今日笔记!——分析Java应用性能
Posted Java架构没有996
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了今日笔记!——分析Java应用性能相关的知识,希望对你有一定的参考价值。
1 问题描述
因产品架构的复杂性,可能会导致性能问题的因素有很多。根据部署架构,大致的可以分为应用端瓶颈、数据库端瓶颈、环境瓶颈三大类。可以根据瓶颈的不同部位,选择相应的跟踪工具进行跟踪分析。
应用层面瓶颈大致有如下两类,一是应用服务端复杂的逻辑处理导致应用端代码执行慢;二是资源锁争用导致线程阻塞问题(最典型的特征是线程状态为“java.lang.Thread.State: BLOCKED (on object monitor)”)等。
数据库层面瓶颈表现出来的现象都是SQL执行慢,其原因可分为两种,一是因索引缺失、SQL不规范等导致的SQL自身性能差;二是因为受环境资源瓶颈或并发资源锁等影响出现等待导致的SQL执行慢。
环境瓶颈导致的影响通常是整体性的,常见的有应用及数据库服务器的资源瓶颈(CPU、内存、IO等)、网络瓶颈等。
根据业务场景的不同特征,针对单点和并发两种场景,可以采用不同的方式进行跟踪分析。在分析单点场景性能问题时,可以通过相关agent探针追踪链路信息,进而进行进一步分析,复杂场景可以借助JProfiler、Arthas、连续多次抓取线程快照等方式进行跟踪分析。JProfiler、Arthas两个工具优点是可以直观方便的进行跟踪分析,但是性能开销较大。在并发场景,一般采用多次抓取线程及数据库会话快照的方式进行跟踪分析。
2 故障排查
2.1 整体思路
明确现象,跟踪数据,寻找瓶颈,优化瓶颈。
无论应用还是数据库,无论用各种工具分析报告还是原始的线程堆栈、会话日志的方式进行跟踪分析,其思路都是一致的,都是依据跟踪数据,明确热点内容,分析性能瓶颈。根据跟踪的数据分析线程或DB会话状态、执行的线程堆栈、SQL内容等信息,明确热点内容,进而定位性能瓶颈。
2.2单点场景性能分析
单点场景性能分析,可以通过集成相关链路性能跟踪探针进行定性分析,类似插件可以跟踪请求和SQL信息,可以直观的得到瓶颈内容。有时瓶颈出现在应用服务端,但是因业务逻辑较复杂,一个请求涉及跨多个产品模块的调用,很难根据程序跟踪器的日志快速定位到准确的瓶颈点,这种场景则需要借助调试工具做进一步分析。在此,重点针对功能较完善的JProfiler工具和所有环境都适应的JDK Jcmd工具进行示例。其他工具可以根据个人喜好,参考帮助文档使用。
2.2.1 Jprofiler跟踪方案
应用层面单点性能跟踪的主要目标为应用方法级耗时分析,可针对方法消耗的CPU资源进行跟踪。具体方法为:在开始验证问题之前,先通过“StartRecording”开启跟踪,然后重现问题,操作完成后点击“StopRecording”即可完成跟踪。
Start Recording
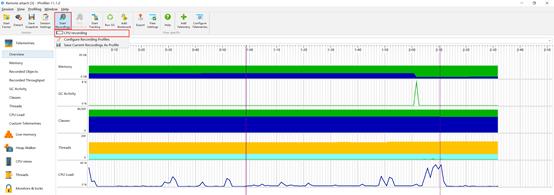
Stop Recording
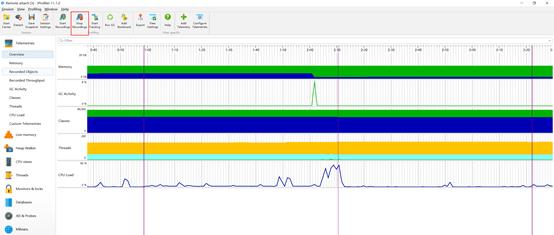
跟踪结束后,选择CPU views-Call Tree即可查看跟踪时段的方法级耗时分布情况。
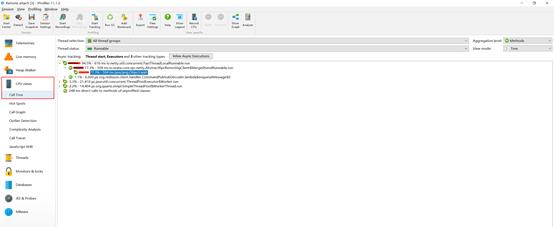
注意,因跟踪过程中会记录跟踪时段JVM所有的信息,为减少其他操作对目标场景的影响,一般建议在跟踪时尽量减少其他人员同时操作系统。如无法避免其他人员操作带来的干扰,可以通过方法名、类名等搜索过滤关键信息来快速定位。
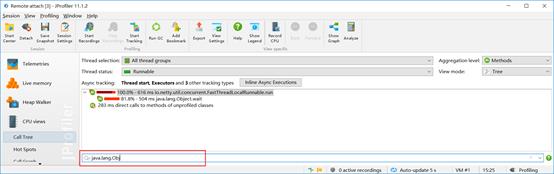
2.2.2 JDK内部工具跟踪方案
有时可能因用户管理规范等原因,项目环境无法安装JProfiler等第三方工具,我们也可以通过连续抓取线程快照的方式,在验证问题时进行高频采样,统计业务典型堆栈出现的频数,根据不同堆栈内容出现的频数比例即可大概的明确性能耗时分布情况。具体操作方式如下:
跳转到JDK的bin目录,执行如下命令开启连续打印线程快照,开启线程快照打印之后重现有问题的功能场景,功能执行结束之后,通过Ctrl+C命令终止快照打印,跟踪结束后在JDK bin目录下即会产生一个线程快照文件SingleTrace.log。
for i in {1…10000}; do ./jcmd /jstack/runtime/caf-bootstrap.jar Thread.print >> SingleTrace.log ; done;
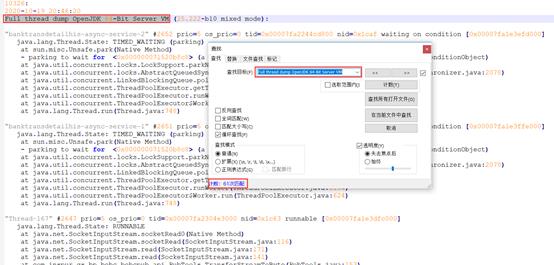
最终生成的线程快照文件通常较大,可以借助VSCode、notepad++等工具进行统计分析。文件打开之后,第一步可以先统计每个线程快照顶部的“Full thread dump OpenJDK 64-Bit Server VM”得到抓取线程快照的总次数,之后可以结合业务场景的典型方法进行统计在相关方法出现频数,根据典型场景占总次数的比例即可大概的明确对应方法在总耗时中占用的比例。
2.3 并发场景性能分析
在做并发场景性能跟踪时,为减小因抓取性能数据对系统整体带来过大的性能开销,通常以固定时间间隔(如每次间隔5s)连续多次抓取快照的方式进行收集性能数据。结合产品的实际情况,通常需要重点关注应用层面线程状态和数据库层面的会话状态两类信息。因此,在跟踪过程中通常采用应用线程快照+数据库会话快照相结合的方式进行跟踪。分析时可用结合问题时段的线程状态、堆栈信息、数据库会话状态情况定位性能瓶颈。一般来说,线程状态为RUNNABLE状态,在同一份线程快照出现频率高、或者不同快照中出现频率高的线程一般为性能瓶颈内容。
【获取资料】
2.3.1 应用层跟踪方案
收集线程堆栈快照的命令:jcmd PID Thread.print >>tracelog.log。
为了操作方便,整理了批量脚本,按照如下步骤操作即可收集内存及线程信息,在分析线程问题时,只关注线程堆栈相关内容即可。
① 将troubleshooting.sh文件放到JDK的bin目录下,具体路径为*/jstack/runtime/java/x86_64-linux/bin
②将troubleshooting.sh授予可执行权限:chmod +x troubleshooting.sh
③运行troubleshooting.sh抓取堆栈信息:./troubleshooting.sh 。执行后在jdk bin目录下会产生一个命名为trace.log的日志文件,trace.log默认只保存最近一次抓取的日志内容。
④通过 sz trace.log命令或其他文件传输工具将日志文件下载到本地查看即可。
2.3.2 数据库会话跟踪
DBSQLMonitor工具(http://gsk.inspur.com/File/t-7237)可以自动定期记录数据库会话信息,工具支持跟踪所有会话和仅阻塞两种模式。在大量复杂的DB阻塞场景,仅阻塞模式生成的日志可以快速的定位阻塞源;所有会话模式生成的日志更并发场景分析SQL瓶颈。
工具部署。将工具部署于任一能连接数据库的机器,使用具有管理员权限的用户登录工具,根据分析场景的需要,将跟踪方式设置为所有会话或仅阻塞模式,并设置记录会话快照的时间间隔。在并发性能分析时,为能够更准确的记录真实的环境信息,通常将时间间隔设置为工具允许的最小时间间隔3s。
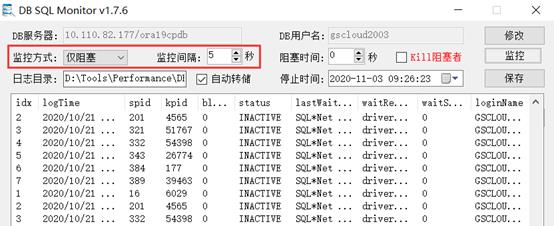
日志分析。跟踪结束后,在分析并发场景SQL性能时,可以直接筛选活动状态(非sleeping、Inactive)的会话,结合会话状态、等待事件、会话内容等信息确定数据库层面性能情况。
日志说明。Idx表示一次会话快照中的日志编号;logTime为时间戳,相同时间戳的多条记录表示在时间戳时刻的多个会话; spid为sessionID;blocked为阻塞当前会话的sessionID,该字段内容对应spid,blocked为0的表示没有被阻塞;status为当前会话状态;lastWaittype为会话等待事件;programName为当前连接对应的进程名称,GSCloud对应的进程名为JDBC Thin Client;sqlText为当前会话正在执行的SQL脚本。

2.3.3 典型场景分析思路
并发场景性能瓶颈大致可以分为如下几种情况:
(1)应用自身代码逻辑执行慢
应用层面代码执行慢的问题,表现到线程跟踪日志上就是某个活动状态的线程在某个方法执行的时间很长。如JProfiler日志中某方法耗时很长、同一个快照有多个线程在执行相同内容或连续多个线程快照均在执行某方法等。明确瓶颈方法后,分析栈顶或Jprofiler中top耗时的最叶子节点即可。
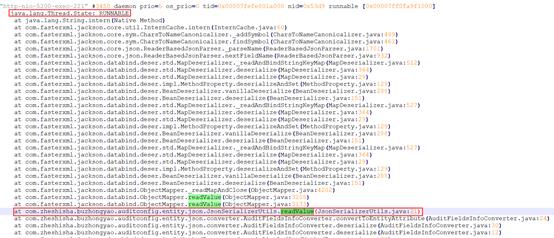
典型特征:线程状态为RUNNABLE状态,且栈顶为非等待类型堆栈。
如下示例中,多次抓取线程快照,线程状态一直保持RUNNABLE,产品线程栈顶均为XXX.readValue(),且栈顶代码没有出现等待。因此,我们可以得出,XXX.readValue()是由于String.intern()导致。
(2)非应用自身逻辑导致的等待
有时还会出现因应用以下层面资源导致的性能瓶颈,如SQL效率低导致应用长时间等待数据库返回数据、应用与数据库之间网络环境不佳导致接收数据库返回的结果集时耗时过长等。
①数据库SQL执行慢
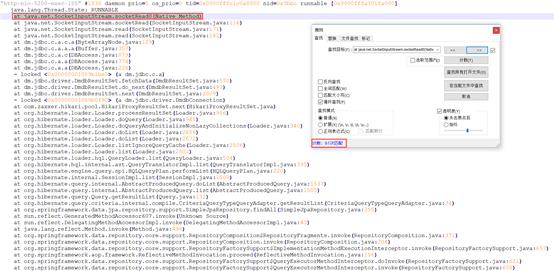
当发现大量活动线程在等待数据库返回时,则需要进一步结合数据库session日志做进一步分析。以如下示例为例,当前时刻的线程快照中有61个线程在等待网络返回,此时可以检查相关时段活动状态的会话情况,假如线程快照前后的数据库会话中活动会话数与等待网络返回的数目接近,则基本可以确定应用层面的等待是由于SQL性能差导致。【获取资料】
典型特征:线程状态为RUNNABLE,且栈顶在存在网络相关等待,且数据库会话中存在大量活动状态会话。
②网络等环境因素导致等待
有时还会有另一种场景,线程快照中存在大量等待网络返回的活动线程,但是数据库层面并没有与之对应的出现大量活动状态的会话,这种情况可能是如栈顶代码所示,应用和数据库服务器之间真正的出现了网络瓶颈。
典型特征:线程状态为`RUNNABLE`,且栈顶在存在网络相关等待,且数据库会话中没有货只有个别零散的活动状态会话(个别是指一次出现的活动会话数很少;零散是指活动会话出现的频率低,间隔很长时间出现一次)。
Linux环境还可以使用iftop工具进行网络情况监控。
(3)应用层面出现并发等待(线程阻塞)
在并发场景,有时候会出现因为资源锁导致的等待问题,线程阻塞问题涉及两种状态的内容,一是阻塞源线程,阻塞源线程状态为RUNNABLE状态,此类线程通常是由于自身或某些外部因素导致的线程执行慢,进而导致申请的资源锁未能及时释放;二是被阻塞的线程,此类线程均为BLOCKED状态,且等待的多为同一个资源。
以如下被阻塞的线程为例,当前线程在执行_addSymbol()方法时,对lock <0x00000004d23c52c0>加锁失败导致出现等待,进而该线程处于被阻塞状态。一般来说,相同方法申请同一个资源的概率相对更大,因此,我们可以用等待加锁的方法作为关键词,搜索存在相关关键词的非BLOCKED状态线程大概率即为阻塞源线程,最终发现该线程阻塞是由于场景(1)中XXX.readValue()方法的String.intern()导致。【获取资料】
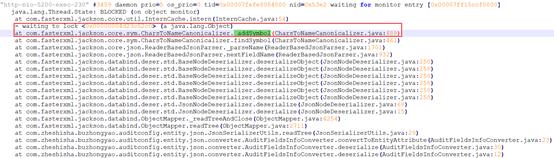
典型特征:线程状态为BLOCKED
3 解决方案
根据分析结论,优化瓶颈内容。
最后,祝大家早日学有所成,拿到满意offer,快速升职加薪,走上人生巅峰。
可以的话请给我一个三连支持一下我哟???【获取资料】

以上是关于今日笔记!——分析Java应用性能的主要内容,如果未能解决你的问题,请参考以下文章