IO流基础基础运用
Posted 烟锁迷城
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了IO流基础基础运用相关的知识,希望对你有一定的参考价值。
1、IO流的基础定义
IO代表input和output,即输入和输出,流代表一种无结构化的传输方式。输入代表将文件写入java程序,输出代表从java程序写入文件。
2、IO流的分类
在java程序中的IO流有非常多的实现类,但核心只分为五种:File,InputStream,OutputStream,Reader,Writer
| 分类 | 字节输入流 | 字节输出流 | 字符输入流 | 字符输出流 |
|---|---|---|---|---|
| 抽象基类 | InputStream | OutputStream | Reader | Writer |
| 访问文件 | FileInputStream | FileOutputStream | FileReader | FileWriter |
| 访问数组 | ByteArrayInputStream | ByteArrayOutputStream | CharArrayReader | CharArrayWriter |
| 抽象基类 | PipedInputStream | PipedOutputStream | PipedReader | PipedWriter |
| 访问字符串 | StringReader | StringWriter | ||
| 缓冲流 | BufferedInputStream | BufferedOutputStream | BufferedReader | BufferedWriter |
| 转换流 | InputStreamReader | OutputStreamWriter | ||
| 抽象基类 | FilterInputStream | FilterOutputStream | FilterReader | FilterWriter |
| 打印流 | PrintStream | |||
| 推回输入流 | PushbackInputStream | PushbackReader | ||
| 特殊流 | DataInputStream | DataOutputStream |
字节流:操作的数据单元是8位的字节,InputStream,OutputStream作为抽象基类
字符流:操作的数据单位是字符,Writer,Reader作为抽象基类
3、基础实现
示例中,read方法是一个字节一个字节进行读取的,当读到结束时,会返回-1,以此为判断循环结束的标准。
public static void main(String[] args) {
FileInputStream fileInputStream = null;
try {
fileInputStream = new FileInputStream("C:/Users/lichong/Desktop/test.txt");
int i;
while ((i = fileInputStream.read())>0){
System.out.print((char) i);
}
}catch (Exception e){
e.printStackTrace();
}
}
4、数据来源及对应的API
I/O流的操作来源主要来自于四个,分别是磁盘,内存,键盘,网络
4.1、磁盘
磁盘的读取就如上面的示例,使用FileInputStream来读取文件,在构造中放入文件的路径即可。
4.2、内存
内存同样可以读取,使用ByteArrayInputStream来读取
4.3、键盘
键盘输入数值也可以进行读取
public static void main(String[] args) {
try {
InputStream inputStream = System.in;
int i;
while ((i = inputStream.read())>0){
System.out.print((char) i);
}
}catch (Exception e){
e.printStackTrace();
}
}
4.4、网络
网络是在不同的电脑中进行通讯,主要使用的是socket
5、File文件操作
file类是为文件进行创建,删除,重命名,移动等操作设计的一个类,属于java.io的包,有四个构造方法
- file(File parent,String child):根据parent抽象路径名和child路径名字符串创建一个新的file实例
- file(String pathname):将指定路径名转化为抽象路径名创建一个新的file实例
- file(String parent,String child):根据parent路径名和child路径名创建一个file实例
- file(URI uri):指定URI转化为抽象路径名
6、输入输出字节流的使用
6.1、文件的输入输出字节流使用
用字节流进行文件输入输出的示例如下
在实例中,增加了缓冲区byte[] bytes = new byte[1024];,缓冲区可以让原本每个字节都会写入磁盘的操作减少为数次缓冲区写入,也就是说,缓冲区会先将准备写入磁盘的数据缓冲起来,等到缓冲区满再一次写入磁盘。
public static void main(String[] args) throws IOException {
File file = new File("E:/test/lxh.jpg");
FileInputStream fileInputStream = new FileInputStream(file);
FileOutputStream fileOutputStream = new FileOutputStream("E:/test/lxhh.jpg");
int len = 0;
byte[] bytes = new byte[1024];
while ((len = fileInputStream.read(bytes)) != -1) {
fileOutputStream.write(len);
fileOutputStream.write(bytes,0,len);
}
fileInputStream.close();
fileOutputStream.close();
}
流在使用过后一定要关闭,不然文件就会一直处于占用之中,无法被其他程序使用。为了防止忘记关闭流或者频繁地关闭流,java7新增了一个语法,当流被trycatch包裹时,流会被自动关闭,但是这个流一定要实现Closeable接口才能被关闭。
read方法的作用是从输入流中读取字节,如果read方法没有读到输入,就会阻塞。read有一个返回值,返回下一个数据的字节,如果已经读取到文件的最后一个字节,read会返回一个-1。
write方法的作用是将文件流写入磁盘,如果将每一个字节直接写入磁盘,会导致频繁的写入操作,所以采用缓冲区的方式,填满缓冲区后一次性写入,可以减少磁盘写入压力。outputStream.write(bytes);。但是这样直接使用缓冲区会有问题,就是在覆盖前一个缓冲区内的数据时,如果最后一次无法填满缓冲区,就会导致有错误的数据停留在缓冲区内,因此要额外增加一个范围,保证缓冲区的数据是正确的。
缓冲区的大小要合适,比如1024,不是越大越好,因为缓冲区本身保存在内存中,太大的缓冲区反而会拖慢速度。
6.2、内存的输入输出字节流使用
对于内存数据而言,同样可以被读取
public static void main(String[] args) {
try {
ByteArrayInputStream inputStream = new ByteArrayInputStream("helloworld".getBytes());
ByteArrayOutputStream outputStream = new ByteArrayOutputStream();
int i = 0;
while ((i = inputStream.read())!=-1){
char c = (char) i;
outputStream.write(Character.toUpperCase(c));
}
System.out.println(outputStream.toString());
}catch (Exception e){
e.printStackTrace();
}
}
6.3、缓冲流的输入输出字节流使用
缓冲流是带缓冲区的处理流,它会提供一个缓冲区,缓冲区的作用主要是避免每次和硬盘打交道,能够提高输入输出的执行效率。
BufferedInputStream附带一个8kb大小的缓冲数组,也可以自定义缓冲区大小,它主要用来装饰其他输入流,提供缓冲。
BufferedOutputStream同样用来装饰其他输出流。
public static void main(String[] args) {
try {
BufferedInputStream inputStream = new BufferedInputStream(new FileInputStream(""));
BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream(""));
int len = 0;
byte[] bytes = new byte[1024];
while ((len = inputStream.read(bytes)) != -1) {
outputStream.write(bytes, 0, len);
outputStream.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
在每次循环的结束,都会调用一个flush方法,这个方法的作用是避免缓冲区还没有写满,不触发磁盘写入导致数据缺失,调用flush方法会触发刷盘,将缓冲区数据写入磁盘内。
如果不写flush方法,调用close方法关闭流也可以触发刷盘,因为在源码中,close方法同样调用了flush方法。
在上面的示例中,try catch可以起到自动关闭流的作用。
public void close() throws IOException {
try (OutputStream ostream = out) {
flush();
}
}
7、输入输出字符流的使用
7.1、文件的输入输出字符流使用
在计算机内部,一个汉字字符等于三个字节长度,按照字节流读取必然会出现乱码问题,因此想要正确读取,就要使用字符流
字符流和字节流的使用方式很接近,只是要做一个替换即可。
public static void main(String[] args) {
try {
FileReader fileReader = new FileReader("");
FileWriter fileWriter = new FileWriter("");
int len = 0;
char[] chars = new char[1024];
while ((len = fileReader.read(chars))!=-1){
fileWriter.write(chars,0,len);
}
} catch (Exception e) {
e.printStackTrace();
}
}
7.2、字符转化流
在编码格式不一致的情况下,会发生文件内容的乱码,字符转化流可以指定编码格式,修正乱码,也可以作为字节流和字符流转化的工具。
字符转换流修饰其他的数据流,可以添加参数编码格式,如果不添加,就按照编译器的默认格式。
在示例中,使用了缓冲流提升性能,在BufferedReader 中有一个很好的方法,readLine,可以读取一行的数值,
public static void main(String[] args) {
try {
BufferedInputStream inputStream = new BufferedInputStream(new FileInputStream("C:/Users/ASUS/Desktop/test.txt"));
BufferedReader reader = new BufferedReader(new InputStreamReader(inputStream, "UTF-8"));
BufferedOutputStream outputStream = new BufferedOutputStream(new FileOutputStream("C:/Users/ASUS/Desktop/test1.txt"));
BufferedWriter writer = new BufferedWriter(new OutputStreamWriter(outputStream, "UTF-8"));
int len = 0;
char[] chars = new char[1024];
while ((len = reader.read(chars)) != -1) {
writer.write(chars, 0, len);
writer.flush();
}
String s = null;
while ((s = reader.readLine()) != null) {
writer.write(s);
writer.flush();
}
} catch (Exception e) {
e.printStackTrace();
}
}
8、序列化与反序列化
- 序列化:将对象状态信息转化为可存储或传输形式的过程,也就是把对象转化为字节序列的过程成为对象的序列化
- 反序列化:是序列化的逆向过程,把字节数组反序列化为对象,把字节序列恢复为对象的过程称为对象的反序列化
ObjectOutputStream和ObjectInputStream是序列化和反序列化的两个数据流,序列化可以让类的生命周期远远大于jvm的生命周期。
需要注意的是,想要序列化的类需要实现Serializable接口。
public static void main(String[] args) {
User user = new User();
try {
ObjectOutputStream outputStream = new ObjectOutputStream(new FileOutputStream("E:/user"));
outputStream.writeObject(user);
ObjectInputStream inputStream = new ObjectInputStream(new FileInputStream("E:/user"));
user = (User)inputStream.readObject();
System.out.println(user);
} catch (Exception e) {
e.printStackTrace();
}
}
9、IO流的底层原理
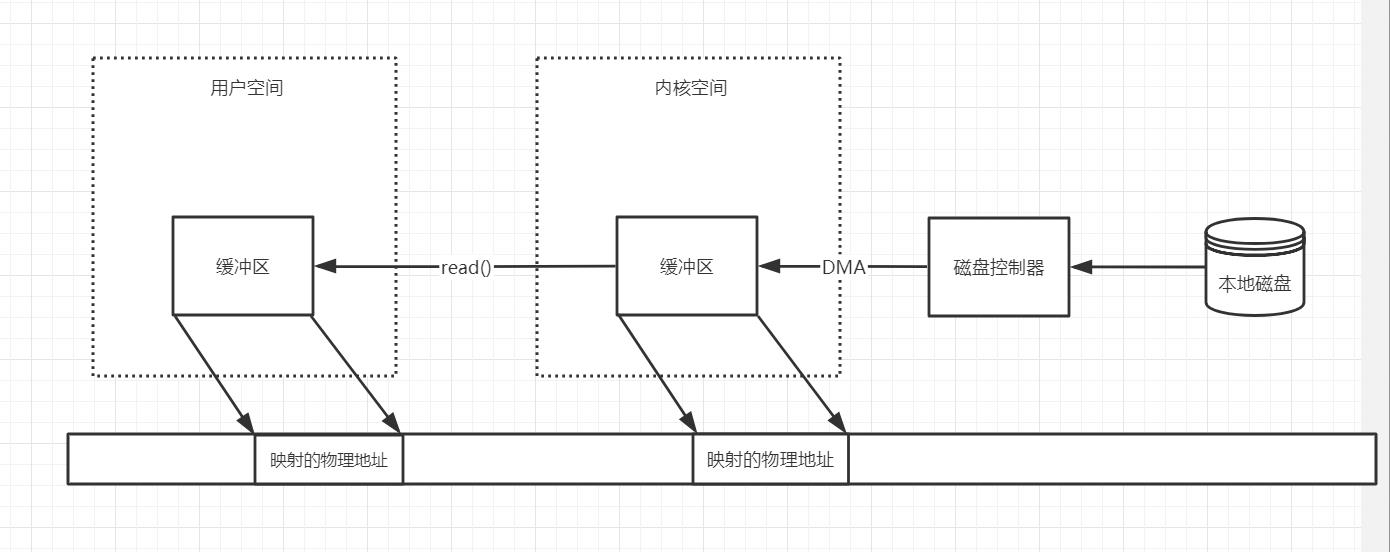
当read命令被发起,进程会向用户空间的缓冲区请求数据,如果用户空间的缓冲区为空,就会向内核空间的缓冲区请求数据,内核空间会向磁盘控制器发起指令,要求磁盘从指定的空间读取数据放到内核空间的缓冲区。磁盘控制器会通过DMA访问,直接将数据写入内核空间的缓冲区中,一旦内核空间缓冲区被填写完成,数据将被发送到用户空间缓冲区,进程就可以读取到数据。
这里的缓冲区和缓冲流的缓冲区并无区别,都是将数据暂存到缓冲区,读取数据时会从缓冲区进行读取,减少磁盘交互。
内核空间的缓冲区除了减少磁盘交互之外,内核空间一般不会直接从磁盘读取,这样的数据隔离能保证系统安全。如果内核空间的缓冲区没有用户空间缓冲区需要的数据,那么这个请求会被放到一个队列里挂起,这就是阻塞,直到数据已经读取到内核空间缓冲区,然后数据被复制到用户空间缓冲区,这时才会唤醒挂起线程,重新运行。
在数据写入时也会在缓冲区写入,缓冲区写满后被写入磁盘,这样会带来一个风险,就是在计算机宕机时,可能会导致缓冲区数据丢失。
- read操作:将数据从内存缓冲区复制到用户缓冲区
- write操作:将数据从用户缓冲区复制到内存缓冲区,通过磁盘控制器写入磁盘
- 缓冲IO:使用缓冲区的IO被称为缓冲IO,它在一定程度上分离了用户空间和内核空间,保护了系统本身的运行安全。它减少了系统磁盘读取次数以提升性能。但是磁盘控制器在进行DMA时,会通过页缓存进行反复多次的数据复制,这对于性能是很大的开销
以上是关于IO流基础基础运用的主要内容,如果未能解决你的问题,请参考以下文章
java内存流:java.io.ByteArrayInputStreamjava.io.ByteArrayOutputStreamjava.io.CharArrayReaderjava.io(代码片段