2021阿里+头条+腾讯等大厂Java笔试题分享
Posted Java范德萨
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了2021阿里+头条+腾讯等大厂Java笔试题分享相关的知识,希望对你有一定的参考价值。
前言
最近一个读者和我反馈,他坚持刷题2个月,终于去了他梦寐以求的大厂,薪资涨幅非常可观,期间面字节跳动还遇到了原题…
因为据我所知很多大厂技术面试的要求是:技术要好,计算机基础扎实,熟练掌握算法和数据结构,语言不重要,熟练度很重要。每一轮技术面试都可能考代码,不只考算法,但一定会考算法。
那你知道为什么要考算法么?其实核心是看候选人是不是足够聪明。考算法一般会分两步,第一步是直接让你说思路,第二步是让你直接上手写代码。很多大厂的算法题一般对应的是 LeetCode 中级模式,要通过面试,你肯定得花时间好好准备。
所以说算法是其中必要的一个环节!在面试中业务问题可以好好总结总结,但算法就必须依靠牢固的基础和刷题量。算法根基不扎实,不仅难过面试,对于代码性能的提升、编程语言的驾驭也会比别人弱很多。因此,现在算法基础不牢固的同学,都很难通过大厂的面试。但是只靠刷题去提升算法能力,进度太慢,而且还容易抓不住重点。
现在市面上的算法资料也五花八门,种类繁多,小编也整理了一份不同于市面且有意思的算法资料,不能说多全面,但是是小编花了很长时间整理归纳出来的,自我感觉还行。分享给同事及群里反响都不错,所以小编打算分享出来给大家,可以一起探讨完善
系统介绍
整个系统可以从功能上分为3块:
- 业务系统:在上游有很多的业务系统,业务系统的运行产生很多的数据,这些数据分散在很多的数据库中,大部分是mysql数据库
- 数据智能平台:数据智能平台属于中台系统,主要为业务系统提供强大的数据支撑服务,下层连接数仓。
- 数据仓库: 数据仓库统一集中的管理所有的数据,数仓会将业务系统产生的数据按天进行加工、抽取、转换到数据仓库存储。
当一天结束后,各个业务系统产生了大量的数据,这些数据由定时任务进行加工、抽取到数据仓库存储,当半夜你还在睡觉的时候,这些定时任务就在默默的运行着。

而每天加工的数据通常要求在上班工作时间之前加工完成,然后通过数据智能平台的查询系统供业务系统查询调用,这一次数据没有查询到是因为在第二天早上10点,数据还没有加工完成。下面就是找问题优化了,因为正常来讲,即使定时任务链再长,也不会慢到第二天10点钟数据还没有出来。下面就是找问题,然后进行优化了。
任务优化
通过任务日志发现有一个上游系统的数据抽取执行时间有3个小时,而数据量仅100万。当然,光凭这样还无法确定这个任务是否是可以被优化的。
查看任务代码,逻辑还比较简单:有一张原始数据表,记录商品信息以及定义的分类(这一点是虚构的,实际情况要复杂一些,我这里精简然后转换了一下,便于理解),而数仓的目标表是将分类和商品分别存储在不同的表中,大致结构如下。
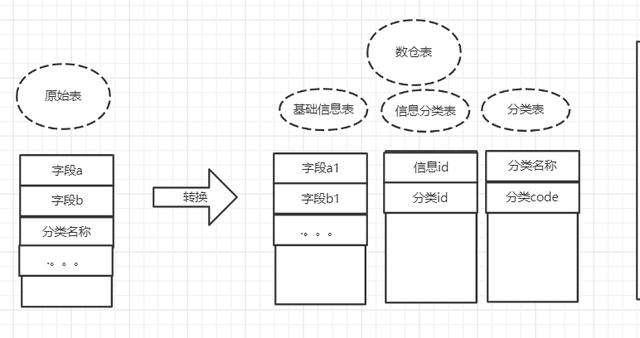
那为什么需要进行这样的转换呢? 这是因为整个大的系统,一般来说只能定义一些基本的规范,而具体的细节规范则无法约束,比如A系统的身份证字段名称为card_no,而B系统的身份证字段名称为crdt_no(这种情况大家应该经常遇到);再比如处理实体关系的时候,处理方式也是不同的,1对1的关系,可以建两张表关联,也可以一张表都存储,这就造成了多个系统的不统一性,而这种情况是不可避免的,因为从业务系统来说,都保证了系统的正常运行。
而数仓对多个原始数据处理的时候就需要考虑到兼容的问题,所以就会出现如上图的转换过程。
而这个任务执行3个小时的原因在于原始表中的一条记录,会转换到数仓表中的三张表中,而且这三张表是通过id进行关联,整个代码流程如下。

然而问题来了,100万的数据,跑了3个小时,然后我开始尝试去优化程序的执行流程,大概从一下几点入手
- 将分类缓存,分类在系统中已经固定,不会发生变化,缓存可以减少查询数据库的次数
- 每次从原表中读取的数据更多,从原来的500/次 -> 2000/次
经过优化,效率有一些提升,但并不是很明显(有同学可能要问了,这些都是很基本的,为什么最开始做? 咳咳。。。这个嘛,历史原因吧,在最开始数据可能不多,不论以什么方式执行,都差别不大,比如执行10分钟和执行20分钟,看似2倍的执行效率,但是由于没有影响到业务系统,且一直正常运行,也就没有看出问题)。
这里数据是需要关联的,所以我们是需要插入数据并拿到这条记录的自增长id,然后插入到关联表,而表结构基本不可能去动的(表结构动了那真是牵一发而动全身了,第二天准得被叫去喝茶)。

那么我们先来分析一下这里为什么执行这么慢呢。
- 原表100万的数据,每次查询出2000条,所以查询的总次数就是1000000/2000 = 500次,这肯定消耗不了多少时间。这里基本没有优化的空间,就算一次全部查询出来,也仅仅节省499次的查询时间(也不可能一次查询这么多数据)
- 查询的2000条数据,数据转换,然后依次插入到信息表以及关联表中,这里是一条一条解析执行的,总计插入数据库4000次,毫无疑问,这里是最耗时的。数据转换是必须的,而且是在内存中操作,所以耗时不是特别多;那么剩下的就是总计100万 * 2的数据库插入次数,能否进行优化呢?
首先想到的就是批量插入,批量插入可以有效的降低数据库访问次数。但是这里不能进行批量插入是因为需要取到自增长id,感觉陷入了困境。

当天晚上昨晚运动之后,抛开烦恼,觉得浑身舒坦。

突然,脑袋灵光一闪,数据库的自增长id是由数据库控制的数值,而自增长的步长我们是知道的,比如自增长步长为1,当前自增长id为1的话,那么可以肯定,下一条记录的自增长id就为2,以此类推。
那是否可以插入一条记录,取到自增长id,然后就可以计算出之后所有数据的自增长id,而不再需要每条记录都去取自增长id了。
但是这样也有一个问题,就是在数据转换导入的过程中,不能有其他的程序向表中插入数据,不然会导致程序计算的自增长id匹配不上。而这个问题根本不存在,因为数仓的数据都是由原始表计算插入的,在同一时间是没有其他的任务写这张表,那么我们就可以放心大胆的干了。
总结
阿里伤透我心,疯狂复习刷题,终于喜提offer 哈哈~好啦,不闲扯了,文章开头说要免费给大家分享我的复习资料,下面就给大家展示一下——点击这里免费获取我的复习刷题宝典

1、JAVA面试核心知识整理(PDF):包含JVM,JAVA集合,JAVA多线程并发,JAVA基础,Spring原理,微服务,Netty与RPC,网络,日志,Zookeeper,Kafka,RabbitMQ,Hbase,MongoDB,Cassandra,设计模式,负载均衡,数据库,一致性哈希,JAVA算法,数据结构,加密算法,分布式缓存,Hadoop,Spark,Storm,YARN,机器学习,云计算共30个章节。

2、Redis学习笔记及学习思维脑图
3、数据面试必备20题+数据库性能优化的21个最佳实践

24675569795)]
3、数据面试必备20题+数据库性能优化的21个最佳实践
[外链图片转存中…(img-ULyEX6xD-1624675569796)]
以上是关于2021阿里+头条+腾讯等大厂Java笔试题分享的主要内容,如果未能解决你的问题,请参考以下文章