大数据量性能优化之分页查询
Posted JavaEdge.
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了大数据量性能优化之分页查询相关的知识,希望对你有一定的参考价值。
刷帖子翻页需要分页查询,搜索商品也需分页查询。当遇到上千万、上亿数据量,怎么快速拉取全量数据呢?
比如:
- 大商家拉取每月千万级别的订单数量到自己独立的ISV做财务统计
- 拥有百万千万粉丝的大v,给全部粉丝推送消息
案例
常见错误写法
SELECT *
FROM table
where kid = 1342
and type = 1
order id asc
limit 149420,20;
典型的排序+分页查询:
order by col limit N,OFFSET M
mysql 执行此类SQL时:先扫描到N行,再取 M行。
N越大,MySQL需扫描更多数据定位到具体的N行,这会耗费大量的I/O成本和时间成本。
为什么上面的SQL写法扫描数据会慢?
- t是个索引组织表,key idx_kid_type(kid,type)
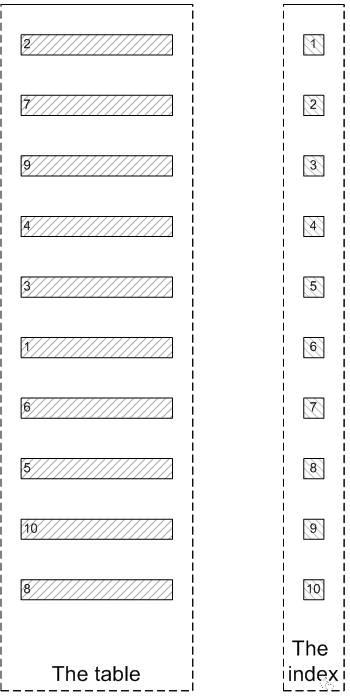
符合kid=3 and type=1 的记录有很多行,我们取第 9,10行。
select * from t where kid =3 and type=1 order by id desc 8,2;
对于Innodb,根据 idx_kid_type 二级索引里面包含的主键去查找对应行。
对百万千万级记录,索引大小可能和数据大小相差无几,cache在内存中的索引数量有限,而且二级索引和数据叶子节点不在同一物理块存储,二级索引与主键的相对无序映射关系,也会带来大量随机I/O请求,N越大越需遍历大量索引页和数据叶,需要耗费的时间就越久。

由于上面大分页查询耗时长,是否真的有必要完全遍历“无效数据”?
若需要:
limit 8,2
跳过前面8行无关数据页的遍历,可直接通过索引定位到第9、10行,这样是不是更快?
这就是延迟关联的核心思想:通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据,而非通过二级索引获取主键再通过主键遍历数据页。

通过如上分析可得,通过常规方式进行大分页查询慢的原因,也知道了提高大分页查询的具体方法。
一般分页查询
简单的 limit 子句。limit 子句声明如下:
SELECT * FROM table LIMIT
[offset,] rows | rows OFFSET offset
limit 子句用于指定 select 语句返回的记录数,注意:
offset指定第一个返回记录行的偏移量,默认为0
初始记录行的偏移量是0,而非1rows指定返回记录行的最大数量
rows为 -1 表示检索从某个偏移量到记录集的结束所有的记录行。
若只给定一个参数:它表示返回最大的记录行数目。
实例:
select * from orders_history where type=8 limit 1000,10;
从 orders_history 表查询offset: 1000开始之后的10条数据,即第1001条到第1010条数据(1001 <= id <= 1010)。
数据表中的记录默认使用主键(id)排序,上面结果等价于:
select * from orders_history where type=8
order by id limit 10000,10;
三次查询时间分别为:
3040 ms
3063 ms
3018 ms
针对这种查询方式,下面测试查询记录量对时间的影响:
select * from orders_history where type=8 limit 10000,1;
select * from orders_history where type=8 limit 10000,10;
select * from orders_history where type=8 limit 10000,100;
select * from orders_history where type=8 limit 10000,1000;
select * from orders_history where type=8 limit 10000,10000;
三次查询时间:
查询1条记录:3072ms 3092ms 3002ms
查询10条记录:3081ms 3077ms 3032ms
查询100条记录:3118ms 3200ms 3128ms
查询1000条记录:3412ms 3468ms 3394ms
查询10000条记录:3749ms 3802ms 3696ms
在查询记录量低于100时,查询时间基本无差距,随查询记录量越来越大,消耗时间越多。
针对查询偏移量的测试:
select * from orders_history where type=8 limit 100,100;
select * from orders_history where type=8 limit 1000,100;
select * from orders_history where type=8 limit 10000,100;
select * from orders_history where type=8 limit 100000,100;
select * from orders_history where type=8 limit 1000000,100;
三次查询时间如下:
查询100偏移:25ms 24ms 24ms
查询1000偏移:78ms 76ms 77ms
查询10000偏移:3092ms 3212ms 3128ms
查询100000偏移:3878ms 3812ms 3798ms
查询1000000偏移:14608ms 14062ms 14700ms
随着查询偏移的增大,尤其查询偏移大于10万以后,查询时间急剧增加。
这种分页查询方式会从DB的第一条记录开始扫描,所以越往后,查询速度越慢,而且查询数据越多,也会拖慢总查询速度。
优化
- 前端加缓存、搜索,减少落到库的查询操作
比如海量商品可以放到搜索里面,使用瀑布流的方式展现数据 - 优化SQL 访问数据的方式
直接快速定位到要访问的数据行。推荐使用"延迟关联"的方法来优化排序操作,何谓"延迟关联" :通过使用覆盖索引查询返回需要的主键,再根据主键关联原表获得需要的数据。 - 使用书签方式 ,记录上次查询最新/大的id值,向后追溯 M行记录
延迟关联
优化前
explain SELECT id, cu_id, name, info, biz_type, gmt_create, gmt_modified,start_time, end_time, market_type, back_leaf_category,item_status,picuture_url FROM relation where biz_type ='0' AND end_time >='2014-05-29' ORDER BY id asc LIMIT 149420 ,20;
+----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+
| id | select_type | table | type | possible_keys | key | key\\_len | ref | rows | Extra |
+----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+
| 1 | SIMPLE | relation | range | ind\\_endtime | ind\\_endtime | 9 | NULL | 349622 | Using where; Using filesort |
+----+-------------+-------------+-------+---------------+-------------+---------+------+--------+-----+
执行时间:
20 rows in set (1.05 sec)
优化后:
explain SELECT a.* FROM relation a, (select id from relation where biz_type ='0' AND end\\_time >='2014-05-29' ORDER BY id asc LIMIT 149420 ,20 ) b where a.id=b.id;
+----+-------------+-------------+--------+---------------+---------+---------+------+--------+-------+
| id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
+----+-------------+-------------+--------+---------------+---------+---------+------+--------+-------+
| 1 | PRIMARY | <derived2> | ALL | NULL | NULL | NULL | NULL | 20 | |
| 1 | PRIMARY | a | eq_ref | PRIMARY | PRIMARY | 8 | b.id | 1 | |
| 2 | DERIVED | relation | index | ind_endtime | PRIMARY | 8 | NULL | 733552 | |
+----+-------------+-------------+--------+---------------+---------+---------+------+--------+-------+
执行时间:
20 rows in set (0.36 sec)
优化后 执行时间 为原来的1/3 。
书签
首先获取符合条件的记录的最大 id和最小id(默认id是主键)
select max(id) as maxid ,min(id) as minid
from t where kid=2333 and type=1;
根据id 大于最小值或者小于最大值进行遍历。
select xx,xx from t where kid=2333 and type=1
and id >=min_id order by id asc limit 100;
select xx,xx from t where kid=2333 and type=1
and id <=max_id order by id desc limit 100;
案例
当遇到延迟关联也不能满足查询速度的要求时
SELECT a.id as id, client_id, admin_id, kdt_id, type, token, created_time, update_time, is_valid, version FROM t1 a, (SELECT id FROM t1 WHERE 1 and client_id = 'xxx' and is_valid = '1' order by kdt_id asc limit 267100,100 ) b WHERE a.id = b.id;
100 rows in set (0.51 sec)
使用延迟关联查询数据510ms ,使用基于书签模式的解决方法减少到10ms以内 绝对是一个质的飞跃。
SELECT * FROM t1 where client_id='xxxxx' and is_valid=1 and id<47399727 order by id desc LIMIT 100;
100 rows in set (0.00 sec)
小结
根据主键定位数据的方式直接定位到主键起始位点,然后过滤所需要的数据。
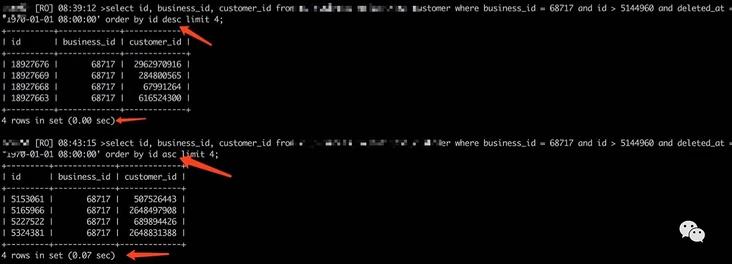
相对比延迟关联的速度更快,查找数据时少了二级索引扫描。但优化方法没有银弹,比如:
order by id desc 和 order by asc 的结果相差70ms ,生产上的案例有limit 100 相差1.3s ,这是为啥?
还有其他优化方式,比如在使用不到组合索引的全部索引列进行覆盖索引扫描的时候使用 ICP 的方式 也能够加快大分页查询。
子查询优化
先定位偏移位置的 id,然后往后查询,适于 id 递增场景:
select * from orders_history where type=8 limit 100000,1;
select id from orders_history where type=8 limit 100000,1;
select * from orders_history where type=8 and
id>=(select id from orders_history where type=8 limit 100000,1)
limit 100;
select * from orders_history where type=8 limit 100000,100;
4条语句的查询时间如下:
第1条语句:3674ms
第2条语句:1315ms
第3条语句:1327ms
第4条语句:3710ms
- 1 V.S 2:select id 代替 select *,速度快3倍
- 2 V.S 3:速度相差不大
- 3 V.S 4:得益于 select id 速度增加,3的查询速度快了3倍
这种方式相较于原始一般的查询方法,将会增快数倍。
使用 id 限定优化
假设数据表的id是连续递增,则根据查询的页数和查询的记录数可以算出查询的id的范围,可使用 id between and:
select *
from order_history
where c = 2
and id between 1000000 and 1000100
limit 100;
查询时间:
15ms
12ms
9ms
这能够极大地优化查询速度,基本能够在几十毫秒之内完成。
限制是只能使用于明确知道id。
另一种写法:
select *
from order_history
where id >= 1000001
limit 100;
还可以使用 in,这种方式经常用在多表关联时进行查询,使用其他表查询的id集合,来进行查询:
select *
from order_history
where id in
(select order_id from trade_2 where goods = 'pen')
limit 100;
临时表
已经不属于查询优化,这儿附带提一下。
对于使用 id 限定优化中的问题,需要 id 是连续递增的,但是在一些场景下,比如使用历史表的时候,或者出现过数据缺失问题时,可以考虑使用临时存储的表来记录分页的id,使用分页的id来进行 in 查询。这样能够极大的提高传统的分页查询速度,尤其是数据量上千万的时候。
数据表的id
一般在DB建立表时,强制为每一张表添加 id 递增字段,方便查询。
像订单库等数据量很大,一般会分库分表。这时不推荐使用数据库的 id 作为唯一标识,而应该使用分布式的高并发唯一 id 生成器,并在数据表中使用另外的字段来存储这个唯一标识。
先使用范围查询定位 id (或者索引),然后再使用索引进行定位数据,能够提高好几倍查询速度。即先 select id,然后再 select *。
参考
- https://segmentfault.com/a/1190000038856674
以上是关于大数据量性能优化之分页查询的主要内容,如果未能解决你的问题,请参考以下文章