T7浏览内核缓存优化与应用——MemoryCache
Posted 百度App技术
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了T7浏览内核缓存优化与应用——MemoryCache相关的知识,希望对你有一定的参考价值。
阅读收获
-
了解浏览内核缓存的底层机制,探讨内核缓存的优化方向; 了解百度APP浏览内核团队的在资源缓存、内存管理的挑战及实践应用。
T7浏览内核 百度App内核团队基于Chromium项目面向移动端深度定制优化的高性能浏览内核。
1.前言
在使用百度App浏览页面时,用户体验的好坏主要体现在页面展现的速度是否够快、够流畅。资源加载阶段是页面展现中的瓶颈耗时阶段,而预加载和缓存复用是可以显著提升资源加载性能的优化方案。本文将讲述百度App T7浏览内核团队通过优化页面缓存机制从而提升性能的优化方案,使得百度App页面展示速度得到进一步提升。
2.背景
介绍百度App T7浏览内核对缓存机制所做的优化之前,首先介绍一下T7浏览内核页面资源加载流程。
主文档和子资源的加载流程如下:
资源加载流程图
UI线程和Blink线程发起的html主文档请求,都是以UI线程中的BeginNavigation方法为入口,首先判断是否需要发起网络请求,若需要,则通过IO线程的网络库请求资源内容,收到首字节后将消息传输至Blink线程并创建Document相关对象;
从网络库中获取到HTML主文档资源内容后,通过网络库的IO线程传输至Blink线程,Blink线程获取到资源内容后开始读取HTML主文档内容,再进行解析、布局和渲染工作;
当解析到主文档中的子资源信息,Blink线程将按照顺序对子资源发起请求,获取到子资源的数据后,会针对不同的子资源做不同的处理,同步JS资源加载完成之前内核会停止解析,直到JS资源执行完成之后解析才会恢复,而CSS资源会阻塞内核的布局,当页面的JS和CSS都加载完成后内核会进行布局和渲染,完成页面展现。
通过数据分析,从页面开始加载至页面内容完成展现显示给用户,其中最为耗时的阶段就是网络加载耗时。T7浏览内核页面展现关键阶段的耗时占比如下图,其中资源加载网络耗时(包括主文档和子资源)占整个流程耗时的50%左右。
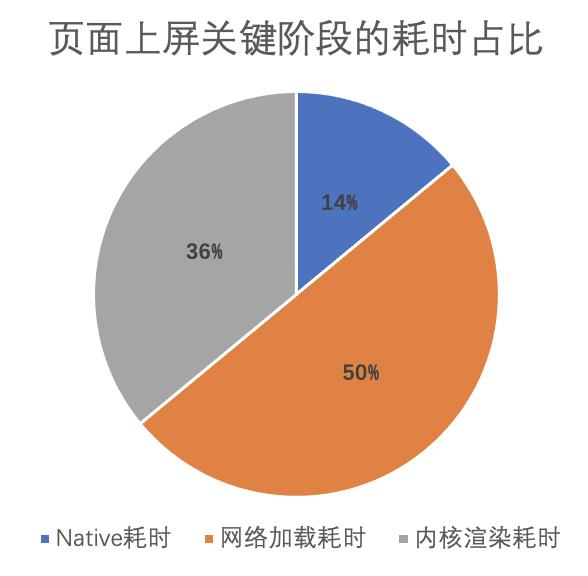
而网络加载耗时较长的原因主要受多种非技术因素影响,如网络状态、服务器性能等。为减少网络请求的影响,T7浏览内核设计了资源缓存机制,网络资源加载可以直接复用已缓存数据,无需发起网络请求,从而降低网络耗时。
T7浏览内核缓存机制包含 HTTPCache 和 MemoryCache 。
3.T7浏览内核缓存机制介绍
丨3.1 HTTPCache 与 MemoryCache
HTTPCache是接收HTTP(s)请求,HTTPCache 又可以称为 DiskCache,是决定何时以及如何从 DiskCache 或网络中获取数据的模块。
MemoryCache是内存级缓存,且实现于 Blink线程 中。
Chrome官方对 HTTPCache 和 MemoryCache 的注释如下:
The HTTP Cache is the module that receives HTTP(S) requests and decides when and how to fetch data from the DiskCache or from the network. The cache lives in the browser process, as part of the network stack. It should not be confused with Blink's in-memory cache, which lives in the renderer process and it's tightly coupled with the resource loader.
浏览器缓存被分为强缓存和协商缓存。强缓存表示不会向服务器发送请求,直接从缓存中读取资源。协商缓存表示向服务器发送请求,服务器根据请求的 Request header 的一些参数来判断是否命中协商缓存,如果命中,则返回304状态码并带上新的 Response header 通知浏览器从缓存中读取资源,若未命中则返回新的 Response header 和新的资源内容。而 HTTPCache 和 MemoryCache 均属于强缓存。
两种缓存机制的对比如下:
| 缓存类型 | HTTPCache | MemoryCache |
| 存储方式 | 磁盘缓存 资源原始内容 |
内存缓存 Resource对象 |
| 最大容量 | 20M | 8M |
| 加载效率 | <100ms | 几乎不耗时 |
存储资源类型 (HTTP(s)) |
主文档+子资源 | 子资源 |
| 清理时机 | 已缓存Size超过阈值 | 随时被GC清理 |
| 实现线程 | IO线程 | Blink线程 |
主文档加载流程如下:
主文档加载流程
查看 HTTPCache 是否已缓存此资源,若已缓存,则直接返回资源内容,否则执行步骤2;
发起网络请求,并将网络返回的资源内容存储至 HTTPCache 中。
子资源加载流程如下:
子资源加载流程
查看 MemoryCache 是否缓存此资源,若已缓存,则直接返回资源内容,否则执行步骤2;
查看 HTTPCache 是否缓存此资源,若已缓存,则直接返回资源内容,否则执行步骤3;
发起网络请求,并将网络返回的资源内容存储至HTTPCache和MemoryCache 中。
从存储方式和实现逻辑上,MemoryCache必定快于HTTPCache,且MemoryCache 实现于 Blink线程 中,从 MemoryCache 中获取到资源内容后无需发送请求至网络库,既提升了资源的提取时间,又缩减了资源的请求路径,此路径为资源加载的最短路径,所以 MemoryCache 机制在资源缓存能力方面有着很大的优势。
而当前 MemoryCache 机制存在不能存储主文档、资源保存为弱引用导致清理时机不受控制、接口不对外开放等限制,导致只有少部分资源才能从 MemoryCache 中 被复用,其优势并未最大化。
4.MemoryCache优化与定制
为了解决 MemoryCache 机制的限制,我们针对当前的 MemoryCache 机制做了改进,相比 T7浏览内核原始 MemoryCache,改进后的 MemoryCache 将缓存更多类型的资源,同时复用率有了很大的提升,促使资源加载速度得到进一步的提升。
针对 T7浏览内核 MemoryCache 具体改进点如下:
4.1.1 主文档缓存能力
T7浏览内核 PlzNavigation架构下,不管是 UI线程 还是 Blink线程 发起的跳转,都以 UI线程 中的 BeginNavigation方法 为入口。主文档资源在 UI线程 中判断跳转页面是否需要网络层处理,若需要网络层处理,则走网络请求逻辑,实现资源请求并返回所需网络数据。即主文档资源的缓存和加载流程未与 MemoryCache 有交集,所以无法使用 MemoryCache 机制。为此我们新增主文档 MemoryCache 缓存能力,可在页面发起网络请求之前查询 MemoryCache 中是否已缓存主文档内容,若已缓存,则直接复用。
4.1.2 file协议资源缓存能力
file协议子资源不会被存储至 MemoryCache 中,为提高file资源的加载速度,去除资源的IO读取耗时,我们扩展了 MemoryCache 针对file协议资源的存储能力。
MemoryCache 由于仅保存资源的弱引用对象,所以被存储资源的生命周期与页面生命周期基本一致,即页面退出后,该页面中已存储至 MemoryCache 中的资源随时可能被删除。那么页面中被缓存的资源仅能被当前页面复用,可避免页面中相同资源的多次请求,页面刷新时也可复用已存储至 MemoryCache 的资源。但页面浏览结束后,页面中已缓存的多数资源便会被GC清理掉,所以此时再次打开页面,资源已不能从 MemoryCache 中复用,需要从 HTTPCache 或网络中重新加载资源。
为解决此问题,我们从 MemoryCache 中开辟出固定的空间,此空间用于存放我们需要多次复用的资源,其存储与清理的时机单独管理。清理策略使用LRU算法,根据设置的空间大小上限,优先清理长时间没有被使用的资源。此时部分资源可多次重复被复用,大大提升资源的 MemoryCache 复用率。
T7浏览内核 MemoryCache 机制只能由网页主文档写明的子资源链接触发加载和缓存,没有提供相应的接口对外使用。当业务方想要提前加载某些资源至 MemoryCache 中,或从 MemoryCache 查询提取已缓存的资源内容时,没有接口可供使用。
为此我们拓展了此项能力,提供API接口供业务方使用,使得各业务可根据自己的需求,决定是否使用 MemoryCache 机制。
5.定制 MemoryCache 落地
定制 MemoryCache 机制主要应用于资源预加载场景下,提前将页面中的资源内容缓存至 Cache 中,当用户真正打开页面时,可直接从 Cache 中获取,减少网络请求耗时影响。不同场景使用不同的预加载方式,下面将简单介绍已落地场景及定制化 MemoryCache 使用方式和速度收益。
T7浏览内核提供的预加载接口已默认使用定制化 MemoryCache 能力。当前推荐使用 NoState Prefetch 预加载机制。
NoState Prefetch 把网页 (HTML)和其JS和CSS子资源提前预取到Cache (MemoryCache + HTTPCache)的一种机制,内核无需解析、执行javascript以及维护页面状态。
使用方式:
HTML中插入 <link rel="prerender"> 样式元素;
调用 WebView 中 startPrerender(url) 方法。
落地业务:百度APP H5普通落地页、商业托管页。
速度收益:提升30%以上。
T7浏览内核提供完整的API接口以供业务方使用定制化 MemoryCache 机制,包括存储资源至 MemoryCache、查询资源是否存储至 MemoryCache、删除 MemoryCache 中资源。
具体API及使用方式:
addToWebCache:通过URL预加载资源并存储至 MemoryCache 中,可设置资源请求的UA等 Request Headers 中相关信息。
removeFromWebCache:通过URL删除缓存至 MemoryCache 中的资源。
isInWebCache:通过URL查看资源是否已存储至 MemoryCache 中。
6.展望
以上就是本次百度APP 浏览内核团队针对内核缓存机制所作的优化和改进,最终对页面上屏性能有着显著的提升。未来我们将继续努力和探索,运用内核团队坚实的技术底蕴和技术实力,为业务的发展做支撑。
招聘信息
百度APP产品研发部,诚招各类研发职位:php/Go/C++、移动端、前端、网络库研发等职位。欢迎感兴趣的同学们投递。投递邮箱:yangying18@baidu.com
以上是关于T7浏览内核缓存优化与应用——MemoryCache的主要内容,如果未能解决你的问题,请参考以下文章