Java实习生每日10道面试题打卡!
Posted 兴趣使然的草帽路飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java实习生每日10道面试题打卡!相关的知识,希望对你有一定的参考价值。
- 打卡 Day25!
- 这些题目都是从牛客面经中挑选出来的大厂面试问题,自己一道一道的搜集答案,拿来分享给大家白嫖! 也欢迎成功上岸大厂的小伙伴分享自己的面经给我,帮大家总结成面试题!
- 提醒打卡的小伙伴,也得坚持刷算法题哦!大厂实习、校招,笔试算法题逃不掉的(尤其是字节),想冲大厂的小伙伴,一定要多刷题!

1、Java里面用的什么字符集,unicode几个字节?
参考文章:
起初 Java 一个 char 类型2个字节(16bit),用来存储 Unicode 字符。字符数据类型的范围为 0 到 65535,可以存储 65536 个不同的 Unicode 字符。
然而随着 Unicode 字符集的增长,已经超过 65536 个了,根据 Unicode 标准,现在 Unicode 代码点的合法范围是 U+0000 到 U+10FFFF,U+0000 到 U+FFFF 称为Basic Multilingual Plane(BMP),代码点大于 U+FFFF 的字符称为增补字符。
int 值可以表示所有的 Unicode 代码点,包括增补代码点。int 的 21 个低位表示 Unicode 代码点,且 11 个高位必须为 0。
Java 的 char类型使用 UTF-16 编码描述一个代码单元。在这种表现形式下,增补字符用一对代码单元编码,即 2 个 char,其中,第一个值取值自 \\uD800-\\uDBFF (高代理项范围),第二个值取值自 \\uDC00-\\uDFFF (低代理项范围)。
Java字符串由 char 序列组成,上面我们已经说过,char 数据类型是一个采用 UTF-16 编码表示 Unicode 代码点的代码单元,大多数的常用 Unicode 字符使用一个代码单元就可以表示,而增补字符需要一对代码单元表示。
Java 代码需要编译成 class 文件后由 JVM 运行,在 class 文件里,字符串使用 UTF-8 编码,保存于常量池中。
2、对方法加 synchronized 关键字,线程怎么知道用的哪一把锁
在 java.lang.Thread 中有一个方法叫 holdsLock(),它返回 true 如果当且仅当当前线程拥有某个具体对象的锁。
public static native boolean holdsLock(Object obj);
3、C/S结构,B/S结构概念与对比?
参考文章:C/S和B/S结构概念
- C/S:客户端、服务端
- B/S:浏览器端、服务端
相信区别参考上面推荐的参考文章。
4、ConcurrentHashMap 在JDK1.7和1.8 锁粒度的区别?
JDK1.7
ConcurrentHashMap 能够实现线程安全且高效是因为采用了分段加锁的方式,与 HashMap 结合起来看,其实就是把一个大 table 分成了一段一段的 Segment,Segment 实现了再入锁 ReentranLock,即充当了 ConcurrentHashMap 中锁的角色。Segment 中有一个一个的 HashEntry 键值对有效数据,图可以这么画:

其实可以把 Segment 理解为一个大 table 中一个一个的位置,这么一理解 ConcurrentHashMap 与 HashTable 最大的区别就是ConcurrentHashMap 对大 table 中每个位置加了锁,而 HashMap 如果要加锁的话就是对整个 table 加锁,当然效率就高了。
ConcurrentHashMap 的 get() 方法还是那套,根据 key 找到对应的 Segment,再遍历 key 拿到具体的 HashEntry。
ConcurrentHashMap 的 put() 方法就显得复杂了,不过大致还是那套,大致是先判断是否需要扩容,扩容整理后根据 key 找到对应的Segment,再往 Segment 中 put 键值对,这个时候 put 是加锁的,利用自旋锁去尝试获取锁,获取锁后判断 key 是否存在,存在就覆盖不存在就添加一个键值对。总之就是利用再入锁的方式锁住S egment,保证只有一个线程在操作 Segment,这就相当于在 HashMap 中保证了只有一个线程在数组的一个位置中 put,这当然不会形成环形链表了。

ConcurrentHashMap 的内部细分了若干个小的 HashMap,称之为段(SEGMENT)。ConcurrentHashMap 是一个 Segment 数组,Segment 通过继承 ReentrantLock 来进行加锁,所以每次需要加锁的操作锁住的是一个 Segment,这样只要保证每个 Segment 是线程安全的,也就实现了全局的线程安全。
ConcurrentHashMap 有 16 个 Segments,所以理论上,最多可以同时支持 16 个线程并发写,只要它们的操作分别分布在不同的 Segment 上。这个值可以在初始化的时候设置为其他值,但是一旦初始化以后,它是不可以扩容的。每个 Segment 内部更像是一个 HashMap。
Segment 内部是由 数组+链表 组成的。 插入的位置是链表表头!
ConcurrentHashMap 初始化的时候会初始化第一个槽 segment[0],对于其他槽来说,在插入第一个值的时候进行初始化。
resize() 该方法不需要考虑并发,因为到这里的时候,是持有该 Segment 的独占锁的。
get()操作是不加锁的。
JDK1.8
JDK1.8 中变化较大,首先取消了 Segment,理解一下第一层直接就是 HashEntry。还有就是当链表达到一定长度的时候会以红黑树的形式代替,这个和 HashMap 一样。
put() 的时候采用了 CAS + synchronized 保证线程安全,get() 就还是那样,读不影响线程安全,所以变化不大。

如果是在链表中插入,则插入的位置是在链表尾。
1.7与1.8的区别
- JDK1.8 取消了 Segment 分段锁的数据结构,取而代之的是 数组+链表+红黑树 的结构。
- JDK1.7采用 Segment 的分段锁机制实现线程安全,其中 Segment 继承自 ReentrantLock。JDK1.8采用 CAS+Synchronized 保证线程安全。
- JDK1.7原来是对需要进行插入、修改、删除操作的 Segment(一个大TABLE分割成多个小 Segment) 加锁,现调整为对每个数组TABLE加锁(Node)。
- 从原来的遍历链表 O(n),变成遍历红黑树 O(logN)。
- JDK1.7链表采用头插法,JDK1.8链表采用尾插法。
5、请你说一下 Ping 的工作原理?
流程总结:
ping 是基于 ICMP 协议工作的,所以要明白 ping 的工作,首先我们先要熟悉 ICMP 协议。
ICMP 是什么?
ICMP 全称是 Internet Control Message Protocol,也就是网络报文控制协议。
ICMP 功能是什么?
ICMP 主要的功能包括:确认 IP 包是否成功送达目标地址、并及时报告 IP 包发送过程中是否被废弃,将 IP 包被废弃的具体原因告知数据发送方。
在 IP 通信中如果某个 IP 包因为某种原因未能达到目标地址,那么这个具体的原因将由 ICMP 负责通知发送方。

如图所示,主机 A 向主机 B 发送了数据包,由于某种原因,途中的路由器 2 未能发现主机 B 的存在,这时路由器 2 就会向主机 A 发送一个 ICMP 目标不可达数据包,说明发往主机 B 的包未能成功。
ICMP 的这种通知消息会使用 IP 进行发送 。
因此,从路由器 2 返回的 ICMP 包会按照往常的路由控制先经过路由器 1 再转发给主机 A 。
收到该 ICMP 包的主机 A 分解 ICMP 包的首部和数据域以后得知具体发生问题的原因。
ICMP 包首部(头部)的类型字段,大致可以分为两大类:
- 一类是用于诊断的查询消息,也就是「查询报文类型」。
- 另一类是通知出错原因的错误消息,也就是「差错报文类型」。
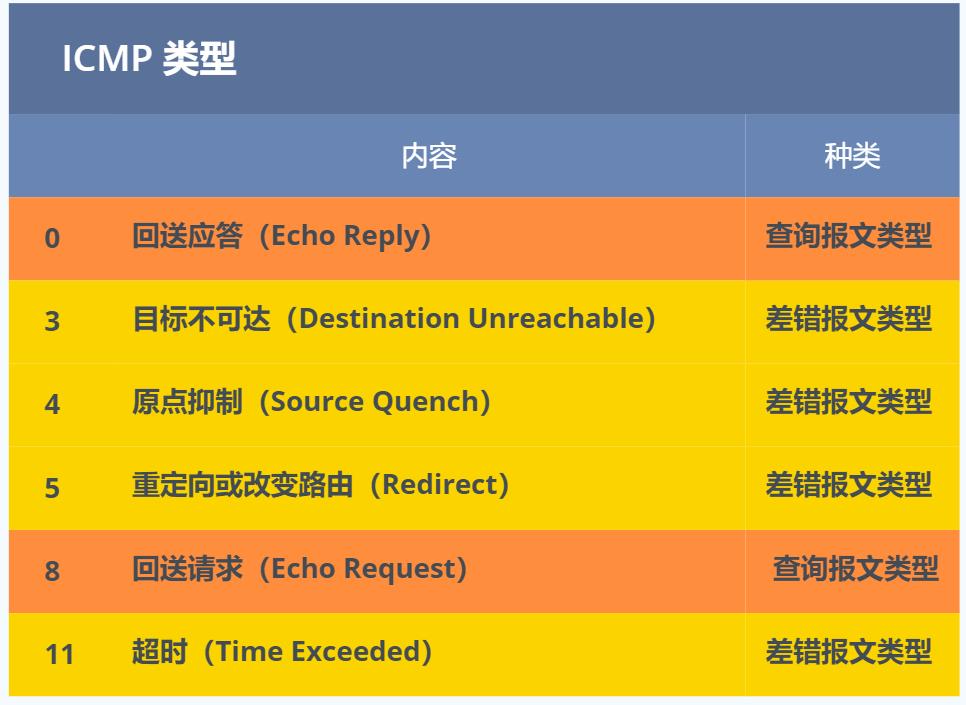
ping命令就是采用的是 「查询报文类型」实现的:
回送消息 —— 类型 0 和 8,用于进行通信的主机或路由器之间,判断所发送的数据包是否已经成功到达对端的一种消息。

可以向对端主机发送回送请求的消息(ICMP Echo Request Message,类型 8),也可以接收对端主机发回来的回送应答消息(ICMP Echo Reply Message,类型 0)。

相比原生的 ICMP,这里多了两个字段:
- 标识符:用以区分是哪个应用程序发 ICMP 包,比如用进程
PID作为标识符; - 序号:序列号从
0开始,每发送一次新的回送请求就会加1, 可以用来确认网络包是否有丢失。
在选项数据中,ping 还会存放发送请求的时间值,来计算往返时间,说明路程的长短。
差错报文类型:
目标不可达消息(Destination Unreachable Message) —— 类型为 3。
IP 路由器无法将 IP 数据包发送给目标地址时,会给发送端主机返回一个目标不可达的 ICMP 消息,并在这个消息中显示不可达的具体原因,原因记录在 ICMP 包头的代码字段。
由此,根据 ICMP 不可达的具体消息,发送端主机也就可以了解此次发送不可达的具体原因。
举例 6 种常见的目标不可达类型的代码:

6、JVM 中有哪几种内存屏障?
- ① StoreStore 屏障:禁止该屏障前面的写操作,和后面的写操作重排序。
- ② StoreLoad 屏障:禁止该屏障前面的写操作,和后面的读操作重排序。
- ③ LoadLoad 屏障:禁止该屏障前面的读操作,和后面的读操作重排序。
- ④ LoadStore 屏障:禁止该屏障前面的读操作,和后面的写操作重排序。
7、什么是倒排索引?
参考文章:
- 正排索引:正排表是以文档的 ID 为关键字,表中记录文档中每个词的位置信息,查找时扫描表中每个文档中词的信息直到找出所有包含查询关键词的文档。
如图:
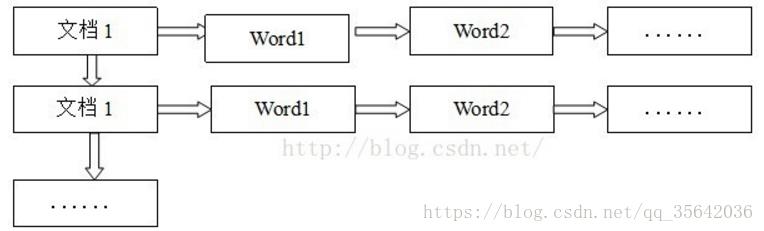
正排表结构如上图所示,这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
- 倒排索引:倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的 ID 和字符在该文档中出现的位置情况。
如图:
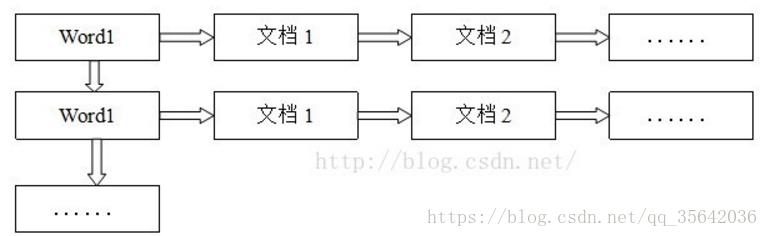
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
ElasticSearch 倒排索引的原理,参考文章:倒排索引、分词详解
8、Spring Bean 的注入方式?
参考文章:Spring定义bean的注入方式
- 构造器注入
- setter 方法注入
- 接口注入
- 静态工厂的方法注入
- 实例工厂的方法注入
9、静态内部类和匿名内部类之间的区别?
内部类:
- 成员内部类可访问外部类所有的方法和成员变量。
- 不能有静态的方法和成员变量。
静态内部类:
- 只能访问外部类的静态成员变量与静态方法。
- 静态内部类的非静态成员可访问外部类的静态变量,而不可访问外部类的非静态变量。
匿名内部类:
- 没有类名,没有
class关键字也没有extends和implements等关键字修饰。 - 类的定义和对象的实例化同时进行。
10、红黑树,平衡二叉树、完全二叉树的特点以及区别?
参考文章:红黑树和平衡二叉树有什么区别?
- 二叉查找树:
二叉查找树是二叉树中最常用的一种类型,是为了实现快速查找的,不仅仅支持快速查找一个数,还支持快速插入和删除数据。二叉查找树的这些性能都依赖于二叉查找树的特殊结构,二叉查找树的要求,在树中的任意一个节点,其左子树中的每个节点的值,都要小于这个节点的值,而右子树节点的值都要大于这个节点的值。
- 平衡二叉树(AVL):
AVL树是带有平衡条件的二叉查找树,一般是用平衡因子差值判断是否平衡并通过旋转来实现平衡,左右子树树高不超过 1,和红黑树相比,AVL树是严格的平衡二叉树,平衡条件必须满足(所有节点的左右子树高度差的绝对值不超过1)。不管我们是执行插入还是删除操作,只要不满足上面的条件,就要通过旋转来保持平衡,而旋转是非常耗时的,由此我们可以知道 AVL 树适合用于插入与删除次数比较少,但查找多的情况。
- 红黑树:
红黑树的性质:
| 红黑树的性质 |
|---|
| 性质1:每个节点要么是黑色,要么是红色。 |
| 性质2:根节点是黑色。 |
| 性质3:每个叶子节点(NIL)是黑色。 |
| 性质4:每个红色节点的两个子节点一定都是黑色。不能有两个红色节点相连。 |
| 性质5:任意一节点到每个叶子节点的路径都包含数量相同的黑结点。俗称:黑高! |
红黑树的优势在于它是一棵平衡二叉查找树,对于普通的二叉查找树(非平衡二叉查找树)在极端情况下可能会退化为链表的结构,例如,当我们依次插入 3、4、5、6、7、8 这些数据时,二叉树会退化为如下链表结构:

红黑树是一种弱平衡二叉树(只有黑色节点完美平衡,红色节点不一定平衡),是特殊的二叉查找树(平衡二叉查找树)。
找工作,要拿一份高薪,不光要有扎实的基础知识体系,也需要不断开阔自己的技术栈,这里给大家分享两门中间件学习课程,Kafka 和 Redis 的教学视频~


以上是关于Java实习生每日10道面试题打卡!的主要内容,如果未能解决你的问题,请参考以下文章