机器学习- 吴恩达Andrew Ng Week8 知识总结 Clustering
Posted 架构师易筋
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了机器学习- 吴恩达Andrew Ng Week8 知识总结 Clustering相关的知识,希望对你有一定的参考价值。
Coursera课程地址
因为Coursera的课程还有考试和论坛,后续的笔记是基于Coursera
https://www.coursera.org/learn/machine-learning/home/welcome
Clustering ML:聚类
1. 无监督学习:简介 Unsupervised learning introduction
无监督学习与监督学习形成对比,因为它使用未标记的训练集而不是标记的训练集。
回顾监督学习:给结果打标, 对y进行分类
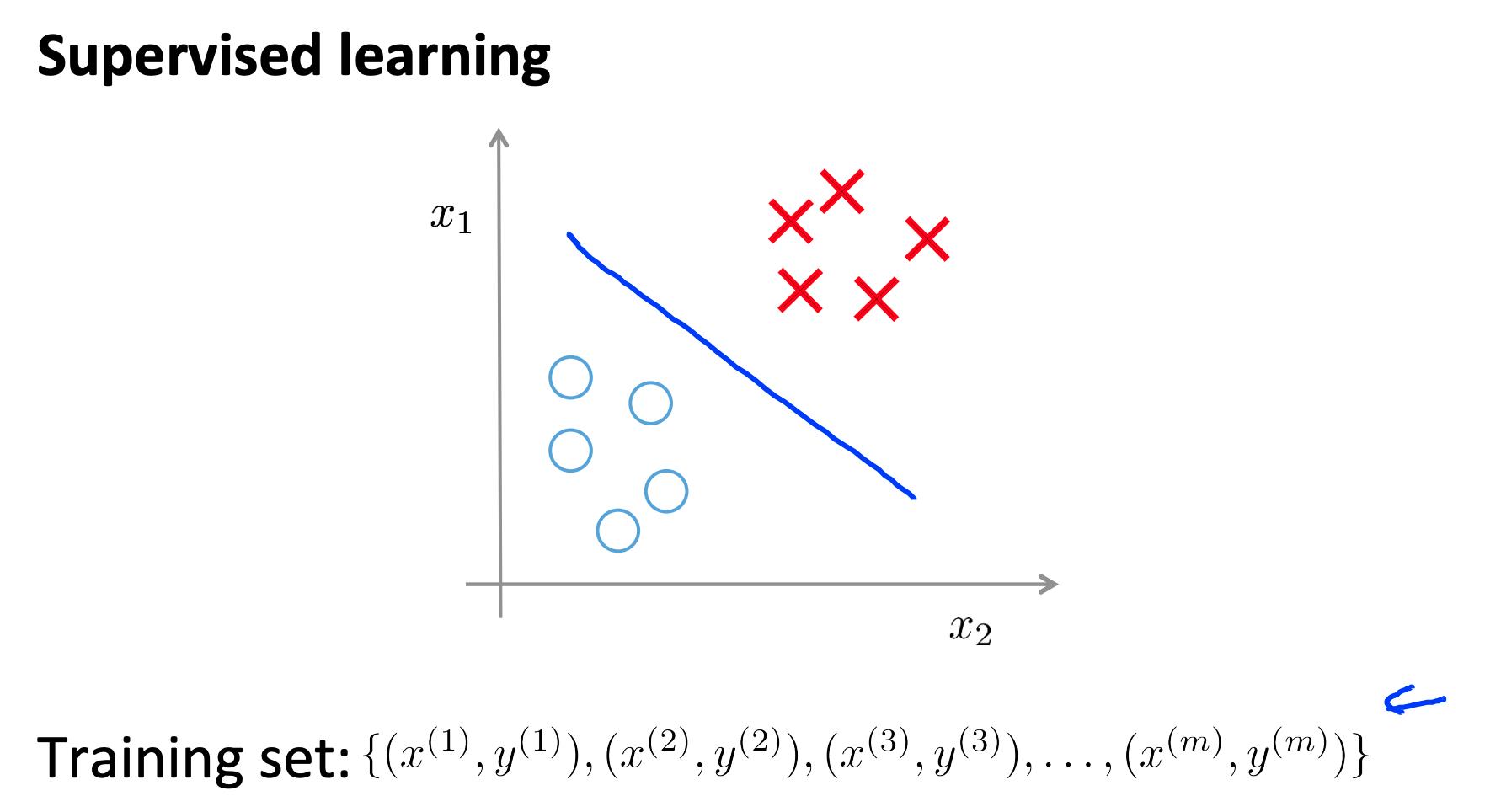
非监督学习,就是y没有分类
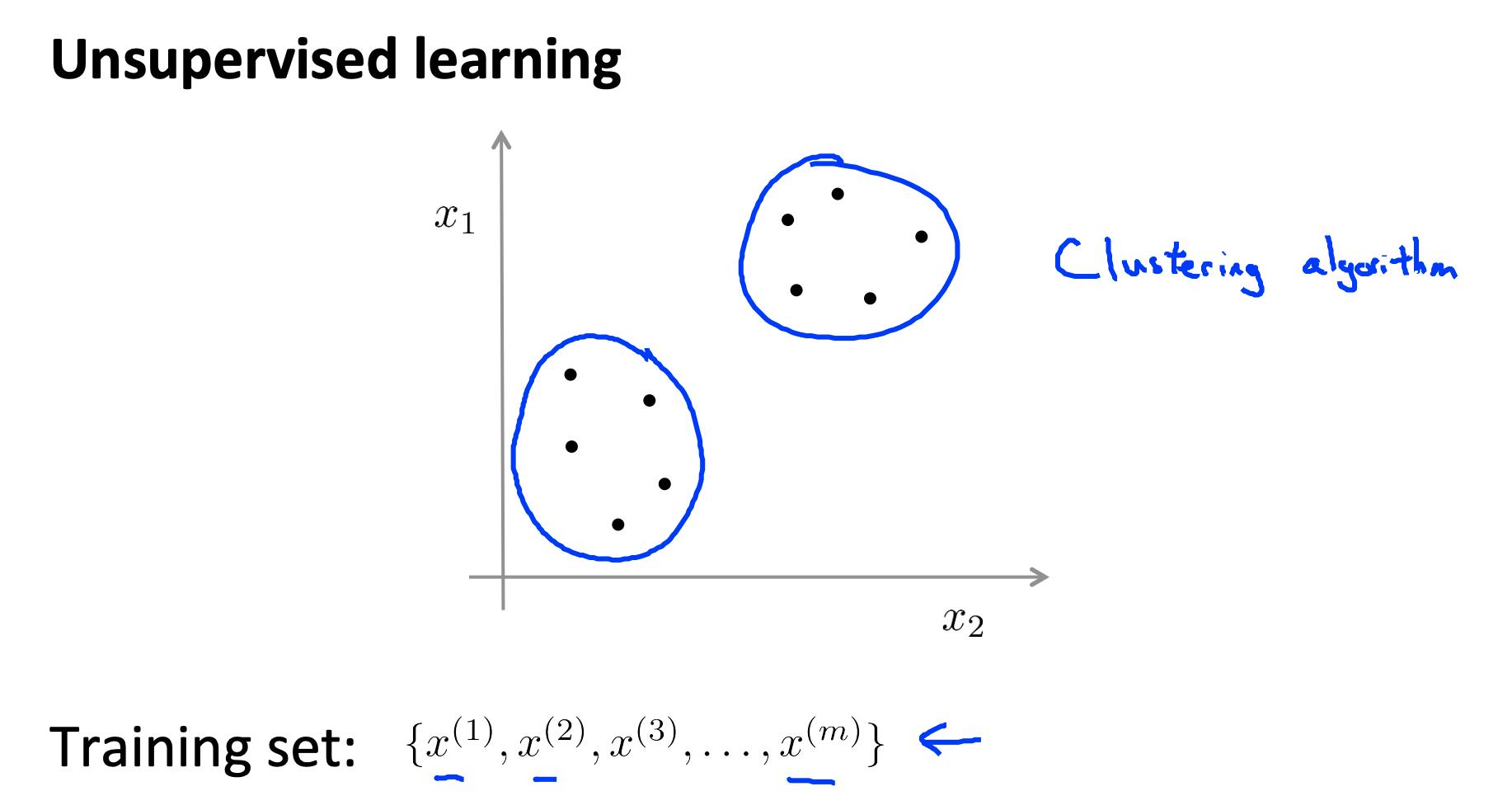
换句话说,我们没有预期结果的向量 y,我们只有一个可以找到结构的特征数据集。
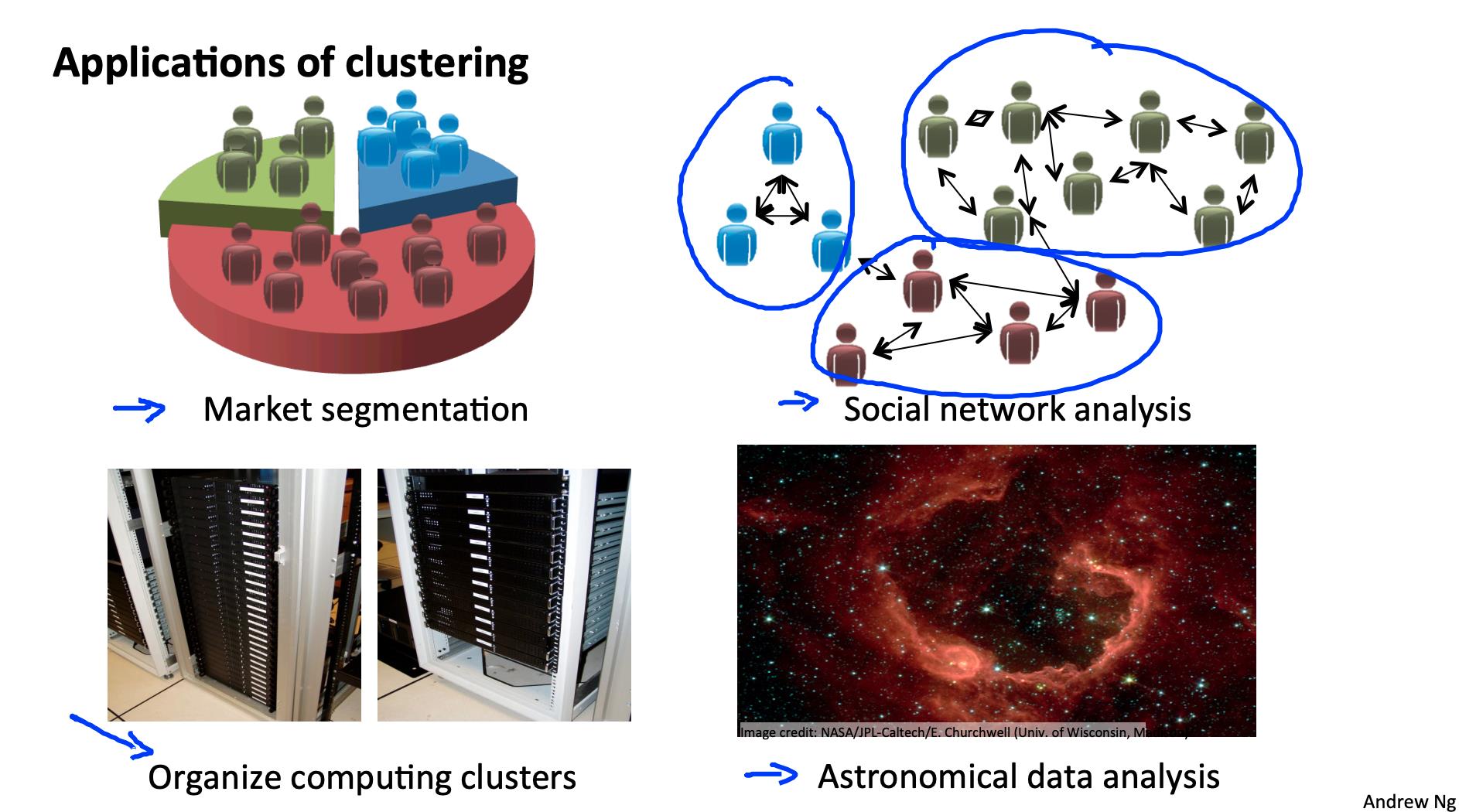
聚类适用于:
- 市场细分
- 社交网络分析
- 组织计算机集群
- 天文数据分析
2. K-Means 算法 K-means algorithm
K-Means 算法是最流行和最广泛使用的算法,用于自动将数据分组为相干子集。
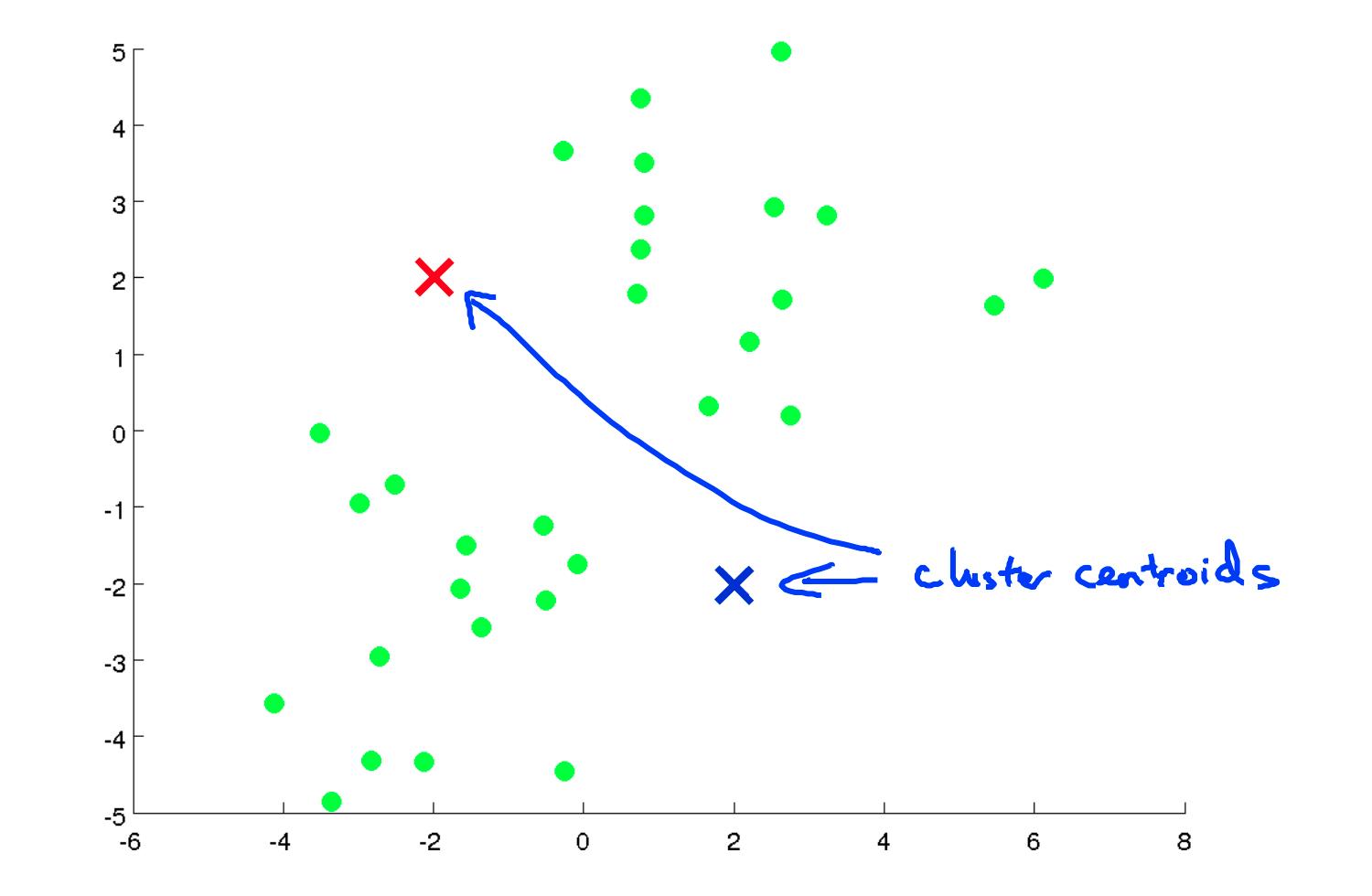
- 随机初始化数据集中的两个点,称为集群质心。
- 集群分配:根据示例最接近的集群质心将所有示例分配到两个组中的一组。
- 移动质心:计算两个聚类质心组中每一个内的所有点的平均值,然后将聚类质心点移动到这些平均值。
- 重新运行 (2) 和 (3) 直到我们找到我们的集群。
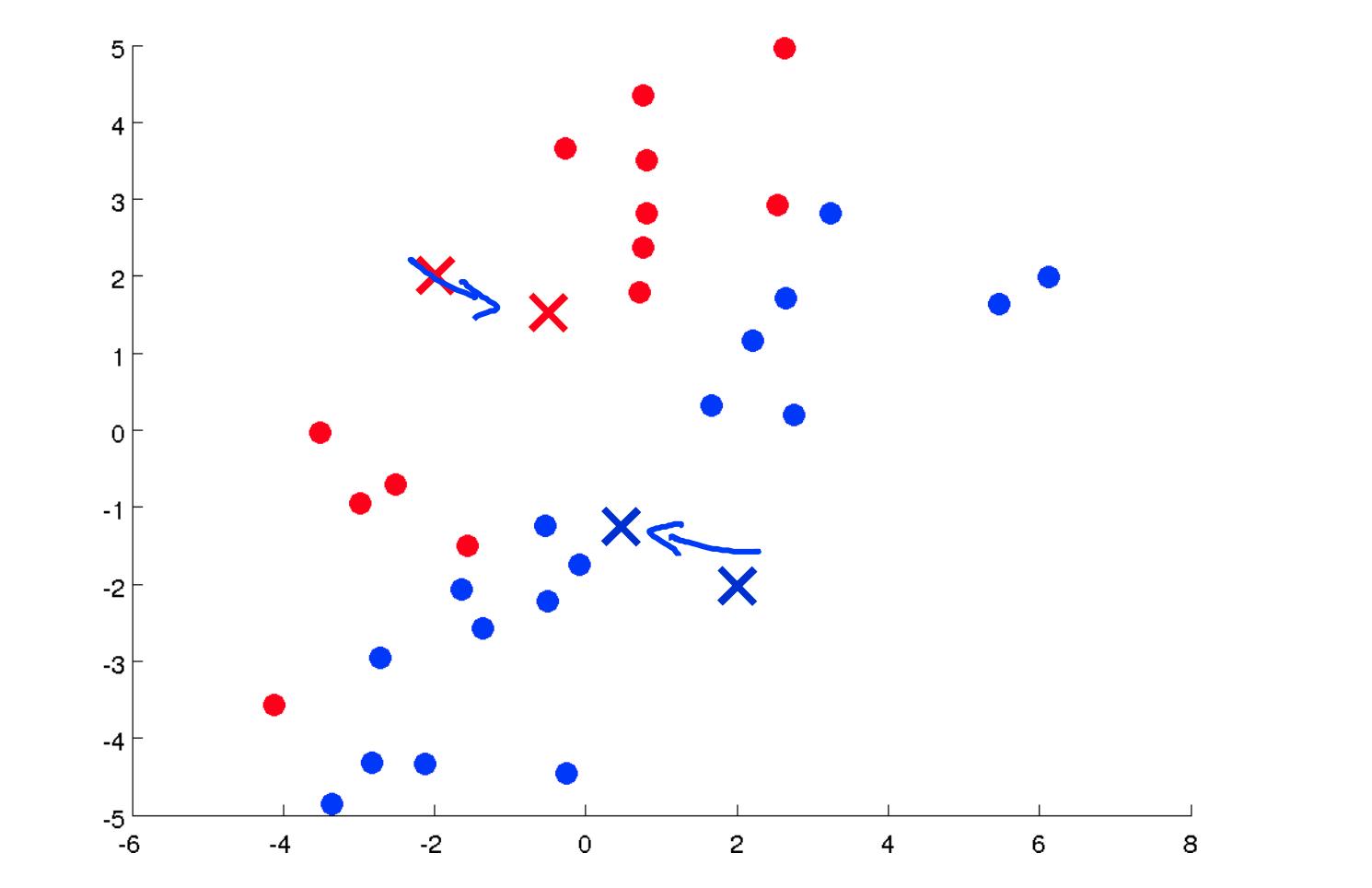
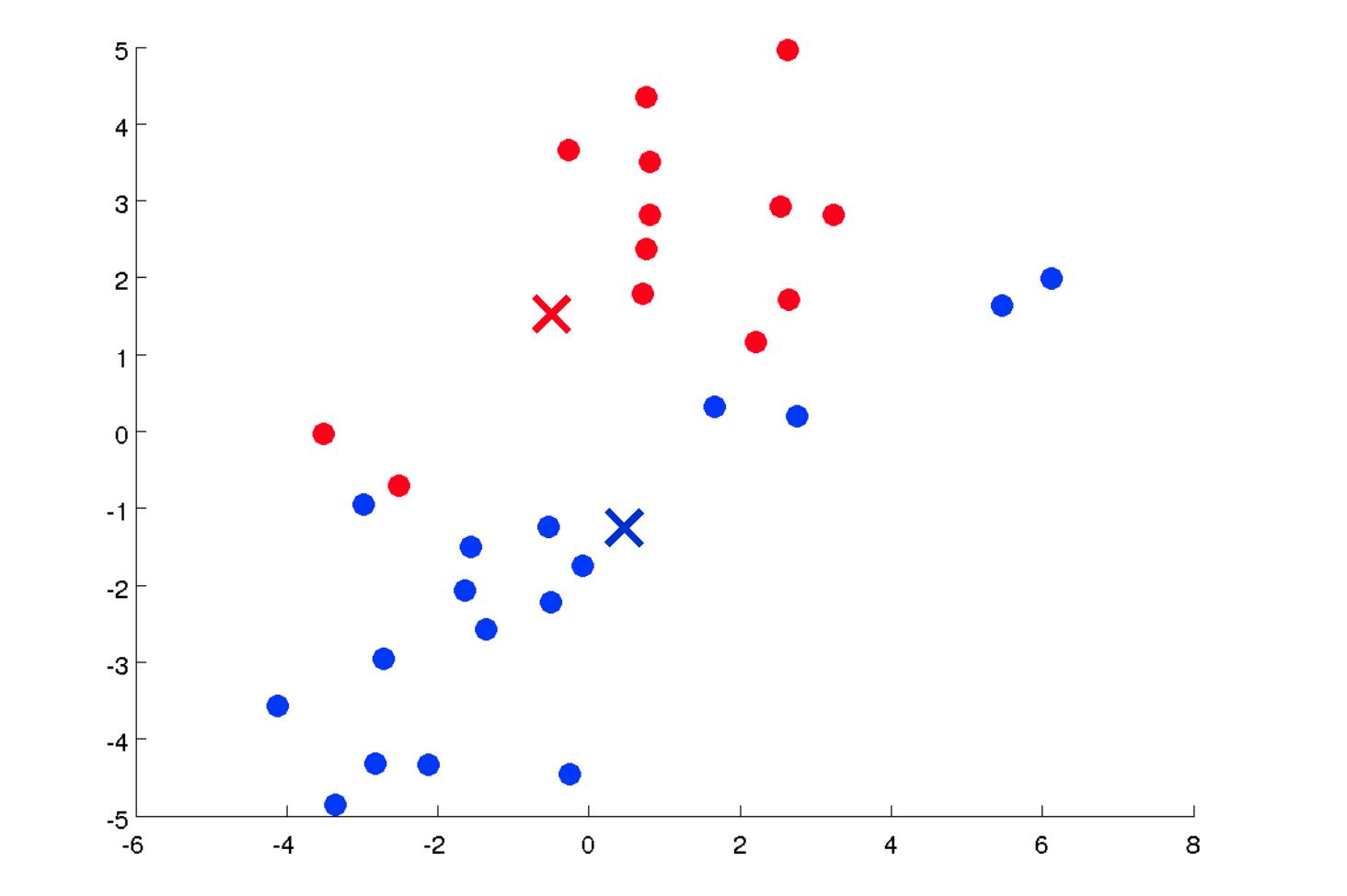
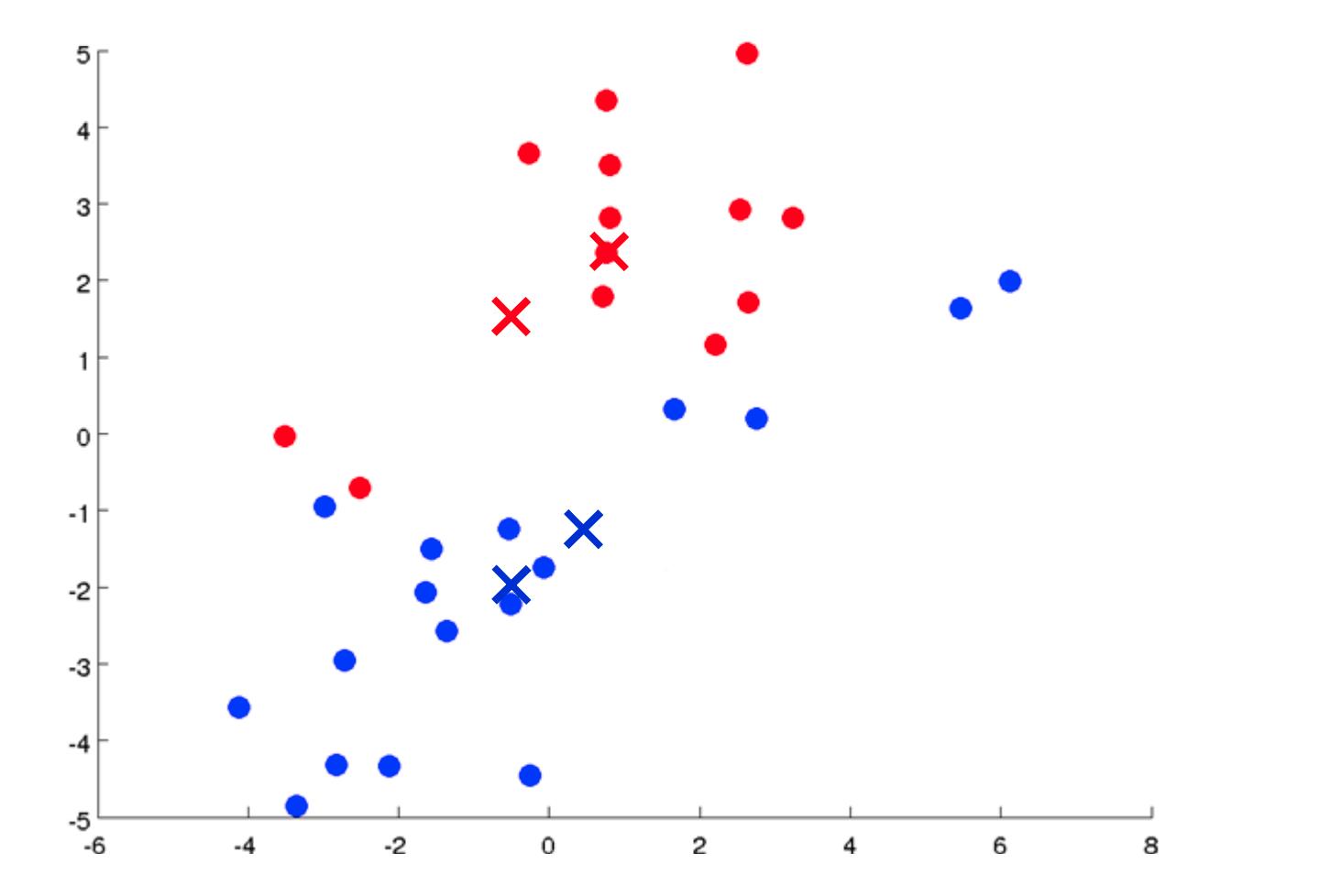
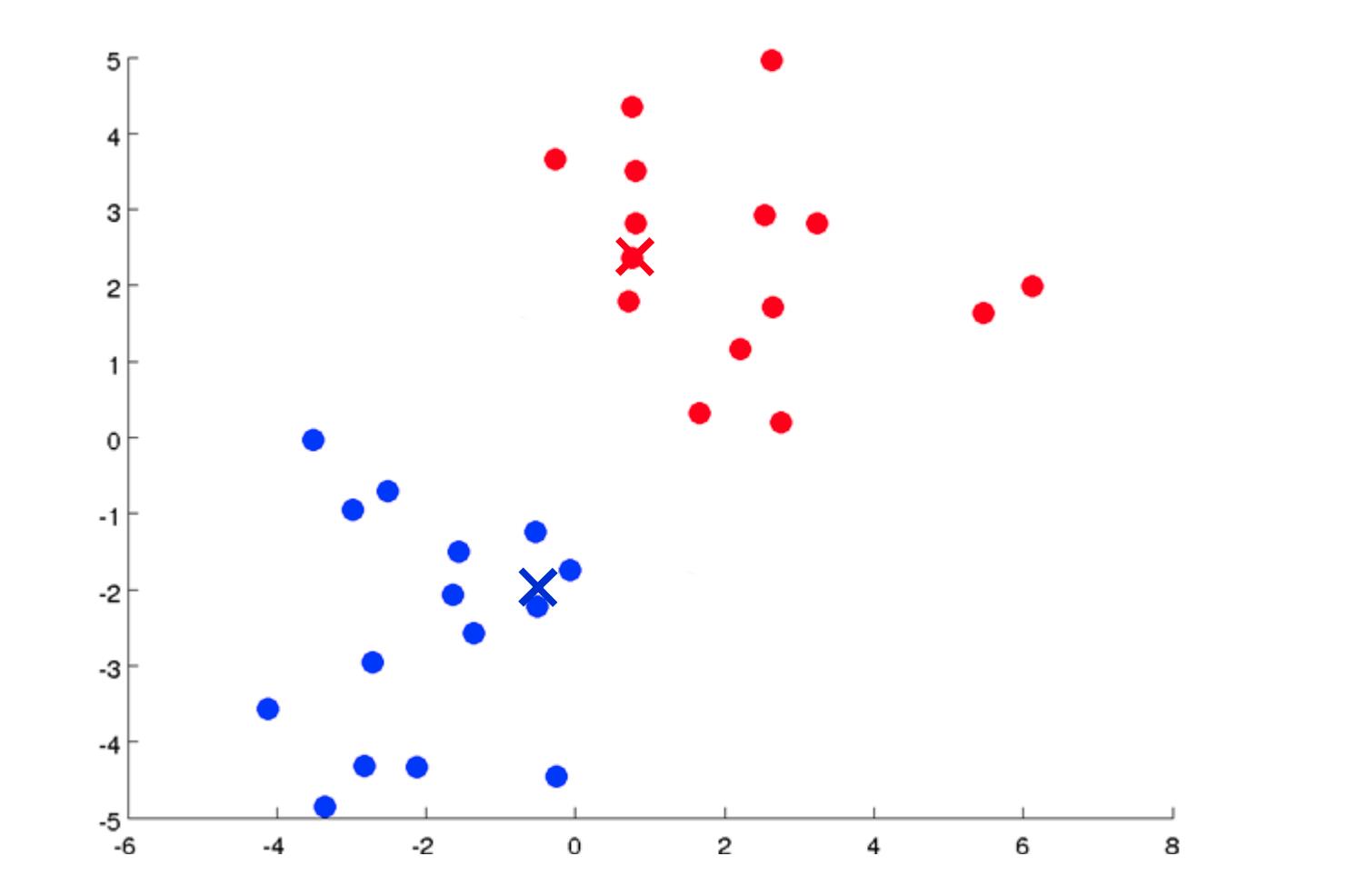
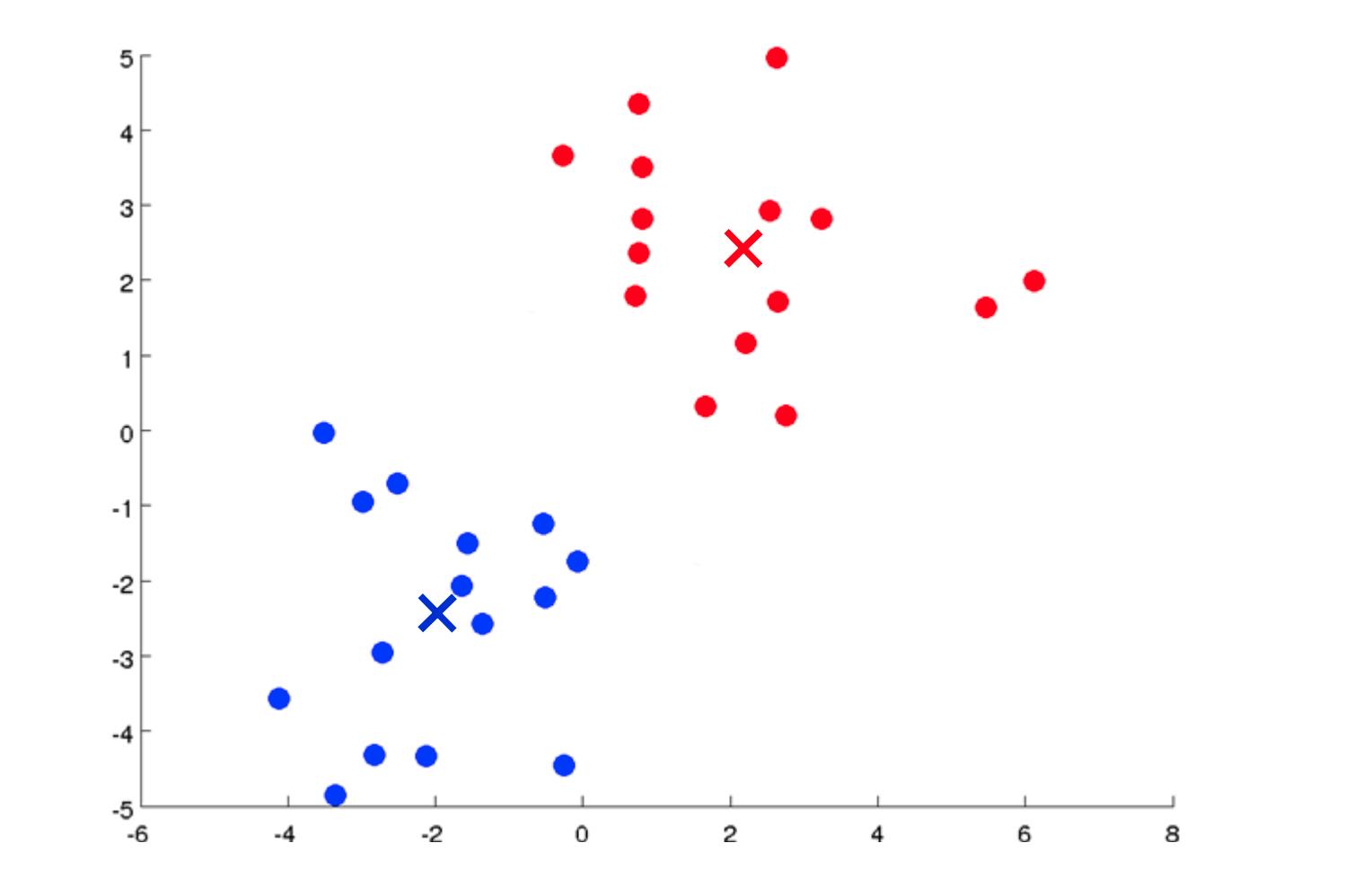
我们的主要变量是:

- K(簇数)
- 训练集 x(1) ,x(2) ,…,x(m)
- 在哪里 x(i) ∈R(n)
请注意,我们不会使用x0=1 约定。
算法:

Randomly initialize K cluster centroids mu(1), mu(2), ..., mu(K)
Repeat:
for i = 1 to m:
c(i):= index (from 1 to K) of cluster centroid closest to x(i)
for k = 1 to K:
mu(k):= average (mean) of points assigned to cluster k
第一个 for 循环是“集群分配”步骤。我们制作了一个向量c,其中c(i)表示分配给示例x(i)的质心。
我们可以更数学地编写集群分配步骤的操作如下:
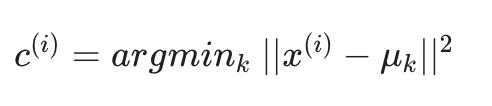
也就是说,每个C(i) 包含距离最小的质心的索引X(i).
按照惯例,我们对右侧进行平方,这使得我们试图最小化的函数急剧增加。这主要只是一个约定。但是一个有助于减少计算负载的约定,因为欧几里德距离需要平方根,但它被取消了。
没有平方:
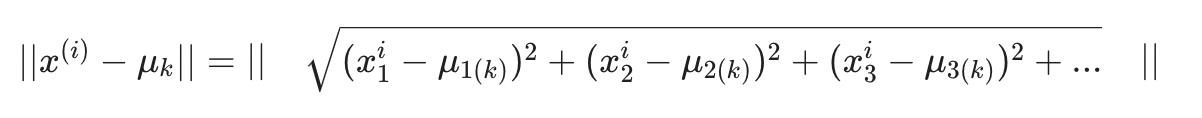
有平方
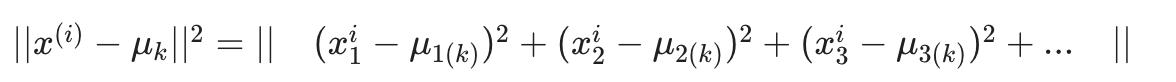
…所以平方约定有两个目的,更锐利地最小化和更少的计算。
所述第二for循环是“移动质心”步骤,其中我们每个质心移动到其平均组。
更正式地,这个循环的方程如下:
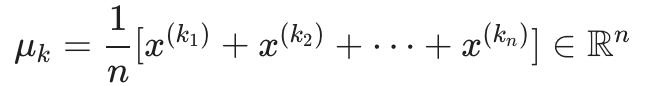
其中每个x(k1),x(k2) ,…,x(kn) 是分配给组的训练示例mμk.
如果您有一个分配了0 个点的簇质心,您可以随机地将该质心重新初始化为一个新点。您也可以简单地消除该集群组。
经过多次迭代后,算法将收敛,其中新的迭代不会影响集群。
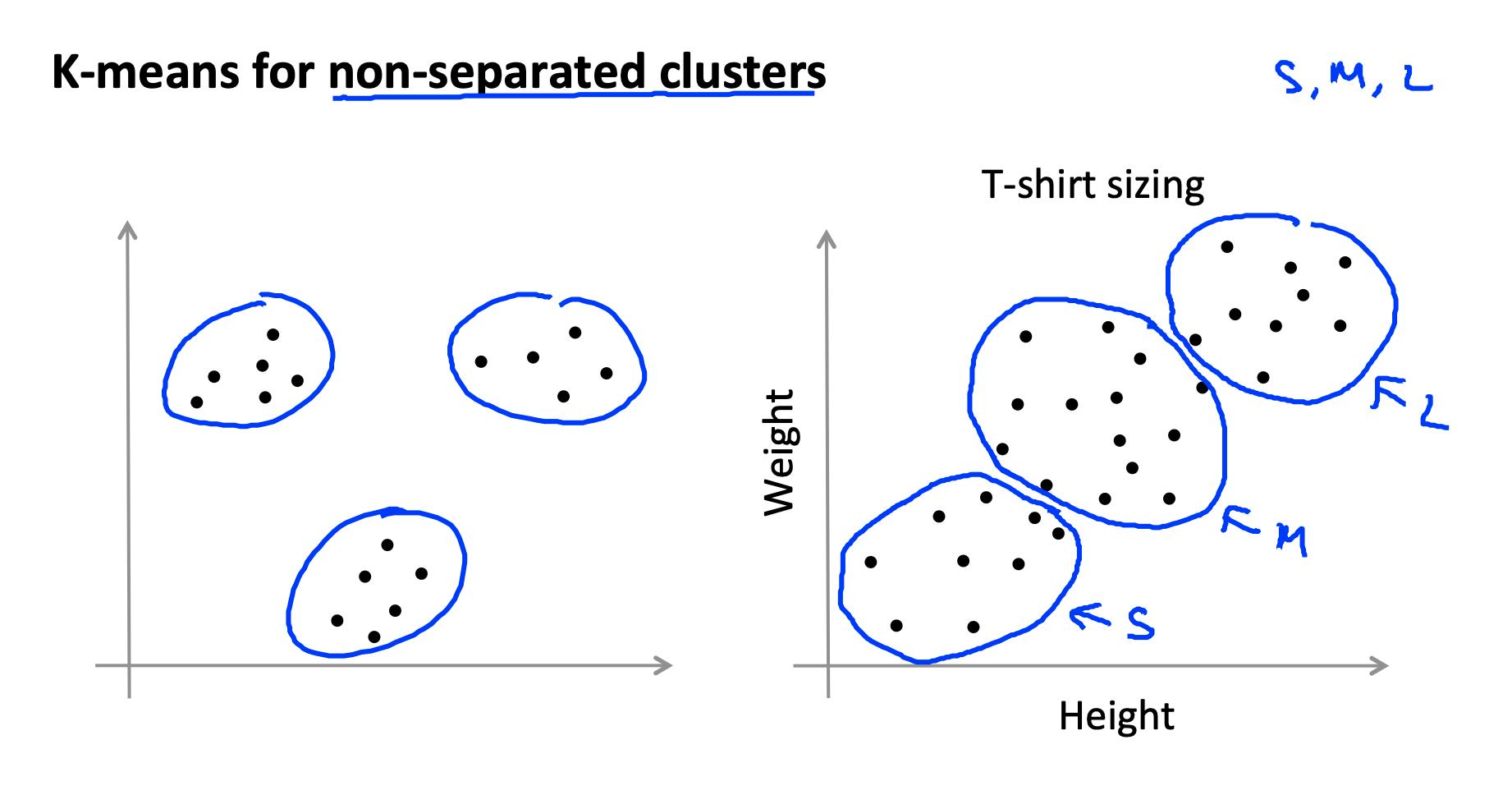
关于非分离集群的注意事项:一些数据集没有真正的内部分离或自然结构。K-means 仍然可以将您的数据均匀地分割为 K 个子集,因此在这种情况下仍然很有用。
3. 优化目标 Optimization Objective

回想一下我们在算法中使用的一些参数:

使用这些变量,我们可以定义我们的成本函数:
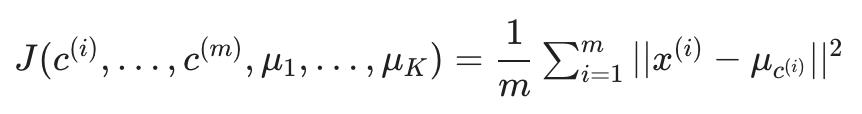
我们的优化目标是使用上述成本函数最小化所有参数:
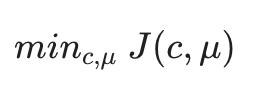
也就是说,我们在集合 c 中找到所有值,代表我们所有的集群,μ 代表我们所有的质心,这将最小化每个训练示例到其相应集群质心的距离的平均值。

上述成本函数通常称为训练示例的失真。
在集群分配步骤中,我们的目标是:
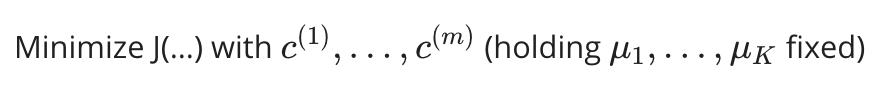
在移动质心步骤中,我们的目标是:

使用 k-means,成本函数有时不可能增加。它应该总是下降。
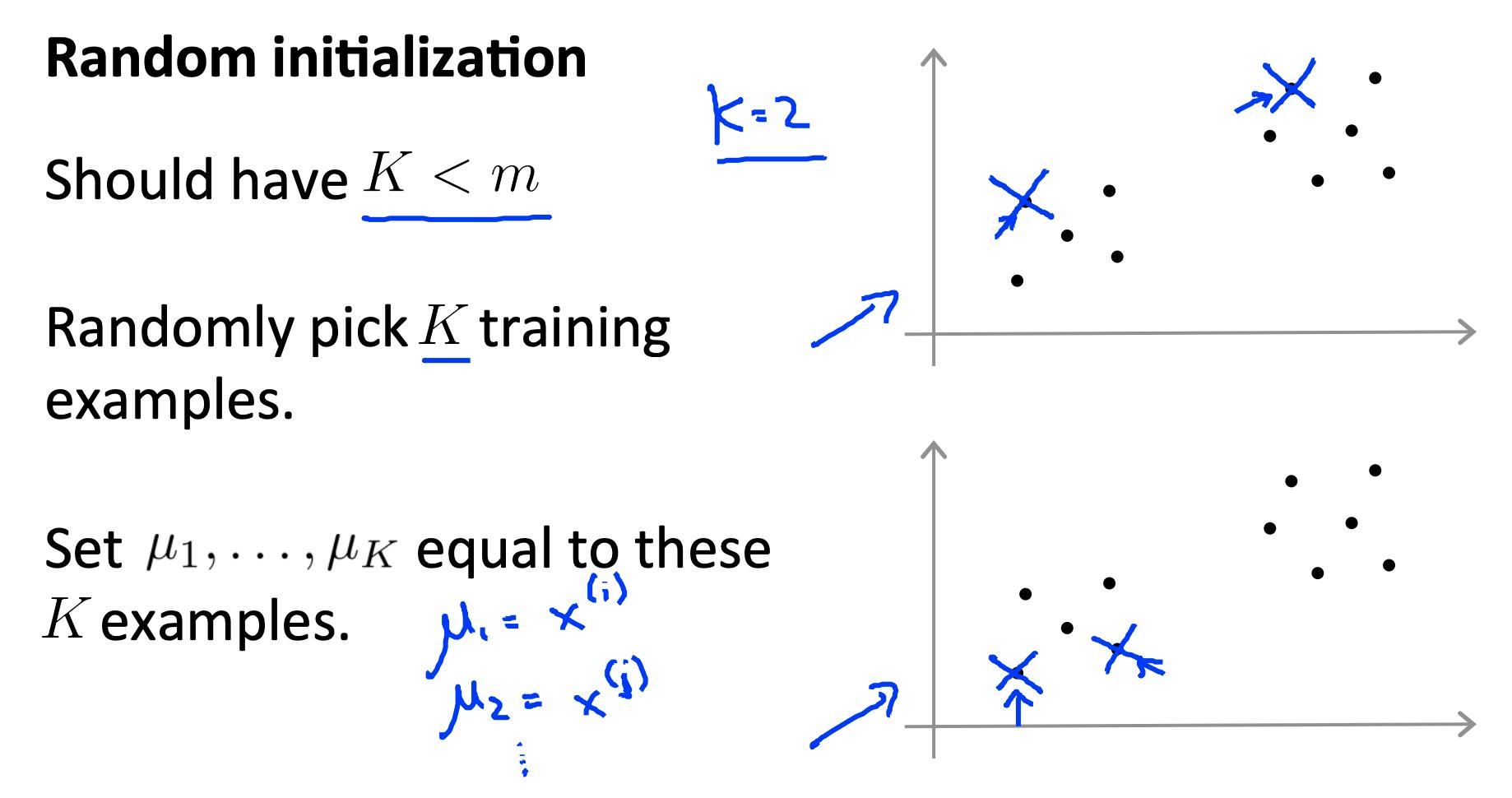
4. 随机初始化 Random initialization
有一种特别推荐的方法来随机初始化您的集群质心。

- 有 K<m。也就是说,确保您的集群数量少于您的训练示例数量。
- 随机选取 K 个训练样本。(讲座中没有提到,但也要确保所选的例子是独一无二的)。
- 设置 μ1, … μk 等于这 K 个例子。
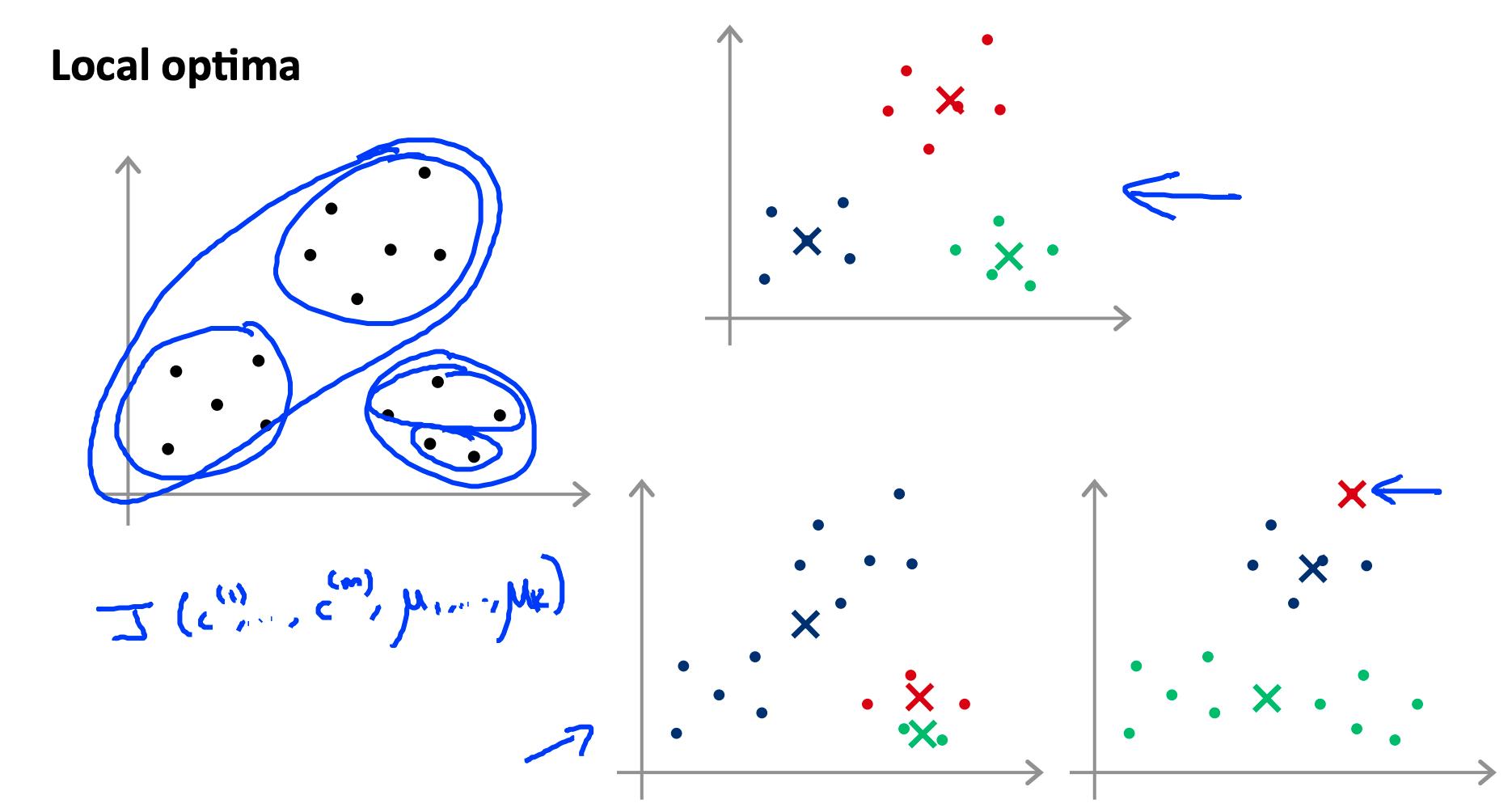
K-means可能会陷入局部最优。为了减少这种情况发生的可能性,您可以在许多不同的随机初始化上运行该算法。在 K<10 的情况下,强烈建议运行随机初始化循环。

for i = 1 to 100:
randomly initialize k-means
run k-means to get 'c' and 'm'
compute the cost function (distortion) J(c,m)
pick the clustering that gave us the lowest cost
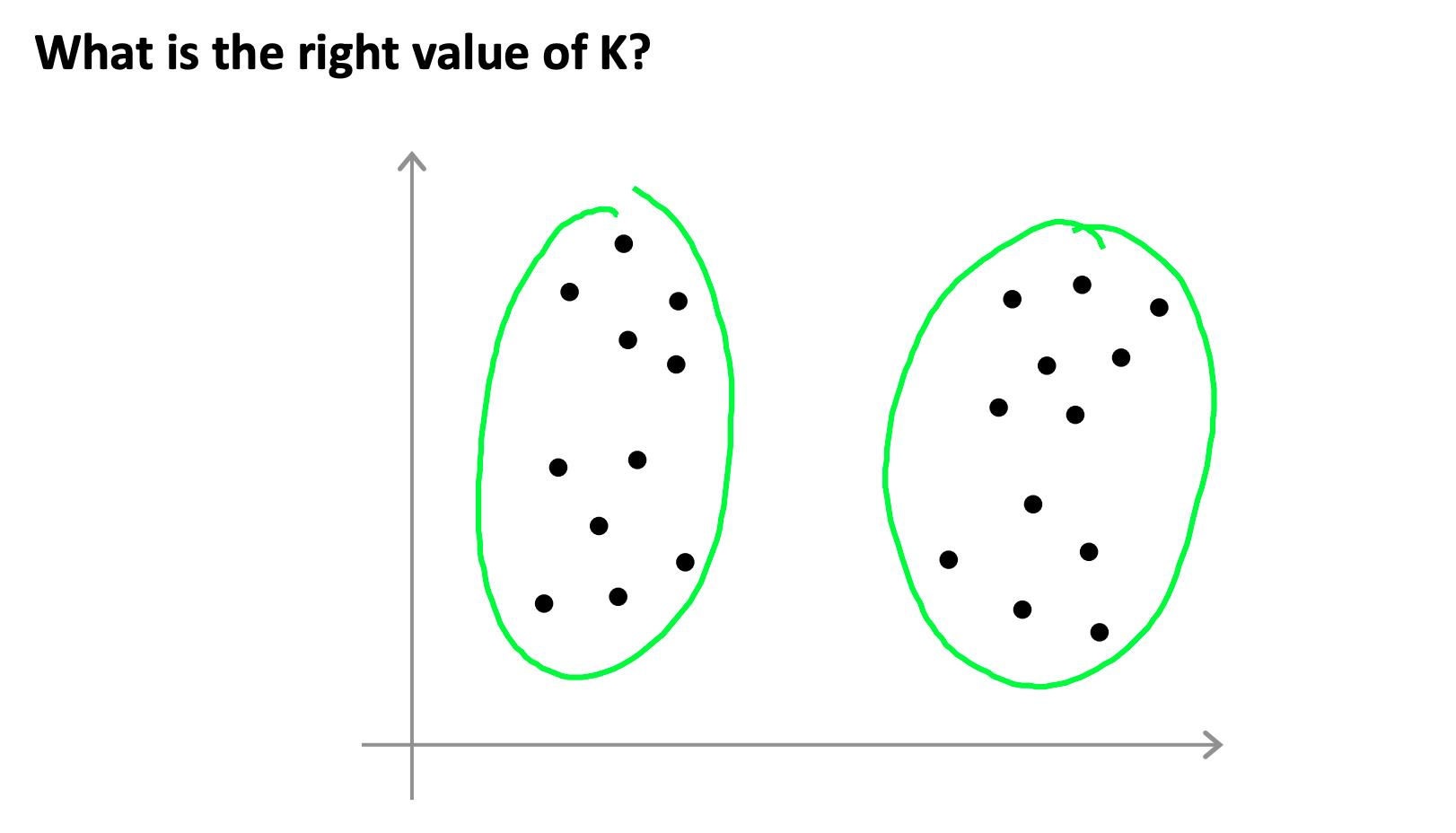
5. 选择簇数 Choosing the number of clusters
选择 K 可能非常随意和模棱两可。
肘部方法:绘制成本 J 和集群数量 K。成本函数应该随着集群数量的增加而减小,然后变平。在成本函数开始变平的点选择 K。
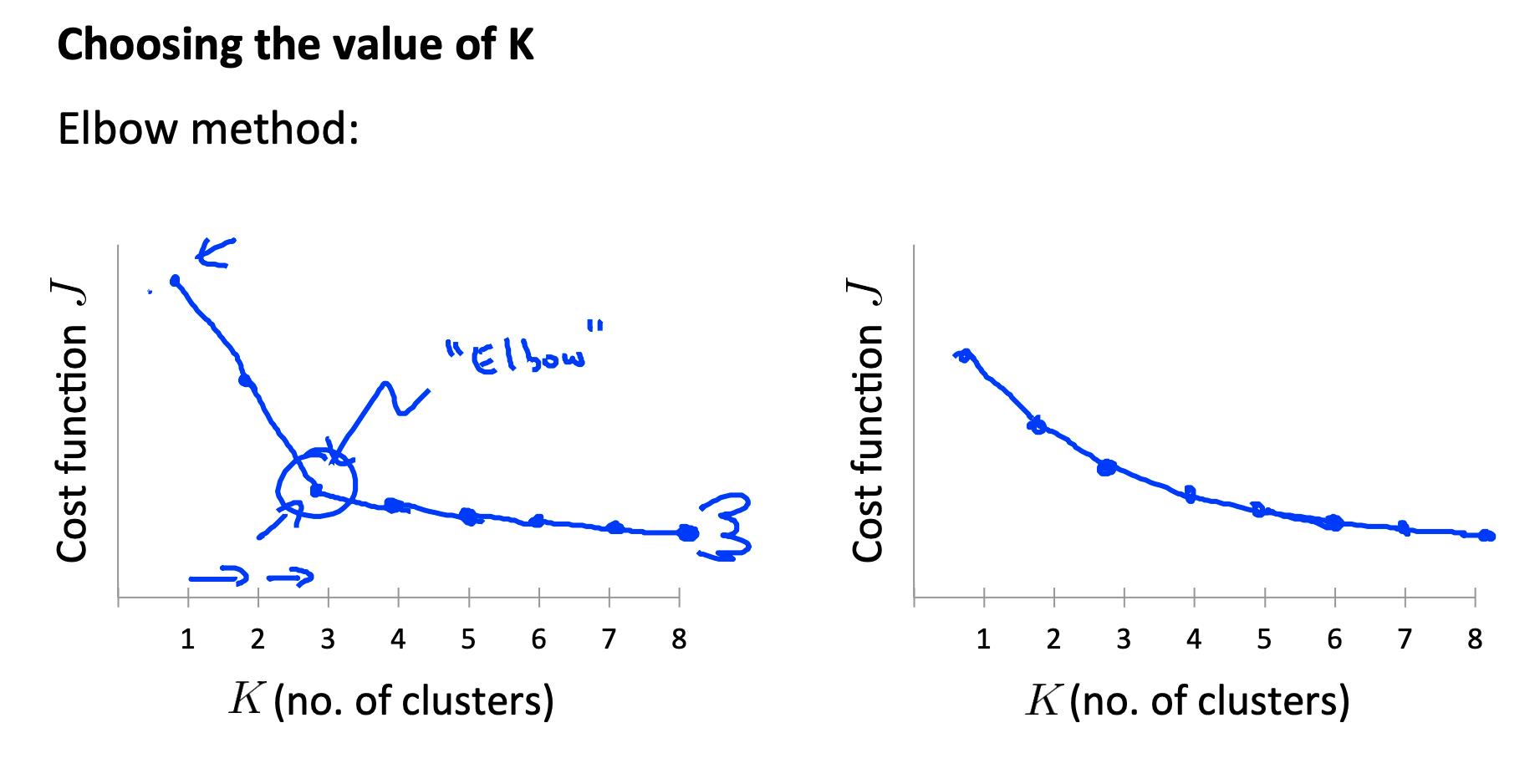
然而,很多时候,曲线是非常平缓的,所以没有明显的肘部。
注意: J总是随着 K 的增加而减少。一个例外是如果 k-means 陷入糟糕的局部最优。
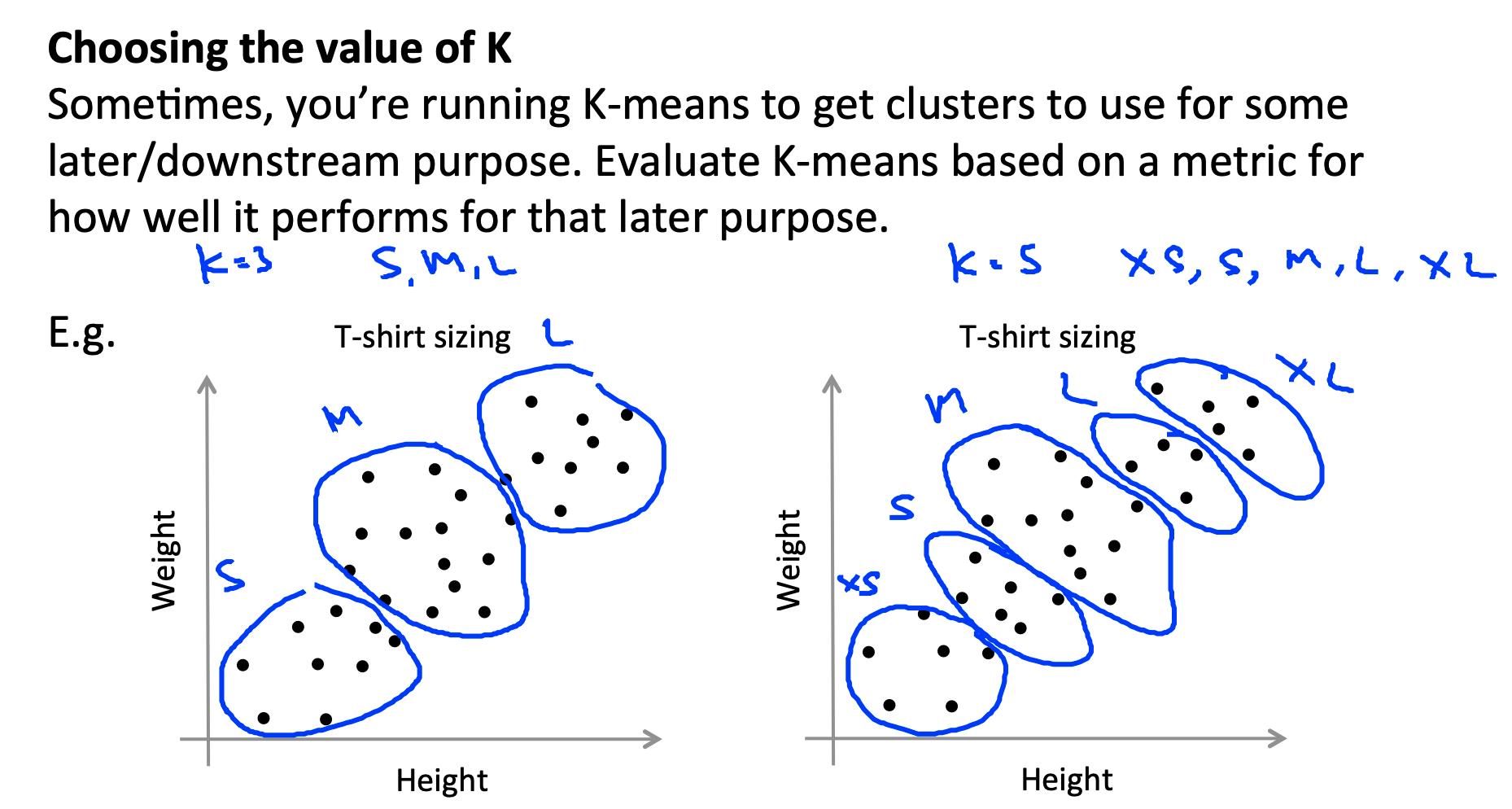
选择 K 的另一种方法是观察 k-means 在下游目的上的表现如何。换句话说,您选择的 K 被证明对您试图通过使用这些集群实现的某些目标最有用。
6. 奖励:讨论 K-Means 的缺点
这链接到一个讨论,其中显示了 K-means 给出完全正确但出乎意料的结果的各种情况:
http://stats.stackexchange.com/questions/133656/how-to-understand-the-drawbacks-of-k-means
参考
https://www.coursera.org/learn/machine-learning/resources/kGWsY
https://www.coursera.org/learn/machine-learning/supplement/hFF7A/lecture-slides
以上是关于机器学习- 吴恩达Andrew Ng Week8 知识总结 Clustering的主要内容,如果未能解决你的问题,请参考以下文章