别人家的几G面经怎么获取的?爬虫一键爬取即可,躺好直接看!!!
Posted Code皮皮虾
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了别人家的几G面经怎么获取的?爬虫一键爬取即可,躺好直接看!!!相关的知识,希望对你有一定的参考价值。
前言
博主 常年游荡于牛客面经区,总结了字节、阿里、百度、腾讯、美团等等大厂的高频考题,但是今天,我教大家如何进行面经爬取,如果能帮到各位小伙伴,麻烦一件三连多多支持,感激不敬!!!
本次爬取以Java面经为例,学会的小伙伴可以按照规律爬取牛客任意面经


教学
进入Java面经区,打开控制台刷新请求
可以发现,发送浏览器中的URL,得到的响应内容是没有面经的,那么面经的数据从何而来???不要着急,那么多请求我们接着看!
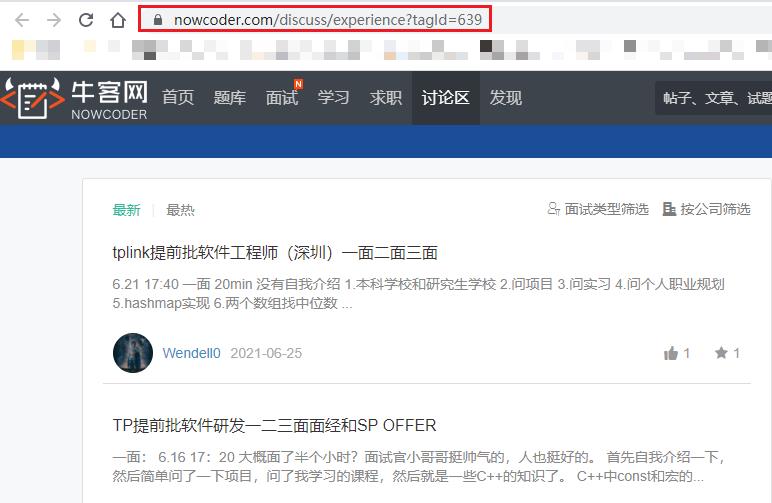
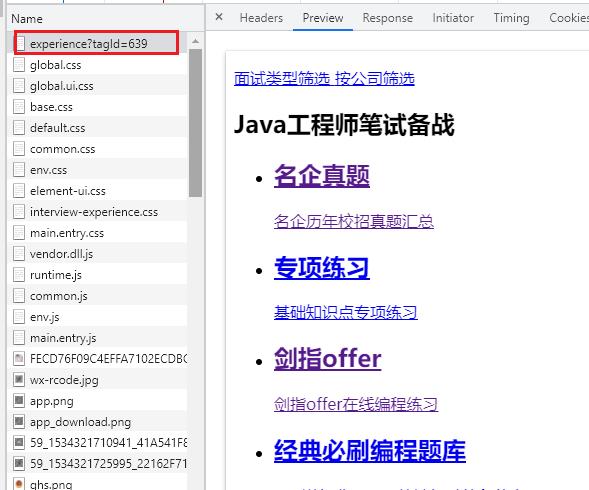
往下滑,可以看见带json的请求,经验告诉我就是这个请求
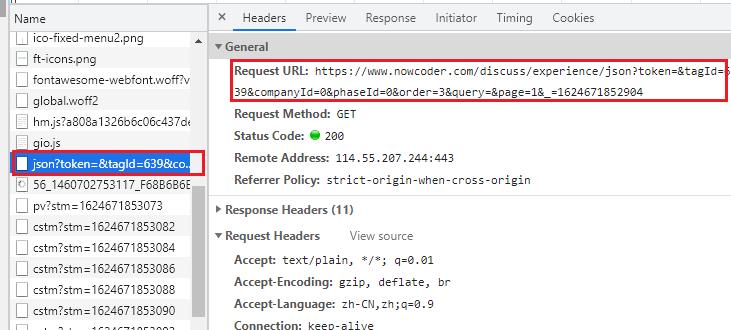
复制该URL,我们去浏览器请求该URL,可发现我们得到了面经的数据

但是,面经是JSON格式,我们可以复制到在线json解析工具去查看,如下

可以看到data下的discussPosts下保存着所有的帖子即面经信息
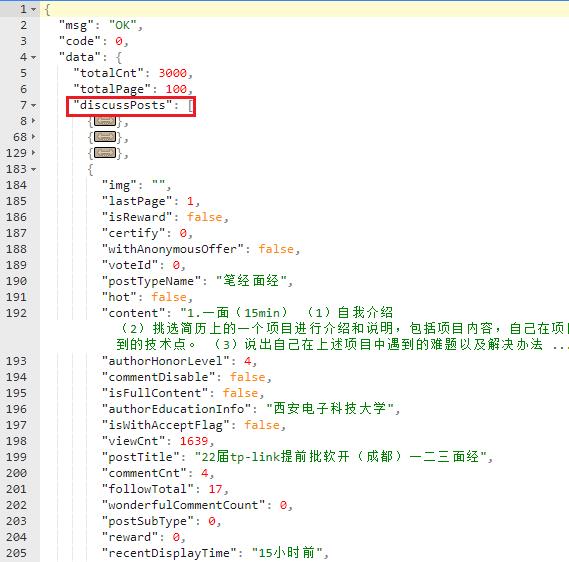
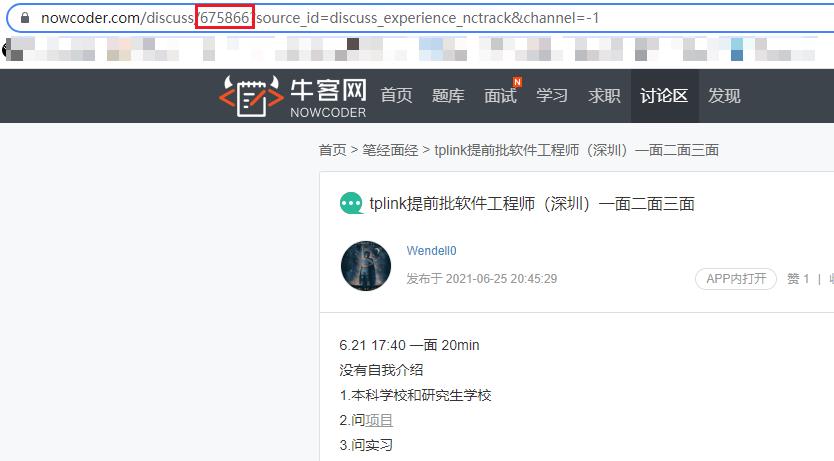
但是这个json不像我以前见到的,这个json串没有直接保存帖子详情页的URL,但是我们可以提供过访问路径发现规律

可以看见访问路径有个675866,就是对应json串中的postId,而后面的参数是可以省略的
小技巧
想必单页面经是肯定不能满足各位小伙伴的,那么如果进行多页爬取呢,不要着急,我来为大家总结规律,也希望小伙伴们能一键三连哦!!!

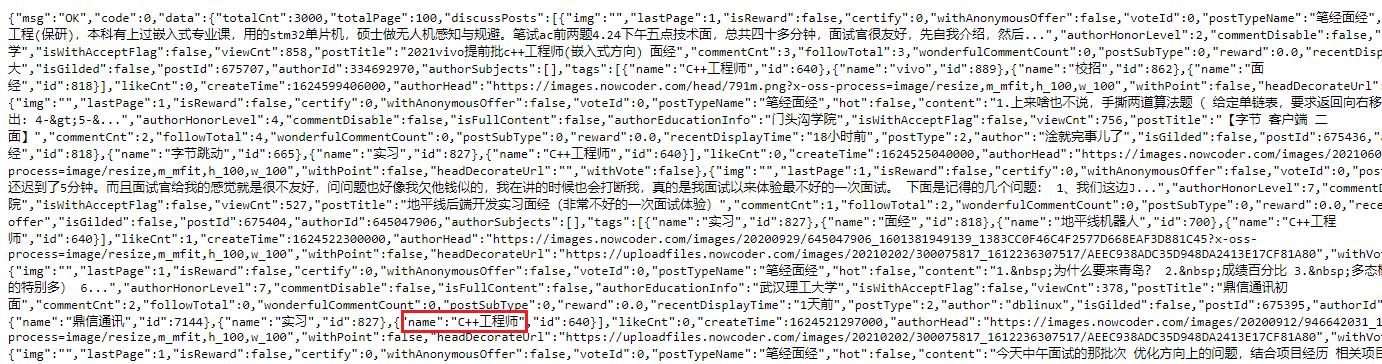
一样的套路,如下图是C++区域的面经JSON字符串,应该不用我多教了吧
完整代码
如果有新手,可以看看我的爬虫教学索引哦,练完包你熟练掌握!!!
import requests
import json
import os
from bs4 import BeautifulSoup
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (Khtml, like Gecko) Chrome/91.0.4472.114 Safari/537.36"
}
path = "./面经"
symbol_list = ["\\\\", "/", "<", ":", "*", "?", "<", ">", "|","\\"","&"]
#替换掉标题字符,因为如果有这些字符是不能保存到txt中的
def replaceTitle(title):
for i in symbol_list:
if title.find(str(i)) != -1:
title = title.replace(str(i)," ")
return title
#获取详情页URL
def getDetail_Url(tmp_path,json_str):
discussPosts = json_str['data']['discussPosts']
for discussPost in discussPosts:
title = discussPost['postTitle']
detail_url = "https://www.nowcoder.com/discuss/" + str(discussPost['postId'])
detail_response = requests.get(url=detail_url,headers=headers)
getDetailData(tmp_path,title,detail_response)
#请求详情页获取数据
def getDetailData(tmp_path,title,detail_response):
detailData = BeautifulSoup(detail_response.text,"html.parser")
div_data = detailData.find(class_="post-topic-main").find_all("div")
title = replaceTitle(title)
print("正在保存" + tmp_path + ":" + title)
with open(tmp_path + "/" + title + ".txt",'w',encoding='utf-8') as f:
for i in div_data:
try:
#遇到class为clearfix的标签即可跳出循环,因为需要的数据都已经获取到了,该标签下的数据是不需要的
if i['class'].count('clearfix') != 0:
break
except:
pass
tmp_text = i.text.strip('\\n').strip()
f.write(tmp_text + "\\n")
f.close()
# 开始
if __name__ == '__main__':
url = "https://www.nowcoder.com/discuss/experience/json?token=&tagId=639&companyId=0&phaseId=0&order=3&query=&page=1"
for i in range(1,3):
url = url + str(i)
if not os.path.exists(path):
os.mkdir(path)
tmp_path = path + "/第" + str(i) + "页面试题"
if not os.path.exists(tmp_path):
os.mkdir(tmp_path)
response = requests.get(url=url,headers=headers)
json_str = json.loads(response.text)
getDetail_Url(tmp_path,json_str)
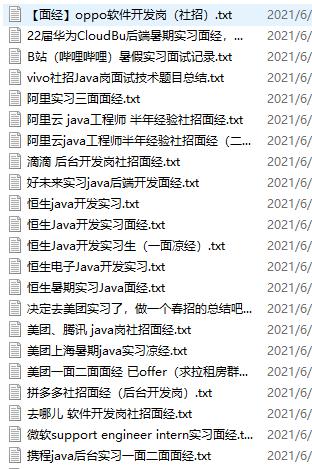
结果展示


CSDN独家福利降临!!!
最近CSDN有个独家出品的活动,也就是下面的《Python的全栈知识图谱》,路线规划的非常详细,尺寸 是870mm x 560mm 小伙伴们可以按照上面的流程进行系统的学习,不要自己随便找本书乱学,要系统的有规律的学习,它的基础才是最扎实的,在我们这行,《基础不牢,地动山摇》尤其明显。
最后,如果有兴趣的小伙伴们可以酌情购买,为未来铺好道路!!!
最后
我是 Code皮皮虾,一个热爱分享知识的 皮皮虾爱好者,未来的日子里会不断更新出对大家有益的博文,期待大家的关注!!!
创作不易,如果这篇博文对各位有帮助,希望各位小伙伴可以一键三连哦!,感谢支持,我们下次再见~~~
分享大纲
更多精彩内容分享,请点击 Hello World (●’◡’●)
以上是关于别人家的几G面经怎么获取的?爬虫一键爬取即可,躺好直接看!!!的主要内容,如果未能解决你的问题,请参考以下文章