视频质量评价:挑战与机遇
Posted LiveVideoStack_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了视频质量评价:挑战与机遇相关的知识,希望对你有一定的参考价值。
 正文字数:5168 阅读时长:10分钟
正文字数:5168 阅读时长:10分钟
本文整理自鹏城实验室助理研究员王海强在LiveVideoStack线上分享上的演讲。他通过自身的实践经验,详细讲解了视频质量评价的挑战与机遇。
文 / 王海强
整理 / LiveVideoStack
大家晚上好,感谢参加今晚的分享。我叫王海强,来自鹏城实验室。今天我分享的题目是“视频质量评价的挑战与机遇”。这是今天要分享的内容。
首先,我会简单介绍一下什么是视频质量评价及它的分类。第二部分,我会结合实际业务介绍一下视频质量评价在业务链路中到底有什么作用。接下来会简单介绍一下目前视频质量评价在业界应用的现状、挑战与机遇。第四部分将会介绍一个我们之前所开发的基于深度学习的视频质量评价算法。然后,我会宣传一下在ICME 2021正在举办的质量评价竞赛。最后是QA环节。
01
—
视频质量评价简介
第一部分是视频质量评价的简介。什么是视频质量评价呢?因为大部分视频业务是以服务于用户为目的,以人眼观看、最终体验为基准。视频质量评价致力于衡量视频的人眼感知质量。

上图用JPEG压缩图像给出一个例子。最左边图像是无损的,所以它的分数是1.0最高分。最右边图像是JPEG压缩质量最差的,它的分数非常低,接近最低分0。而中间三个图像的码率是逐渐降低的,质量是在逐渐变化的,相应的分数也在逐渐降低。而质量评价的目的就是,对于一个图像或视频,我们希望能够给出这样一个分数作为参考,再以这个分数为前提去优化系统或者做监控。

这里给出一个H.264压缩视频作为例子。因为线上分享播放视频不是很方便,所以我在这里只给出一个视频作为例子,其他地方我都是给出图片例子,但背后的概念都是相通的。
这个是无损的视频,它的分数为5分,最高分。然后是4分,也是质量非常好的状态。然后是3分,在脸部已经可以看到一些block了。而2分的质量就已经很模糊了。最后是相当差的质量,我觉得可能没有人愿意为这种服务而付钱吧。
总体来说,视频质量评价可以从下面几个方向来分类。
1.1 视频质量评价方法分类
第一个就是根据视频质量评价的方法来分类。

主观质量评估
如果我们让人去观看,并让人去打分,这叫作主观质量评估,即依赖人眼观看并给出打分。这是一个费时费力,而且对环境要求非常严格的过程。但是它得到的分数是比较可依赖的,我们经常用这个分数来衡量客观质量评估算法。
这里的客观质量评估算法就是,我不可能将所有视频、所有场景都找人来观看,我想要一个算法可以自动计算出这个视频的质量分数。
而衡量一个算法好坏,就是看一下客观分数与主观分数的逼近程度。一个好的算法会给出一个接近于主观分数的估计。
客观质量评价
具体到客观质量评估,根据使用多少源视频的信息,它可以分为三个大类。
第一类是全参考。当我们衡量损伤视频的时候,无损的源视频是可用的,我们就可以通过对比两个视频的方式作出评价。第二类是无参考。源视频的任何信息都没有,我们只使用损伤视频的信息来衡量其质量。第三类是不太常见的,即部分参考。没有像素级的源视频,只从源视频里提取很少量信息,再用这些信息加上损伤视频来作估计。
1.2 视频质量评价内容分类

传统的视频质量评价都是对于PGC(Professional Generated Contents),叫作专业制作内容,如传统VoD、家里看的电视或电影,它们都是由专业人员拍摄,它们的构图、环境、灯光等各方面都比较好。这种情况下,我们假设它们的无损源视频就有完美的质量,我们比较难去进一步增强它们的质量。近年来,用户原创视频UGC(User Generated Contents)开始兴起,比如手机上看的短视频、直播场景、实时会议场景。一方面,因为这种视频发出去的源已经经过压缩了,所以它并没有完美的质量,例如实时视频通话就有视频的损伤。另外一方面,我们作为普通用户,视频构图不好,拍摄有抖动,光照也不好,有些人还会后期处理加滤镜,看起来好看一些,导致视频经受多层损伤处理。
总体来说,以评价内容来分,视频可以分为PGC和UGC的视频内容,PGC是传统的研究领域,UGC是近几年兴起的领域。
02
—
质量评价在视频业务链路中的作用
下面我就结合具体的业务线来介绍质量评价能起到什么作用。
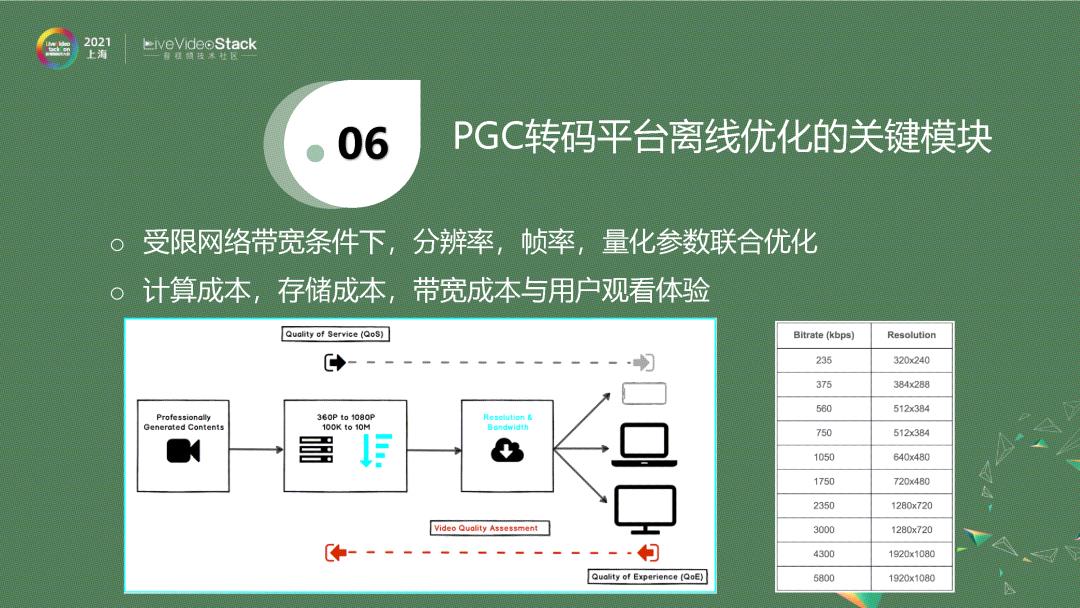
上图是一个简化版的PGC转码平台示意图。对于系统来说,拿到一个原始的、无损的、高分辨率、高帧率的源,一般将其采样成不同的分辨率,每一个分辨率会压缩成特定的码率,这样经过CDN,根据用户端可用带宽,自动选择一个码率,然后分发给用户。
图中右边是给出一个码表,它来自Netflix 2015年的技术帖子,即把一个视频压缩到对应的分辨率后,它的码率就是固定的。当你的可用带宽是200k~6Mb,每个码率点分发的视频分辨率也是固定的,这就是固定码表。这样一个系统是单向的,它根据用户的可用带宽,决定分发什么,而没有考虑到视频的差异性。譬如我刚才播放的视频,需要的码率要高一点。现在一个静止页面,需要的码率低一点。这种固定码给的形式完全忽略了视频本身的特性,没有一个从用户端去feedback的过程。就是说,在受限带宽下,是动态调整分辨率,还是调整帧率,还是调整具体的量化参数,我们需要一个更好的策略来达到我的目标的码率。

然后,对于UGC来说,它的播放量有一个长尾效应,也叫作马太效应、二八效应。它大概类似于一个恐龙的形状,播放量和点击量最高的视频永远只有一小部分,后面有一个比较长的尾巴,这代表了有相当一部分视频其实是没有什么人去看的。如果统计一下,你就会发现,播放量最高的视频永远是内容、质量比较好,比较有趣,画面比较清晰等类似特性。而尾部视频要么拍摄得不好,要么画面很渣,要么趣味性不够。
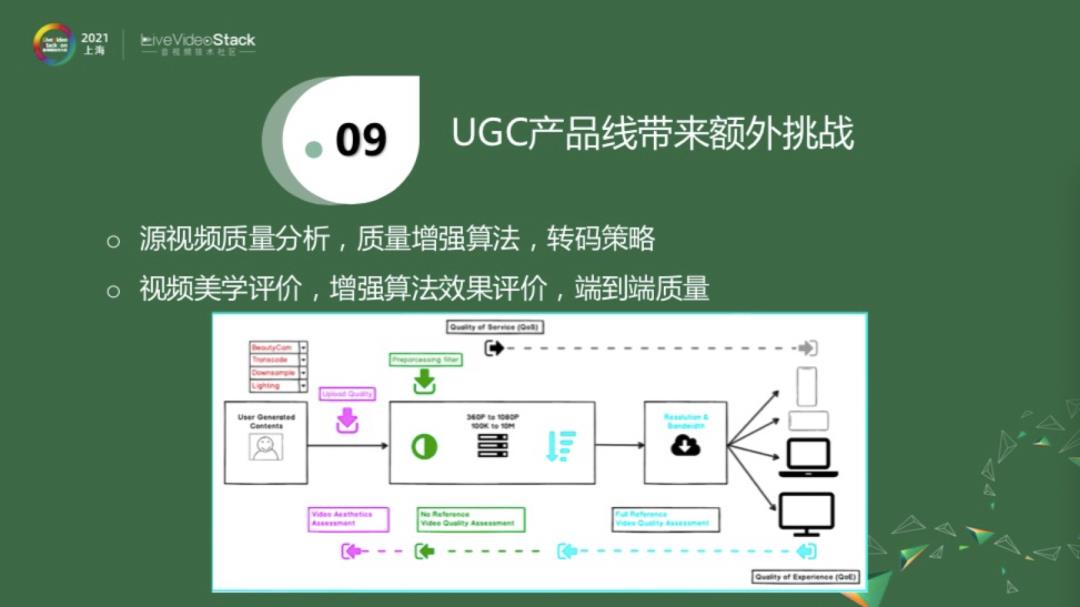
对于UGC视频来说,除了上面介绍的PGC转码平台,即得到一个上传的源进行降分辨率、降帧率的分发之外,还有一些额外的工作可以做。譬如说这是一个UP主或者用户上传的短视频,它可能经过了美颜相机处理。而且目前我们的手机是不支持无损拍摄的,手机自己会压缩一下,否则流量是非常可观的,而且手机会做一些其他的调整。这时候上传的视频质量已经不是无损的。我们在这里需要一个算法来衡量一下,用户上传的视频是不是很好的质量,它是属于头部、中部,还是尾部。如果检测到它是属于头部,那它的推送量就更高一些。如果它是属于脖子这一块,即不是最优质的视频,我们是否可以用一些方法将其增强一下,尽量把它变成头部视频。我可以选择性地加入一些处理手段,来进一步增强它的质量。实际情况往往没那么简单,我们也需要确认一下,这里是不是已经增强了它的质量。处理之后,后面就是一个类似PGC的转码平台。以上的讨论是对于单个模块的。如果我们把这一切串联起来,就是从用户上传到用户接收,当整个系统串联起来的时候,这就是一个比较大的视频质量评价范畴。因为对某一部分,我们有比较好的估计,那串联起来的情况,就可能变得复杂很多了。
03
—
质量评价在业界的挑战与机遇

目前来说,视频质量评价在业界经历了十几年的发展,但以我的了解,其实视频质量评价在业界用的还不是特别多。原因也是很客观的,有如下四点。第一是算力成本,因为视频质量评价从技术上来说还是相对比较难的问题。比如会议场景,发送端经过腾讯会议后台转码,然后分发到对面的接收端,我想衡量一下接收的视频质量是否还好。在源端和接收端去做这件事是比较有挑战性的,因为对于用户来说,可能百分之五、百分之十的CPU消耗都是很可观的、甚至是不能接受的一个指标。那么把计算放到转码服务器上进行相对来说会好一点,但是也有一定的问题,比如隐私问题,或者是如果算法过于复杂,后台的压力问题。第二,不同的业务场景具有不同的业务核心指标。如实时会议要求时延不能太高,不能两个人说话的时候,一个人等了好几秒对面才会听到,然后才回复。第三,虽然视频质量评估在学术界汇报的结果会比较高,但真正在业务场景下,各种各样的 bad case都会出现,即如果把一个指标放在线上跑完后就会发现,剩下的工作量可能就是解决各种bad case了。
最后,综合以上,作为领导或者负责人就会衡量一个问题,这么大的投入,对系统改变这么大,这到底能带来多少收益?以上问题,导致了视频质量评价在业界的应用不是很广泛,虽然感兴趣的人有很多。

但是,对于一个视频业务,不管是PGC还是UGC,竞争是比较激烈的。虽然在目前阶段,视频以内容为王,特别是优质内容,当解决了优质内容之后,你和竞品的差异究竟在哪儿,就是你有什么杀手锏,可以让你的视频比竞品更优秀,我们相信这个答案就是极致的用户体验。目前,UGC的视频质量评价在业界的情况是,现有算法较难满足业务需要,因为准确度是很有限的。而且大部分算法是对单个失真类型,而UGC视频是串联了多个失真视频类型,这样综合下来,它的性能比较有限。另外,新的算法大都处于起步阶段,特别是基于深度学习的算法。
04
—
基于深度学习的视频质量评价算法设计
我们围绕着UGC视频质量评价,特别是无参考算法,也做了一定的探索。这一部分内容我今天先简单介绍一下,然后在4月份的分享会给出更详实的数据和更多细节。

相对于全参考视频质量算法,无参考视频质量评价面临着更多的问题。第一,无参考质量评价算法没有一个原始的无损源做参考,不能从对比的角度来评价质量,而只能从失真视频里提取有限的信息。另外,我们知道训练一个深度神经网络需要的数据量比较大,而目前的关于视频质量的数据库的量都比较小,训练起来是比较有难度的,特别是多失真的场景。
目前在学术界有一些对应的策略,针对第一个无参考源可用的问题,有些学者会使用基于多任务的学习来融合额外信息。这里我会给出一些例子。而对于人工标注数据库太小的问题,一个策略是使用与主观分数无关的额外表征来帮助网络训练。
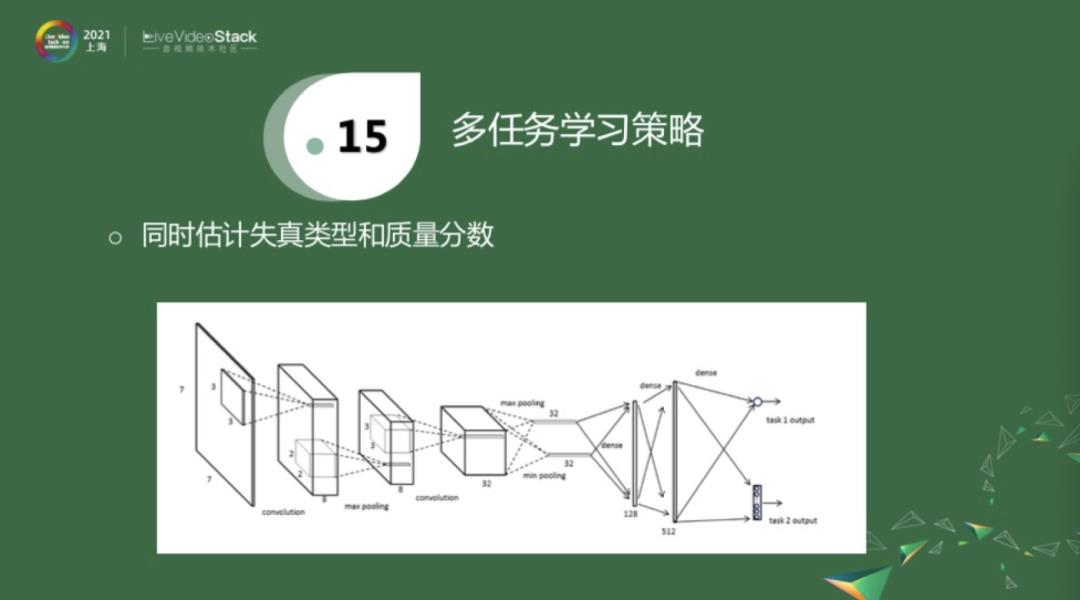
对于第一项多任务学习策略来融合额外信息,我先简单介绍一下两个工作。上图是一个很简单的神经网络,经过三层卷积层和两层全连接层之后,得到一个分数输出。同时也有另外一个输出,它是在分数估计的基础之上额外添加了一个信息,即估计失真类型。就是一方面估计失真类型,另一方面估计客观分数。因为失真类型相对来说是比较容易获得的。它的一个比较大的缺陷就是,标注的视频必须要同时知道这两个label,才能进行训练。
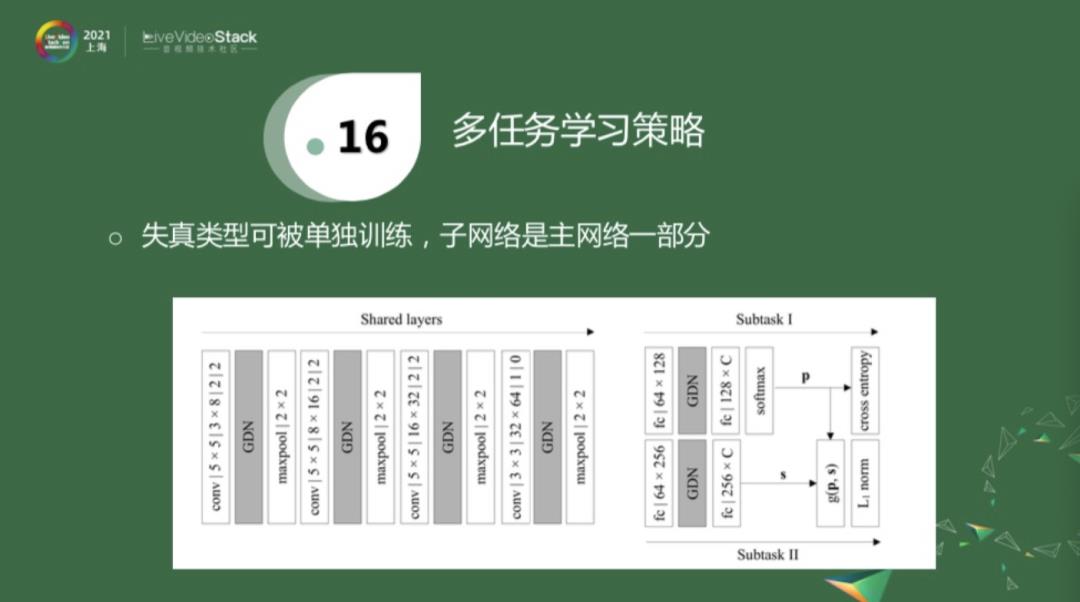
还有一个工作和上面的方法大致类似,就是在一个更复杂的网络中,前面的系数是被共享的,后面有两个subtask,一个task去估计失真类型,另外一个task去估计分数。相对于上面网络的来说,失真类型的参数可以被共享,这一块是否存在对于分数估计子任务来说是没有影响的,即上面的网络是下面的一部分。这样就有一个好处,当一些视频没有分数标记的时候,我们可以对源视频进行压缩,只使用失真类型去预训练这个网络。当经过预训练之后,在同时有两种label的数据库中,再去fine-tune。即先人工生成一些只包含失真类型去预训练这个分支,再用同时包含两种label的数据库去做进一步的训练。这是对上面策略的一个改进,即使用多任务策略来引入额外信息,以帮助网络训练。
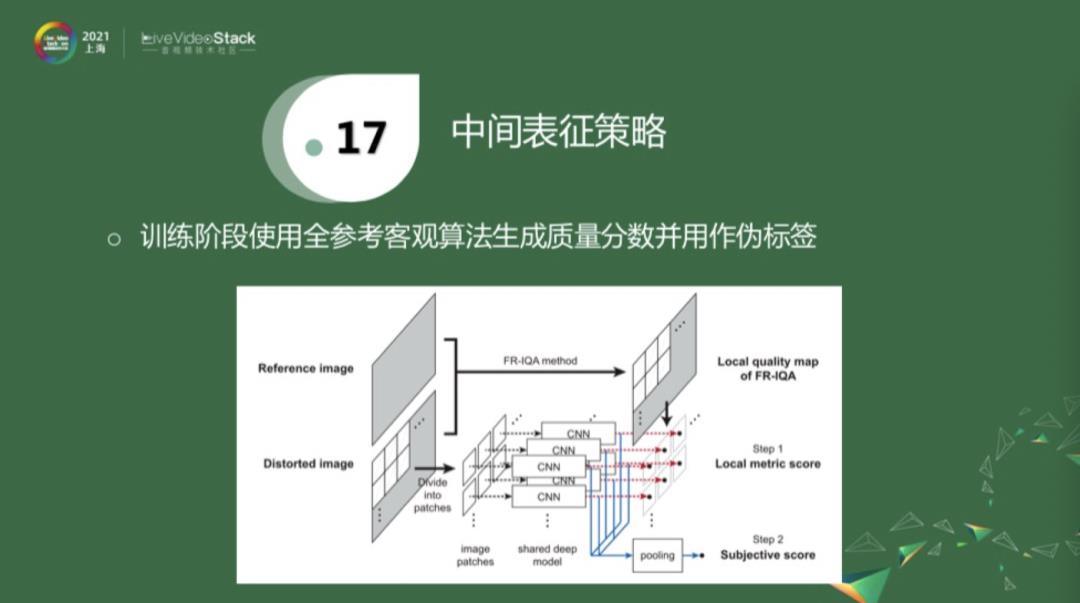
中间表征策略,是最近几年的工作。对于一个失真图像和参考图像,它们没有标注,就用一些性能比较好的全参考算法去算出伪标签,再用伪标签去训练网络。训练阶段应该对应于红线,用得着这些伪标签。在inference阶段,直接从失真图像拿出patch,经过下面的蓝线给出估计,再把它们pull到一块,得到分数估计。这就是利用伪标签作为中间表征。
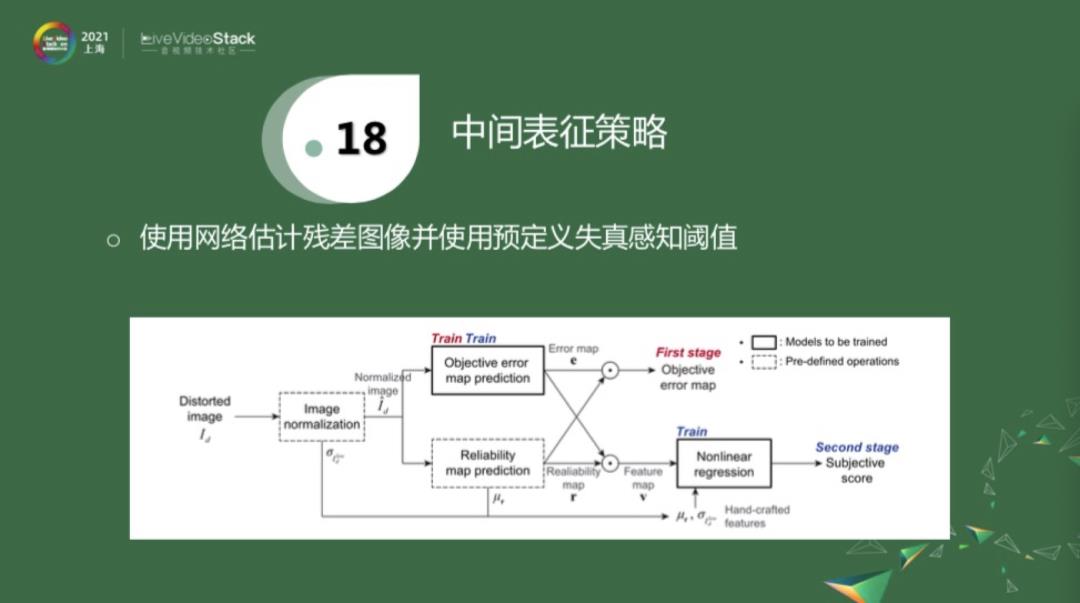
还有一种中间表征策略就是用残差图像。残差图像就是原始图像和失真图像的一个差值,专业术语是residual。给我一个失真图像,这个分支的学习对象是这个残差图像。如果有失真图像所对应的参考图像的话,做一个简单的减法,就可以得到label,再用这个label去训练这些网络。这个算法,要提前定义一些失真感知阈值,一旦学到残差帧之后,就把两个值乘起来,做进一步的分数估计。
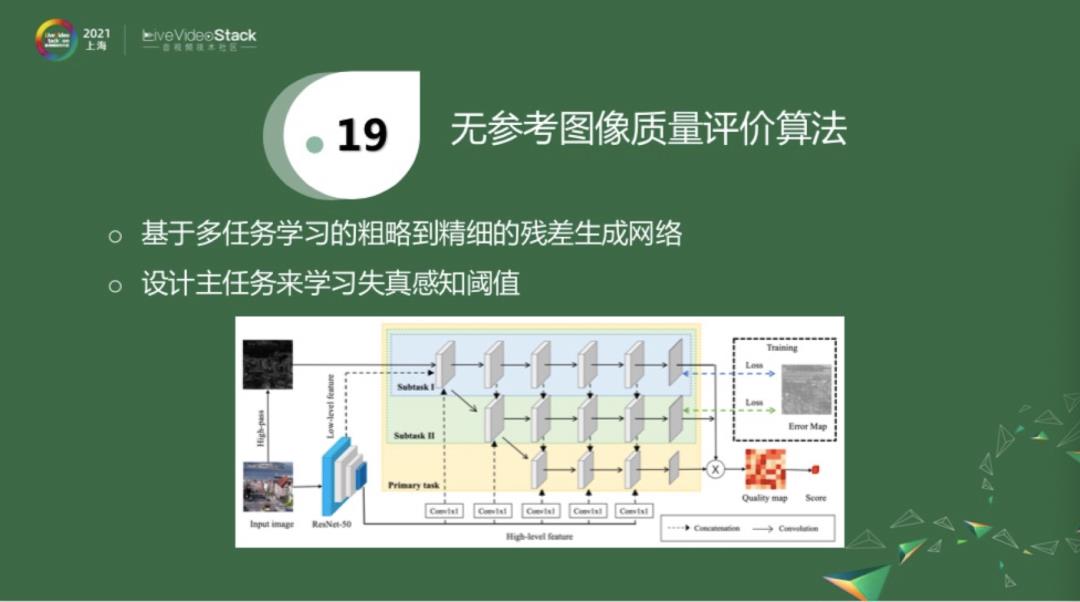
我们最近也围绕这个方向做了一些探索,我们的方法是融合了以上两种策略。第一种策略是,也使用中间表征这个残差帧来作为初步的学习对象。相对于上面的改进就是,我们失真感知阈值是经网络学习得到的,如上图有三个subtask。Subtask1学习一个粗略的残差帧。Subtask2学习更精细的残差帧。主任务会学习失真感知阈值。三个网络训练完后,就可以把失真感知阈值和残差帧乘起来,做进一步的质量评估。关于这个算法,今天先简单分享这些,我们在4月份会介绍更多内容。
05
—
ICME 2021质量评价竞赛
最后,我想分享一个信息,ICME 2021举办了一个质量评价竞赛。

这个竞赛的初衷是,结合目前学术界的研究热点和业界痛点,以推动UGC视频质量评价在学术界和业界的进展。为了这个目的,我们自己构建了一个大规模数据集,其中用于训练的数据集是对外公开的,我们保留了一部分测试集。作为比赛的主办方,我们在比赛结束之前会提供相对客观、独立的性能验证结果,作为评测标准。它包含了两个track,因为是UGC视频。其中一个是MOS track,就是估计每一个视频的绝对质量,这里包含用户上传的非完美的视频,也包含对其做压缩所得到的失真视频。另一个是DMOS track,类似于传统的PGC视频,去估计源视频经压缩之后的质量变化。

上图给出了大会的网址,搜索icme challenge就可以搜索到。具体的竞赛网址是由ugcvqa给出。下面是具体比赛的timeline。目前已经是3月,模型提交时间是4月底,大概还是一个月的时间。最后在5月底,我们会给出提交的模型在非公开的测试集上验证的结果,大家可以将其作为某种参考。如果感兴趣的话,欢迎参加,或者讨论。

最后是今天所用的一些参考文献。
这是我今天所分享的内容,谢谢大家。


详情请扫描图中二维码或点击阅读原文了解大会更多信息。
以上是关于视频质量评价:挑战与机遇的主要内容,如果未能解决你的问题,请参考以下文章