金融应用场景下跨数据中心的MGR架构方案
Posted 老叶茶馆_
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了金融应用场景下跨数据中心的MGR架构方案相关的知识,希望对你有一定的参考价值。
本文来源:原创投稿
* GreatSQL社区原创内容未经授权不得随意使用,转载请联系小编并注明来源。
0. 内容提纲
1. 运行环境
2. 部署MGR A&B
3. 部署MGR A、B之间的复制通道
4. 几个注意事项
如何在多个数据中心部署多套mysql MGR集群以便快速切换。
在金融应用场景下,经常会要求在同城多中心部署高可用数据库架构,以期实现在发生故障时能达到快速切换的目标。
在同一个数据中心内,可以部署MGR集群,就可以实现快速灵活切换。
而即便是在同城,跨数据中心时,网络条件好的话,延迟可能也在 1ms 之内。这种网络条件下,如果要在同城多中心部署MGR集群也是可以尝试的(如果业务并发量不是特别高的话),但考虑到多数据中心间有较大概率会出现光缆被挖断等风险,所以还是不建议这么做。
因此,最好还是在同一个数据中心内部署一套独立的MGR集群,再通过主从复制(replication)方式(可以是异步复制或半同步复制),把数据复制一份到另一个数据中心内的MGR集群里,这样一旦主机房出现异常时,就可以快速切换到备用机房了,并且不担心数据库的高可用保障等级。
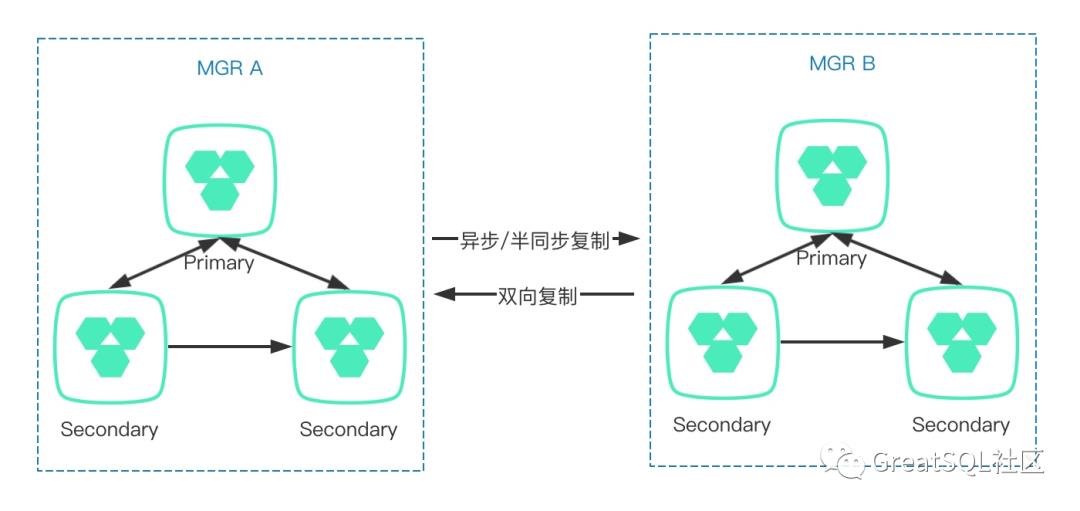
上面该方案的架构示意图。
接下来一起来完成这个架构方案的实施。
1. 运行环境
本次采用3个节点部署这套架构,各节点用途说明见下
| 节点 | IP | 用途 |
|---|---|---|
| Node1 | 172.16.16.10 | MGR A & B 主节点(分配不同端口,多实例方式,下同) |
| Node2 | 172.16.16.11 | MGR A & B 从节点 |
| Node3 | 172.16.16.12 | MGR A & B 从节点 |
每个节点上都运行两个实例,分别是3306、4306端口,其中3306端口的实例构成MGR A集群,4306端口的实例构成MGR B集群。
除了MySQL官方社区版本外,如果想体验更可靠、稳定、高效的MGR,推荐使用GreatSQL版本。本文采用GreatSQL 8.0.22版本,关于这个版本的说明详见 GreatSQL,打造更好的MGR生态。
2. 部署MGR A&B
按照常规方式部署MGR即可,下面是一份关键配置参考:
group_replication_single_primary_mode=ON
log_error_verbosity=3
group_replication_bootstrap_group=OFF
group_replication_transaction_size_limit=<默认值150MB,但建议调低在20MB以内,不要使用大事务>
group_replication_communication_max_message_size=10M
group_replication_flow_control_mode=“DISABLED” #官方版本的流控机制不太合理,其实可以考虑关闭
group_replication_exit_state_action=READ_ONLY
group_replication_member_expel_timeout=5 #如果网络环境不好,可以适当调高
slave_parallel_type=LOGICAL_CLOCK
slave_parallel_workers=128 #可以设置为逻辑CPU数量的2-4倍
binlog_transaction_dependency_tracking=writeset
transaction_write_set_extraction=XXHASH64
slave_checkpoint_period=2
更多关于MGR以及复制的配置参考这份指南:MGR最佳实践。
启动MGR A,确认工作正常:
[root@GreatSQL mgrA-1][(none)]> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 5499a6cb-91cb-11eb-966f-525400e802e2 | mgrA-1 | 3306 | ONLINE | PRIMARY | 8.0.22 |
| group_replication_applier | ec2fcbeb-976c-11eb-a652-525400e2078a | mgrA-2 | 3306 | ONLINE | SECONDARY | 8.0.22 |
| group_replication_applier | edfbdeda-91c8-11eb-a3c6-525400fb993a | mgrA-3 | 3306 | ONLINE | SECONDARY | 8.0.22 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
[root@GreatSQL mgrA-1][(none)]> select @@global.group_replication_group_name;
+---------------------------------------+
| @@global.group_replication_group_name |
+---------------------------------------+
| f195537d-19ac-11eb-b29f-5254002eb6d6 |
+---------------------------------------+
用同样的方法,再部署MGR B,并确认工作正常:
[root@GreatSQL mgrB-1][(none)]> select * from performance_schema.replication_group_members;
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| CHANNEL_NAME | MEMBER_ID | MEMBER_HOST | MEMBER_PORT | MEMBER_STATE | MEMBER_ROLE | MEMBER_VERSION |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
| group_replication_applier | 31f7accc-96ac-11eb-92f8-525400e802e2 | mgrB-1 | 4306 | ONLINE | PRIMARY | 8.0.22 |
| group_replication_applier | b084f8a1-96a8-11eb-9a70-525400fb993a | mgrB-2 | 4306 | ONLINE | SECONDARY | 8.0.22 |
| group_replication_applier | ed57ca6b-96a9-11eb-be28-525400e2078a | mgrB-3 | 4306 | ONLINE | SECONDARY | 8.0.22 |
+---------------------------+--------------------------------------+-------------+-------------+--------------+-------------+----------------+
[root@GreatSQL mgrB-1][(none)]> select @@global.group_replication_group_name;
+---------------------------------------+
| @@global.group_replication_group_name |
+---------------------------------------+
| 476c0276-be03-11eb-bd34-525400e802e2 |
+---------------------------------------+
确认上述2个MGR集群以及各个节点的 server_uuid 都不一样。
3. 部署MGR A、B之间的复制通道
从MySQL 5.7开始,支持多源复制(Multi-Source Replication),因此我们可以很方便的利用多源复制,在两个MGR集群之间再构建一个复制通道。
这个复制通道,既可以选择 异步复制(Asynchronous Replication),也可以选择 半同步复制(Semisynchronous Replication),可以根据两个MGR集群之间的网络状况,以及实际业务需要评估决定。
本案选择半同步复制方案,这仅限于实验目的,不表示我们推荐大家也采用半同步方案。
相应地,下面也是一份半同步的参考配置,大家可根据实际情况适当调整:
rpl_semi_sync_master_timeout=2592000000
rpl_semi_sync_master_wait_for_slave_count=1
rpl_semi_sync_master_wait_point=AFTER_SYNC
在MGR B的Pirmary节点上创建半同步复制通道(记得设置通道名):
[root@GreatSQL mgrB-1][(none)]> CHANGE MASTER TO
MASTER_HOST='172.16.16.10', MASTER_PORT=3306,
MASTER_USER='repl', MASTER_PASSWORD='repl',
MASTER_AUTO_POSITION=1
FOR CHANNEL 'mgrA-to-mgrB-semisync' ;
确认半同步复制生效:
[root@GreatSQL mgrB-1][(none)]> SHOW REPLICA STATUS\\G
Replica_IO_State: Queueing master event to the relay log
Source_Host: 172.16.16.10
Source_User: repl
Source_Port: 3306
...
Replica_IO_Running: Yes
Replica_SQL_Running: Yes
...
Source_UUID: 5499a6cb-91cb-11eb-966f-525400e802e2
...
Replica_SQL_Running_State: waiting for handler commit
...
Retrieved_Gtid_Set: f195537d-19ac-11eb-b29f-5254002eb6d6:17-36885051:36885053:36885057:36885059:36885064:36885067
Executed_Gtid_Set: 476c0276-be03-11eb-bd34-525400e802e2:1-5,
f195537d-19ac-11eb-b29f-5254002eb6d6:1-36884719:36884727:36884729-36884732:36884734-36884737
Auto_Position: 1
Replicate_Rewrite_DB:
Channel_Name: mgrA-to-mgrB-semisync
...
P.S,上面的信息是已经运行一段时间后截取出来的,所以GTID的值看起来比较大。
也可以用类似的方法构建传统的异步复制通道,以及双向复制通道,都是可以的。
4. 几个注意事项
两个MGR集群各节点的 server_uuid 确保不重复。
两个MGR集群的名字(group_replication_group_name)确保不重复。
构建完复制通道后,MGR B里的Primary节点最好也要设置为只读(super_read_only=1),避免误操作写入数据。
两个MGR集群之间也要定期校验数据一致性,不管是异步复制还是(增强)半同步复制,乃至MGR都还存在多个丢数据的BUG,不能盲目乐观相信用了增强版同步/MGR就能保证数据一致性了。
本文先介绍基于多数据中心、多套MGR的架构方案。下一次再进一步介绍当发生故障或其他异常需要进行高可用切换的方案。
Enjoy GreatSQL :)
文章推荐:
扫码加入GreatSQL/MGR交流QQ群
点击文末“阅读原文”直达「叶问」专栏
以上是关于金融应用场景下跨数据中心的MGR架构方案的主要内容,如果未能解决你的问题,请参考以下文章