AI论文解读:基于Transformer的多目标跟踪方法TrackFormer
Posted 华为云
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了AI论文解读:基于Transformer的多目标跟踪方法TrackFormer相关的知识,希望对你有一定的参考价值。
摘要:多目标跟踪这个具有挑战性的任务需要同时完成跟踪目标的初始化、定位并构建时空上的跟踪轨迹。本文将这个任务构建为一个帧到帧的集合预测问题,并提出了一个基于transformer的端到端的多目标跟踪方法TrackFormer。
本文分享自华为云社区《论文解读系列十四:基于transformer的多目标跟踪方法TrackFormer详细解读》,原文作者:谷雨润一麦 。

多目标跟踪这个具有挑战性的任务需要同时完成跟踪目标的初始化、定位并构建时空上的跟踪轨迹。本文将这个任务构建为一个帧到帧的集合预测问题,并提出了一个基于transformer的端到端的多目标跟踪方法TrackFormer。本文模型通过注意力机制实现了帧与帧之间的数据关联,完成了视频序列间的跟踪轨迹的预测。Transformer的解码器同时从静态的目标查询中初始化新的目标和从跟踪查询中跟踪已有的跟踪轨迹并对位置进行更新,两种类型的查询都可以同时从self-attention和encoder-decoder的注意力中关注到全局的帧级特征。因此可以省略掉额外的图优化和匹配的过程,也不需要对运动和外貌特征进行建模。
1. Motivation
多目标跟踪任务需要跟踪一系列目标的轨迹,当目标在视频序列中移动时可以保持各自具有区分性的跟踪id。现有的tracking-by-detection的方法一般都包含两个步骤(1)检测单独视频帧中目标(2)对帧与帧之间的检测目标进行关联,从而形成每个目标的跟踪轨迹。传统的基于tracking-by-detection的方法的数据关联一般都需要图优化或者利用卷积神经网络预测目标间的分数的方式。本文提出了一个新的跟踪范式tracking-by-attention,该方法将多目标跟踪任务建模为一个集合预测问题,通过提出的TrackFormer网络实现了端到端的可训练的在线多目标跟踪网络。该网络利用encoder对来自卷积网络的图像特征进行编码,然后通过decoder将查询向量解码为包围框和对应的身份id,其中的跟踪查询用来做帧与帧之间的数据关联。
2. 网络结构
本文提出的TrackFormer是一个基于transformer的端到端多目标跟踪方法,它将多目标跟踪任务建模为一个集合预测问题,并引出了tracking-by-attention这种新的范式。下面将从整体流程、跟踪过程和网络损失函数三个方面分别对网络进行介绍。
图一 trackformer训练流程图
2.1 基于集合预测的多目标任务
给定具有K个不同identity的目标的视频序列,多目标跟踪任务需要生成包括包围框和身份id(k)的跟踪轨迹

总帧数T 的子集(t1,t2,…)记录了目标从进入到离开场景的时间序列。
为了将MOT(多目标跟踪任务)建模为序列预测问题,本文利用了transformer的编码器-解码器结构。文本模型通过下面四个步骤完成在线的跟踪并同时输出每一帧目标的边界框、类别以及身份id:
1)通过通用的卷积神经网络backbone提取帧级的特征,例如ResNet
2)通过transformer的编码器的self-attention模块完成帧级特征编码
3)通过transformer的解码器的self-和cross-attention完成对查询实体的解码
4)通过多层感知机对解码器输出进行映射完成边界框和类别的预测
其中解码器的注意力机制一共分为两种(1)所有查询向量上的self-attention,可以用来响应场景中的所有目标;(2)编码器和解码器之间的注意力,可以获取到当前帧的全局视觉信息。另外,因为transformer具有排列不变性,需要分别给特征输入和解码查询实体添加额外的位置编码和目标编码。
2.2 基于解码器查询向量的跟踪过程
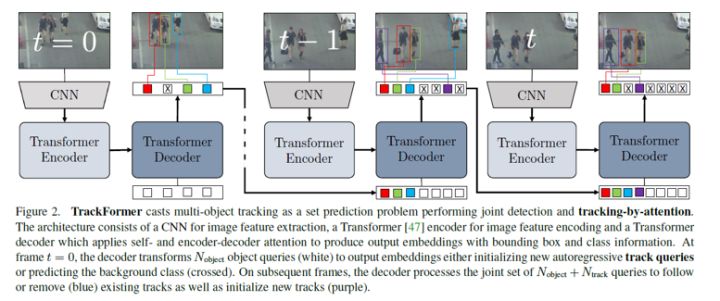
Transformer的解码器查询向量一共有两种初始化方式(1)静态目标查询向量,帮助模型在任意帧初始化跟踪目标(2)自回归跟踪查询向量,负责在帧与帧之间跟踪目标。Transformer同时对目标和跟踪查询进行解码可以以一种统一方式的实现检测和跟踪,因此引入了一种tracking-by-attention的模式。详细的网络结构如下图所示:

图二 trackformer网络结构
2.2.1 跟踪初始化
场景中新出现的目标都是通过固定数量(Nobject)的目标查询向量进行检测的,这Nobject个目标向量在网络训练过程中会不断学习从而可以实现场景中的所有目标编码,然后通过transformer的解码器的解码完成新目标类别和位置信息的预测,从而实现了跟踪的初始化。
2.2.2跟踪查询
为了实现帧与帧之间的跟踪,本文在解码过程中提出了“跟踪查询”这个概念。跟踪查询会在视频序列中不断跟踪目标,在携带者身份信息的同时还通过自回归的方式自适应的调整目标的位置预测。为了实现这个目标,在解码过程中会用上一帧对应的输出embedding来初始化检测的跟踪查询向量,然后在解码过程中通过encoder和decoder建立当前帧和查询向量之间注意力关系,从而完成了跟踪查询中各个实例的身份和位置的更新。
跟踪查询向量如图一中的颜色方块所示,上一帧的transformer输出embedding会被用来初始化当前帧的查询向量,通过和当前帧特征进行查询,完整帧与帧之间的目标跟踪。
2.3 网络训练及损失函数
因为查询跟踪需要跟踪下一帧的目标并和目标查询交互一起工作,TrackFormer需要专门的帧与帧之间的跟踪训练。如图一所示,本文通过同时训练紧邻的两帧来完成跟踪训练,并一起优化所有的多目标跟踪目标函数。集合预测损失度量了每一帧的所有输出

的类别和边界框预测与真实目标之间的相似性,集合预测损失一共可以分为两部分计算:
1)上一帧(t-1)的 Nobject 个目标查询的loss
2)从上一步得到得到的跟踪目标和当前帧(t)的新的检测目标总共N个查询的loss
因为transformer的输出是无序的,因此在计算集合预测损失之前需要先完成输出embedding和真实标签之间的匹配问题。这个匹配可以同时通过跟踪id和包围框以及类别之间的相似性来完成,首先考虑跟踪id的情况,我们用 Kt-1 表示t-1帧的跟踪id集合,用 Kt 表示当前帧t的跟踪id集合,通过这两个跟踪集合可以完成Ntrack跟踪查询和真实标签的硬匹配。两个集合的匹配一共可以分为三种情况:(1)kt-1 和 kt 的交集,这个可以用来直接给跟踪查询embedding匹配对应的真实标签(2)kt-1 中出现 kt 中没有的,直接舍匹配背景标签(3)kt 和 kt-1中有中不存在的在,这一部分是新的目标,需要用匈牙利算法对目标查询和真实标签的包围框和类别进行优化匹配得到最小损失的匹配结果。匹配过程如下公式所示:

σ为gt到目标查询(Nobject)的映射关系,优化目标就是让匹配损失最小,匹配损失同时包括了类别损失和包围框损失如下所示:


得到匹配结果后,最后就可以计算集合预测损失,同时包括了跟踪和目标查询输出的损失,计算方法如下:


∏是通过跟踪id和匈牙利算法得到的输出与真值之间的匹配结果。
3. 实验结果

表3-1 MOT17上的跟踪结果
从表3-1的结果可以看出,在私有检测器上的跟踪结果仍有一定差距,这主要是因为基于transformer的检测器效果没有现在SOTA的方法好,但当采用共有检测器时,在线上跟踪的情况下无论是在MOTP和IDF1都有明显的提升。

表3-2 MOTS20上的跟踪结果
除了目标检测和跟踪之外,TrackFormer还可以预测实例水平的分割图。从表3-2可以看出无论是在交叉验证结果上还是测试集上,TrackFormer都要优于现有的SOTA方法。
以上是关于AI论文解读:基于Transformer的多目标跟踪方法TrackFormer的主要内容,如果未能解决你的问题,请参考以下文章
带你读AI论文丨用于细粒度分类的Transformer结构—TransFG
带你读AI论文丨用于细粒度分类的Transformer结构—TransFG