思的hard题,面试官没让写代码让说思路,但放在正常应届生招聘那可能就要手撕了,在剑指offer的第41题和力扣【数据流中的中位数】。
题目描述是这样的:
中位数是有序列表中间的数。如果列表长度是偶数,中位数则是中间两个数的平均值。
例如,
[2,3,4] 的中位数是 3
[2,3] 的中位数是 (2 + 3) / 2 = 2.5
设计一个支持以下两种操作的数据结构:
void addNum(int num) - 从数据流中添加一个整数到数据结构中。
double findMedian() - 返回目前所有元素的中位数。
其实问题也很简单,也就是一组数据,找出它的中位数,然后有所不同的是这组数据可能会新增一些其他数据,也就是要我们自己维护这么一个数据结构去尽量高效的完成它。
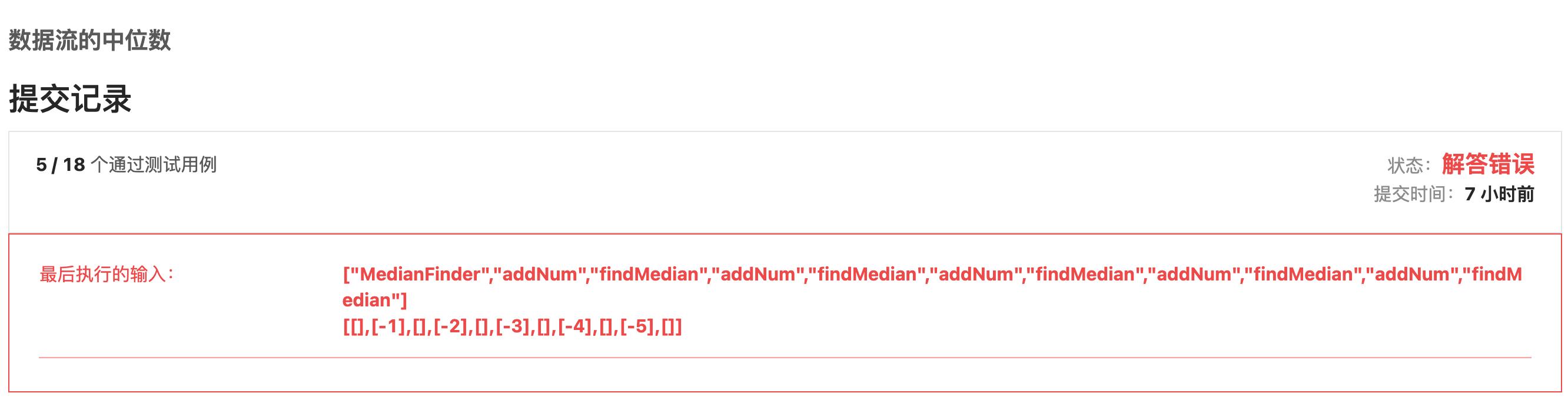
我打开这题力扣上的额描述,它好像就在诱惑我,告诉我什么!

然后我就以为真实的数据就在这个范围,然后一顿操作猛如虎,一提交直接GG。不过这个问题是个非常好的问题,等到后面讲,仔细先看看!
好了不多说了,我们进入正题,看看这个经典问题到底如何分析。
小白级别方法(无脑排序)
这个问题的解决老少皆宜,小白也有小白的方法,题不在难,能过就行(只对小白有效哇)。
一组数据存储,我用数组、List都可以,而中位数,其实就是中间一个(偶数两个均值)数,这个也好办啊,排序啊!
一个ArrayList()海纳百川(不定长数组可以存储数据),一行Arrays.sort()走天下。用编程语言中已经存在的集合和API可以轻松实现!
分析一下这个算法的时间复杂度,每次插入时候需要排序 nlogn,查询时间近O(1);次数多的话时间复杂度还是蛮高的。
具体代码为:
/** initialize your data structure here. */
public MedianFinder() {
}
List<Integer>list=new ArrayList<>();
public void addNum(int num) {
list.add(num);
list.sort(null);
}
public double findMedian() {
if(list.size()%2==1)
return list.get(list.size()/2);
else {
return (double) (list.get((list.size()-1)/2)+list.get(list.size()/2))/2;
}
}
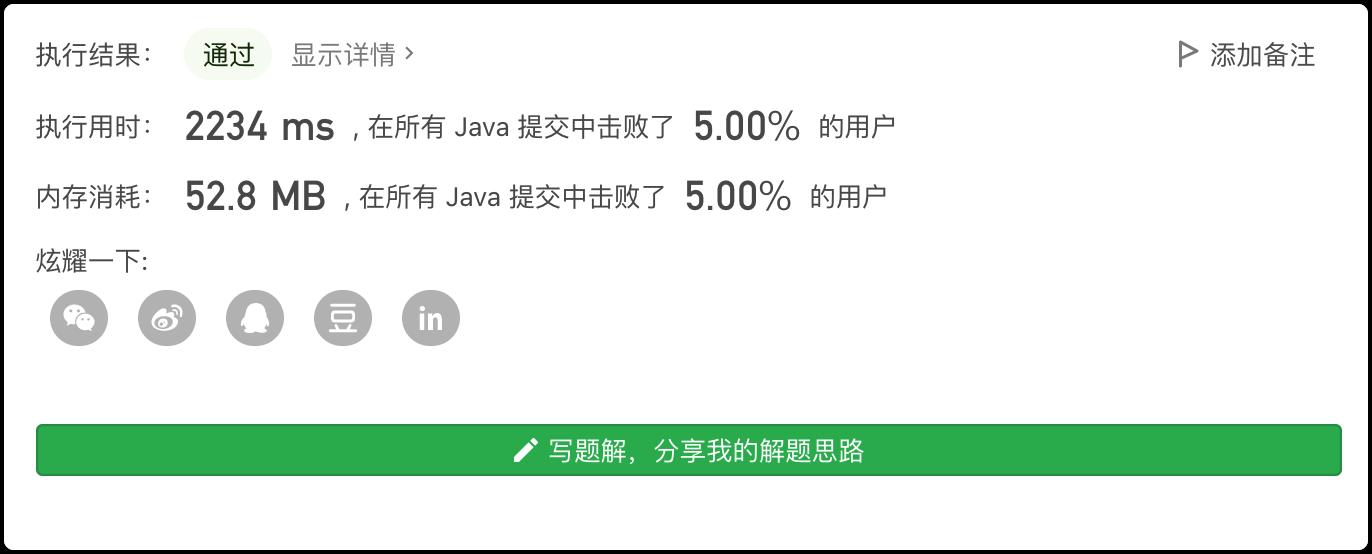
一看结果,2000+ms,这也是一种极限了,这种方法仅限于小白,只为求过。
大白级别的方法(插入排序)
大白比小白稍微强一点,比较它大一点嘛,懂得多一点。
大白看到:**这个序列刚开始没有!**然后一点一点在原有的基础上增加长度,如果每次都打乱排序那代价有点高!所以能不能复用上次已经排好序的结果?
这不就插入排序嘛!
每次新来元素相当于插入排序的最后一步使他有序,然后在插入……
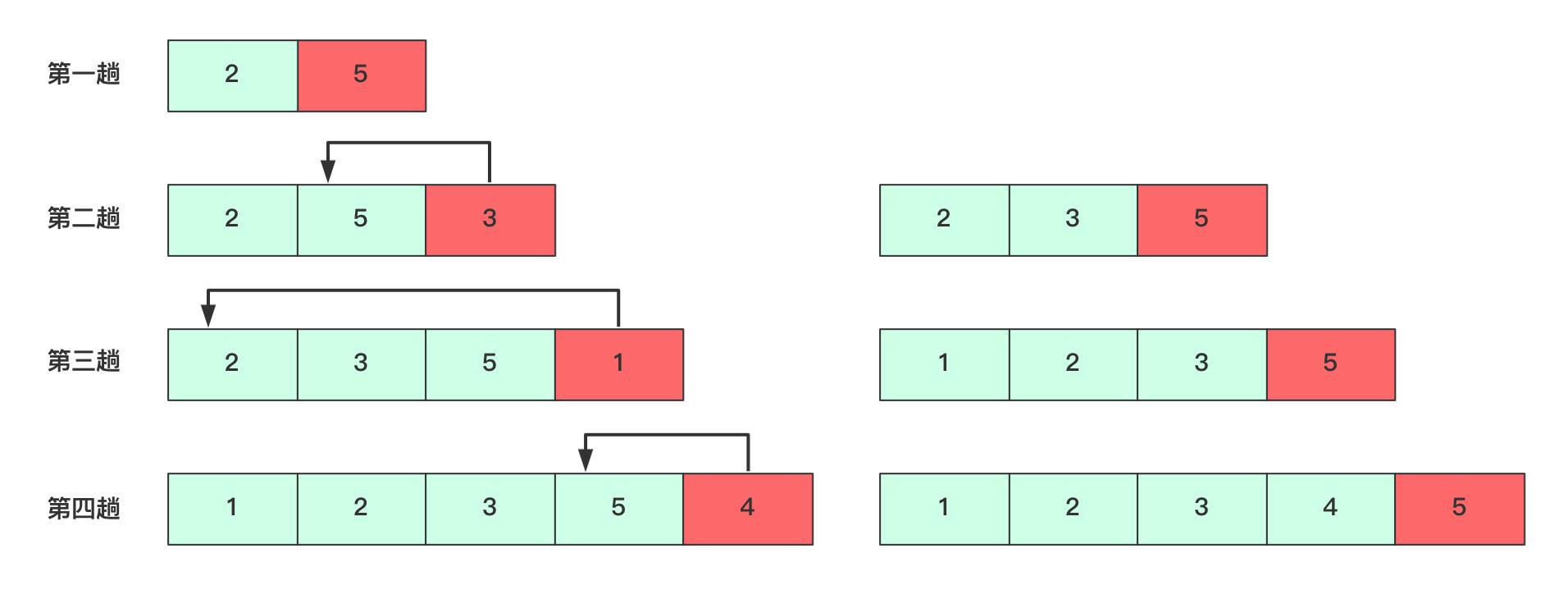
这个流程每次插入的时候由两个部分组成,查找和移动,其中查找花费O(n),插入也是O(n)。时间复杂度依然是O(n)。
可以维护常数表示数据总个数,查找中位数时候可以直接根据数量查找,时间复杂度为O(1).这样的时间复杂度在插入上优化为O(n)相比O(nlogn)有很大的提升。
但是聪明的大白还能发现一些闪光点,数组前面有序的,只是插入最后一个元素需要锁定在有序顺序结构中的位置,线性一个个查找太耗时了哇!这明显就是一个二分应用的场景么!可以使用二分法找到插入的位置,然后插入。
二分+插入的时间复杂度是多少呢?
记住,不是O(logn),二分查找每一次的时间复杂度确实是O(logn),但插入操作的时间复杂度依旧是O(n),总的时间复杂度取最高量级 O(logn)+O(n)=O(n)。
所以这里以后如果遇到某个面试官问你:插入排序使用二分查找优化时间复杂度是多少?你一定要坚定的回答:是O(n2),从单词操作来看,虽然查询变为O(logn)但是插入依旧O(n),所以n个数时间复杂度依旧为O(n2)。
好了既然解释清楚,一顿操作猛如虎,直接上代码:
class MedianFinder {
/** initialize your data structure here. */
public MedianFinder() {
}
int arr[]=new int[50000];
int count=0;
public void addNum(int num) {
int low=0,high=count-1;
while (low <= high) {
int mid = (low + high) / 2;
int midVal = arr[mid];
if (midVal < num)
low = mid + 1;
else if (midVal > num)
high = mid-1 ;
else
low++;
}
for(int i=count-1;i>=low;i--){
arr[i+1]=arr[i];
}
arr[low]=num;
count++;
}
public double findMedian() {
if(count%2==1)
return arr[count/2];
else
return (double) (arr[count/2-1]+arr[count/2])/2;
}
}
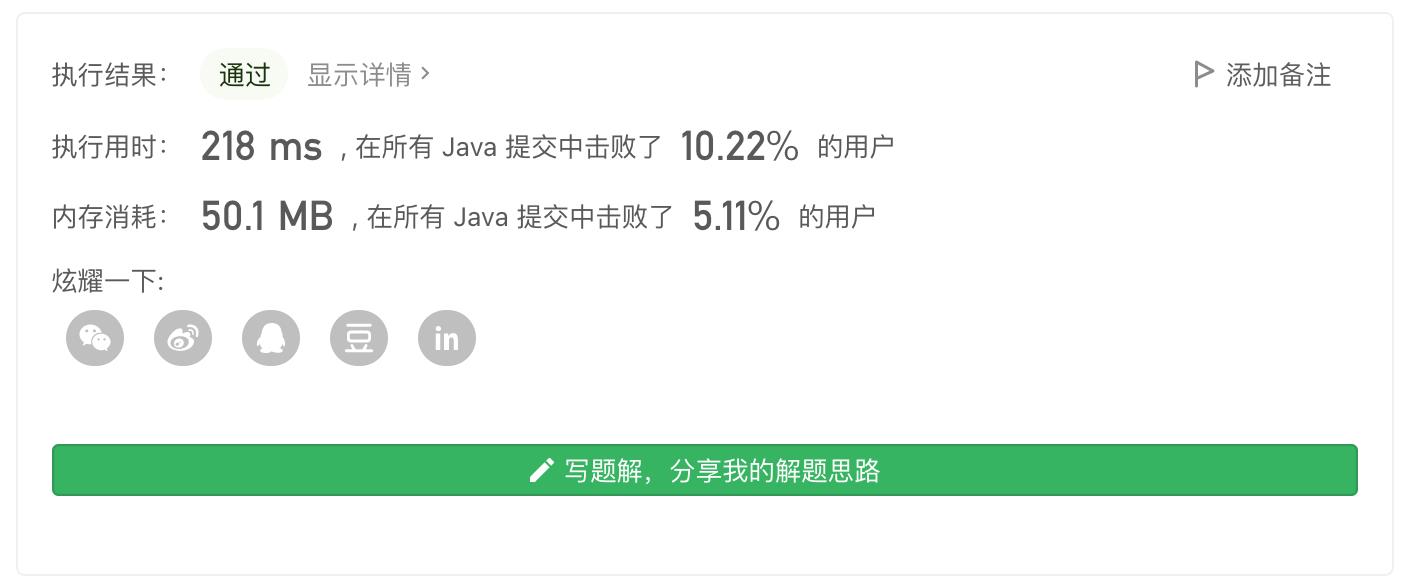
提交之后,200+ms,比起前面小白的无脑排序优化了很多,但只击败了10%用户,说明方法还是不够好,还是很白。
大佬的解法(双堆/优先队列)
这个问题的话其实也能想出来,但是确实除了这个问题没见到两个队这么玩的,也算是打开眼界一回。
在前面,我们讲过堆排序 和优先队列的原理 ,里面详细的讲解了 堆这种数据结构,我们简单回顾一下堆:
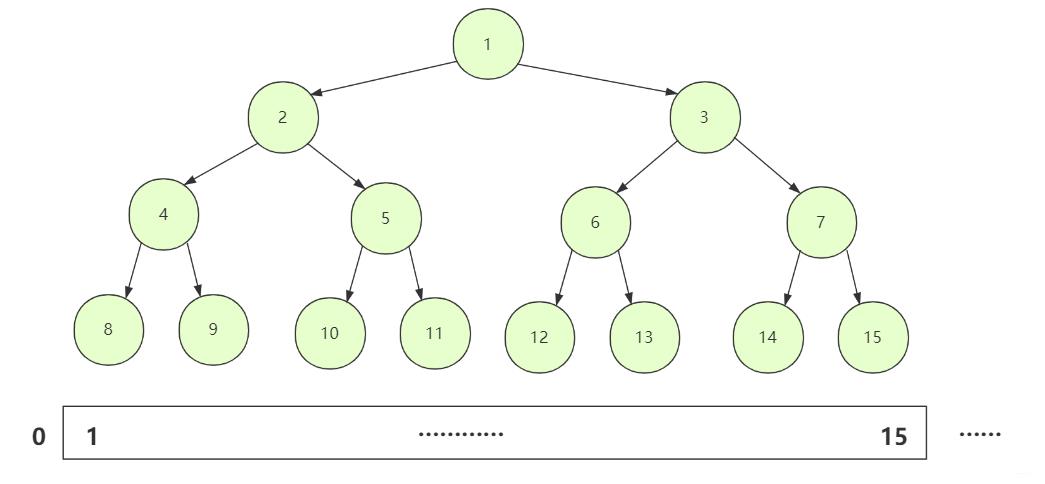
堆是一种完全二叉树(即最后一层从左向右存在节点连续),因为是完全二叉树我们经常用数组存储,可以通过二叉树下标转换很好的锁定位置进行交换。
堆分为大根堆和小根堆:
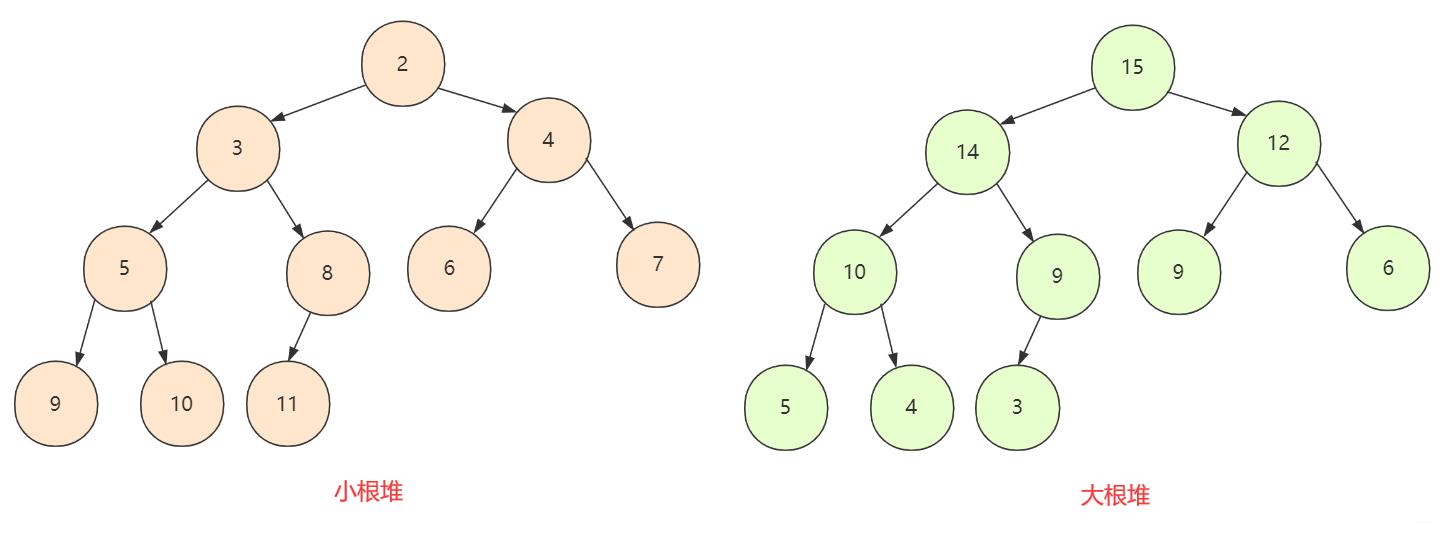
如果所有节点大于孩子节点值,那么这个堆叫做大根堆,堆的最大值在根节点。
如果所有节点小于孩子节点值,那么这个堆叫做小根堆,堆的最小值在根节点。
了解完这些基本解决这题就够了,这里不需要知道堆、优先队列的具体实现。但是堆和优先队列,怎么应用到这个中位数查找呢?
这个就很巧妙了,我们将数据等半到两个堆中,其中一个是小根堆,一个是大根堆,小根堆存最大的一半数据,大的中最小的在堆顶;大根堆存最小的一半数据,小的中最大的在堆顶,中位数就只可能在两个堆顶部分产生啦!
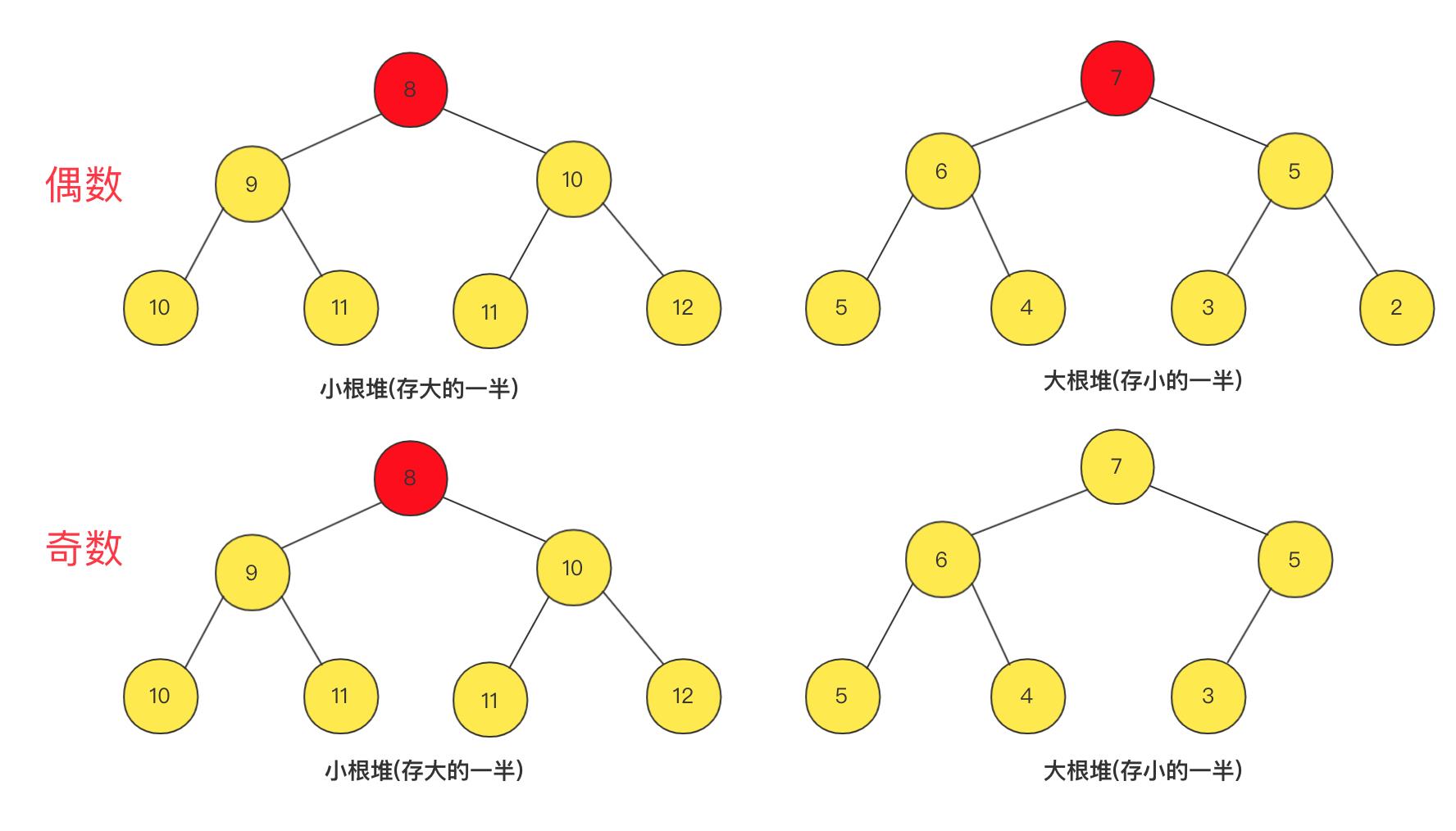
但是在具体实现过程中,也有很多需要注意的地方,再添加时候要先判断和其中一个堆顶比较大小,应该加到哪一个堆(优先队列)中,但是添加之后可能数值一直递增很大或者数值一直递减很小可能造成两个堆元素数量不平衡,那么就要将其中少的加到多的中。
这里我在实现的时候约束小根堆的元素个数等于大根堆个数(偶数)或者等于大根堆个数加一(奇数),在奇数情况就直接取小根堆顶返回即可。因为Java已经实现优先队列,你不需要详细实现其中细节(大佬可以试试参考以前我写的优先队列实现)。
分析这个时间复杂度,每个堆插入、删除的时间复杂度级别是O(log n/2),即使如果面临元素平衡可能多操作两次,但是时间复杂度还是O(logn)级别。比起O(n)快了不少,数据量越大体现越明显。
具体代码为:
class MedianFinder {
/** initialize your data structure here. */
public MedianFinder() {
}
Queue<Integer>q1=new PriorityQueue<>();//小根堆 放大的数据
//大根堆
Queue<Integer>q2=new PriorityQueue<>(new Comparator<Integer>() {
@Override
public int compare(Integer o1, Integer o2) {
return o2-o1;
}
});
public void addNum(int num) {
if(q1.isEmpty())
q1.add(num);
else if(num>q1.peek()){//插入到小根堆
q1.add(num);
if (q1.size()>q2.size()+1){
q2.add(q1.poll());
}
}
else{//插入到大根堆
q2.add(num);
if (q2.size()>q1.size()){
q1.add(q2.poll());
}
}
}
public double findMedian() {
if(q1.size()==q2.size())
return (double)(q1.peek()+q2.peek())/2;
else
return q1.peek();
}
}
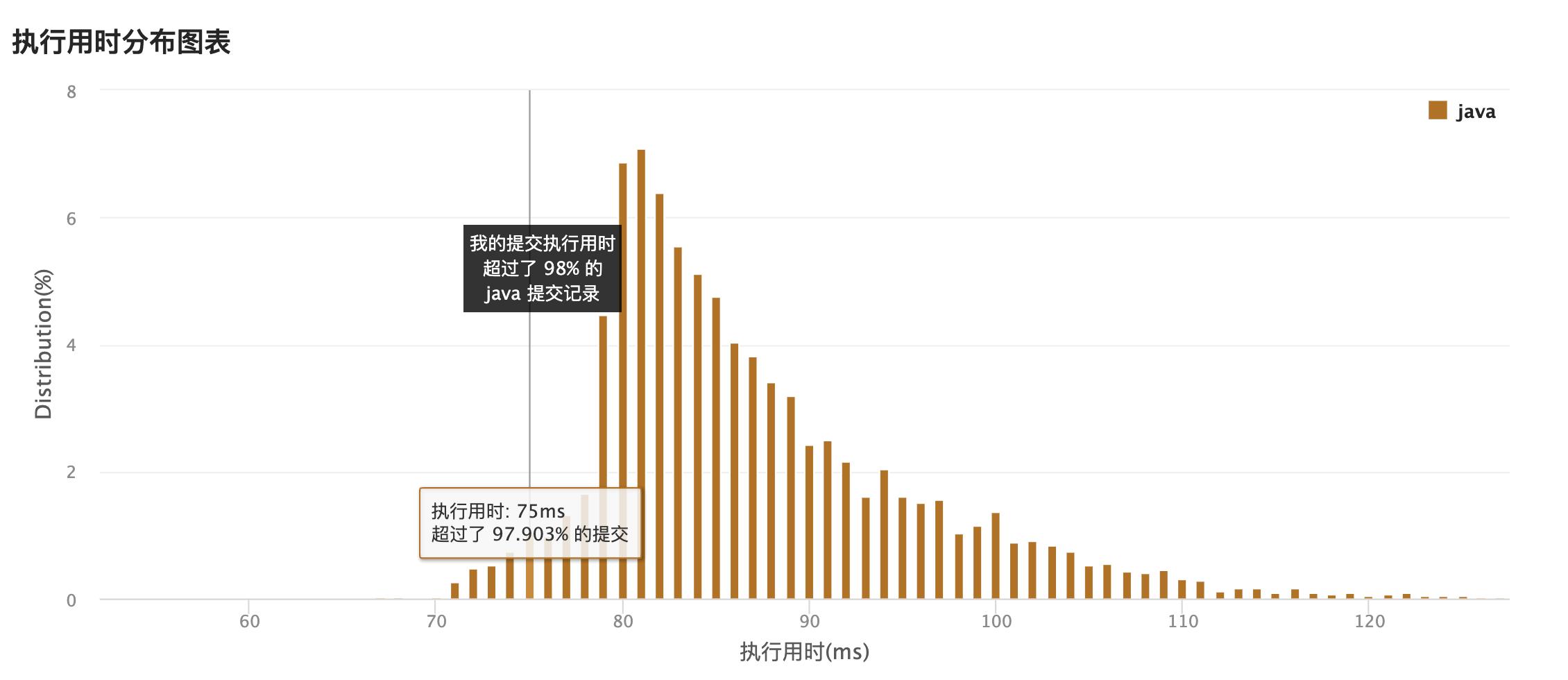
执行区间75ms,比起上一个大白又好很多,这个双堆,真的太妙了!我也是第一次见。
提升
对于这个问题,还有一些妖魔鬼怪用二叉搜索树来做,理论上也是可行的,插入效率不一定很稳定,查询效率比较低(二叉树的中序排序)。
但是文初提到的场景问题还是要仔细思考一下,面试场景很可能会问到:
1.如果数据流中所有整数都在 0 到 100 范围内,你将如何优化你的算法?
2.如果数据流中 99% 的整数都在 0 到 100 范围内,你将如何优化你的算法?
对于第一个问题,应该用什么方法优化呢?
如果还是采用传统的双堆,如果数据量非常大的情况下,效率肯定还是有优化空间,当数据比较集中分布的时候,肯定要考虑计数排序啊!
如果数据分布在0-100之间,可以直接开一个101大小的数组,遇到一个数就将其对应位置值加一,不光0-100 可以这样,在某个范围内都可以通过移动表示。
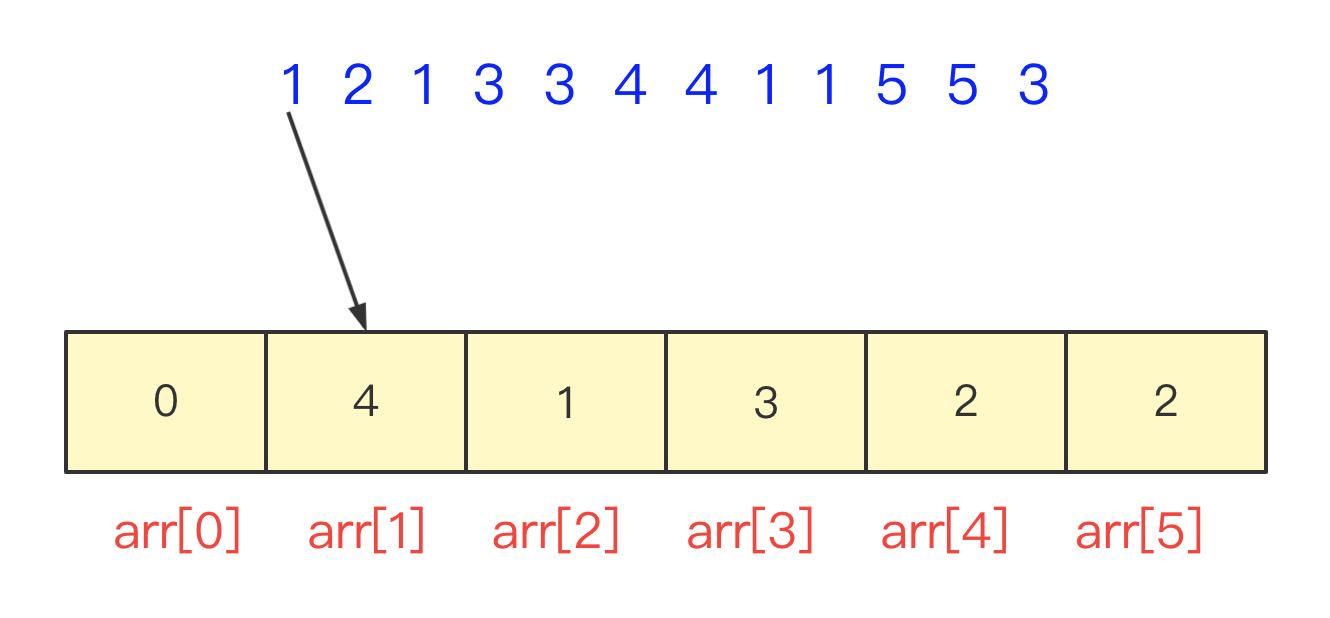
然后你找到中位数,只需要枚举叠加找到中间位置的数啦。
不过你可以再进行优化,将这个计数排序修改一下,用数组值表示小于当前位置值的个数。这样这个数组值是连续递增的,查找的时候还可以使用二分优化。
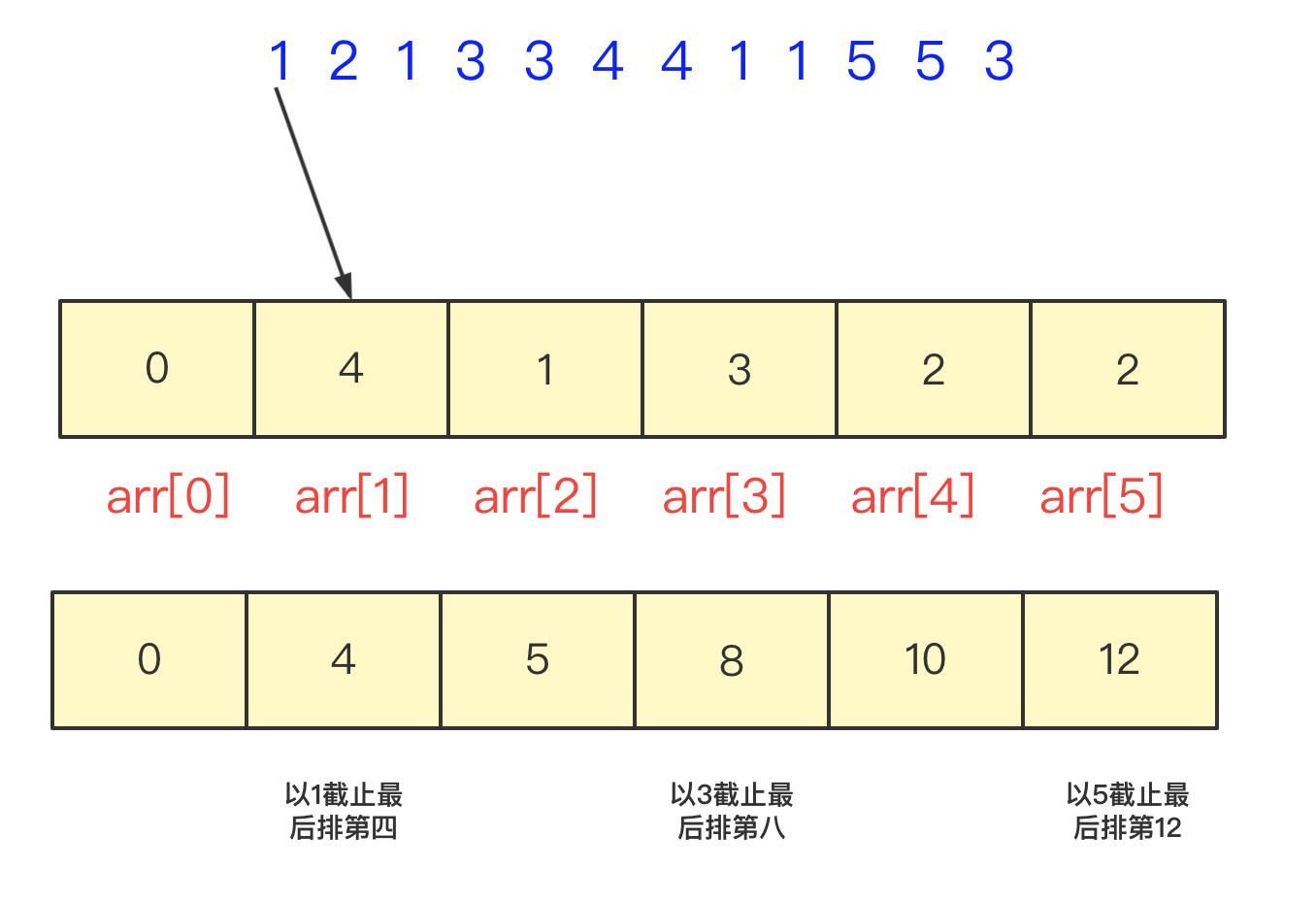
不过具体实现上,可能还有一些你需要考虑的,分析算法复杂度,每次插入操作,对应小标以及之后值都要加一,所以操作次数不超过50,而查询操作使用二分法也不超过10次,所以在数据比较集中 数据个数很多有大量重复情况,使用计数排序是非常好的。
另外,如果99%在0-100范围内也很容易哇,就是在前后边缘特意设置0和102,超过100的放到102号,小于0的放到0位置,剩下每次来x放x+1位置,因为中位数肯定出现在0-100所以这个依旧可行!
本文收藏再开源数据结构与算法仓库中:
https://github.com/javasmall/bigsai-algorithm
关于作者
bigsai,在读研一,手握腾讯、字节实习offer,蓝桥杯国一选手,专注于数据结构与算法、Java领域的知识分享,喜欢用图将复杂内容简单化,欢迎关注同名公众号【
bigsai】,坚持输出干货,如果有学习、实习、考研、选择等问题欢迎交流!
以上是关于数据流中的中位数,我轻敌了的主要内容,如果未能解决你的问题,请参考以下文章