DL4J实战之四:经典卷积实例(GPU版本)
Posted 程序员欣宸
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了DL4J实战之四:经典卷积实例(GPU版本)相关的知识,希望对你有一定的参考价值。
欢迎访问我的GitHub
这里分类和汇总了欣宸的全部原创(含配套源码):https://github.com/zq2599/blog_demos
本篇概览
- 作为《DL4J实战》的第四篇,今天咱们不写代码,而是为今后的实战做些准备:在DL4J框架下用GPU加速深度学习的训练过程;
- 如果您电脑上有NVIDIA显卡,并且成功的安装了CUDA,那么就随本文一起实际操作吧,全文由以下内容构成:
- 软硬件环境参考信息
- DL4J的依赖库和版本
- 使用GPU的具体操作步骤
- GPU训练和CPU训练对比
软硬件环境参考信息
- 众所周知,欣宸是个穷人,因此带NVIDIA显卡的电脑就是一台破旧的联想笔记本,相关信息如下:
- 操作系统:Ubuntu16桌面版
- 显卡型号:GTX950M
- CUDA:9.2
- CPU:i5-6300HQ
- 内存:32G DDR4
- 硬盘:NvMe 1T
- 实际证明,以上配置可以顺利运行《DL4J实战之三:经典卷积实例(LeNet-5)》一文中的实例,并且可以通过GPU加速训练(GPU和CPU的对比数据会在后面给出)
- 在Ubuntu16环境安装NVIDIA驱动和CUDA9.2的过程,可以参考文章《纯净Ubuntu16安装CUDA(9.1)和cuDNN》,这里面安装的CUDA版本是9.1,请自行改为9.2版本
DL4J的依赖库和版本
- 首先要强调的是:不要使用CUDA 11.2版本(这是执行nvidia-smi时输出的版本),截止写本文时,使用CUDA 11.2及其依赖库,在启动时会有ClassNotFound异常
- CUDA 10.X版本我这里也没有试过,因此不做评论
- CUDA 9.1和9.2版本都尝试过,可以正常使用
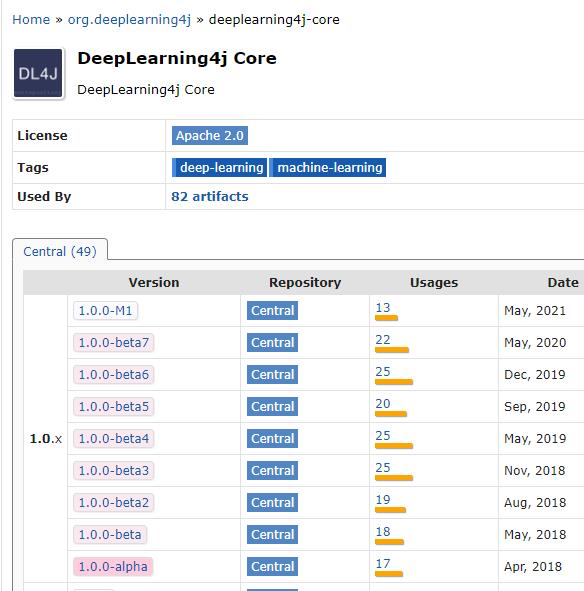
- 为什么不用9.1呢?咱们先去中央仓库看看DL4J核心库的版本情况,如下图,最新的版本已经到了1.0.0-M1:
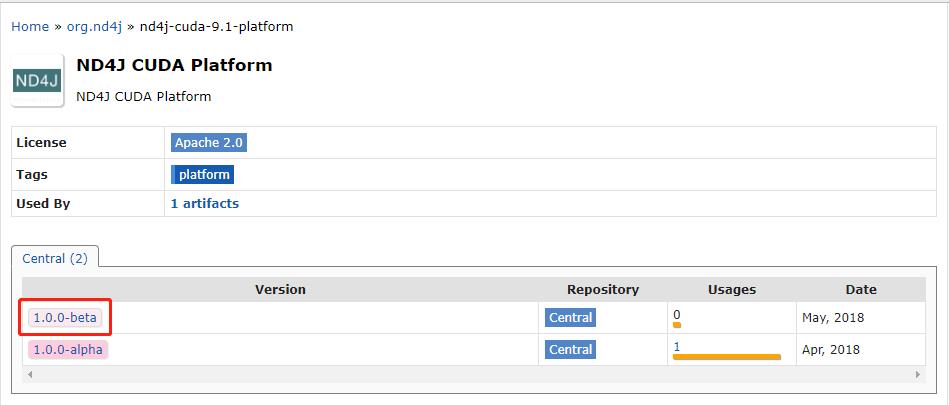
- 再看看CUDA 9.1对应的nd4j库的版本情况,如下图红框,最新的是2018年的1.0.0-beta,与核心库差距太大了:
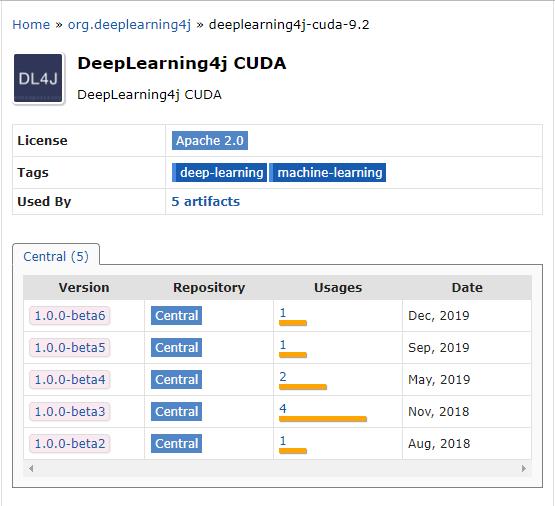
- 好了,再来看看CUDA 9.2对应的nd4j库的版本情况,如下图红框,最新的是1.0.0-beta6,与核心库差两个版本,因此,建议使用CUDA 9.2:
使用GPU的具体操作步骤
- 使用CPU还是GPU,具体操作步骤非常简单:切换不同的依赖库即可,下面分别介绍
- 如果您用CPU做训练,则依赖库和版本如下:
<!--核心库,不论是CPU还是GPU都要用到-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-beta6</version>
</dependency>
<!--CPU要用到-->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-native</artifactId>
<version>1.0.0-beta6</version>
</dependency>
如果您用GPU做训练,且CUDA版本是9.2,则依赖库和版本如下:
<!--核心库,不论是CPU还是GPU都要用到-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-core</artifactId>
<version>1.0.0-beta6</version>
</dependency>
<!--GPU要用到-->
<dependency>
<groupId>org.deeplearning4j</groupId>
<artifactId>deeplearning4j-cuda-9.2</artifactId>
<version>1.0.0-beta6</version>
</dependency>
<!--GPU要用到-->
<dependency>
<groupId>org.nd4j</groupId>
<artifactId>nd4j-cuda-9.2-platform</artifactId>
<version>1.0.0-beta6</version>
</dependency>
- java代码就不在这里贴出了,用的是《DL4J实战之三:经典卷积实例(LeNet-5)》中的代码,不做任何改变
内存设置
- 使用IDEA运行代码的时候,可以按照当前硬件情况将内存适当调大,步骤如下图:
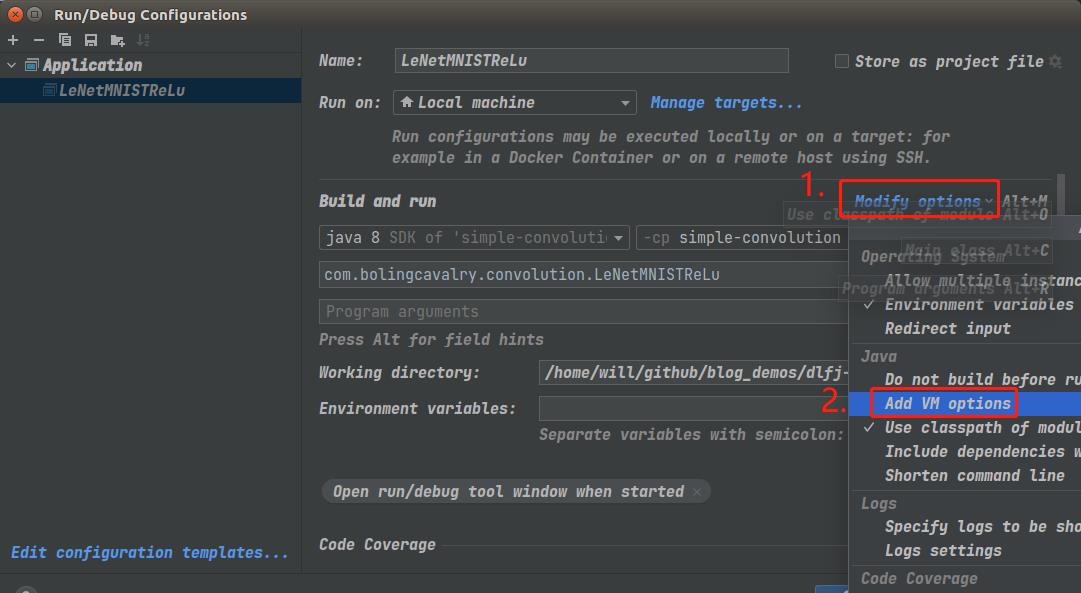
- 请酌情调整,我这里设置为8G
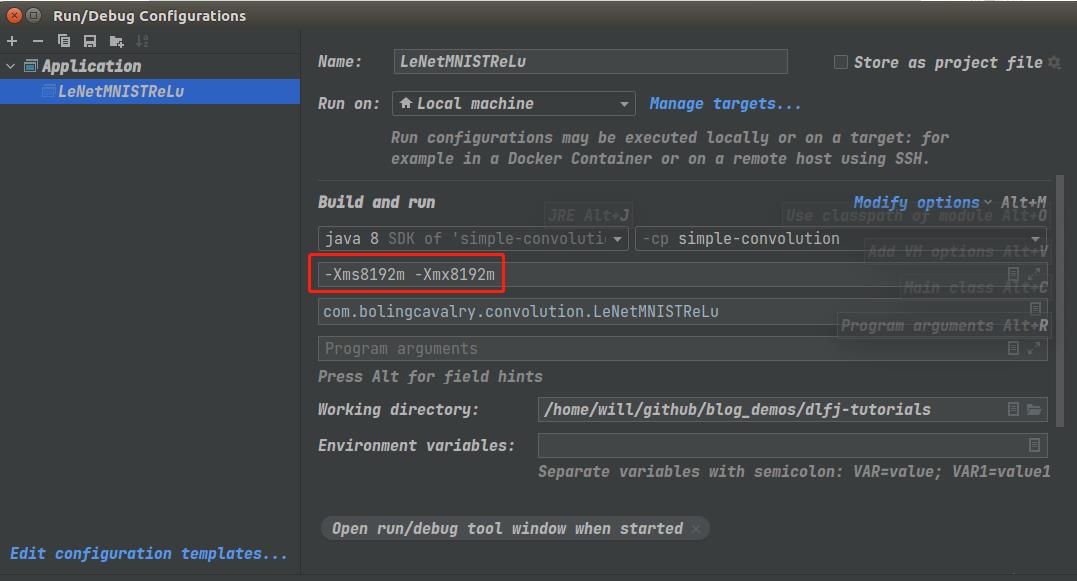
- 设置完毕,接下来在同一电脑上分别用CPU和GPU执行训练和测试,通过对比检查GPU加速效果
CPU版本
- 在这台破旧的笔记本电脑上,用CPU做训练是非常吃力的,如下图,几乎被榨干:
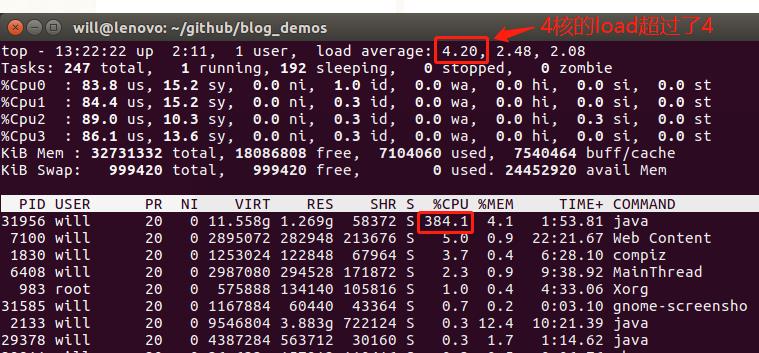
- 控制台输出如下,耗时158秒,真是个漫长的过程:
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9
---------------------------------------------------
973 1 0 0 0 0 2 2 1 1 | 0 = 0
0 1132 0 2 0 0 1 0 0 0 | 1 = 1
1 5 1018 1 1 0 0 4 2 0 | 2 = 2
0 0 2 1003 0 3 0 1 1 0 | 3 = 3
0 0 1 0 975 0 2 0 0 4 | 4 = 4
2 0 0 6 0 880 2 1 1 0 | 5 = 5
6 1 0 0 3 4 944 0 0 0 | 6 = 6
0 3 6 1 0 0 0 1012 2 4 | 7 = 7
3 0 1 1 0 1 1 2 964 1 | 8 = 8
0 0 0 2 6 2 0 2 0 997 | 9 = 9
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================
13:24:31.616 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 完成训练和测试,耗时[158739]毫秒
13:24:32.116 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 最新的MINIST模型保存在[/home/will/temp/202106/26/minist-model.zip]
GPU版本
- 接下来按照前面给出的依赖关系修改pom.xml文件,即可启用GPU,运行过程中,控制台输出以下内容表示已启用GPU:
13:27:08.277 [main] INFO org.nd4j.linalg.api.ops.executioner.DefaultOpExecutioner - Backend used: [CUDA]; OS: [Linux]
13:27:08.277 [main] INFO org.nd4j.linalg.api.ops.executioner.DefaultOpExecutioner - Cores: [4]; Memory: [7.7GB];
13:27:08.277 [main] INFO org.nd4j.linalg.api.ops.executioner.DefaultOpExecutioner - Blas vendor: [CUBLAS]
13:27:08.300 [main] INFO org.nd4j.linalg.jcublas.JCublasBackend - ND4J CUDA build version: 9.2.148
13:27:08.301 [main] INFO org.nd4j.linalg.jcublas.JCublasBackend - CUDA device 0: [GeForce GTX 950M]; cc: [5.0]; Total memory: [4242604032]
- 这次的运行过程明显流畅了许多,CPU使用率下降了不少:
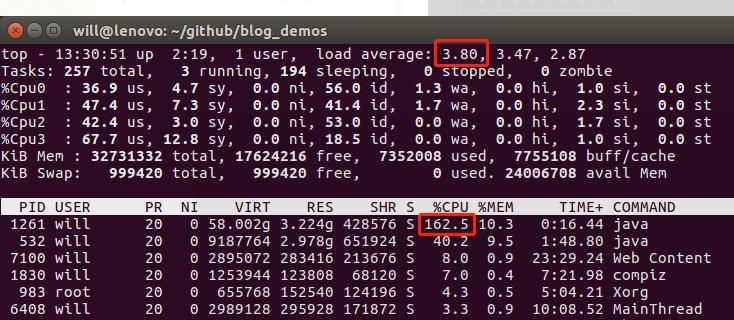
- 控制台输出如下,耗时21秒,可见GPU加速效果还是很明显的:
=========================Confusion Matrix=========================
0 1 2 3 4 5 6 7 8 9
---------------------------------------------------
973 1 0 0 0 0 2 2 1 1 | 0 = 0
0 1129 0 2 0 0 2 2 0 0 | 1 = 1
1 3 1021 0 1 0 0 4 2 0 | 2 = 2
0 0 1 1003 0 3 0 1 2 0 | 3 = 3
0 0 1 0 973 0 3 0 0 5 | 4 = 4
1 0 0 6 0 882 2 1 0 0 | 5 = 5
6 1 0 0 2 5 944 0 0 0 | 6 = 6
0 2 4 1 0 0 0 1016 2 3 | 7 = 7
1 0 2 1 0 1 0 2 964 3 | 8 = 8
0 0 0 2 6 3 0 2 1 995 | 9 = 9
Confusion matrix format: Actual (rowClass) predicted as (columnClass) N times
==================================================================
13:27:30.722 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 完成训练和测试,耗时[21441]毫秒
13:27:31.323 [main] INFO com.bolingcavalry.convolution.LeNetMNISTReLu - 最新的MINIST模型保存在[/home/will/temp/202106/26/minist-model.zip]
Process finished with exit code 0
- 至此,DL4J框架下的GPU加速实战就完成了,如果您手里有NVIDIA显卡,可以尝试一下,希望本文能给您一些参考
你不孤单,欣宸原创一路相伴
以上是关于DL4J实战之四:经典卷积实例(GPU版本)的主要内容,如果未能解决你的问题,请参考以下文章