模式识别期末考试名词解释总结
Posted 栀染
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了模式识别期末考试名词解释总结相关的知识,希望对你有一定的参考价值。
模式识别名词解释汇总
1、机器学习
计算机从数据中学习出规律和模式,以应用在新数据上做预测的任务。
2、过拟合
学习器把训练样本自身的一些特点当作了所有潜在样本都会具有的一般性质,所导致的泛化性能下降。
3、欠拟合
对训练样本的一般性质尚未学好,模型不能在训练集上获得足够低的误差。
4、K折交叉验证
先将数据集D划分为k个大小相似的互斥子集,从D中通过分层采样得到子集,每个子集都尽可能保持数据分布的一致性,每次k-1个子集的并集作为训练集,余下的那个子集作为测试集,从而获得k组训练/测试集,从而进行k次训练和测试,最终返回的是这k个测试结果的均值。
5、查准率
预测为正例样本中真实类别为正例的比例。
查准率等于真正例除以真正例和假正例的和,
公式如下:
P=TP/(TP+FP)
6、查全率
真实类别为正例的样本预测为正例的比例。
查全率等于真正例除以真正例和假反例的和,
公式如下:
R=TP/(TP+FN)
7、PR曲线平衡点
简称BEP,是“查准率=查全率”时的取值,即2乘以查全率乘以查准率除以查全率和查准率的和,
公式如下:
F1=2PR/(P+R)
8、假正例率
预测为正例并且预测错了的数量占真实类别为反例样本的比例。
简称FPR,假正例率等于假正例除以真反例与假正例的和,
公式如下:
FPR=FP/(TN+FP)
9、真正例率
预测为正例并且预测正确的数量占真实类别为正例样本的比例。
简称TPR,真正例率等于真正例除以真正例与假反例的和,
公式如下:
TPR=TP/(TP+FN)
10、AUC
ROC 曲线与横轴所围成的面积。
(AUC 越大,模型的分类性能就越高)。
11、凸函数
对于一元函数 f(x),
如果对于任意 tϵ[0,1]均满足 f(tx1+(1−t)x2)≤tf(x1)+(1−t)f(x2)。则f(x)为凸函数。
12、梯度
一个函数的全部偏导数构成的向量。
13、信息增益
在划分数据集之前之后信息发生的变化。
信息增益在决策树算法中是用来选择特征的指标,信息增益越大,则这个特征的选择性越好,在概率中定义为:待分类的集合的熵和选定某个特征的条件熵之差。
公式如下:
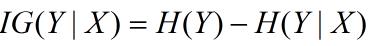
14、基尼指数
表示在样本集合中一个随机选中的样本被分错的概率。
( 注意: Gini指数越小表示集合中被选中的样本被分错的概率越小,也就是说集合的纯度越高,反之,集合越不纯。)
15、预剪枝
在决策树生成过程中,对每个节点在划分先进行估计,若当前结点的划分不能带来决策树泛化能力提升,则停止划分合并将当前结点标记为叶结点。
16、后剪枝
先从训练集生成一颗完整的决策树,然后自底向上地对非叶结点进行考察,若将该结点对应的子树替换为叶结点能带来决策树泛化性能提升,则将该子树替换为叶结点。
17、神经网络
由适应性的简单单元组成的广泛并行互连的网络。他的组织能够模拟生物
神经系统对真实世界物体所作出的交互反应。
18、one-hot编码
One-Hot 编码又称为一位有效编码,主要是采用 N 位状态寄存器来对N 个状态进行编码,每个状态都由他独立的寄存器位,并且在任意时候只有一位有效。
19、间隔
两个异类支持向量到超平面的距离之和。
20、支持向量
距离超平面最近的样本点。
21、聚类
将样本集划分为若干互不相交的子集,即样本簇。
22、降维
通过某种数学变换将原始高位属性空间转变为一个低维“子空间”,在这个子空间中样本密度大幅提高,距离计算也变得更为容易。
23、留一法
n 折交叉验证(n 是数据集中样本的数目)被称为留一法(Leave-One Out),即每次用一个样本做验证集,其余的样本做训练集
以上是关于模式识别期末考试名词解释总结的主要内容,如果未能解决你的问题,请参考以下文章