近期面试总结:秒杀设计AQS synchronized相关问题
Posted 兴趣使然的草帽路飞
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了近期面试总结:秒杀设计AQS synchronized相关问题相关的知识,希望对你有一定的参考价值。

1、面试官:如何设计一个秒杀系统?请你阐述流程?
这一面试题答案参考自三太子敖丙的文章:阿里面试官问我:如何设计秒杀系统?我给出接近满分的回答
秒杀系统要解决的几个问题?
① 高并发
秒杀的特点是时间极短、 瞬间用户量大。在秒杀活动持续时间内,Redis 服务器需要承受大量的用户请求,在大量请求条件下,缓存雪崩,缓存击穿,缓存穿透这些问题都是有可能发生的。
一旦缓存失效,或者缓存无效,每秒上万甚至十几万的QPS(每秒请求数)直接打到数据库,基本上都要把库打挂掉,而且你的服务不单单是做秒杀的还涉及其他的业务,你没做降级、限流、熔断啥的,别的一起挂,小公司的话可能全站崩溃404。
为此,在设计秒杀系统时,首先要考虑并发安全和用户访问效率,二者缺一不可!
② 超卖
但凡设计到商品购买,秒杀购物问题,最需要注意的就是超卖问题,因为一旦由于程序不安全,导致超卖问题产生,不光需要赔付商家损失,还需要追究秒杀系统的开发者的责任!
③ 恶意请求
在秒杀购物时,商品价格比较低,价值较高的商品可能会被一些恶意的第三方,开多台机器执行抢购脚本,机器抢购肯定要比我们人手动点击要快,所以,在设计秒杀系统时,要防止 不良程序员 的恶意抢购。
④ 链接暴露
假如设置定时秒杀开启,在未到秒杀开启时间之前,下单购买按钮应该是禁用的(不可点击),但是,如果我们请求下单的链接没有经过网关加密封装,而是直接以原链接的方式依附于下单购买按钮,那么 F12 时,就可以获取下单购买链接 URL,然后直接去请求下单链接,跳过点击方式直接购买商品!
如何解决上面遇到的几个问题?
① 秒杀模块微服务化
对于秒杀抢购系统,将其设计成单独一个模块,单独部署一台或者多太服务器,这样可以避免服务崩溃时,公司其他项目可以正常运行不受影响。
与此同时,要单独给秒杀系统建立一个数据库,现在的互联网架构部署都是分库的,一样的就是订单服务对应订单库,秒杀我们也给他建立自己的秒杀数据库,防止服务崩溃对其他数据库造成影响。
② 秒杀链接加盐
URL动态化,通过 MD5 之类的加密算法加密随机的字符串去做 URL,然后通过前端代码获取 URL 后台校验后才能通过。
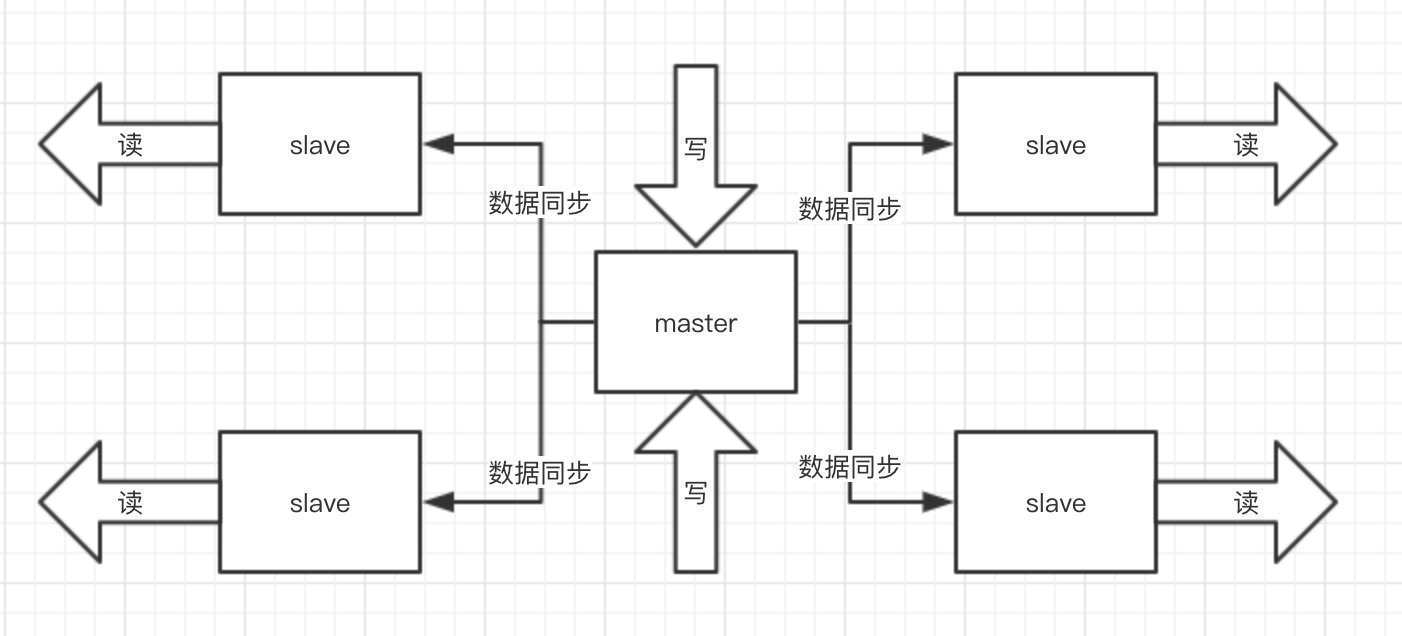
③ Redis集群
如果在大请求量下,单机的Redis顶不住,那就多找几个兄弟,秒杀本来就是读多写少,通过 Redis 集群,主从同步、读写分离,再加上 哨兵、开启 持久化,来保证 Redis 服务高可用!
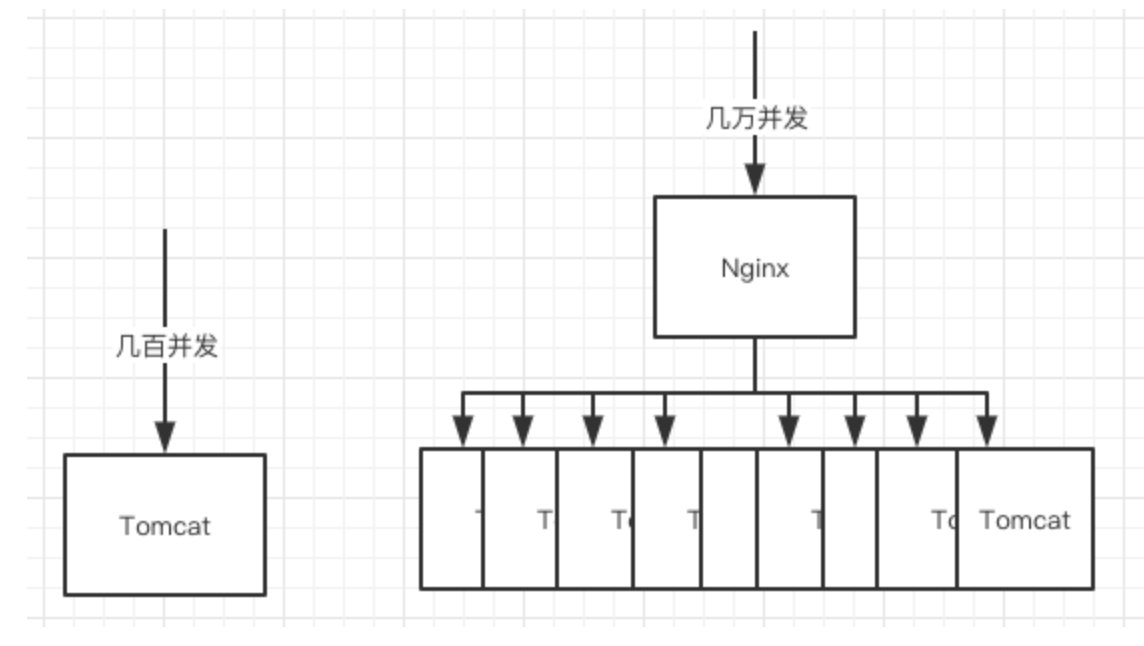
④ 通过 nginx 做负载均衡
Nginx 是 高性能的web服务器,并发随便顶几万不是梦,但是我们的 Tomcat 只能顶几百的并发,我们可以通过Nginx 负载均衡,平分大并发量的请求给多台服务器的 Tomcat,在秒杀开启的时候可以多租点流量机。
⑤ 秒杀页面资源静态化
秒杀一般都是特定的商品还有页面模板,现在一般都是前后端分离的,所以页面一般都是不会经过后端的,但是前端也要自己的服务器啊,那就把能提前放入**cdn服务器 **的东西都放进去,反正把所有能提升效率的步骤都做一下,减少真正秒杀时候服务器的压力。
⑥ 下单按钮控制
在没到秒杀开始时间之前,一般下单按钮都是置灰的,只有时间到了,才能点击。这是因为怕大家在时间快到的最后几秒秒疯狂请求服务器,然后还没到秒杀的时候基本上服务器就挂了。
这个时候就需要前端的配合,定时去请求你的后端服务器,获取最新的北京时间,到时间点再给按钮可用状态。按钮可以点击之后也得给他置灰几秒,不然他一样在开始之后一直点的。
⑦ 前后端限流
限流可以分为 前端限流 和 后端限流。
- 前端限流:这个很简单,一般秒杀抢购,下单按钮不会让你一直点的,一般都是点击一下或者两下然后几秒之后才可以继续点击,这也是保护服务器的一种手段。
- 后端限流:秒杀的时候肯定是涉及到后续的订单生成和支付等操作,但是都只是成功的幸运儿才会走到那一步,那一旦 100 个产品卖光了,
return了一个false,前端直接秒杀结束,然后你后端也关闭后续无效请求的介入了。
⑧ 库存预热
秒杀的本质,就是对库存的抢夺。如果每个秒杀下单的用户请求过来,都去数据库查询库存校验库存,然后扣减库存,这样不光效率低下,而且数据库压力也是巨大的!
既然数据库顶不住,但是他的兄弟非关系型的数据库 Redis 能顶啊!
超卖问题:
我们要在开始秒杀之前,通过定时任务提前把商品的库存加载到 Redis 中去,让整个库存校验流程都在 Redis 里面去做,然后等到秒杀活动结束了,再异步的去修改数据库中库存就好了。
但是用了 Redis 就有一个问题了,我们上面说了我们采用 主从 Redis,就是我们会先去读取库存,再判断库存,当有库存时才会去减库存,正常情况没问题,但是高并发的情况问题就很大了。
就比如现在库存只剩下 1 个了,我们高并发嘛,4 个服务器一起查询了发现都是还有 1 个,那大家都觉得是自己抢到了,就都去扣库存,那结果就变成了 -3,这种情况下,只有一个请求是真的抢到商品了,其他 3 个都是超卖的。
如何解决?
可以通过使用 Lua 脚本来解决超卖问题。
**Lua 脚本是类似Redis事务,有一定的原子性,不会被其他命令插队,可以完成一些 Redis 事务性的操作。**这点是关键!
把判断库存、扣减库存的操作都写在一个 Lua 脚本中,并将该脚本交给 Redis 去执行,当 Redis 中库存数量减到 0 之后,后面扣库存的请求都直接 return false。
⑨ 限流&降级&熔断&隔离
不怕一万就怕万一,万一秒杀系统真的顶不住了,限流,顶不住就挡一部分出去。但是不能说不行,降级,降级了还是被打挂了,熔断,至少不要影响别的系统,隔离,你本身就独立的,但是你会调用其他的系统嘛,你快不行了你别拖累兄弟们啊。
2、面试官:AQS源码有了解过吗?请你说一下加锁和释放锁的流程
这一面试题答案参考自三太子敖丙的文章:我画了35张图就是为了让你深入 AQS
① AQS 基本介绍
AQS中 维护了一个volatile int state(代表共享资源)和一个 FIFO 线程等待队列(多线程争用资源被阻塞时会进入此队列)。
这里volatile能够保证多线程下的可见性,当state = 1则代表当前对象锁已经被占有,其他线程来加锁时则会失败,加锁失败的线程会被放入一个 FIFO的等待队列中,并会被 UNSAFE.park() 操作挂起,等待其他获取锁的线程释放锁才能够被唤醒。
另外state的操作都是通过CAS来保证其并发修改的安全性。
如图所示:

AQS 中提供了很多关于锁的实现方法:
getState():获取锁的标志 state 值。setState():设置锁的标志 state 值。tryAcquire(int):独占方式获取锁。尝试获取资源,成功则返回 true,失败则返回 false。tryRelease(int):独占方式释放锁。尝试释放资源,成功则返回 true,失败则返回 false。
② 加锁与竞争锁使用场景分析
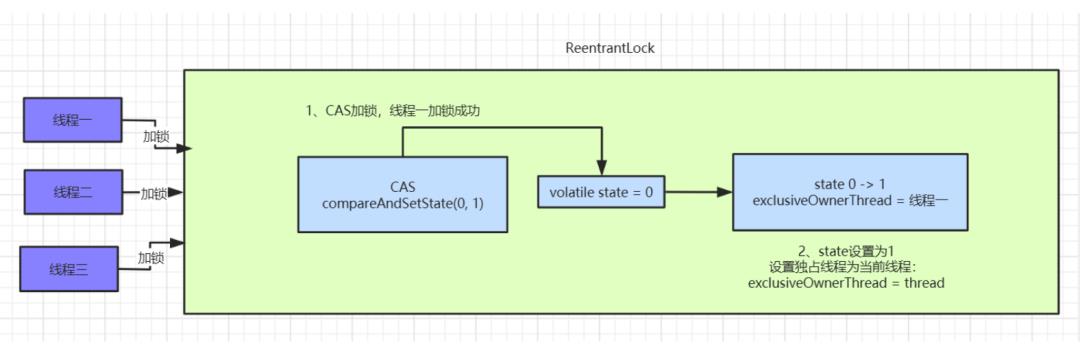
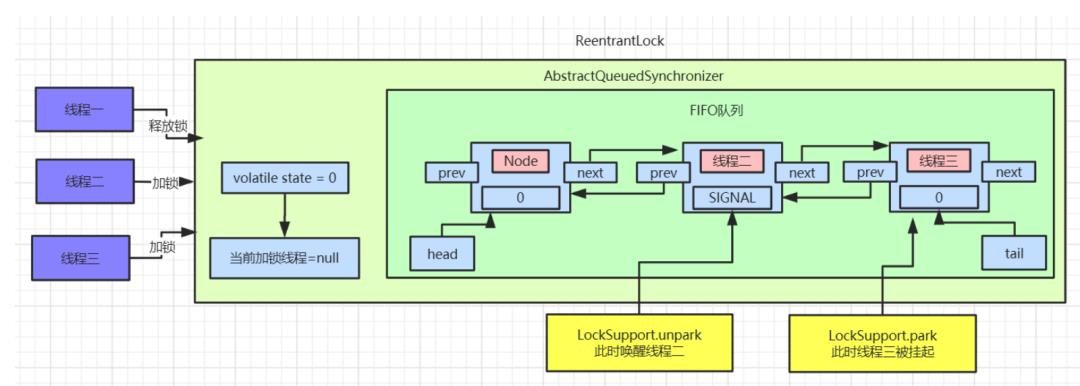
如果同时有三个线程并发抢占锁,此时线程一抢占锁成功,线程二和线程三抢占锁失败,具体执行流程如下:
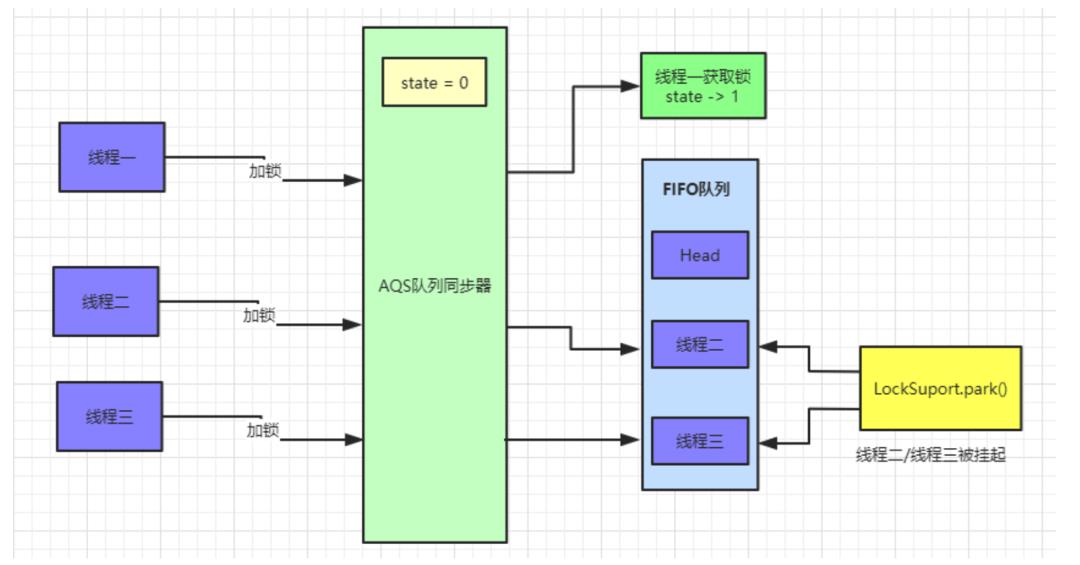
此时AQS内部数据为:
具体看下抢占锁代码实现:java.util.concurrent.locks.ReentrantLock .NonfairSync
static final class NonfairSync extends Sync {
// 加锁
final void lock() {
// CAS 修改 state 的值为 1
if (compareAndSetState(0, 1))
setExclusiveOwnerThread(Thread.currentThread());
else
acquire(1);
}
// 尝试竞争资源
protected final boolean tryAcquire(int acquires) {
return nonfairTryAcquire(acquires);
}
}
这里使用的 ReentrantLock 非公平锁,线程进来直接利用CAS尝试抢占锁,如果抢占成功state值回被改为 1,且设置独占锁线程对象为当前线程。
// CAS 尝试抢占锁
protected final boolean compareAndSetState(int expect, int update) {
return unsafe.compareAndSwapInt(this, stateOffset, expect, update);
}
// 设置独占锁线程对象为当前线程
protected final void setExclusiveOwnerThread(Thread thread) {
exclusiveOwnerThread = thread;
}
线程一抢占锁成功后,state变为 1,线程二通过CAS修改state变量必然会失败。此时AQS中FIFO(First In First Out 先进先出)队列中。
public final void acquire(int arg) {
if (!tryAcquire(arg) &&
acquireQueued(addWaiter(Node.EXCLUSIVE), arg))
selfInterrupt();
}
tryAcquire() 方法的具体实现是通过内部调用nonfairTryAcquire()方法,这个方法执行的逻辑如下:
- 首先会获取
state的值,如果不为0则说明当前对象的锁已经被其他线程所占有。 - 接着判断占有锁的线程是否为当前线程,如果是则累加
state值,这就是可重入锁的具体实现,累加state值,释放锁的时候也要依次递减state值。 - 如果
state为 0,则执行CAS操作,尝试更新state值为 1,如果更新成功则代表当前线程加锁成功。
③ 释放锁使用场景分析
释放锁的过程,首先是线程一释放锁,释放锁后会唤醒head节点的后置节点,也就是我们现在的线程二,具体操作流程如下:
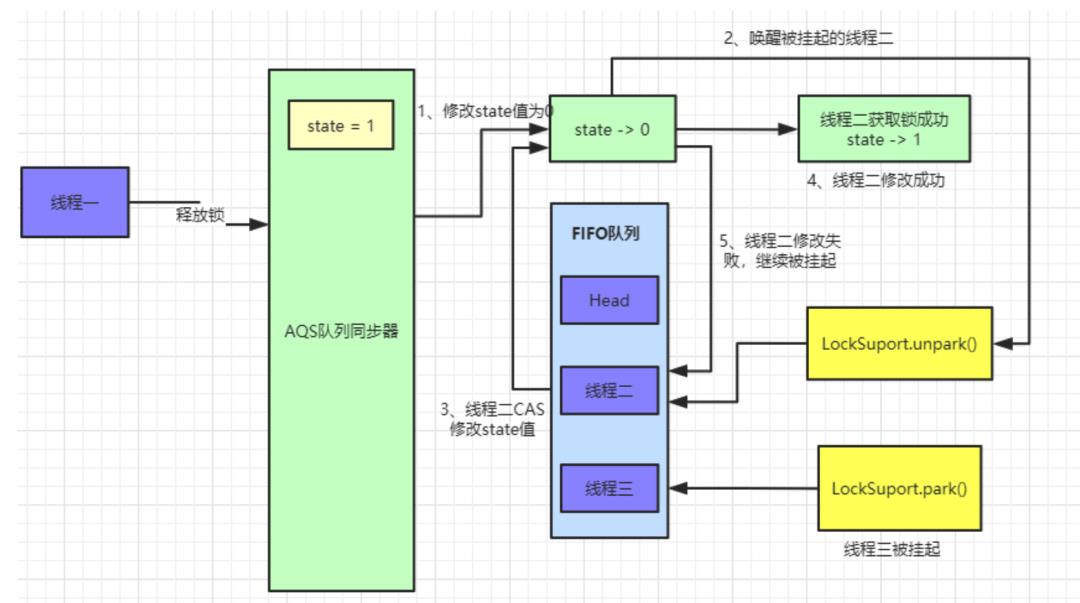
执行完后等待队列数据如下:
此时线程二已经被唤醒,继续尝试获取锁,如果获取锁失败,则会继续被挂起。
线程释放锁的代码:
java.util.concurrent.locks.AbstractQueuedSynchronizer.release():
public final boolean release(int arg) {
if (tryRelease(arg)) {
Node h = head;
if (h != null && h.waitStatus != 0)
unparkSuccessor(h);
return true;
}
return false;
}
这里首先会执行tryRelease()方法,这个方法具体实现在ReentrantLock中,如果tryRelease()执行成功,则继续判断 head 节点的 waitStatus 是否为 0,前面我们已经看到过,head的waitStatue为SIGNAL(-1),这里就会执行 unparkSuccessor() 方法来唤醒 head 的后置节点,也就是上面图中线程二对应的Node节点。
ReentrantLock.tryRelease():
protected final boolean tryRelease(int releases) {
int c = getState() - releases;
if (Thread.currentThread() != getExclusiveOwnerThread())
throw new IllegalMonitorStateException();
boolean free = false;
if (c == 0) {
free = true;
setExclusiveOwnerThread(null);
}
setState(c);
return free;
}
执行完ReentrantLock.tryRelease()后,state被设置成 0,Lock 对象的独占锁被设置为 null。
接着执行java.util.concurrent.locks.AbstractQueuedSynchronizer.unparkSuccessor()方法,唤醒head的后置节点:
private void unparkSuccessor(Node node) {
int ws = node.waitStatus;
if (ws < 0)
compareAndSetWaitStatus(node, ws, 0);
Node s = node.next;
if (s == null || s.waitStatus > 0) {
s = null;
for (Node t = tail; t != null && t != node; t = t.prev)
if (t.waitStatus <= 0)
s = t;
}
if (s != null)
LockSupport.unpark(s.thread);
}
这里主要是将head节点的waitStatus设置为 0,然后解除head节点next的指向,使head节点空置,等待着被垃圾回收。
此时重新将head指针指向线程二对应的Node节点,且使用LockSupport.unpark方法来唤醒线程二。
被唤醒的线程二会接着尝试获取锁,用CAS指令修改state数据。
3、面试官:请你谈一谈synchronized的实现原理
这一面试题答案参考文章:死磕 java同步系列之synchronized解析
synchronized 加锁解锁原理分析
sychronized 锁,在Java内存模型层面,涉及到 2 个指令(JMM 定义了8 个操作来完成主内存和工作内存的交互操作,参考文章:搜集了这么多资料,不信你还理解不了 JMM 内存模型、volatile 关键字保证有序性和可见性实现原理!),lock 和 unlock:
lock,锁定,作用于主内存的变量,它把主内存中的变量标识为线程独占状态。unlock,解锁,作用于主内存的变量,它把锁定的变量释放出来,释放出来的变量才可以被其它线程锁定。
这两个指令并没有直接提供给用户使用,而是提供了两个更高层次的指令 monitorenter 和 monitorexit 来隐式地使用 lock 和 unlock 指令。而 synchronized 就是使用 monitorenter 和 monitorexit 这两个指令来实现的。
根据JVM规范的要求,在执行 monitorenter 指令的时候,首先要去尝试获取对象的锁,如果这个对象没有被锁定,或者当前线程已经拥有了这个对象的锁,就把锁的计数器加1,相应地,在执行 monitorexit 的时候会把计数器减 1,当计数器减小为 0 时,锁就释放了。
sychronized 锁是如何保证,原子性、可见性、和一致性呢?
还是回到Java内存模型上来,synchronized关键字底层是通过 monitorenter 和 monitorexit 实现的,而这两个指令又是通过 lock 和 unlock 来实现的。
而 lock 和 unlock 在Java内存模型中是必须满足下面四条规则的:
- ① 一个变量同一时刻只允许一条线程对其进行
lock操作,但lock操作可以被同一个线程执行多次,多次执行lock后,只有执行相同次数的unlock操作,变量才能被解锁。 - ② 如果对一个变量执行
lock操作,将会清空工作内存中此变量的值,在执行引擎使用这个变量前,需要重新执行load或assign操作初始化变量的值; - ③ 如果一个变量没有被
lock操作锁定,则不允许对其执行unlock操作,也不允许unlock一个其它线程锁定的变量; - ④ 对一个变量执行
unlock操作之前,必须先把此变量同步回主内存中,即执行store和write操作;
通过规则 ①,我们知道对于 lock 和 unlock 之间的代码,同一时刻只允许一个线程访问,所以,synchronized 是具有原子性的。
通过规则 ① ② 和 ④,我们知道每次 lock 和 unlock 时都会从主内存加载变量或把变量刷新回主内存,而 lock 和 unlock 之间的变量(这里是指锁定的变量)是不会被其它线程修改的,所以,synchronized 是具有可见性的。
通过规则 ① 和 ③ ,我们知道所有对变量的加锁都要排队进行,且其它线程不允许解锁当前线程锁定的对象,所以,synchronized 是具有有序性的。
综上所述,synchronized 是可以保证原子性、可见性和有序性的。
synchronized 锁优化
Java在不断进化,同样地,Java 中像 synchronized 这种关键字也在不断优化,synchronized 有如下三种状态:
- 偏向锁,是指一段同步代码一直被一个线程访问,那么这个线程会自动获取锁,降低获取锁的代价。
- 轻量级锁,是指当锁是偏向锁时,被另一个线程所访问,偏向锁会升级为轻量级锁,这个线程会通过自旋的方式尝试获取锁,不会阻塞,提高性能。
- 重量级锁,是指当锁是轻量级锁时,当自旋的线程自旋了一定的次数后,还没有获取到锁,就会进入阻塞状态,该锁升级为重量级锁,重量级锁会使其他线程阻塞,性能降低。
总结
(1)synchronized 在编译时会在同步块前后生成 monitorenter 和 monitorexit 字节码指令;
(2)monitorenter 和 monitorexit 字节码指令需要一个引用类型的参数,基本类型不可以哦;
(3)monitorenter 和 monitorexit 字节码指令更底层是使用Java内存模型的 lock 和 unlock 指令;
(4)synchronized 是可重入锁;
(5)synchronized 是非公平锁;
(6)synchronized 可以同时保证原子性、可见性、有序性;
(7)synchronized 有三种状态:偏向锁、轻量级锁、重量级锁;
为了帮助更多小白从零进阶 Java 工程师,从CSDN官方那边搞来了一套 《Java 工程师学习成长知识图谱》,尺寸 870mm x 560mm,展开后有一张办公桌大小,也可以折叠成一本书的尺寸,有兴趣的小伙伴可以了解一下,当然,不管怎样博主的文章一直都是免费的~

以上是关于近期面试总结:秒杀设计AQS synchronized相关问题的主要内容,如果未能解决你的问题,请参考以下文章