基于PowerVM技术的虚拟化设计思路及优化研究
Posted twt企业IT社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了基于PowerVM技术的虚拟化设计思路及优化研究相关的知识,希望对你有一定的参考价值。
摘要:本文通过对PowerVM设计过程中所包含的各个模块(整体框架、网络架构、存储架构、其他外设等)进行技术剖析,并详细比对各种技术架构的优缺点及适用场合。提出设计的原则、设计的思路以及设计过程中必须完成的模型,最终结合实际的案例展示了整个PowerVM的规划设计过程。
引言
Power小型机曾是企业用来运行自己重要业务的主要服务器,尤其是在一些金融企业内,小型机在数据中心内的占有率一度几乎达到了80-90%。随着云计算的发展,这种单一实体服务器运行业务的模式已经退出历史舞台,虚拟化技术所构建的私有云平台逐渐成为企业数据中心的主流架构。那么如何利用既有的小型机资源实现稳定效率的计算资源平台成为企业数据中心面临的主要问题。
1.技术概述
所谓PowerVM技术就是在Power平台上实现的虚拟化技术,它可以实现计算资源与硬件平台的隔离,实现计算资源的动态调配,实现计算资源的高度共享。
2.项目实施目标
要完成一个IBM小型机虚拟化平台建设项目,需要完成以下总的目标:1)业务系统功能目标;2)业务连续性目标;3)业务性能目标;根据项目实施的总体目标,我们带着以下问题来完成项目需求分析,简单说这个需求分析就是要设计好项目实施需要解决的问题来指导我们设计过程中所运用到的方法以及工具。
具体说来,基于总体目标,我们需要完成如下问题设计:1)需要设计多少个客户分区需要设计什么样配置的客户分区来支撑应用架构的实现?2)IO服务分区需要设计成什么模式来满足业务连续性的需求?3)需要设计多少个网络逻辑分区来满足业务隔离性需求?4)需要采用什么样的物理配置来满足业务的性能要求?
3.选择物理硬件配置
前面章节提到PowerVM的实现,需要解决一个很关键的问题就是选择什么样的硬件配置来满足业务系统功能以及性能的需求。选择硬件配置无非就是要完成表3.1所列出项目的赛选。
对于CPU来讲,一个物理CPU可以按照核的0.1粒度来划分,就是说从CPU资源共享技术上来讲,一个物理核最多可以虚拟出10个Dlpar。如果是双核的CPU,那么意味着可以做到20个Dlpar来共享这一个物理CPU。而内存的划分相对比较自由,任何数量的内存都可以划分。对于HBA卡来说,通常带宽参数有4G、8G、16G,8GB的为常见配置,对于网卡来讲的话通常有GB和10GB,根据自己的网络环境选择合适带宽的网卡。在选择这些硬件配置的时候需要根据以下几个基本原则来执行:
1)根据业务系统的数量以及每个业务系统大概的资源需求曲线趋势来决定CPU和内存资源的数量配置。
2)IO设备配置选择需要根据设计的Vios数目做均衡配比,也就是说如果双VIOS模式,那么IO板卡数量上的配置应该达到偶数级的配置,并且平均划给两个VIOS。
3)所有的客户分区会分时分空间的方式共享VIOS上的IO设备,配置的选择应该能够支持业务系统的峰值并且具备一定的抗突发压力的冗余能力。
4.项目详细设计及优化
4.1 设计及规划步骤
当硬件配置已经确定的前提条件下,那么下面的工作就是要按照科学合理的规划步骤来设计和优化虚拟化项目实施:
① 硬件拓扑及位置规划设计;
② 系统整体分区配置设计规划;
③ 系统网络设计规划;
④ 系统存储设计规划;
⑤ 分区备份及媒体库设计规划;
⑥ VIOS分区优化参数配置规划;
⑦ 客户分区优化参数配置规划;
⑧ 压力测试及项目评估;
4.2 硬件拓扑及位置规划设计
这个问题的阐述,本文以一个实际的案例来说明具体的设计原则及设计思想。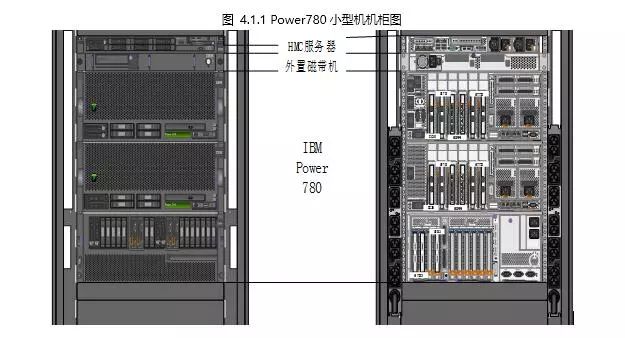
如图4.1.1 所示,以780为例,一个物理服务器包括了两个主机柜和一个IO扩展柜,分别位于机柜的不同位置。在同一个主机柜(CEC)之内,其内部的物理架构如下图4.1.2 所示:
图 4.1.2Power780内部总线架构图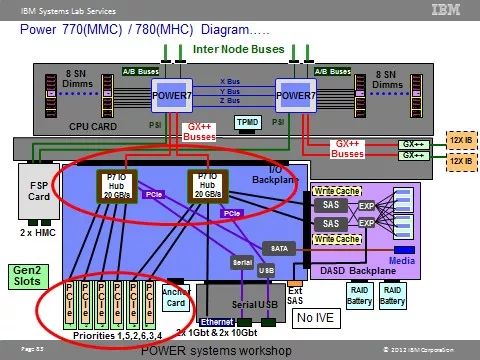
图 4.1.3 IO扩展柜内部总线架构图 ↓
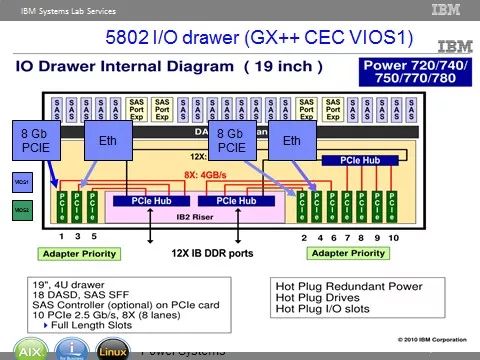
根据两个架构图所示,从CPU到最末端的HBA卡,经历了不同的总线架构。这里有两点思路是设计PowerVM时,必须遵循的原则:
1)同类型的所有HBA卡位置的配置要保证在服务器内部所经历的FRU是冗余的、均衡的。
2)不同类型的HBA卡,要保证重要的IO设备放在服务优先级高的位置上。
举个例子,按照以上实例,如果我们要配置4块双口FC卡和两块儿双口10GB光口网卡。首先,主机柜(CEC)的槽位足够,那么FC卡和网卡只用主柜槽位,保证机柜服务的优先性。其次,由于对于同一个主机柜来说,只需要配置所有资源的1/2,也就是22PFC+12PNIC,也就是说一个CEC上需要占用3个槽位。最后,一个CEC内部PCIe槽位的优先级顺序如图4.1.1所示。网卡优先级最高,占用槽位1;光纤卡既要保证服务优先级,又要保证内部FRU分布的均衡性,那么分别占用槽位3、5。
4.3 系统整体分区规划设计
对于PowerVM的系统整体架构如图4.3.1所示。
图 4.3.1PowerVM整体架构图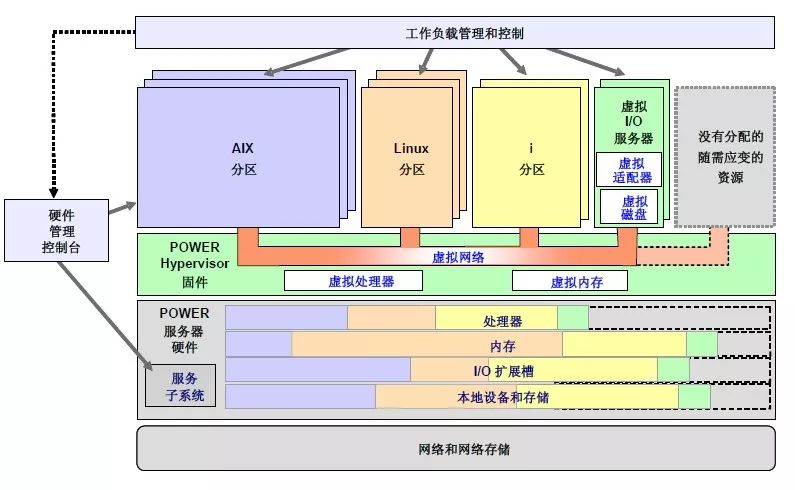
总的来讲,PowerVM的架构主要模块分为三个部分:Hypervisor、客户分区、虚拟VIOS分区。Hypervisor层是写入到Firmware层面的软件模块,它可以实现客户分区的CPU以及内存共享问题,同时也是实现资源逻辑隔离的工具。虚拟VIOS分区是客户分区实现IO共享以及逻辑隔离的工具,客户分区的所有网络及存储流量都会经过VIOS里面的物理IO设备。客户分区是真正提供给应用来运行的操作系统分区。实现系统分区整体架构的设计,落到细节就是要解决如下问题:
① 分区数量;
② 分区概要文件控制要素;
③ 分区资源配额比例以及动态调整范围等;
④ 客户分区虚拟板卡配额分配;
对于1,很容易解决。一般高冗余模式下的PowerVM架构,VIOS分区应该保持双冗余模式。客户分区需要根据业务需求以及业务的扩展性要求留有一定冗余即可。
对于2,所谓的概要文件控制要素就是创建概要文件的时候所需要设置的控制参数,一般定义为如下模型:
Partition Profile = {
Name,
Partition_ID,
Partition_Name,
Adapter_Max,
Time_Reference,
MSP_y/n }
Partition_ID: 分区标识。Partition_Name:分区命名。Adapter_Max: 分区可以容纳的最大分区数目。Time_Reference,MSP_y/n:这两个控制参数决定动态迁移LPM功能能否实现。
对于3,分区资源配额比例主要是指客户分区以及虚拟VIOS分区对于CPU及内存资源的配额比例。可以定义为如下模型:
Partition Resource = {
Partition_ID,
CPU = {
PU_Min, PU_Desire, PU_Max;
VP_Min, VP_Desire, VP_Max;
Mode,
Weight},
Memory = {
Mem_Min, Mem_Desire, Mem_Max;} }
每一项资源的配额都会有最大、最小、期望三个值来控制。满足不了最小值,分区无法启动。资源充足情况下,系统会满足其期望值分配。Mode决定资源独占还是共享方式,对于VIO和非常重要的分区可以采取独占方式,其他情况均应该采用共享模式,否则虚拟化就是失去了意义。对于Weight参数,它决定了资源抢占的优先级程度。同样是根据系统资源重要性来配置具体权重值。
关于VP和PU的区别,VP是指客户分区内可以观测到的虚拟CPU的个数,而PU是指分区真正可以获得的处理器的处理能力。VP数目多的场合下,处理多线程应用程序是很有意义的。但是VP太多的情况下,会增加处理器上下文切换的时间。总体原则,VP的数目应该保持为物理CPU核数的2倍-4倍是比较好的选择。
对于4,客户分区虚拟板卡配额,也就是客户分区内应该部署的虚拟网卡、虚拟光纤卡、虚拟SCSI等的具体数目。对于这个问题我们需要结合存储和网络的具体架构来设计IO板卡的设计,所以放在后面章节来讨论。
4.4 网路架构规划设计
对于PowerVM可以实现的网络架构,有很多种。本文探讨的前提条件是:
第一、双VIO的网络架构;
第二、需要支持多VLAN的网络架构。
基于这个前提条件,本文将可以实现的网络架构归为两种模式:一种是NIB模式,另外一种是LoadSharing模式。
基于NIB模式的网络架构,如图4.4.1所示:
图 4.4.1PowerVM网络架构图(NIB)
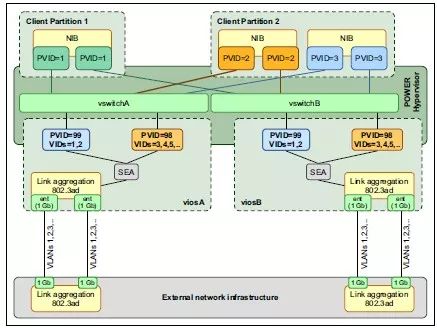
2)虚拟IO分区(VIOS) - 两个VIOS组成一个VIOS集群,它们通过特殊内部VLAN(PVID=100)来实现心跳检测。只有一个逻辑交换机提供给客户分区使用。
3)网络映射 - 客户分区的网卡不需要映射到任何一个具体的VIOS上,只需要将网卡VLAN标签(PVID)设置好即可。
4)故障转移模式 - 客户分区理论上没有任何网卡故障可言,故障转移通过VIO分区的切换实现网络流量的转移。
5)流量负载模式 - 客户分区网卡的映射对于客户分区来讲是透明的,它无法决定流量的选择。完全靠VIOS分区来实现整体上的负载均衡。根据以上架构描述,可以看出以上两种架构有几下主要区别:
①故障转移方式差异,NIB通过客户分区感知故障然后在网卡绑定层面实现故障转移,这种故障转移方式相对滞后,因为虚拟网卡不存在真正的物理故障,故障转移需要ping工具来实时监测网络可用状态。除非系统层面增加长ping工具实时监测网络可用情况。Loadsharing通过VIO感知故障然后在VIO层面实现网络流量接管。
②流量负载均衡方式差异,NIB通过主观设计网卡AP顺序实现网络流量的均衡,这种方式相对可控流向,但是其流量的均衡也需要付出人工代价来持续维护;Loadsharing通过VIO从整体调整网络流量负载,虽然不可控制其具体流向,但是它可以自动实现分区间的负载流量平衡,随着分区的增减变更,它会自动实现流量动态调整。
面对这两种网络架构,如何科学正确地选择自己的网络架构,以什么原则什么方法来选择?以什么模式什么工具将设计落地?就选择的基本原则,本文认为有以下两点:
首先,功能上两种架构都能实现网络的高可用、VLAN的支持、网络流量的均衡负载等重要功能。如果就以上功能而言,对了两种架构的优缺点之后,选择Loadsharing方式是相对比较合理科学的方式。
其次,要考虑到特殊的网络层面需求。如果有对NIB架构模式的特殊需求,那么同样可以选择NIB方式。
本文接下来基于Loadsharing方式的设计来探讨设计如何落地。那么基于这种架构下的网络设计,需要做好以下几个模型的设计和实现:
1)VIO网络映射模型
SEA = {
SEA_Name;
Linkagg_NIC {
Device_Name;
Physical NIC {
Device_Name;
Slot_Port;
}
};
Virtual_NICs {
Ent0 {
Device_Name;
Virutal_ID;
PVID;
Vlan_Tags { Vlan1,..VlanN }
Extenal_Access {
y;
Priority = 1 }
}
Ent1 {
Device_Name;
Virutal_ID;
PVID;
Vlan_Tags { Vlan1,..VlanN }
Extenal_Access {
y;
Priority = 1 }
}
}
}
2)客户分区网络映射模型
Dlpar_Virual_NIC = {
Device_Name;
Virutal_ID;
PVID;
Extenal_Access { n, Priority }
}
VIO网络映射模型主要完成网卡由物理网卡到虚拟网络的部署及配置。SEA_Name是共享网卡,是物理网卡到虚拟网卡间的桥梁。Virtual_NICs里面定义的网卡属于VIOS上的虚拟网卡,主要负责连接客户分区上的虚拟网卡,可以看作是虚拟交换机的端口组。客户分区的虚拟网卡定义模型主要定义客户分区上的虚拟网卡的部署方法。其中
A = Dlpar_Virual_NIC.PVID
B = SEA.Vitural_NIC.VLAN_Tags
A∈B (A必须是B的最小子集)
上述公式表明客户分区的PVID必须定义为VIOS上虚拟网卡上所绑定的VLAN标签,SEA所有虚拟网卡上的VLAN标签不能重合,否则网络无法通讯。另外关于访问外网的控制元素: Extenal_Access { y/n,priority }
SEA.Virtual_NIC = { y, 1 }
Dlpar_Virtual_NIC = { n, null }
虚拟VIO上的虚拟网卡必须设置为外网访问模式,而客户分区的外网访问模式必须关闭,否则网络与外界无法实现网络通讯。
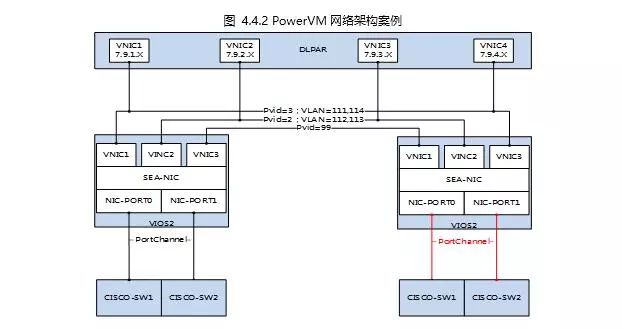
其中,具体模型套用如下:
SEA = {
ent10;
Linkagg_NIC {
ent9;
Physical NIC {
ent7, P2-C1-T1-L1;
ent8, P2-C1-T1-L2;
}
};
Virtual_NICs {
ent0 {
ent0; 2; 1;
Vlan_Tags { 111,112 }
Extenal_Access { y,1 }
}
ent1 {
ent1; 3; 2;
Vlan_Tags { 113,114 }
Extenal_Access { y,1}
}
ent2 { ent2; 4; 99; }
}
}
}
Dlpar_Virual_NIC1 = {ent0;1;111;n}
Dlpar_Virual_NIC2 = {ent0;2;112;n}
Dlpar_Virual_NIC3 = {ent0;3;113;n}
Dlpar_Virual_NIC4 = {ent0;4;114;n}
4.5 存储架构设计
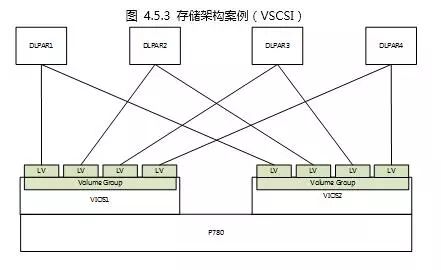
对于存储架构的设计,从实现的技术角度可以分为两种:一种是VSCSI的方式,它是通过VIOS上的VSCSI卡与客户分区上的VSCSI卡建立映射关系,将VIOS里面的存储对象(PV、LV)提供给客户分区使用。另外一种是通过虚拟光纤卡-NPIV方式,它通过将VIOS光纤卡进行虚拟化,通过虚拟WWWN将存储对象直接映射给客户分区。首先来看一下VSCSI架构,如下图所示:
图 4.5.1 PowerVM存储架构-VSCSI
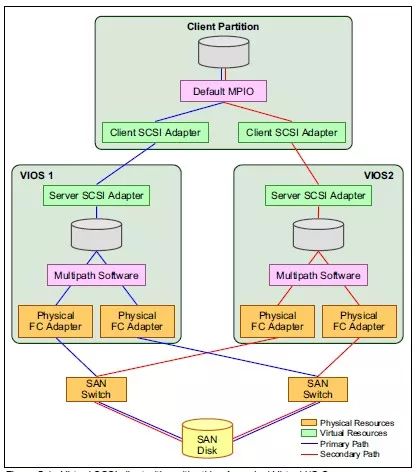
由图可以看到,存储卷首先通过两个VIOS的物理光纤卡,将卷共享给两个VIOS,然后通过多路径聚合软件将这个卷在不同的VIOS分别聚合为各自的一个磁盘,然后由VIOS将磁盘通过VSCSI卡映射给客户分区,客户分区再通过多路径聚合软件将两个VIOS提供的磁盘聚合成为一个磁盘。当然我们也可以在VIOS层面对磁盘再进行LVM方式的虚拟化。
图 4.5.2PowerVM存储架构-VSCSI
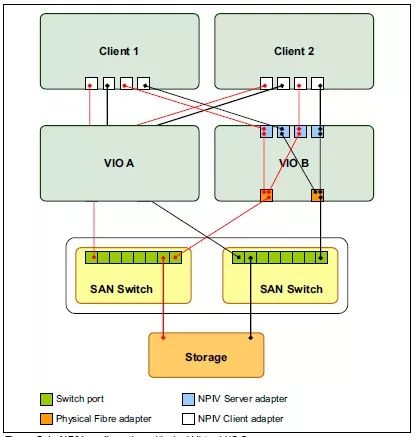
对于NPIV方式实现的存储架构,在VIOS层面将光纤卡虚拟成为多个vfchost,客户分区创建若干具备独立WWN的虚拟光纤卡分别与VIOS上的vfchost建立绑定关系。这样客户分区的虚拟光纤卡的WWN就会被加入在物理SAN环境,通过Zone的设置存储设备就可以直接将存储卷划分给客户分区,期间没有经过VIOS的再分配。
对于这两种架构的特点对比分析如下:
①高可用:NPIV是通过客户分区的多个虚拟光纤卡链路聚合实现VIOS的高可用。VSCSI通过客户分区的两个VSCSI卡将链路聚合实现VIOS的高可用。二者没有明显差异。
③灵活性:NPIV方式每增加一个动态分区,就需要增加SAN的ZONE配置,需要新增存储卷。VSCSI的方式只要将在VIOS层面增加逻辑卷即可,不需要变更SAN环境,不需要增加存储卷的划分,相对灵活简单。如果客户分区变动频繁的话,VSCSI的方式是最佳选择。
④其他:NPIV支持LPM功能。但是VSCSI方式如果采用逻辑卷方式,就无法实现LPM功能。
技术架构选择之后,如何将存储架构具体落地,还需要完成具体存储映射模型的设计,对于NPIV技术架构,需要完成以下两个模型设计:
NPIV = {
FC{
Device_Name;
Slot_Port;
WWName;
Vhosts {
Vhost { VID; VfcName }
}
}
};
Dlpar_VFC = {
VFC{
VID;
WWName;
Vhost { VID };
};
}
对于VSCSI技术架构的实现,需要完成以下两个模型的设计:
VSCSI = {
VolumeGroup{
PVs{
LUN_ID;
Device_Name;
}
LVs{
LV_Name;
Vscsi;
}
}
}
Dlpar_SCSI = {
SCSIs {
SCSI { VID,Vscsi }
}
}
本文探讨的业务环境背景,首先客户分区数量相对固定而且数目不多;其次客户分区不仅要支撑重量级应用服务而且要支撑重量级数据库服务。应用服务器通过负载均衡设备实现应用集群,数据库部署Oracle RAC,因此不需要LPM功能。因此本文将存储架构设计为融合模式,数据库分区的数据磁盘以NPIV方式映射,其他磁盘都用VSCSI方式实现。
VIOS01_NPIV = {
fcs0 {
CEC01-C2-P1;
10000090FA7F4762;
{vfchost0, 301}
{vfchost4, 501}
}
fcs1 {
CEC01-C2-P2;
10000090FA7F4763;
{vfchost2, 401}
{vfchost6, 601}
}
fcs2 {
CEC01-C5-P1;
10000090FA855118;
{vfchost1, 302}
{vfchost5, 502}
}
fcs3 {
CEC01-C5-P2;
10000090FA855119;
{vfchost3, 402}
{vfchost7, 602}
}
}
VIOS02_NPIV(略)
Dlpar1_VFC = {
VFC0{ 11;C05076082A460000;{301}};
VFC1{ 12;C05076082A460000;{302}};
VFC2{ 13;C05076082A460000;{303}};
VFC3{ 14;C05076082A460000;{304}};
}
}
Dlpar2_VFC(略)
在设计以上模型的时候,需要保证以下设计原则:
1)每一个客户分区分别要映射到两个VIOS上的物理不同光纤卡上,保证物理光纤卡和VIOS都能避免单点故障发生。但是客户分区的光纤链路不宜太多。
2)虚拟板卡的标识和命名能清晰体现客户分区到VIOS映射关系,而且这种命名规则具备可扩展性,也就是说随着客户分区的增加,这种命名规则依然能保持。
4.6 其他外设架构规划设计
完成4.5的规划设计之后,PowerVM整体的规划设计工作相当于完成了80%。本节讨论的是客户分区所需要的一些其他外设的规划,比如说磁带机、DVD设备等。对于磁带机和DVD物理设备,所有客户分区只能共享VIOS物理设备,而且不能同时共享,只能分时共享。规划设计阶段完成以下模型设计即可。
SCSI = {
Vhost {
SCSI_ID,
Device { device_name }
Partition { ID, SCSI_ID }
}
}
Dlpar_SCSI = {
SCSI{
SCSI_ID,
VIOS_SCSI {SCSI_ID}
}
}
例如以下案例:
{
Vhost0 {311,{rmt0,cd0},{any,any}}
Vhost1 {411,{rmt0,cd0},{any,any}}
Vhost2 {511,{rmt0,cd0},{any,any}}
...
}
Dlpar1_SCSI = {
SCSI{ 11, {311} }
}
以上案例可以实现磁带机、DVD、虚拟媒体库三种设备在各个客户分区间的共享,客户分区的SCSI卡已经跟VIOS上的虚拟SCSI卡建立映射关系,每次只需要将具体设备挂载到相应的vhost上,客户分区就可以使用这个挂载设备了。
4.7 参数配置优化
截至到目前为止,PowerVM功能设计阶段基本结束。接下的任务就是要对整个架构的参数配置进行优化配置工作。具体描述如下:
(一)网络性能优化参数
1) mtu,mtu_bypass
操作:分别在VIOS和客户分区打开大数据包传输控制参数,并设置较大MTU值。
2)jumbo_frames,large_send,
3)large_recieve
操作:分别在VIOS和客户分区打开以上三个参数来保证大的数据包可以高效可靠通讯。
3) flow_ctrl
操作:如果网络环境带宽为10GB,建议在VIOS上打开该参数,避免设备缓存满了之后导致数据包频繁重传或者丢包现象发生。
4)udp_pmtu_discovery
5)tcp_pmtu_discovery
操作:如果是NIB架构,建议打开以上参数。
(二)存储性能优化参数
1)fc_err_recov
操作:设置链路切换为fast_fail策略。在这里一定要注意,如果有HA的配置或者是ORACLE的配置,其仲裁时间一定要超过这个策略的时间,否则可能引起闹分裂现象发生。
2)Dyntrk
操作:打开光纤链路设备动态跟踪开关。
3)max_xfer_size
操作:将光纤最大传输单元调整到最大值。
4)num_cmd_elems
操作:调整光纤卡最大等待命令队列。
5)reserve_policy
操作:该参数为文件系统共享锁开关,打开该开关,将磁盘共享锁交给数据库来控制。如果用VSCSI的架构,这个锁必须打开。
6)maxproc
7)nofiles
8)PagingSpace
操作:以上参数根据具体数据库应用或者其他应用场合,将相应参数调整为合适的值。
5.总结及展望
本文通过对PowerVM设计过程中所包含的各个模块(整体框架、网络架构、存储架构、其他外设等)进行技术剖析,并详细比对各种技术架构的优缺点及适用场合。提出设计的原则、设计的思路以及设计过程中必须完成的模型,最终结合实际的案例展示了整个PowerVM的规划设计过程。希望对所有用到以及将来用到PowerVM的企业提供参考。PowerVM本身是一个复杂的技术架构,它不仅仅包括本文所涉及到的一些技术点,而且还有其他更高级的功能项(AMS、AME、企业池化等),在此基础之上,本人将继续探讨和研究一些新的技术点的应用并共享给行业内通道技术爱好者。
【参考文献】
[1]IBM Cop.<
[2]IBM Cop.<
本文作者赵海系社区专家,现于某城商银行系统规划设计中心任系统架构师,专注于银行数据中心解决方案规划及设计工作。
作者更多实用技术文章:
以上是关于基于PowerVM技术的虚拟化设计思路及优化研究的主要内容,如果未能解决你的问题,请参考以下文章