年薪32W的学霸笔记——进程线程协程(纯干货分享)
Posted 程序员二黑
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了年薪32W的学霸笔记——进程线程协程(纯干货分享)相关的知识,希望对你有一定的参考价值。
大家好,我是二黑,这里赠送一套软件测试相关资源:
- 软件测试相关工具
- 软件测试练习集
- 深入自动化测试
- Python学习手册
- Python编码规范
- 大厂面试题和简历模板
关注我公众号:【程序员二黑】即可免费领取!
交流群:642830685
目录
进程线程协程
并发和并行
多任务
多任务可以通过多进程 多线程 协程来实现
##### 多线程实现多任务
from threading import Thread
def work1():
for i in range(100):
print(f"浇花的第{i+1}秒")
def work2():
for i in range(100):
print(f"打墙的第{i+1}秒")
#创造线程
t = Thread(target=work1)
t2 = Thread(target=work2)
# 开启线程
t.start()
t2.start()
# 等待线程执行结束后再往下执行
t.join()
t2.join()
print("执行完啦")
==============执行结果==============
浇花的第1秒
浇花的第2秒
浇花的第3秒work2
work2
work2
work2
work2
浇花的第4秒
work2
CPU和多任务的关系

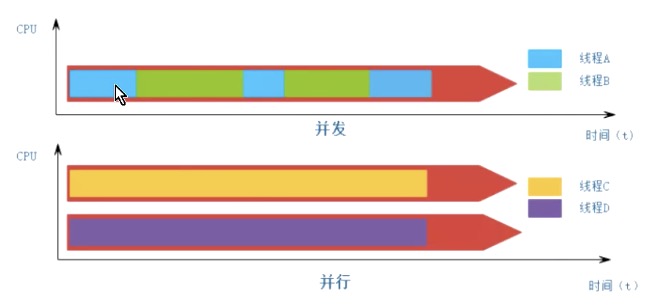
并发和并行
-
并发 指的是任务数多于CPU核数,通过操作系统的各种任务调度算法,实现用多个任务一起执行(实际上总有一些任务不在执行,因为切换任务的速度相当快,看上去一起执行而已)
-
并行 指的是任务数小于等于CPU核数,即任务真的是一起执行的
同步和异步
-
同步 是指线程在访问某一资源时,获得了资源的返回结果后才会执行其他操作(先做某件事,再做某件事)。可以理解为 进程或线程A和B一块配合,A执行到一定程度时要依靠B的某个结果,于是停下来,示意B执行,B执行后将结果给A,A再继续操作
-
异步 与同步相对,是指线程在访问某一资源时,无论是否取得返回结果,都进行下一步操作,当有了资源返回结果时,系统自会通知线程
线程
简述python线程的缺陷以及适用场景
因为有GIL锁的存在,python中的多线程在同一时间没办法同时执行(即没办法实现并行)
适用场景:涉及到网络 磁盘IO的任务都是IO密集型任务,这类任务的特点是cpu消耗很少
任务的大部分时间都在等到IO操作完成(因为IO的速度要远远低于cpu和内存的速度)
多线程创建方式一
Thread类可以用来创建线程对象
target:指定线程执行的任务(一般是任务函数)
args kwargs:接受任务函数的参数 args=("aa",) kwargs={"name":zn} name:指定线程的名字
from threading import Thread
def work1(url):
for i in range(100):
print(f"第i:{i}个url:{url}")
def work2():
for i in range(100):
print("work2")
# 创造线程
t = Thread(target=work1, args=("https:www.baidu.cpmm",), name="周诺诺的线程1")
t2 = Thread(target=work2, name="周诺诺的线程2")
# 开启线程 异步执行的状态
t.start()
t2.start()
# 默认等待子线程1执行结束
t.join() # 等待子线程t执行结束往下运行
t2.join()
# 主线程等待子线程执行结束后再往下执行
print("执行结束")
多线程创建方式二 继承类来创建线程
通过使用threading模块能完成多任务的程序开发,为了让每个线程的封装性更完美,可以通过类来封装,新建一个类,只要继承threading.Thread就可以了,然后重写run方法
说明: threading.Thread类的run方法,用于定义线程的功能函数,可以在自己的线程类中覆盖该方法,而创建自己的线程实例后,通过Thread类的start方法,可以启动该线程,交给python解释器进行调度,当该线程获得执行的机会时,就会调用run方法执行线程
一个线程类只能写一个run方法,如果有多个任务要执行,则要创建多个线程类
创建多线程执行同一个任务
from threading import Thread
class Mytread(Thread):
"""自定义的线程类"""
def __init__(self, a, b):
super().__init__() # 重写后需要调用父类init 创建线程
self.a = a
self.b = b
def run(self): # 方法名必须是run() 通过start()来调起
"""
线程执行的任务函数
:return:
"""
for i in range(1000):
print("我想要计算a+b", self.a + self.b)
# 创建100个线程
for u in range(100):
Mytread(1, 2).start()
# 创建一个线程
m = MyThread("木森)
m.start()
多线程共享全局变量
python中的多线程可以共享全局变量
缺点:但是会出现资源竞争,导致全局变量数据不准确。比如在计算时赋值还未完成,线程已经切换
操作系统如何切换py中的线程?
GIL全局解释器锁 同一时间只会执行一个线程,如果线程要执行必须要先获取全局解释器锁
1.遇到耗时等待 例如time.sleep(1)会自动释放GIL锁
2.当线程执行时间达到一定的阈值 会自动释放GIL锁
所以线程没有办法并行只能并发
from threading import Thread
n = 100
def work1():
global n
for i in range(100):
n += 1
print(f"进程{os.getpid()}work1执行玩不的值:",n)
# 在子进程里获取父进程id
print(f"子进程的父进程id:{os.getppid()}")
def work2():
global n
for i in range(100):
n += 1
t1 = Thread(target=work1)
t2 = Thread(target=work2)
# 启动线程
t1.start()
t2.start()
t1.join()
t2.join()
print(f"主进程id:{os.getpid()}")
互斥锁解决资源竞争问题
互斥锁为资源引入一个状态 锁定/非锁定
某个线程要更改共享数据时,先将其锁定,此时资源的状态为锁定,其他线程不能更改直到该线程释放资源,将资源的状态变成非锁定,其他的线程才能再次锁定该资源
互斥锁保证了每次只有一个线程进行写入操作,从而保证了多线程情况下数据的准确性
threading模块定义了Lock类,可以方便的处理锁定:
创建锁
meta = threading.Lock()
上锁
meta.acquire()
释放锁
meta.release()
注意:如果这个锁之前是没有上锁的。那么acquire不会堵塞
如果在调用acquire这个锁上锁之前 他已经被其他线程上了锁那么此时acquire堵塞,直到这个锁被解锁为止
import threading
n = 100
def work1():
global n
for i in range(100):
lock.acquire() # 上锁
n += 1
lock.release() # 解锁
def work2():
global n
for i in range(100):
lock.acquire() # 上锁
n += 1
lock.release() # 解锁
t1 = threading.Thread(target=work1)
t2 = threading.Thread(target=work2)
# 创建一把锁
lock = threading.Lock()
# 启动线程
t1.start()
t2.start()
t1.join()
t2.join()
print(n)
死锁
在线程间共享多个资源的时候,如果两个线程分别占有一部分资源并且同时等待对方的资源,就会造成死锁
尽管死锁很少发生,但一旦发生就会造成应用的停止响应
使用线程多的时候一定要避免出现死锁
import threading
n = 100
def work1():
global n
for i in range(100):
lockA.acquire()
lockB.acquire()
n += 1
lockB.release()
lockA.release()
def work2():
global n
for i in range(100):
lockB.acquire()
lockA.acquire()
n += 1
lockA.release()
lockB.release()
t1 = threading.Thread(target=work1)
t2 = threading.Thread(target=work2)
# 创建一把锁
lockA = threading.Lock()
lockB = threading.Lock()
# 启动线程
t1.start()
t2.start()
t1.join()
t2.join()
print(n)
队列
使用队列来实现线程间数据的同步,可以确保数据的安全
queue模块只能在一个进程的多个线程中使用 三种队列
1.先入先出
from queue import Queue,LifoQueue,PriorityQueue
# 初始化一个队列 默认是不限定队列的长度,也可以通过参数去指定队列中数据的最大长度
q =Queue()
q1 =Queue(maxsize=5)
#往队列中添加数据
q.put(1)
q.put(3)
q1.put(4)
print(q.qsize())
# 队列中数据满了会堵塞,等待队列中的数据少了再加 可以设置等待的超时时间
q1.put(2000, timeout=1)
# 往队列中添加数据不等待,如果队列中数据已满直接报错
q.put(2000,block=False)
# 往队列中添加数据不等待
q.put_nowait(2200)
#获取队列中的数据
print(q.get())
print(q.get())
print(q1.get())
# 获取数据 设置等待的超时时间
q.get(timeout=1)
#获取数据默认不等待如果队列中没有数据直接报错
print(q.get(block=False))
#获取数据默认不等待直接报错如果队列中是空的
print(q.get_nowait())
# 判断队列中数据是否为空,为空返回True
q.empty()
# 判断队列中数据是否已满,队列中数据已满返回True
q.full()
#获取队列中的任务数
print(q.qsize())
# join:等待队列中的任务全部执行完毕才会往下执行(不是队列为空,是队列中的所有任务都执行完,队列调用了task_done)
# 告诉队列任务执行完毕
from queue import Queue
q = Queue()
q.put(100)
q.put(200)
print(q.get())
# 每从队列中获取一个数据,要通知队列数据用完了,就会继续往下执行
q.task_done()
print(q.get())
q.task_done()
# 等待队列中的任务执行完毕(不是队列为空,是队列中所有的任务都执行完,调用了task_done)
q.join()
a = 100
print(a)
2.后入先出
q2 = queue.LifoQueue()
q2.put(1)
q2.put(11)
q2.put(12)
print(q2.get())
3.优先级队列
队列中的数据为元祖类型,元祖的第一个元素表示数据的优先级,优先级越小的越先出来
关于优先级,尽量使用数值,如果全是字符串,会按ASCII码进行排序
quene模块一个队列只能在一个进程中使用 一个进程中多个线程使用
#3.优先级 优先级最低的先出来 塞一个元祖
q3 = queue.PriorityQueue()
q3.put((11,'hh'))
q3.put((1,'heh'))
q3.put((3,'hhdddd'))
print(q3.get())
队列在多线程中的应用
相当于线程锁的作用
from queue import Queue
from threading import Thread
q = Queue()
q.put(1)
def work1():
for i in range(20):
n = q.get() # 从队列中获取数据,work1获取到了 work2便获取不到
n += 1
q.put(n) # 把数据送回队列
def work2():
for i in range(20):
n = q.get()
n += 1
q.put(n)
t = Thread(target=work1)
t2 = Thread(target=work2)
t.start()
t2.start()
t.join()
t2.join()
print("n:", q.get())
进程
进程是操作系统资源分配的基本单位,一个进程中可以有多个线程
线程:线程是操作系统任务调度的基本单位
多个进程可以同时进行
每个进程之间资源是独立的
进程和线程对比
功能
进程 能够完成多任务,比如在一台电脑上能够同时运行多个软件
线程 能够完成多任务,比如一个qq中的多个聊天窗口
定义的不同
进程是系统进行资源分配和调度的一个独立单位
线程是进程的一个实体,是CPU调度和任务分派的基本单位,它比进程更小的能独立运行的基本单位。线程自己基本上不拥有系统资源,只拥有一点在运行中必不可少的资源,但是它可与同属一个进程的其他线程共享进程所拥有的全部资源
python中同一个进程中的线程 是没办法并行的(GIL),进程是可以并行的,不同进程中的线程也是可以并行的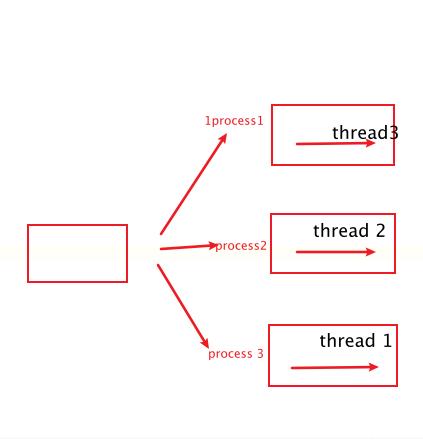
from multiprocessing import Process
def work1(name):
for i in range(20):
print(f"{name}在浇花")
def work2(name):
for i in range(20):
print(f"{name}在做饭")
t = Process(target=work1, args=("jerry",))
t2 = Process(target=work2, args=("jerry",))
t.start()
t2.start()
t.join()
t2.join()
多进程不可共享全局变量
Python 多进程默认不能共享全局变量,因为进程的资源是独立的
主进程与子进程是并发执行的,进程之间默认是不能共享全局变量的(子进程不能改变主进程中全局变量的值)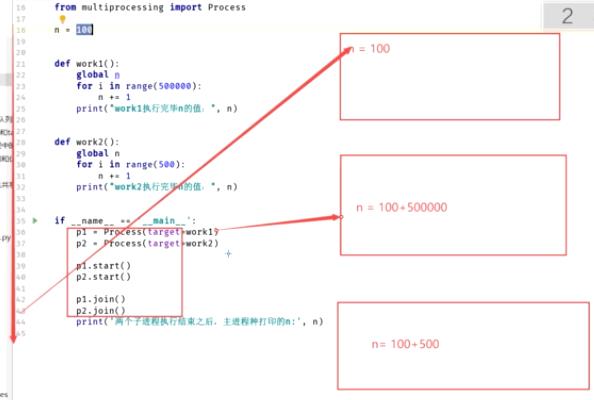
from multiprocessing import Queue, Process
n = 100
def work1():
global n
for i in range(50000):
n += 1
print("work1执行完后n", n)
def work2():
global n
for i in range(500):
n += 1
print("work2执行完后n", n)
t = Process(target=work1)
t2 = Process(target=work2)
t.start()
t2.start()
t.join()
t2.join()
print("两个子进程执行完后主进程中n的值:", n)
=============执行结果=================
work1执行完后n:50100
work2执行完后n:600
两个子进程执行完后主进程中n的值:100
多进程之间通信
进程之间通信:使用队列
multiprocessing.Queue:可以多个进程之间共用(通用)跨进程通讯 队列要在主进程中创建 当成参数传给子进程
queue.Queue模块只能在一个进程中使用 一个进程中多个线程使用
from multiprocessing import Queue, Process
def work1(q): # 要把队列当成参数传进来
for i in range(5000):
n = q.get()
n += 1
q.put(n)
print("work1 n执行后的值", q.get())
def work2(q): # 要把队列当成参数传进来
for i in range(5000):
n = q.get()
n += 1
q.put(n)
print("work2 n执行后的值", q.get())
if __name__ == '__main__':
# 队列要在主进程中创建 当成参数传给子进程
q = Queue()
q.put(100)
t = Process(target=work1, args=(q,))
t1 = Process(target=work2, args=(q,))
t.start()
t1.start()
t.join()
t1.join()
print("两个子进程执行结束后,主进程打印的n", q.get())
=============执行结果=================
work1 n执行后的值 9015
work2 n执行后的值 10100
两个子进程执行结束后,主进程打印的n 10100
通过继承自定义进程类
from multiprocessing import Process, Queue
import requests
"""
创建4个进程发送100个请求
"""
class Myprocess(Process):
def __init__(self, q):
super().__init__() # 重写后需要调用父类init 创建线程
self.q = q
def run(self): # 方法名必须是run() 通过start()来调起
"""
线程执行的任务函数
:return:
"""
while not self.q.empty():
# 当队列中不为空时即进行下面操作
url = self.q.get()
requests.get(url)
print(f"发送请求:{url}")
# 打印进程id
print(f"{self.pid}")
# 创建队列
q = Queue()
# 创建一个100个url放进队列里
for u in range(100):
url = 'https://www.baidu.com'
q.put(url)
q_list = []
# 开4个进程执行100个url
for i in range(4):
p = Myprocess(q)
q_list.append(p)
p.start()
for i in q_list:
i.join()
获取进程id
from multiprocessing import Process
import os
n = 100
def work1():
global n
for i in range(500000):
n += 1
print(f"进程{os.getpid()}work1执行完毕n的值:", n)
print(f"子进程的父进程id:{os.getppid()}")
def work2():
global n
for i in range(500):
n += 1
# 获取子进程id
print(f"进程{os.getpid()}work2执行完毕n的值:", n)
# 获取子进程里的父进程id
print(f"子进程的父进程id:{os.getppid()}")
if __name__ == '__main__':
p1 = Process(target=work1)
p2 = Process(target=work2)
p1.start()
p2.start()
p1.join()
p2.join()
print('两个子进程执行结束之后,主进程打印的n:', n)
# 获取主进程id
print(f"主进程获取id:{os.getpid()}")
进程和队列使用实例
import time
from multiprocessing import Process, Queue
"""
一、使用队列和进程完成下面要求
1、用一个队列来存储数据
2、创建一个专门生产数据的进程类,当队列中数据数量少于50时,开始生产数据,每次生产200个数据,添加到队列中,每生产完一轮 暂停1秒
3、创建一个专门获取数据的进程类,当 队列中数据数量 大于10时就开始获取,,循环获取,每次获取20个。当 队列中数据数量 少于10的时候,暂停2秒
4、 创建一个进程生产数据 ,5个进程获取数据
"""
class Produce(Process):
"""
生产商品进程类
"""
def __init__(self, q):
super().__init__()
self.q = q
def run(self):
# 当队列中数据数量<50时开始生产数据
if self.q.qsize() < 50:
for i in range(200):
self.q.put(i)
time.sleep(1)
class Consumer(Process):
"""
获取数据进程类
"""
def __init__(self, q):
super().__init__()
self.q = q
def run(self):
if self.q.qsize() >= 10:
for i in range(20):
self.q.get()
self.q.task_done()
else:
time.sleep(2)
def main():
q = Queue()
# 创建一个生产数据进程
p = Produce(q)
p.start()
p.join()
# 创建5个消费数据进程
q_list = []
for i in range(5):
C = Consumer(q)
C.start()
q_list.append(C)
for i in q_list:
i.join()
if __name__ == '__main__':
main()
协程
协程又称微线程,是python中另外一种实现多任务的方式,只不过比线程更小占用更小执行单元(理解为需要的资源)。为啥说他是一个执行单元,因为它自带CPU上下文,这样只要在合适的gr时机,我们可以把一个协程切换到另一个协程。只要这个过程中保存或恢复CPU上下文那么程序还是可以运行的
通俗的描述
协程是线程中的一个特殊的函数,这个函数执行的时候,可以在某个地方暂停,并且可以重新在暂停处继续运行,协程在进行切换的时候,只需要保存当前协程函数中的一些临时变量信息,然后切换到另外一个函数中执行,并且切换的次数以及什么时候再切换回原来的函数,都由开发者自己决定。 协程切换的时候既不涉及到资源切换们也不涉及到操作系统的调度,而是在同一个程序中切换不同的函数执行,所以协程占用的资源非常少,切换的时候几乎不耗费什么资源,一秒钟切换个上万次系统都扛得住。
所以说协程与进程 线程相比不是一个维度的概念
原生的协程实现多任务 一般不用(了解)
协程函数的定义和调用
async 加在def前面定义协程函数
await:只能写在协程函数中 await后面必须是一个可等待对象(协程 任务 asyncio.sleep()
async def work1():
for i in range(10):
print(f"work1---浇花--{i}")
# 调用协程函数,创建一个协程对象
cor1 = work1()
# 执行协程
asyncio.run(cor1)
# 原生协程实现多任务
# 定义一个协程函数
import asyncio
async def work1():
for i in range(10):
print(f"work1---浇花--{i}")
await asyncio.sleep(1) # 协程中切换必须要添加等待 await.sleep()
async def work2():
for i in range(10):
print(f"work1---打枪--{i}")
await asyncio.sleep(1) # 协程中切换必须要添加等待 await.sleep()
# 定义一个启动函数
async def run():
# 调用协程函数,返回的是一个协程对象
cor1 = work1()
cor2 = work2()
# 把协程创建成任务
task1 = asyncio.create_task(cor1)
task2 = asyncio.create_task(cor2)
task3 = asyncio.create_task(work1())
task4 = asyncio.create_task(work2())
await task1
await task2
await task3
await task4
if __name__ == '__main__':
m = run()
asyncio.run(m)
greenlet模块实现多任务 一般不用(了解)
为了更好的使用协程来完成多任务,python中的greenlet模块对其封装,从而使得切换任务变得简单,只能手动去切换
import greenlet
import time
def work1():
for i in range(6):
time.sleep(1)
cor2.switch() # 手动切换
print(f"浇花的第{i + 1}次")
def work2():
for i in range(6):
time.sleep(1)
cor1.switch() # 手动切换
print(f"打枪的第{i + 1}次")
cor1 = greenlet.greenlet(work1)
cor2 = greenlet.greenlet(work2)
# 调用switch方法才会执行, 通过switch切换到这个协程中去
cor1.switch()
gevent模块 使用协程要使用的模块
gevent模块又对greenlet进行了一层封装
当程序遇到io耗时等待的时候 会自动进行切换
gevent中默认是遇到gevent.sleep()会进行切换
如果让gevent遇到io自动切换,节省运行时间 需要在程序的导包处加一个monkey补丁,注意:只能在单线程中用,不支持多线程 加了monkey补丁 遇到time.sleep也会自动切换
from gevent import monkey monkey.patch_all() 两行代码要在文件的最上层引入
线程的切换:耗时io操作 网络磁盘 input output 协程切换:遇到io操作
from gevent import monkey
monkey.patch_all()
import gevent
import time
def work1():
for i in range(6):
gevent.sleep(1) # 遇到gevent.sleep才会自动切换
print(f"浇花的第{i + 1}次")
def work2():
for i in range(6):
gevent.sleep(1)
print(f"打枪的第{i + 1}次")
# 创建两个协程
g1 = gevent.spawn(work1)
g2 = gevent.spawn(work2)
#线程等待协程执行结束再往下执行
#gevent中是遇到gevent.sleep()会自动进行切换
g1.join()
g2.join()
=============================创建5000个协程请求url===============================
def timeit(func):
"""
计算耗时装饰器
:param func:
:return:
"""
def wrapper(*args, **kwargs):
s_time = time.time()
func(*args, **kwargs)
e_time = time.time()
print('此程序耗时:', e_time - s_time)
return wrapper
# 10000个请求
urls = ["https:www.baidu.com" for i in range(10000)]
def work3():
while urls:
url = urls.pop()
# gevent.sleep(0.5) # gevent中是遇到gevent.sleep()会自动进行切换
requests.get(ulr,timeout=1) # 如果让gevent遇到io自动切换,节省运行时间 需要在程序的导包处加一个monkey补丁
print(f"正在请求url:{url}")
# 创建5000个协程
@timeit
def main():
cor_list = []
for i in range(5000):
cor = gevent.spawn(work3)
cor_list.append(cor)
for i in cor_list:
i.join()
main()
进程线程协程对比
进程 线程 协程对比
1.进程是资源分配的单位,
2.线程是操作系统调度的单位
3.协程又名微线程,存在于线程之中
4.进程切换需要的资源最大效率很低
5.线程切换需要的资源一般效率一般当然在不考虑G I L锁的情况下。
6.协程切换任务资源很小,效率高
7.多进程多线程。根据C P U核数不一样,只有多进程能实现并行,但是协程是在一个线程中,所以是并发
8.注意点Python中的线程由于GIL锁的存在,并不能够实现并行,要充分利用多核C P U还是需要使用进程来做。
协程:协程又称微线程
进程池
当需要创建的子进程数量不多时,可以直接利用multiprocessing中的Process动态生成多个进程,但如果是成百甚至上千个目标,手动的去创建进程的工作量巨大,此时就可以用到multiprocessing模块提供的pool方法
初始化Pool时,可以指定一个最大进程数,当有新的请求提交到Pool中时,如果池还没有满,那么就会创建一个新的进程用来执行请求,但是如果池中的进程数已经达到指定的最大值,那么该请求就会等待,直到池中有进程结束,才会用之前的进程来执行新的任务,
import time
from multiprocessing import Pool
def work1(name):
for i in range(3):
time.sleep(1)
print(f"{name}:------work1----{i}-")
def main():
# 创建一个拥有5个进程的线程池
po = Pool(5)
# 往进程池添加4任务 当任务数超过进程数数时,会先按照最大进程数来执行,执行完后,空出来的进程会继续执行
# po.apply_async(work1, ("musen1",))
# po.apply_async(work1, ("musen1",))
# po.apply_async(work1, ("musen1",))
# po.apply_async(work1, ("musen1",))
# po.apply_async(work1, ("musen1",))
# po.apply_async(work1, ("musen1",))
for i in range(20):
po.apply_async(work1, ("musen1",))
# 关闭进程池(进程池停止接收任务)
po.close()
# 主进程等待进程池中的任务结束在往下执行
po.join()
if __name__ == '__main__':
main()
进程池之间的队列
进程池和进程池之间进行通讯使用进程池里的队列
进程池的Queue 如果要使用Pool创建进程,就需要使用multiprocessing.Manager().Queue()
而不是multiprocessing.Queue(),否则会报错
import time
from multiprocessing import Pool,Manager
def work1(name,q): # 队列要作为参数传入
for i in range(3):
time.sleep(1)
print(f"{name}:------work1----{i}----{q.get()}")
def main():
# 创建一个用于进程池通讯的队列
q = Manager().Queue()
for i in range(1000):
q.put(f"data-{i}")
# 创建一个拥有5个进程的线程池
po = Pool(5)
for i in range(20):
po.apply_async(work1, ("musen1",q)) # 队列要作为参数传入
# 关闭进程池(进程池停止接收任务)
po.close()
# 主进程等待进程池中的任务结束在往下执行
po.join()
if __name__ == '__main__':
main()
concurrent.futures实现进程池 线程池
import time
from concurrent.futures import ThreadPoolExecutor, ProcessPoolExecutor
def work1(name, age):
for i in range(3):
time.sleep(1)
print(f"{name}:------work1----{age}---")
# ThreadPoolExecutor模块实现了上下文管理器协议
# 创建一个线程池,开启5个线程
with ThreadPoolExecutor(max_workers=5) as f:
f.submit(work1, "musen1", 18)
f.submit(work1, "musen2", 20)
f.submit(work1, "musen3", 23)
f.submit(work1, "musen4", 50)
# 创建一个进程池,开启5个进程 windows要在__main__下面运行
with ProcessPoolExecutor(max_workers=5) as ts:
ts.submit(work1, "nuonuo", 18)
ts.submit(work1, "nuonuo", 18)
ts.submit(work1, "nuonuo", 18)
ts.submit(work1, "nuonuo", 18)最后为方便大家学习测试,特意给大家准备了一份13G的超实用干货学习资源,涉及的内容非常全面。
包括,软件学习路线图,50多天的上课视频、16个突击实战项目,80余个软件测试用软件,37份测试文档,70个软件测试相关问题,40篇测试经验级文章,上千份测试真题分享,还有2021软件测试面试宝典,还有软件测试求职的各类精选简历,希望对大家有所帮助……
关注我公众号:【程序员二黑】即可获取这份资料了!
以上是关于年薪32W的学霸笔记——进程线程协程(纯干货分享)的主要内容,如果未能解决你的问题,请参考以下文章