常识性概念图谱建设以及在美团场景中的应用
Posted 美团技术团队
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了常识性概念图谱建设以及在美团场景中的应用相关的知识,希望对你有一定的参考价值。
常识性概念图谱,是围绕常识性概念建立的实体以及实体之间的关系,同时侧重美团的场景构建的一类知识图谱。本文介绍了美团常识性概念图谱构建的Schema,图谱建设中遇到的挑战以及建设过程中的算法实践,最后介绍了一些目前常识性概念图谱在业务上的应用。
一、引言
在自然语言处理中,我们经常思考,怎么样才能做好自然语言的理解工作。对我们人类来说,理解某一个自然语言的文本信息,通常都是通过当前的信息,关联自己大脑中存储的关联信息,最终理解信息。例如“他不喜欢吃苹果,但是喜欢吃冰淇淋”,人在理解的时候关联出大脑中的认知信息:苹果,甜的,口感有点脆;冰淇淋,比苹果甜,口感软糯、冰凉,夏天能解暑;小孩更喜欢吃甜食和冰淇淋。所以结合这样的知识,会推理出更喜欢冰淇淋的若干原因。但是现在很多自然语言理解的工作还是聚焦在信息的层面,现在的理解工作类似于一个贝叶斯概率,从已知的训练文本中寻找符合条件的最大化文本信息。
在自然语言处理中做到像人一样去理解文本是自然语言处理的终极目标,所以现在越来越多的研究上,引入了一些额外的知识,帮助机器做好自然语言文本的理解工作。单纯的文本信息只是外部客观事实的表述,知识则是在文本信息基础之上对外部客观事实的归纳和总结,所以在自然语言处理中加入辅助的知识信息,让自然语言理解的更好。
建立知识体系则是一种直接的方式,能够帮助自然语言理解得更准确。知识图谱就是围绕这个思想提出,期望通过给机器显性的知识,让机器能够像人一样进行推理理解。所以在2012年Google 正式提出了知识图谱(Knowledge Graph)的概念,它的初衷是为了优化搜索引擎返回的结果,增强用户的搜索质量及体验。
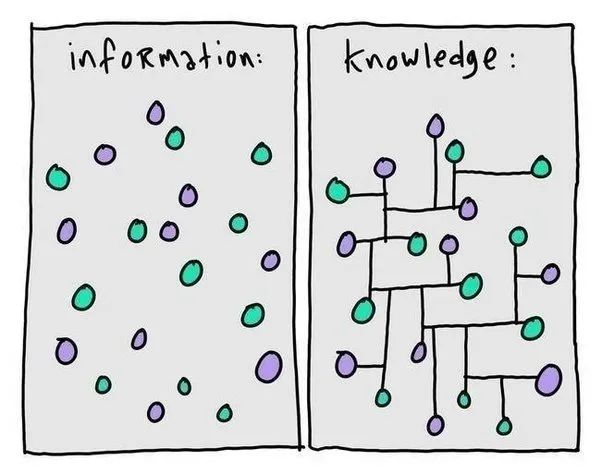
二、常识性概念图谱介绍
常识性概念图谱就是建立概念与概念之间的关系,帮助自然语言文本的理解。同时我们的常识性概念图谱侧重美团的场景,帮助提升美团场景中的搜索、推荐、Feeds流等的效果。
按照理解的需求,主要是三个维度的理解能力:
-
是什么,概念是什么,建立核心概念是什么的关联体系。例如“维修洗衣机”,“维修”是什么,“洗衣机”是什么。
-
什么样,核心概念某一方面的属性,对核心概念某一方面的细化。“带露台的餐厅”、“亲子游乐园”、“水果千层蛋糕”中“带露台”、“亲子”、“水果千层”这些都是核心概念某一个方面的属性,所以需要建立核心概念对应属性以及属性值之间的关联。
-
给什么,解决搜索概念和承接概念之间的Gap,例如“阅读”、“逛街”、“遛娃”等没有明确对应的供给概念,所以建立搜索和供给概念之间的关联网络,解决这一类问题。
总结下来,涵盖“是什么”的概念Taxonomy体系结构,“什么样”的概念属性关系,“给什么”的概念承接关系。同时POI(Point of Interesting)、SPU(Standard Product Unit)、团单作为美团场景中的实例,需要和图谱中的概念建立连接。
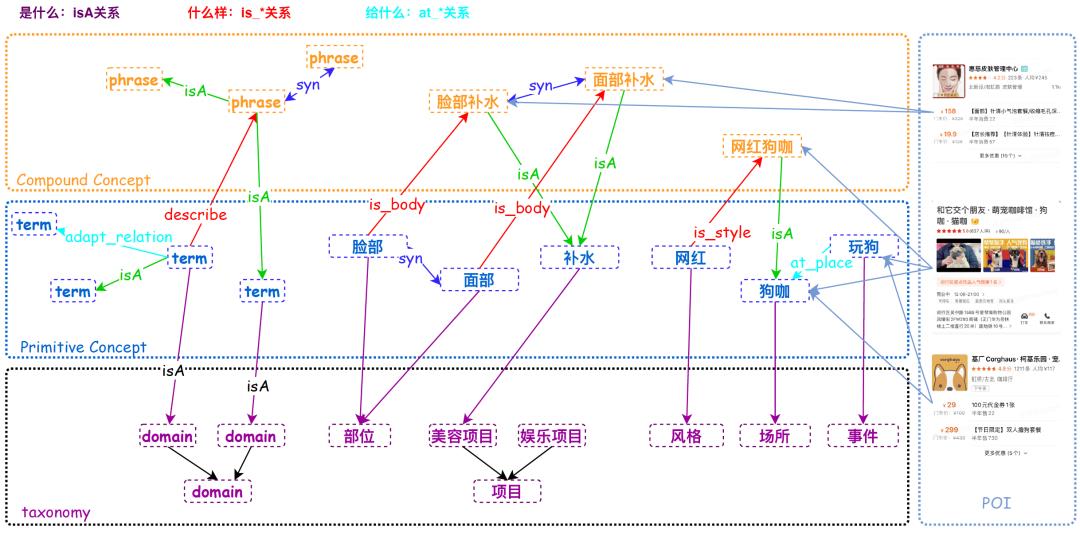
从建设目标出发,拆解整体常识性概念图谱建设工作,拆分为三类节点和四类关系,具体内容如下。
2.1 图谱三类节点
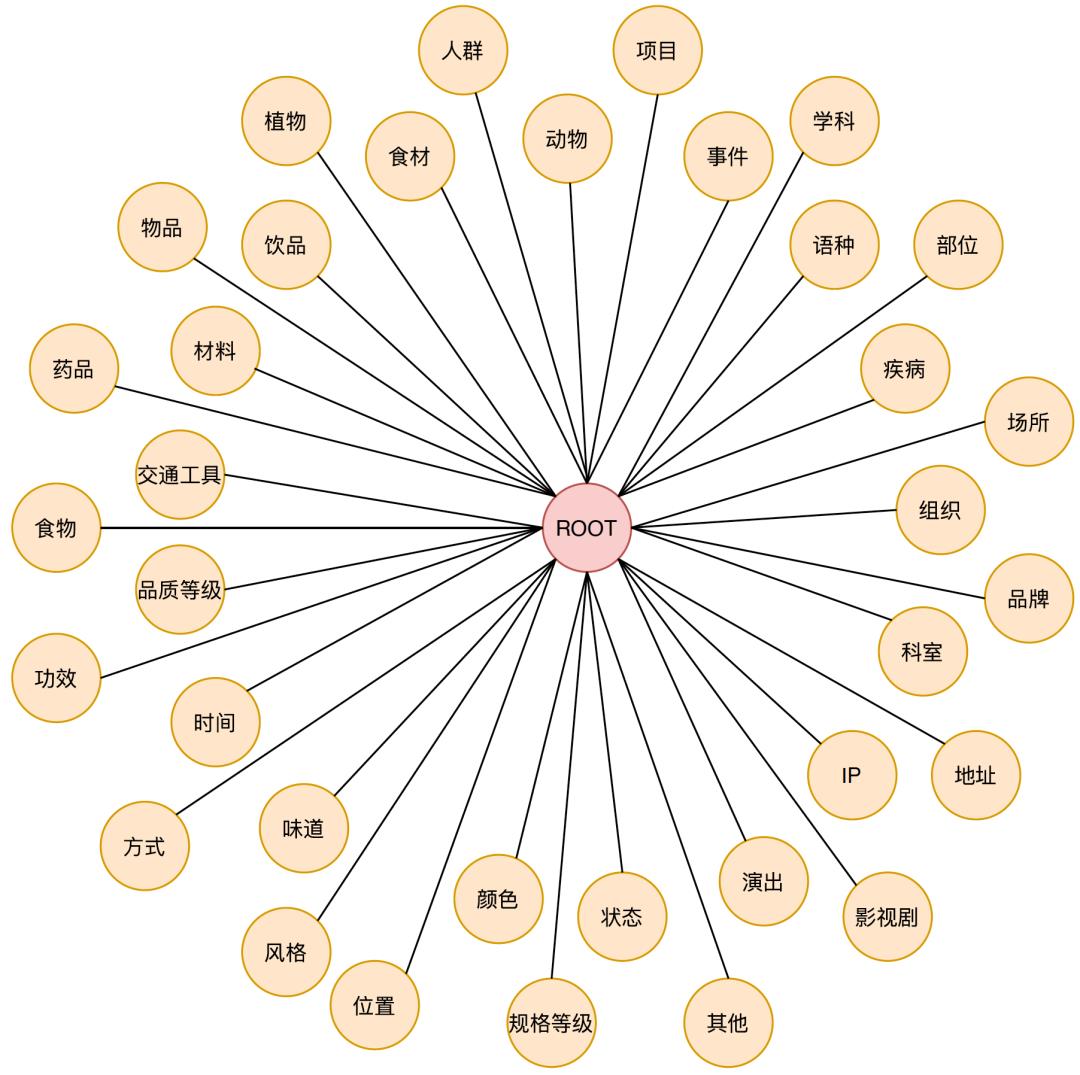
Taxonomy节点:在概念图谱中,理解一个概念需要合理的知识体系,预定义好的Taxonomy知识体系作为理解的基础,在预定义的体系中分为两类节点:第一类在美团场景中可以作为核心品类出现的。例如,食材、项目、场所;另一类是作为对核心品类限定方式出现的,例如,颜色、方式、风格。这两类的节点的定义都能帮助搜索、推荐等的理解。目前预定义的Taxonomy节点如下图所示:
原子概念节点:组成图谱最小语义单元节点,有独立语义的最小粒度词语,例如网红、狗咖、脸部、补水等。定义的原子概念,全部需要挂靠到定义的Taxonomy节点之上。
复合概念节点:由原子概念以及对应属性组合而成的概念节点,例如脸部补水、面部补水等。复合概念需要和其对应的核心词概念建立上下位关系。
2.2 图谱四类关系
同义/上下位关系:语义上的同义/上下位关系,例如脸部补水-syn-面部补水等。定义的Taxonomy体系也是一种上下位的关系,所以归并到同义/上下位关系里。

概念属性关系:是典型的CPV(Concept-Property-Value)关系,从各个属性维度来描述和定义概念,例如火锅-口味-不辣,火锅-规格-单人等,示例如下:
概念属性关系包含两类。
预定义概念属性:目前我们预定义典型的概念属性如下图所示:
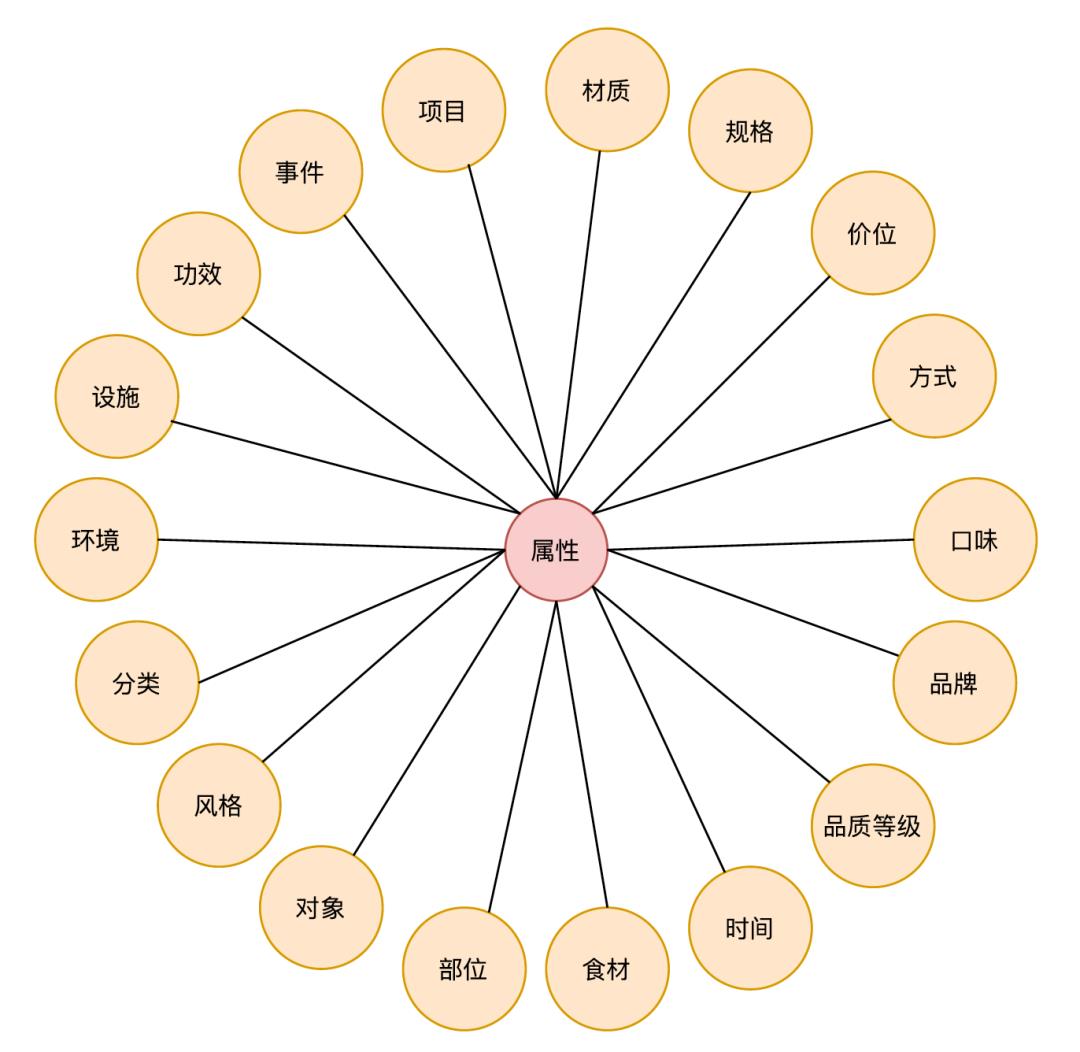
开放型概念属性:除了我们自己定义的公共的概念属性外,我们还从文本中挖掘一些特定的属性词,补充一些特定的属性词。例如,姿势、主题、舒适度、口碑等。
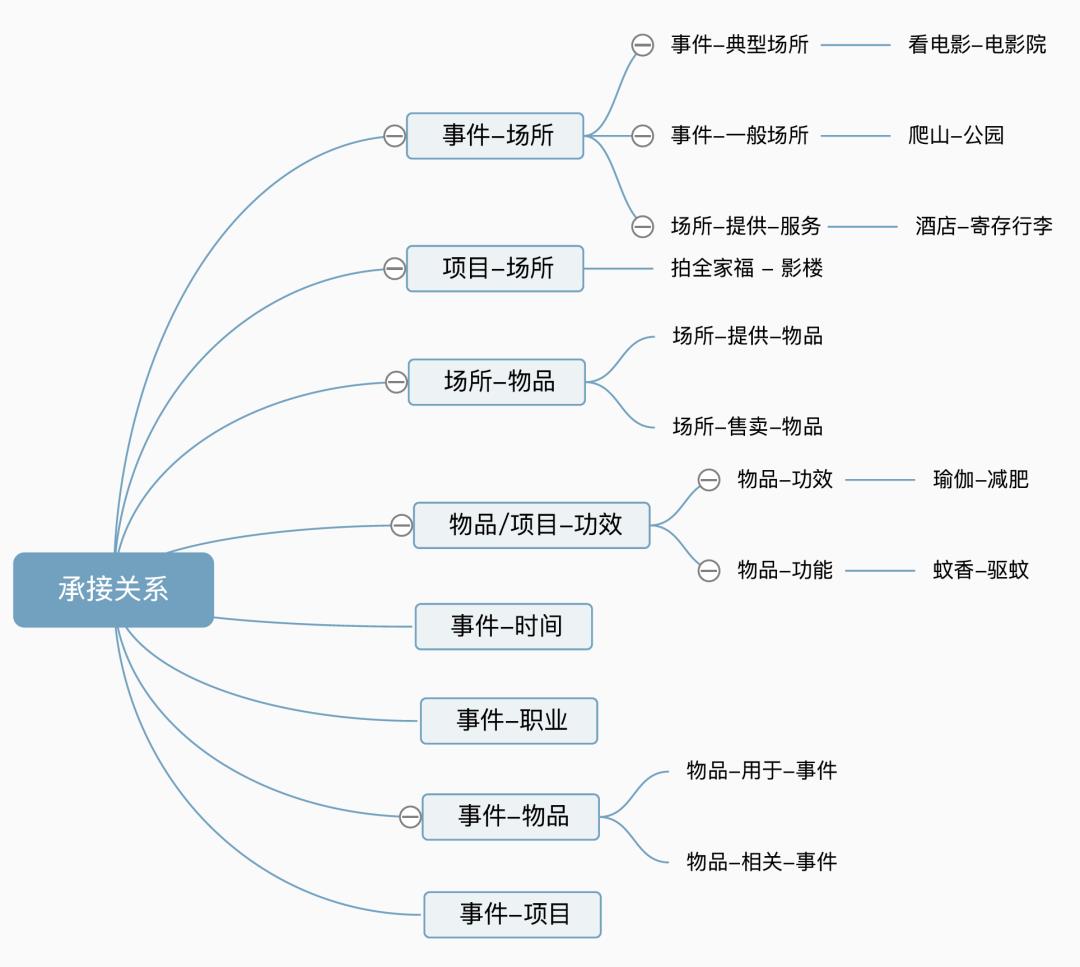
概念承接关系:这类关系主要建立用户搜索概念和美团承接概念之间的链接,例如踏春-场所-植物园,减压-项目-拳击等。
概念承接关系以「事件」为核心,定义了「场所」、「物品」、「人群」、「时间」、「功效」等能够满足用户需求的一类供给概念。以事件“美白”为例,“美白”作为用户的需求,可以有不同的供给概念能够满足,例如美容院、水光针等。目前,定义的几类承接关系如下图所示:
POI/SPU-概念关系:POI作为美团场景中的实例,实例-概念的关系作为知识图谱中最后的一站,常常是比较能发挥知识图谱在业务上价值的地方。在搜索、推荐等业务场景,最终的目的是能够展示出符合用户需求的POI,所以建立POI/SPU-概念的关系是整个美团场景常识性概念图谱重要的一环,也是比较有价值的数据。
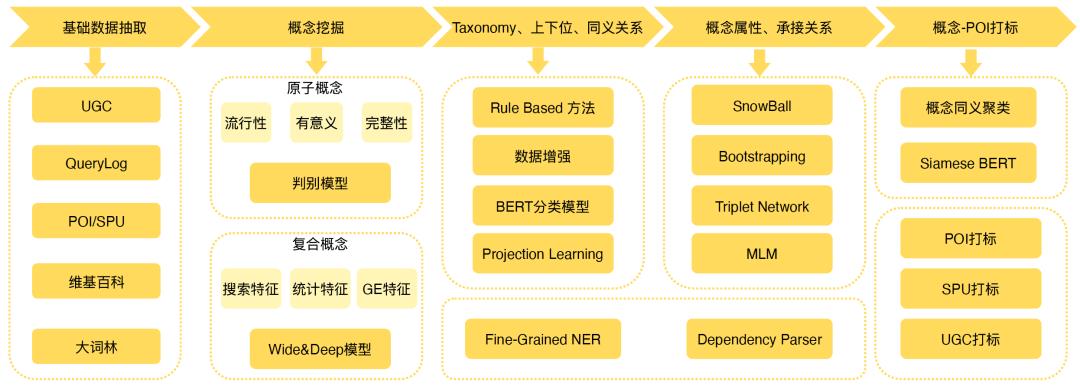
三、常识性概念图谱构建
图谱构建整体框架如下图所示:
3.1 概念挖掘
常识性概念图谱的各种关系都是围绕概念构建,这些概念的挖掘是常识性概念图谱建设的第一环。按照原子概念和复合概念两种类型,分别采取相应的方法进行挖掘。
3.1.1 原子概念挖掘
原子概念候选来自于Query、UGC(User Generated Content)、团单等文本分词后的最小片段,原子概念的判断标准是需要满足流行性、有意义、完整性三个特性的要求。
-
流行性,一个概念应是某个或某些语料内流行度较高的词,该特性主要通过频率类特征度量,如“桌本杀”这个词搜索量很低且UGC语料中频率也很低,不满足流行性要求。
-
有意义,一个概念应是一个有意义的词,该特性主要通过语义特征度量,如“阿猫”、“阿狗”通常只表一个单纯的名称而无其他实际含义。
-
完整性,一个概念应是一个完整的词,该特性主要通过独立检索占比(该词作为Query的搜索量/包含该词的Query的总搜索量)衡量,如“儿童设”是一个错误的分词候选,在UGC中频率较高,但独立检索占比低。
基于原子概念以上的特性,结合人工标注以及规则自动构造的训练数据训练XGBoost分类模型对原子概念是否合理进行判断。
3.1.2 复合概念挖掘
复合概念候选来自于原子概念的组合,由于涉及组合,复合概念的判断比原子概念判断更为复杂。复合概念要求在保证完整语义的同时,在美团站内也要有一定的认知。根据问题的类型,采用Wide&Deep的模型结构,Deep侧负责语义的判断,Wide侧引入站内的信息。
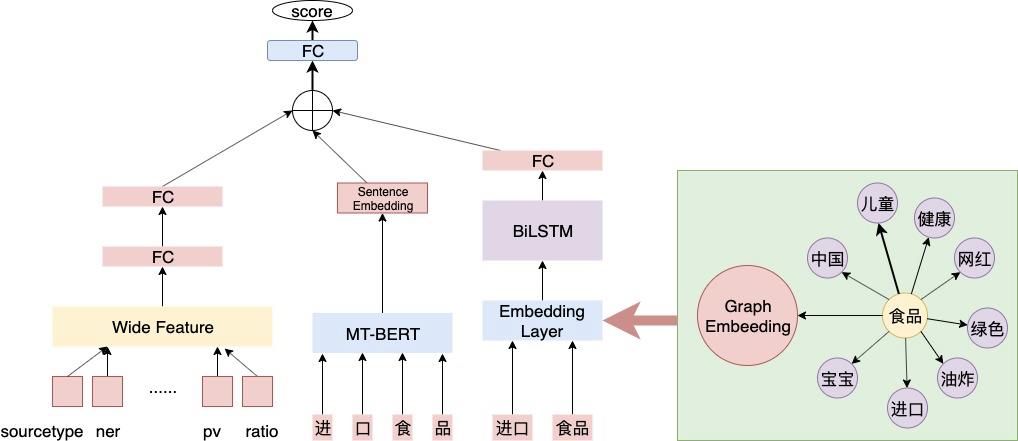
该模型结构有以下两个特点,对复合概念的合理性进行更准确的判断:
-
Wide&Deep模型结构:将离散特征与深度模型结合起来判断复合概念是否合理。
-
Graph Embedding特征:引入词组搭配间的关联信息,如“食品”可以与“人群”、“烹饪方式”、“品质”等进行搭配。
3.2 概念上下位关系挖掘
在获取概念之后,还需要理解一个概念“是什么”,一方面通过人工定义的Taxonomy知识体系中的上下位关系进行理解,另一方面通过概念间的上下位关系进行理解。
3.2.1 概念-Taxonomy间上下位关系
概念-Taxonomy间上下位关系是通过人工定义的知识体系理解一个概念是什么,由于Taxonomy类型是人工定义好的类型,可以把这个问题转化成一个分类问题。同时,一个概念在Taxonomy体系中可能会有多个类型,如“青柠鱼”既是一种“动物”,也属于“食材”的范畴,所以这里最终把这个问题作为一个Entity Typing的任务来处理,将概念及其对应上下文作为模型输入,并将不同Taxonomy类别放在同一空间中进行判断,具体的模型结构如下图所示:
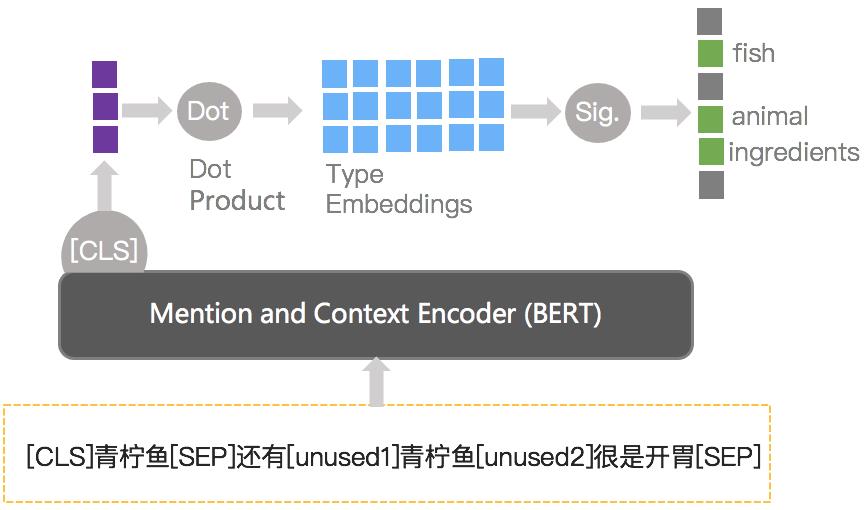
3.2.2 概念-概念间上下位关系
知识体系通过人工定义的类型来理解一个概念是什么,但人工定义的类型始终是有限的,如果上位词不在人工定义的类型中,这样的上下位关系则没办法理解。如可以通过概念-Taxonomy关系理解“西洋乐器”、“乐器”、“二胡”都是一种“物品”,但没办法获取到“西洋乐器”和“乐器”、“二胡”和“乐器”之间的上下位关系。基于以上的问题,对于概念-概念间存在的上下位关系,目前采取如下两种方法进行挖掘:
基于词法规则的方法:主要解决原子概念和复合概念间的上下位关系,利用候选关系对在词法上的包含关系(如西洋乐器-乐器)挖掘上下位关系。
基于上下文判断的方法:词法规则可以解决在词法上存在包含关系的上下位关系对的判断。对于不存在词法上的包含关系的上下位关系对,如“二胡-乐器”,首先需要进行上下位关系发现,抽取出“二胡-乐器”这样的关系候选,再进行上下位关系判断,判断“二胡-乐器”是一个合理的上下位关系对。考虑到人在解释一个对象时会对这个对象的类型进行相关介绍,如在对“二胡”这个概念进行解释时会提到“二胡是一种传统乐器”,从这样的解释性文本中,既可以将“二胡-乐器”这样的关系候选对抽取出来,也能同时实现这个关系候选对是否合理的判断。这里在上下位关系挖掘上分为候选关系描述抽取以及上下位关系分类两部分:
-
候选关系描述抽取:两个概念从属于相同的Taxonomy类型是一个候选概念对是上下位关系对的必要条件,如“二胡”和“乐器”都属于Taxonomy体系中定义的“物品”,根据概念-Taxonomy上下位关系的结果,对于待挖掘上下位关系的概念,找到跟它Taxonomy类型一致的候选概念组成候选关系对,然后在文本中根据候选关系对的共现筛选出用作上下位关系分类的候选关系描述句。
-
上下位关系分类:在获取到候选关系描述句后,需要结合上下文对上下位关系是否合理进行判断,这里将两个概念在文中的起始位置和终止位置用特殊标记标记出来,并以两个概念在文中起始位置标记处的向量拼接起来作为两者关系的表示,根据这个表示对上下位关系进行分类,向量表示使用BERT输出的结果,详细的模型结构如下图所示:

在训练数据构造上,由于上下位关系表述的句子非常稀疏,大量共现的句子并没有明确的表示出候选关系对是否具有上下位关系,利用已有上下位关系采取远程监督方式进行训练数据构建不可行,所以直接使用人工标注的训练集对模型进行训练。由于人工标注的数量比较有限,量级在千级别,这里结合Google的半监督学习算法UDA(Unsupervised Data Augmentation)对模型效果进行提升,最终Precision可以达到90%+,详细指标见表1:

3.3 概念属性关系挖掘
概念含有的属性可以按照属性是否通用划分为公共属性和开放属性。公共属性是由人工定义的、大多数概念都含有的属性,例如价位、风格、品质等。开放属性指某些特定的概念才含有的属性,例如,“植发”、“美睫”和“剧本杀”分别含有开放属性“密度”、“翘度”和“逻辑”。开放属性的数量远远多于公共属性。针对这两种属性关系,我们分别采用以下两种方式进行挖掘。
3.3.1 基于复合概念挖掘公共属性关系
由于公共属性的通用性,公共属性关系(CPV)中的Value通常和Concept以复合概念的形式组合出现,例如,平价商场、日式料理、红色电影高清。我们将关系挖掘任务转化为依存分析和细粒度NER任务(可参考《美团搜索中NER技术的探索与实践》一文),依存分析识别出复合概念中的核心实体和修饰成分,细粒度NER判断出具体属性值。例如,给定复合概念「红色电影高清」,依存分析识别出「电影」这个核心概念,「红色」、「高清」是「电影」的属性,细粒度NER预测出属性值分别为「风格(Style)」、「品质评价(高清)」。
依存分析和细粒度NER有可以互相利用的信息,例如“毕业公仔”,「时间(Time)」和「产品(Product))」的实体类型,与「公仔」是核心词的依存信息,可以相互促进训练,因此将两个任务联合学习。但是由于两个任务之间的关联程度并不明确,存在较大噪声,使用Meta-LSTM,将Feature-Level的联合学习优化为Function-Level的联合学习,将硬共享变为动态共享,降低两个任务之间噪声影响。
模型的整体架构如下图所示:

目前,概念修饰关系整体准确率在85%左右。
3.3.2 基于开放属性词挖掘特定属性关系
开放属性词和属性值的挖掘
开放属性关系需要挖掘不同概念特有的属性和属性值,它的难点在于开放属性和开放属性值的识别。通过观察数据发现,一些通用的属性值(例如:好、坏、高、低、多、少),通常和属性搭配出现(例如:环境好、温度高、人流量大)。所以我们采取一种基于模板的Bootstrapping方法自动从用户评论中挖掘属性和属性值,挖掘流程如下:

在挖掘了开放属性词和属性值之后,开放属性关系的挖掘拆分为「概念-属性」二元组的挖掘和「概念-属性-属性值」三元组的挖掘。
概念-属性的挖掘
「概念-属性」二元组的挖掘,即判断概念Concept是否含有属性Property。挖掘步骤如下:
-
根据概念和属性在UGC中的共现特征,利用TFIDF变种算法挖掘概念对应的典型属性作为候选。
-
将候选概念属性构造为简单的自然表述句,利用通顺度语言模型判断句子的通顺度,保留通顺度高的概念属性。
概念-属性-属性值的挖掘
在得到「概念-属性」二元组后,挖掘对应属性值的步骤如下:
-
种子挖掘。基于共现特征和语言模型从UGC中挖掘种子三元组。
-
模板挖掘。利用种子三元组从UGC中构建合适的模板(例如,“水温是否合适,是选择游泳馆的重要标准。”)。
-
关系生成。利用种子三元组填充模板,训练掩码语言模型用于关系生成。

目前,开放领域的概念属性关系准确率在80%左右。
3.4 概念承接关系挖掘
概念承接关系是建立用户搜索概念和美团承接概念之间的关联。例如,当用户搜索“踏青”时,真正的意图是希望寻找“适合踏青的地方”,因此平台通过“郊野公园”、“植物园”等概念进行承接。关系的挖掘需要从0到1进行,所以整个概念承接关系挖掘根据不同阶段的挖掘重点设计了不同的挖掘算法,可以分为三个阶段:①初期的种子挖掘;②中期的深度判别模型挖掘;③后期的关系补全。详细介绍如下。
3.4.1 基于共现特征挖掘种子数据
为了解决关系抽取任务中的冷启动问题,业界通常采用Bootstrapping的方法,通过人工设定的少量种子和模板,自动从语料中扩充数据。然而,Bootstrapping方法不仅受限于模板的质量,而且应用于美团的场景中有着天然缺陷。美团语料的主要来源是用户评论,而用户评论的表述十分口语化及多样化,很难设计通用而且有效的模板。因此,我们抛弃基于模板的方法,而是根据实体间的共现特征以及类目特征,构建了一个三元对比学习网络,自动从非结构化的文本中挖掘实体关系之间潜在的相关性信息。
具体来说,我们观察到不同商户类目下用户评论中实体的分布差异较大。例如,美食类目下的UGC经常涉及到“聚餐”、“点菜”、“餐厅”;健身类目下的UGC经常涉及到“减肥”、“私教”、“健身房”;而“装修”、“大厅”等通用实体在各个类目下都会出现。因此,我们构建了三元对比学习网络,使得同类目下的用户评论表示靠近,不同类目的用户评论表示远离。与Word2Vec等预训练词向量系统类似,通过该对比学习策略得到的词向量层天然蕴含丰富的关系信息。在预测时,对于任意的用户搜索概念,可以通过计算其与所有承接概念之间的语义相似度,辅以搜索业务上的统计特征,得到一批高质量的种子数据。

3.4.2 基于种子数据训练深度模型
预训练语言模型近两年来在NLP领域取得了很大的进展,基于大型的预训练模型微调下游任务,是NLP领域非常流行的做法。因此,在关系挖掘中期,我们采用基于BERT(参考《美团BERT的探索和实践》一文)的关系判别模型,利用BERT预训练时学到的大量语言本身的知识来帮助关系抽取任务。
模型结构如下图所示。首先,根据实体间的共现特征得到候选实体对,召回包含候选实体对的用户评论;然后,沿用MTB论文中的实体标记方法,在两个实体的开始位置和结束位置分别插入特殊的标志符号,经过BERT建模之后,将两个实体开始位置的特殊符号拼接起来作为关系表示;最后,将关系表示输入Softmax层判断实体间是否含有关系。
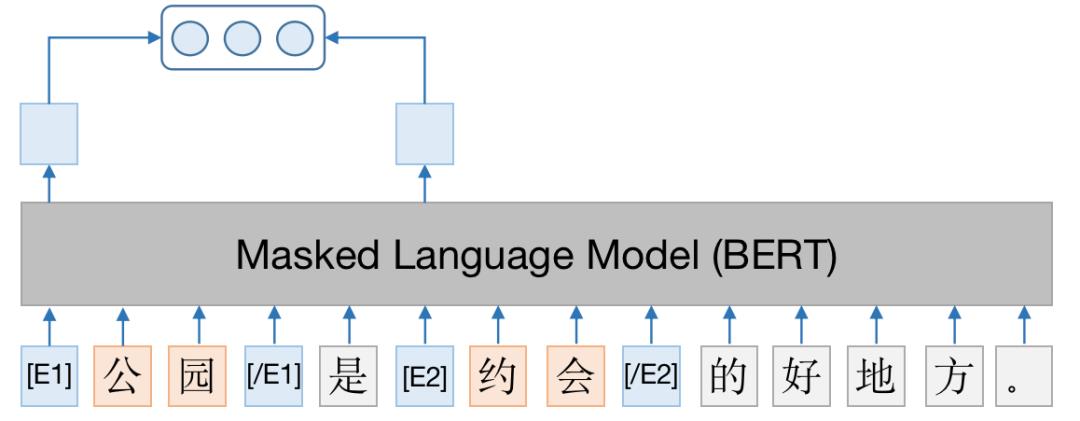
3.4.3 基于已有的图谱结构进行关系补全
通过上述两个阶段,已经从非结构化的文本信息中构建出了一个初具规模的概念承接关系的图谱。但是由于语义模型的局限性,当前图谱中存在大量的三元组缺失。为了进一步丰富概念图谱,补全缺失的关系信息,我们应用知识图谱链接预测中的TransE算法以及图神经网络等技术,对已有的概念图谱进行补全。
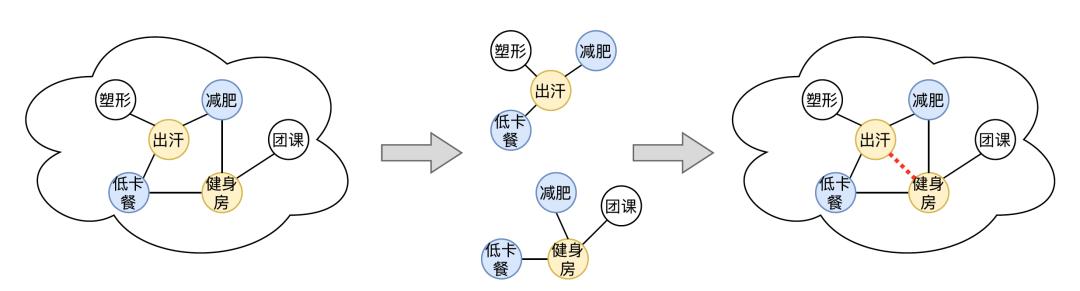
为了充分利用已知图谱的结构信息,我们采用基于关系的图注意力神经网络(RGAT,Relational Graph Attention Network)来建模图结构信息。RGAT利用关系注意力机制,克服了传统GCN、GAT无法建模边类型的缺陷,更适用于建模概念图谱此类异构网络。在利用RGAT得到实体稠密嵌入之后,我们使用TransE作为损失函数。TransE将三元组(h,r,t)中的r视为从h到t的翻译向量,并约定h+r≈t。该方法被广泛适用于知识图谱补全任务当中,显示出极强的鲁棒性和可拓展性。
具体细节如下图所示,RGAT中每层结点的特征由邻居结点特征的均值以及邻边特征的均值加权拼接而成,通过关系注意力机制,不同的结点和边具有不同的权重系数。在得到最后一层的结点和边特征后,我们利用TransE作为训练目标,对训练集中的每对三元组(h,r,t),最小化||h+r=t||。在预测时,对于每个头实体和每种关系,图谱所有结点作为候选尾实体与其计算距离,得到最终的尾实体。
目前,概念承接关系整体准确率90%左右。
3.5 POI/SPU-概念关系建设
建立图谱概念和美团实例之间的关联,会利用到POI/SPU名称、类目、用户评论等多个维度的信息。建立关联的难点在于如何从多样化的信息中获取与图谱概念相关的信息。因此,我们通过同义词召回实例下所有与概念语义相关的子句,然后利用判别模型判断概念与子句的关联程度。具体流程如下:
-
同义词聚类。对于待打标的概念,根据图谱同义词数据,获取概念的多种表述。
-
候选子句生成。根据同义词聚类的结果,从商户名称、团单名称、用户评论等多个来源中召回候选子句。
-
判别模型。利用概念-文本关联判别模型(如下图所示)判断概念和子句是否匹配。
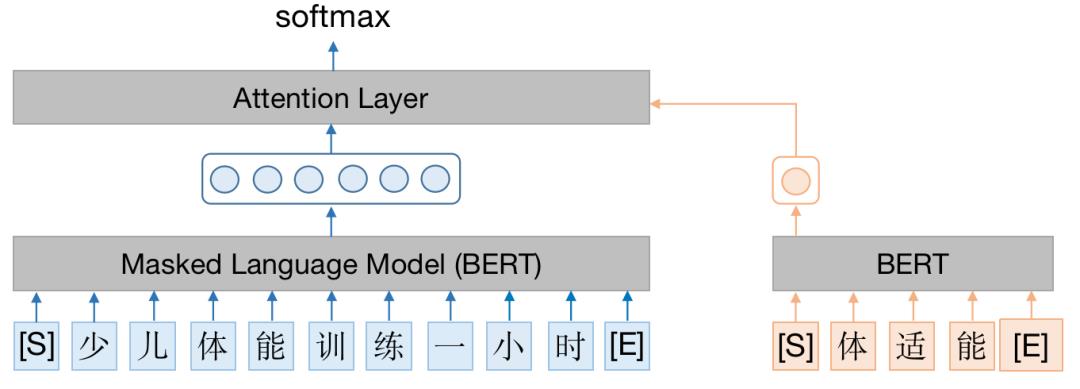
-
打标结果。调整阈值,得到最终的判别结果。
四、应用实践
4.1 到综品类词图谱建设
美团到综业务涵盖知识领域较广,包含亲子、教育、医美、休闲娱乐等,同时每个领域都包含更多小的子领域,所以针对不同的领域建设领域内的知识图谱,能够辅助做好搜索召回、筛选、推荐等业务。
在常识性概念图谱中除了常识性概念数据,同时也包含美团场景数据,以及基础算法能力的沉淀,因此可以借助常识性图谱能力,帮助建设到综品类词的图谱数据。
借助常识性图谱,补充欠缺的品类词数据,构建合理的品类词图谱,帮助通过搜索改写,POI打标等方式提升搜索召回。目前在教育领域,图谱规模从起初的1000+节点扩展到2000+,同时同义词从千级别扩展到2万+,取得了不错的效果。
品类词图谱建设流程如下图所示:

4.2 点评搜索引导
点评搜索SUG推荐,在引导用户认知的同时帮助减少用户完成搜索的时间,提升搜索效率。所以在SUG推荐上需要聚焦两个方面的目标:①帮助丰富用户的认知,从对点评的POI、类目搜索增加自然文本搜索的认知;②精细化用户搜索需求,当用户在搜索一些比较泛的品类词时,帮助细化用户的搜索需求。
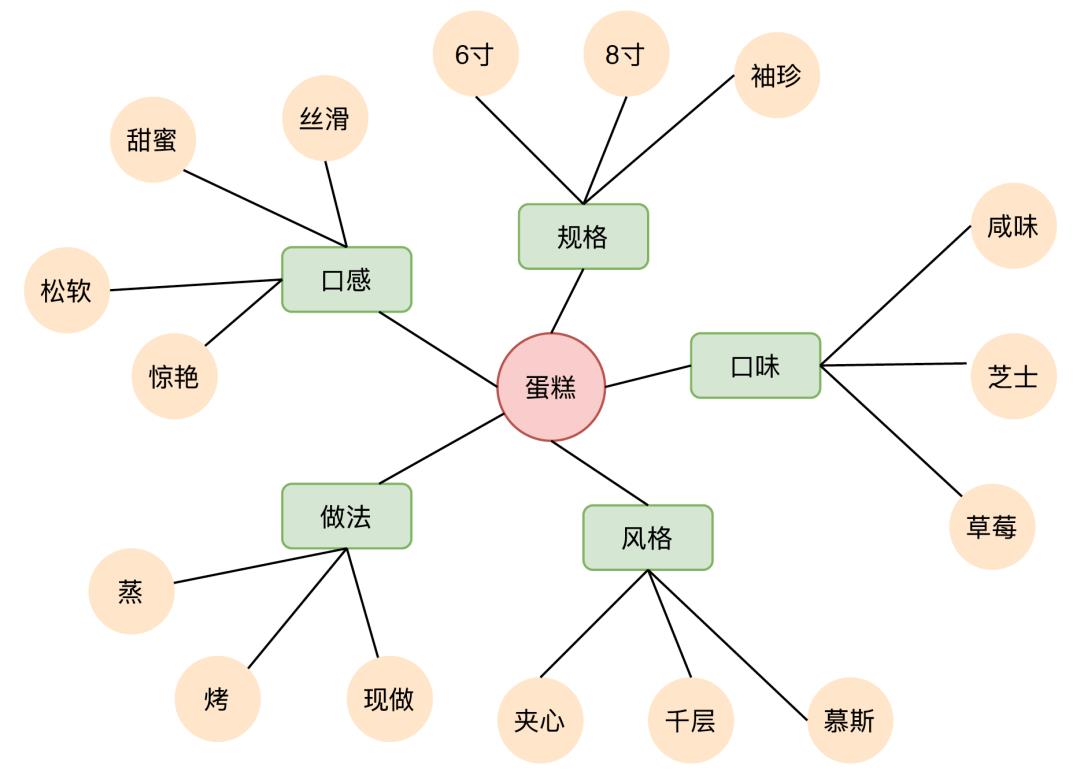
在常识性概念图谱中,建立了很丰富的概念以及对应属性及其属性值的关系,通过一个相对比较泛的Query,可以生成对应细化的Query。例如蛋糕,可以通过口味这个属性,产出草莓蛋糕、芝士蛋糕,通过规格这个属性,产出6寸蛋糕、袖珍蛋糕等等。
搜索引导词Query产出示例如下图所示:
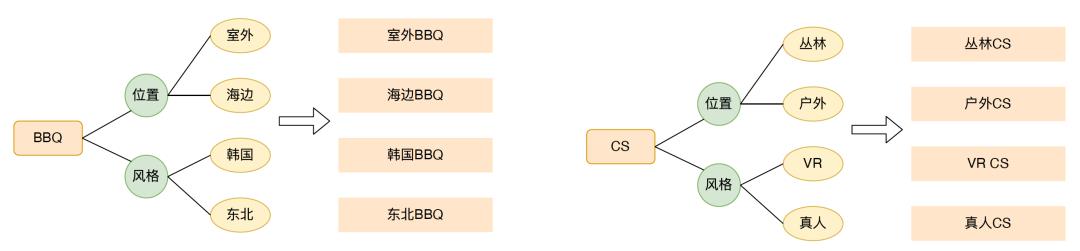
4.3 到综医美内容打标
在医美内容展示上,用户通常会对某一特定的医美服务内容感兴趣,所以在产品形态上会提供一些不同的服务标签,帮助用户筛选精确的医美内容,精准触达用户需求。但是在标签和医美内容进行关联时,关联错误较多,用户筛选后经常看到不符合自己需求的内容。提升打标的准确率能够帮助用户更聚焦自己的需求。
借助图谱的概念-POI打标能力和概念-UGC的打标关系,提升标签-内容的准确率。通过图谱能力打标,在准确率和召回率上均有明显提升。
-
准确率:通过概念-内容打标算法,相比于关键词匹配,准确率从51%提升到91%。
-
召回率:通过概念同义挖掘,召回率从77%提升到91%。

五、总结与展望
我们对常识性概念图谱建设工作以及在美团场景中的使用情况进行了详细的介绍。在整个常识性概念图谱中,按照业务需要包含三类节点和四类的关系,分别介绍了概念挖掘算法、不同种类的关系挖掘算法。
目前,我们常识性概念图谱有200万+的概念,300万+的概念之间的关系,包含上下位、同义、属性、承接等关系,POI-概念的关系不包含在内。目前,整体关系准确率在90%左右,并且还在不断优化算法,扩充关系的同时提升准确率。后续我们的常识性概念图谱还会继续完善,希望能够做到精而全。
参考资料
[1] Onoe Y, Durrett G. Interpretable entity representations through large-scale typing[J]. arXiv preprint arXiv:2005.00147, 2020.
[2] Bosselut A, Rashkin H, Sap M, et al. Comet: Commonsense transformers for automatic knowledge graph construction[J]. arXiv preprint arXiv:1906.05317, 2019.
[3] Soares L B, FitzGerald N, Ling J, et al. Matching the blanks: Distributional similarity for relation learning[J]. arXiv preprint arXiv:1906.03158, 2019.
[4] Peng H, Gao T, Han X, et al. Learning from context or names? an empirical study on neural relation extraction[J]. arXiv preprint arXiv:2010.01923, 2020.
[5] Jiang, Zhengbao, et al. "How can we know what language models know?." Transactions of the Association for Computational Linguistics 8 (2020): 423-438.
[6] Li X L, Liang P. Prefix-Tuning: Optimizing Continuous Prompts for Generation[J]. arXiv preprint arXiv:2101.00190, 2021.
[7] Malaviya, Chaitanya, et al. "Commonsense knowledge base completion with structural and semantic context." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 03. 2020.
[8] 李涵昱, 钱力, 周鹏飞. "面向商品评论文本的情感分析与挖掘." 情报科学 35.1 (2017): 51-55.
[9] 闫波, 张也, 宿红毅 等. 一种基于用户评论的商品属性聚类方法.
[10] Wang, Chengyu, Xiaofeng He, and Aoying Zhou. "Open relation extraction for chinese noun phrases." IEEE Transactions on Knowledge and Data Engineering (2019).
[11] Li, Feng-Lin, et al. "AliMeKG: Domain Knowledge Graph Construction and Application in E-commerce." Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020.
[12] Yang, Yaosheng, et al. "Distantly supervised ner with partial annotation learning and reinforcement learning." Proceedings of the 27th International Conference on Computational Linguistics. 2018.
[13] Luo X, Liu L, Yang Y, et al. AliCoCo: Alibaba e-commerce cognitive concept net[C]//Proceedings of the 2020 ACM SIGMOD International Conference on Management of Data. 2020: 313-327.
[14] Devlin J, Chang M W, Lee K, et al. Bert: Pre-training of deep bidirectional transformers for language understanding[J]. arXiv preprint arXiv:1810.04805, 2018.
[15] Cheng H T, Koc L, Harmsen J, et al. Wide & deep learning for recommender systems[C]//Proceedings of the 1st workshop on deep learning for recommender systems. 2016: 7-10.
[16] Liu J, Shang J, Wang C, et al. Mining quality phrases from massive text corpora[C]//Proceedings of the 2015 ACM SIGMOD International Conference on Management of Data. 2015: 1729-1744.
[17] Shen J, Wu Z, Lei D, et al. Hiexpan: Task-guided taxonomy construction by hierarchical tree expansion[C]//Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2018: 2180-2189.
[18] Huang J, Xie Y, Meng Y, et al. Corel: Seed-guided topical taxonomy construction by concept learning and relation transferring[C]//Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2020: 1928-1936.
[19] Liu B, Guo W, Niu D, et al. A user-centered concept mining system for query and document understanding at tencent[C]//Proceedings of the 25th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining. 2019: 1831-1841.
[20] Choi E, Levy O, Choi Y, et al. Ultra-fine entity typing[J]. arXiv preprint arXiv:1807.04905, 2018.
[21] Xie Q, Dai Z, Hovy E, et al. Unsupervised data augmentation for consistency training[J]. arXiv preprint arXiv:1904.12848, 2019.
[22] Mao X, Wang W, Xu H, et al. Relational Reflection Entity Alignment[C]//Proceedings of the 29th ACM International Conference on Information & Knowledge Management. 2020: 1095-1104.
[23] Chen J, Qiu X, Liu P, et al. Meta multi-task learning for sequence modeling[C]//Proceedings of the AAAI Conference on Artificial Intelligence. 2018, 32(1).
作者简介
宗宇、俊杰、慧敏、福宝、徐俊、谢睿、武威等,均来自美团搜索与NLP部/NLP中心。
阅读更多
---
---------- END ----------
招聘信息
美团搜索与NLP部/NLP中心是负责美团人工智能技术研发的核心团队,使命是打造世界一流的自然语言处理核心技术和服务能力,依托NLP(自然语言处理)、Deep Learning(深度学习)、Knowledge Graph(知识图谱)等技术,处理美团海量文本数据,为美团各项业务提供智能的文本语义理解服务。
NLP中心长期招聘自然语言处理算法专家/机器学习算法专家,感兴趣的同学可以将简历发送至wangzongyu02@meituan.com。
也许你还想看
| 报名 | CCKS2021评测任务:生活服务领域知识图谱问答

以上是关于常识性概念图谱建设以及在美团场景中的应用的主要内容,如果未能解决你的问题,请参考以下文章