万字长文实战分析MySQL死锁
Posted Javachichi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了万字长文实战分析MySQL死锁相关的知识,希望对你有一定的参考价值。
前言
本文先完整介绍mysql的各种锁类型及加锁机制,之后通过一个案例带大家了解如何分析排查死锁问题。最后,再介绍几种预防死锁的方法。
以下是示例表的表结构
CREATE TABLE `t_user` (
`id` int NOT NULL AUTO_INCREMENT,
`name` varchar(128) NOT NULL COMMENT '姓名',
`age` int NOT NULL COMMENT '年龄',
`score_rank` int NOT NULL COMMENT '排名',
PRIMARY KEY (`id`),
UNIQUE KEY `uniq_idx_score_rank` (`score_rank`),
KEY `idx_age` (`age`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8
表数据:

分析的存储引擎是innodb,事务隔离级别默认为可重复读。数据库版本为 8.0.25。
各类锁介绍
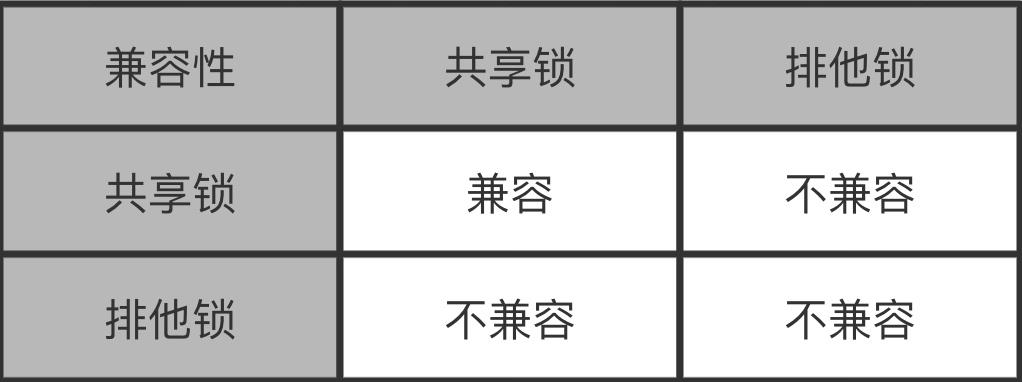
共享锁和排他锁
共享锁又称读锁,在数据库中表示为S锁,多个事务可以对同一数据添加共享锁,即共享锁之间不互斥。
排他锁又称写锁,在数据库中表示为X锁,同一时刻只有一个事务能对一个数据添加排他锁。即排他锁与其他X锁和S锁都互斥。对于被添加了排他锁的数据,只有持有该锁的事务才能对其进行加锁读和写操作。同时,一个事务想要修改数据前,必须先对加排他锁才能进行修改。
值得注意的是,并不是说一个数据加了排他锁后,其他事务就无法读取了。数据库查询数据分为快照读和当前读。
往下继续前,我们需先了解两个知识点:
-
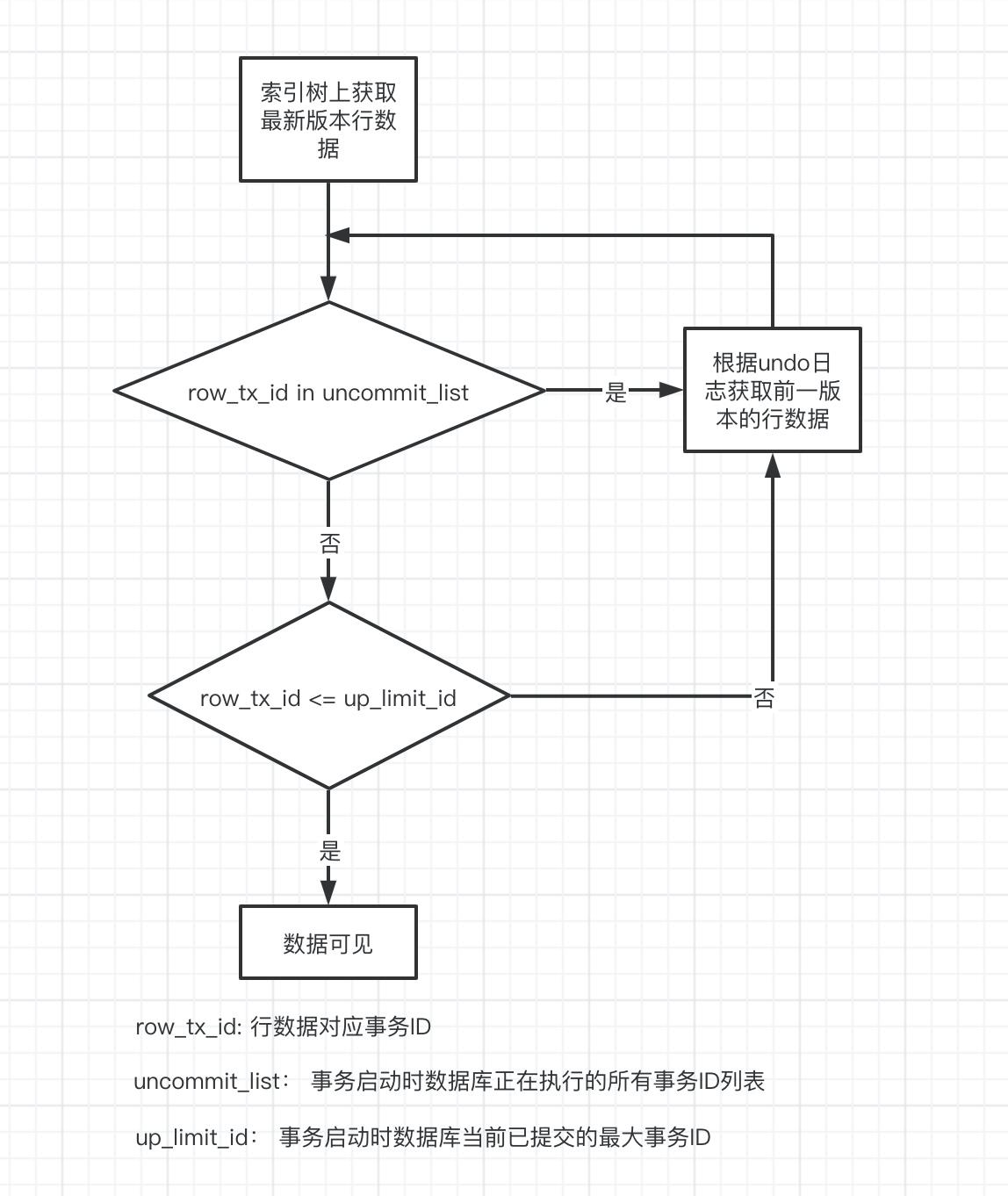
在事务启动时,会对数据库当前事务状态打个快照,可以简单理解为找到当前已提交的最大事务ID记为up_limit_id,并保存“现在正在执行的所有事务ID列表” - uncommit_list。
-
数据库中对于每一行都会通过undo日志实现记录多个数据版本,每个版本都有对应改动的事务ID。
快照读是指不加锁查询,只能读取事务启动时已完成提交的数据版本。查询时,先从索引树上获取到指定数据,然后检查数据当前版本是否可见,如果不可见,获取数据的前一个版本,再检查可见性。

可以发现,数据在被一个事务加排他锁进行修改期间,其他事务仍然可以对其进行不加锁读取。同时,当session2中的事务commit后,session1中的语句4使用快照读仍无法读取到最新版本的数据。
如果想要查询数据最新版本,可使用当前读。当前读需要加锁,可以加读锁(select … lock in share mode),也可以加写锁(select … for update)。
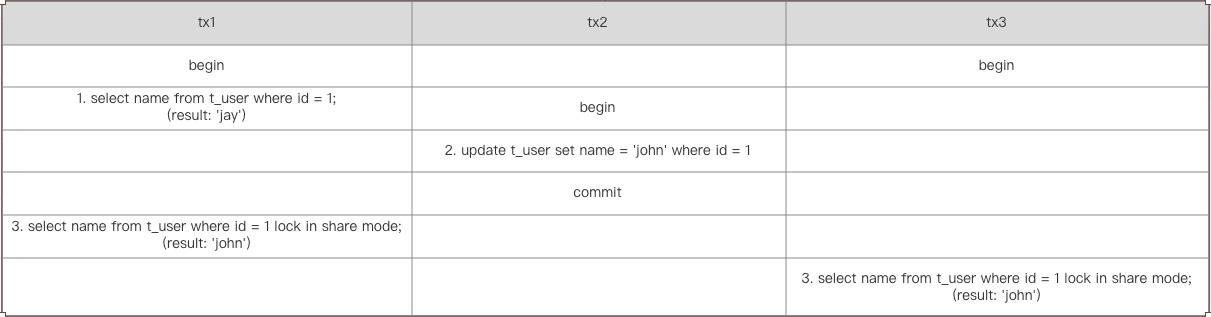
tx1中的语句3,使用当前读的方式查询,获取到tx2更新的最新版本的数据,由于语句3加的是读锁,所以tx3也可以加读锁读取最新数据。
select ... lock in share mode和select ... for update除了加锁的类型不同,有时候加锁的范围也有所不同:
-
select id from t_user where age = 20 lock in share mode: 加读锁当前读,mysql通过普通索引idx_age就能过滤并筛选出想要的字段(id), 无需回表到主键索引查询。所以只会在普通索引idx_age上加读锁。 -
select id from t_user where age = 20 for update: 加写锁当前读,mysql认为接下来会对满足条件的行进行修改,所以除了会对普通索引idx_age加写锁,同时也会对主键索引对应行上加写锁。
表级锁和行级锁
根据加锁的粒度不同可分为表级锁和行级锁:
- 表锁对整张表进行加锁,加锁粒度大,容易发生锁冲突,并发性能低
- 行锁对一行数据进行加锁,加锁粒度较小,发生锁冲突概率较小。并发性能高。
表锁和行锁又能分为表共享锁/表互斥锁、行共享锁/行互斥锁。
意向锁
上小节讲到innodb支持多粒度的锁。而共享锁与排他锁是互斥的。当一个事务想要对表添加表级共享锁时,需要保证:
- 当前没有其他事务持有表的排他锁。
- 当前没有其他事务持有表中任意一行的排他锁。
为了满足第二个要求,如果去遍历检查表中每一行数据的加锁情况,效率明显是很差的。所以,mysql引入了意向锁。
首先说明,意向锁是属于表级别的锁。意向锁也分共享意向锁(IS)和排他意向锁(IX)。比较特殊的是,共享意向锁(IS)和排他意向锁(IX)之间不互斥,都是相互兼容的。

同时,意向锁跟行级锁之间也是相互兼容的。

意向锁主要作用在表锁上。

意向锁是innodb自己维护的,用户无法手动操作意向锁。当事务需要加行共享(排他)锁时,会先自动在所在表添加共享(排他)意向锁。
当事务需要添加表锁,比如要添加表级共享锁时,检查的条件改为:
- 检查当前没有其他事务持有表的排他锁。
- 检查当前没有其他事务持有表的意向排他锁。
如果其他事务持有意向排他锁,证明此时表的某些行被加了排他锁,而无需去遍历检查表的每一行。效率明显提高。
间隙锁(Gap Locks)
思考以下操作顺序的结果:

再复习一遍select ... for update的意思:对满足条件的行加锁,然后把满足条件的最新版本数据全部查询出来。
如果tx2的语句2能正常插入,那tx1的语句3结果有两种:
-
返回[{id: 1, name: ‘jay’, age: 20, score_rank: 1}, {id:4, name: ‘ning’, age: 20, score_rank: 4}], 但是语句1明明已经对
age=20的行都加了锁。为什么前后两次的当前读会不一样呢?会给人一种锁不住的感觉,这称为幻读。 -
返回[{id: 1, name: ‘jay’, age: 20, score_rank: 1}], 这个结果是与语句1一样了。但违反了当前读的语义:读取当前最新版本的数据。
所以语句2是不允许插入的。但语句1该加什么锁才能阻塞语句2呢?只加行锁肯定是不行的,因为语句1加锁的时候无法预知后面有age=20的插入。直接对整个表加锁又会大大降低了数据库的并发性。
为此mysql引入了间隙锁(gap lock), 顾名思义,间隙锁的加锁对象是数据间的间隙。以t_user表数据为例,主键索引上数据的间隙有(-∞, 1), (1, 2), (2, 3), (3, +∞);普通索引idx_age上的间隙有(-∞, 15), (15, 20), (20, 30), (30, +∞); 唯一索引uniq_idx_score_rank有间隙(-∞, 1), (1, 2), (2, 3), (3, +∞)。
间隙锁与区间右侧的行锁构成了next-key lock。即(-∞, 1], (1, 2], (2, 3], (3, +∞]。 大多数情况下,加锁是以next-key lock为基本单位。
少数情况next-key lock会退化为行锁或间隙锁
间隙锁之间是不冲突的,即多个事务可同时对同一个间隙添加间隙锁。因为多个事务添加间隙锁的目的都是保护这个间隙不允许插入新值。
结合间隙锁,我们分析上面的操作结果。语句1除了会添加age=20的行锁外,还会添加间隙锁(15, 20)和(20, 30), 即添加了next-key lock (15, 20]和间隙锁(20, 30)。
tx2的语句2插入时,发现要插入的地方被间隙锁保护着,导致插入阻塞。
next-key锁加锁规则
在讲解加锁规则前,我们先学习如何查看数据库的加锁情况。 不同Mysql版本的查看地方不同,5.8以下可通过表INFORMATION_SCHEMA.INNODB_LOCKS查看;5.8可通过表performance_schema.data_locks查看。两张表的字段大致相同,以下分析均通过5.8版本的performance_schema.data_locks。
performance_schema.data_locks主要字段:
- ENGINE_LOCK_ID: 持有或请求的锁的ID
- ENGINE_TRANSACTION_ID: 请求锁定的事务ID
- THREAD_ID: 事务对应线程ID,关联
performance_schema.threads可以获取线程详细信息 - OBJECT_SCHEMA: 对应锁表的schema名称
- OBJECT_NAME: 对应锁的表名
- INDEX_NAME: 锁对应的索引名称
- LOCK_TYPE: 对应的锁类型,对InnoDB而言,可为表锁(TABLE)或者行锁(RECORD)
- LOCK_MODE: 锁模式,重点!!
- S: LOCK_TYPE=TABLE时,表示表级共享锁;LOCK_TYPE=RECORD, 表示行级共享锁和间隙锁构成的next-key lock
- S, GAP: 间隙锁
- S, REC_NOT_GAP: 行级共享锁
- IS: 意向共享锁
- X: LOCK_TYPE=TABLE时,表示表级排他锁;LOCK_TYPE=RECORD, 表示行级排他锁和间隙锁构成的next-key lock
- X, GAP: 间隙锁
- X, REC_NOT_GAP: 行级排他锁
- X,GAP,INSERT_INTENTION: [插入意向锁](# 插入意向锁)。
- IX: 意向排他锁
- LOCK_STATUS: 锁状态,GRANTED: 已获取;WAITING: 等待获取
- LOCK_DATA: 锁对应的数据,如果锁定的是主键索引,值为加锁的主键值;锁定的是非主键索引,值为[索引值, 对应主键值]。

查询过程中访问到的区间,索引项和数据记录都会被加锁
相信大家还记得select ... lock in share mode和select ... for update由于覆盖索引导致加锁范围的差异。同样的,如果select ... lock in share mode不需要回表查主键索引,也不会在主键上添加间隙锁.
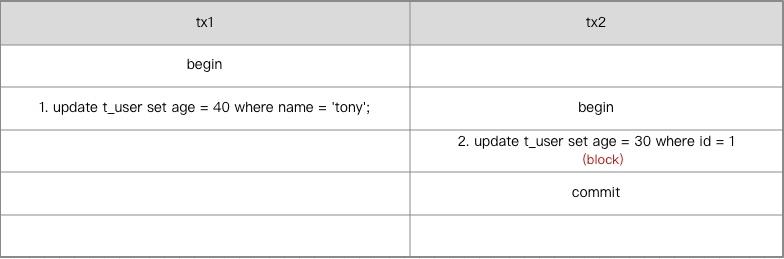
有一种情况需要重点关注下,当查询未命中任何索引时,需要进行全表扫描,此时会对主键索引上所有间隙和所有行数据都加上锁。变相的加上了表级锁。会严重影响并发。
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6eFbMC5h-1624583924136)(https://p3-juejin.byteimg.com/tos-cn-i-k3u1fbpfcp/9e2d99b290754c64b0b7380c038fce72~tplv-k3u1fbpfcp-zoom-1.image)]
从performance_schema.data_locks可发现,tx1中的语句1查询时进行了全表遍历,将(-∞, 1], (1, 2], (2, 3], (3, +∞] 都加了锁,所以tx2的更新语句在获取id=1的行锁时会被阻塞。
等值查询,普通索引查询加锁分析
以下是语句select * from t_user where age = 20 for update的加锁情况。
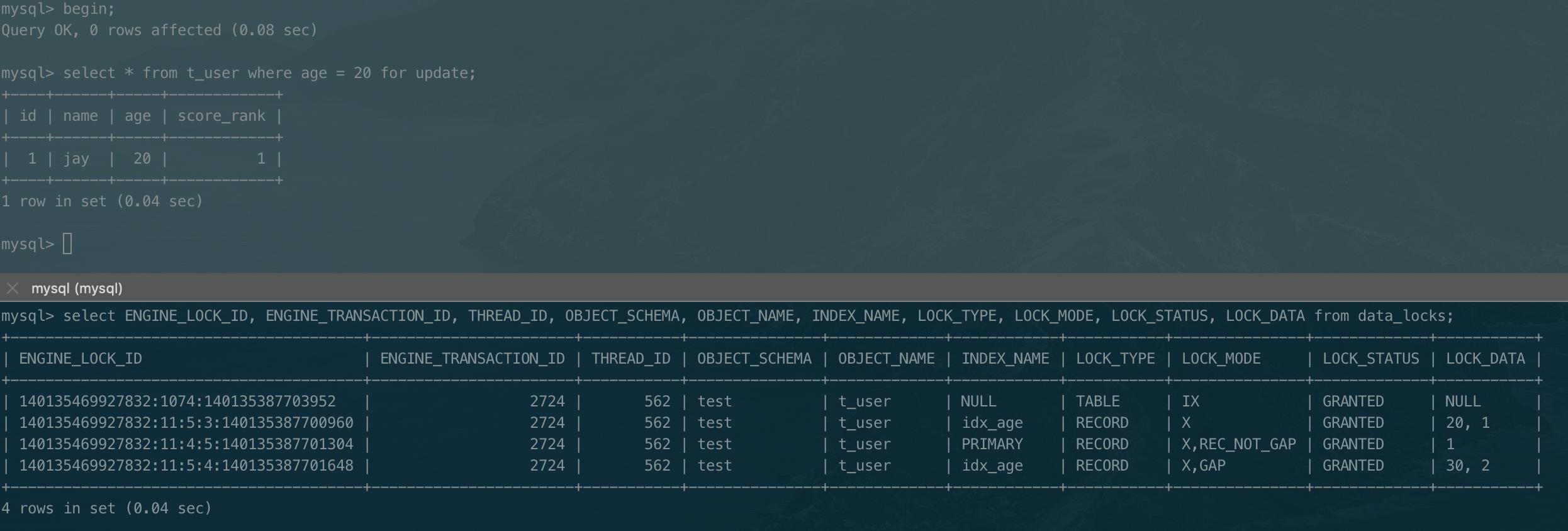
可以发现,先在普通索引上查询,从age = 20开始遍历,一直向右直到找到第一个不满足条件的行记录为止。满足条件的行会添加next-key lock, 即(15, 20]; 对于最后遍历到的不满足条件的行,会退化为间隙锁(20, 30)。
普通索引上查到满足条件的索引后,会到主键索引上回表查询,因为回表时需要查询的主键是确定的,所以主键上不需要间隙锁,只是添加对应行锁。
普通索引上为什么需要添加往右接邻的间隙锁?
首先,非主键索引树上的索引排序是先按索引字段排序,之后再按主键排序,即
idx_age上的索引排序为<15, 3> -> <20, 1> -> <30, 2>, 如果,现在插入一行记录{id: 4, name: ‘zhangsan’, age: 20, score_rank: 5},idx_age的索引顺序会变成<15, 3> -> <20, 1> -> <20, 4> -> <30, 2>, 即新插入的索引是在原来间隙(20, 30)之间的。
等值查询,唯一索引查询加锁分析
以下是语句select * from t_user where score_rank = 1 for update;的加锁情况。
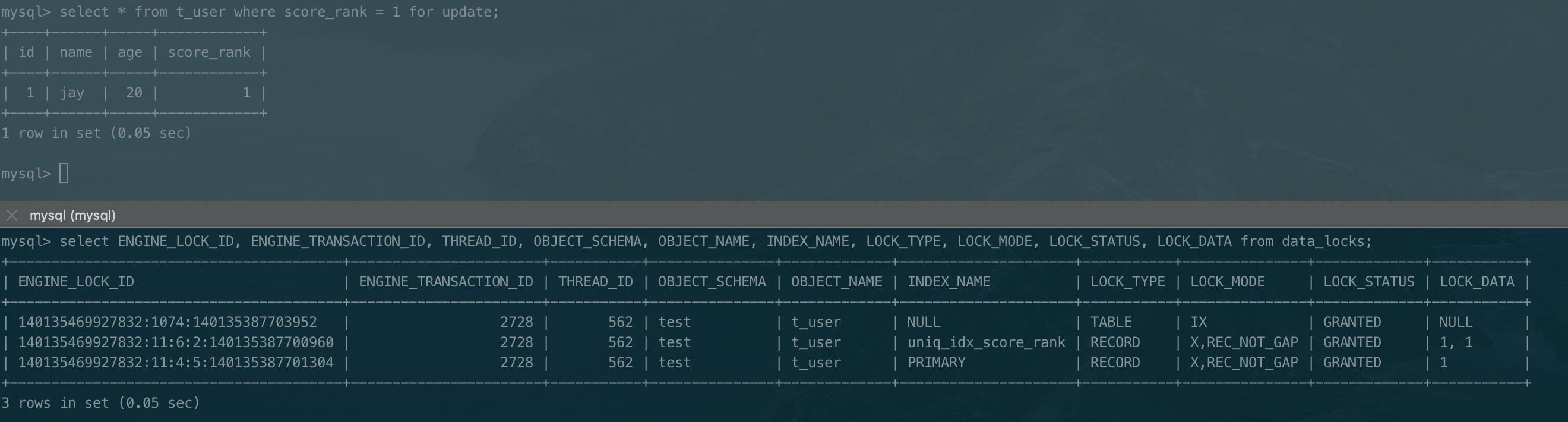
查询走的是唯一索引uniq_idx_name, 与普通索引相比,唯一索引只是在满足条件的行上加行级排他锁。原因在于唯一索引的唯一性,不会有相同值的索引,因此等值查询时不需要担心幻读。
范围查询,普通索引加锁分析
以下是语句select * from t_user where age > 13 and age <= 20 for update 加锁情况
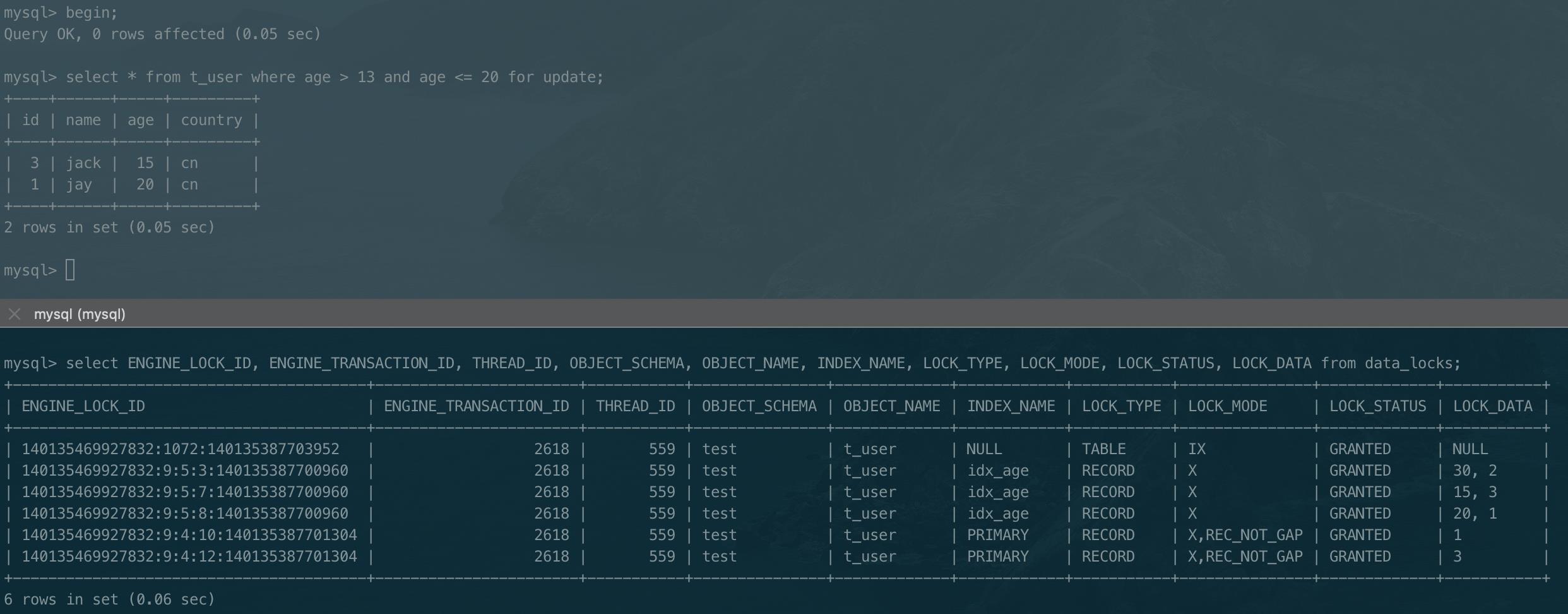
可以发现,普通索引上添加了(-∞, 15], (15, 20], (20, 30]三个next-key lock,对于(20,30]为何不会退化为间隙锁没太理解,欢迎同学留言分享。
需要注意的是,虽然查询条件是age > 13 and ..., 但由于此时索引上没有(13, 15)间隙,所以,会直接将间隙(-∞,15)全部锁起来,这会阻塞其他事务插入age <= 13记录。
范围查询,唯一索引加锁分析
以下是语句select * from t_user where score_rank > 1 and score_rank < 3;加锁情况。
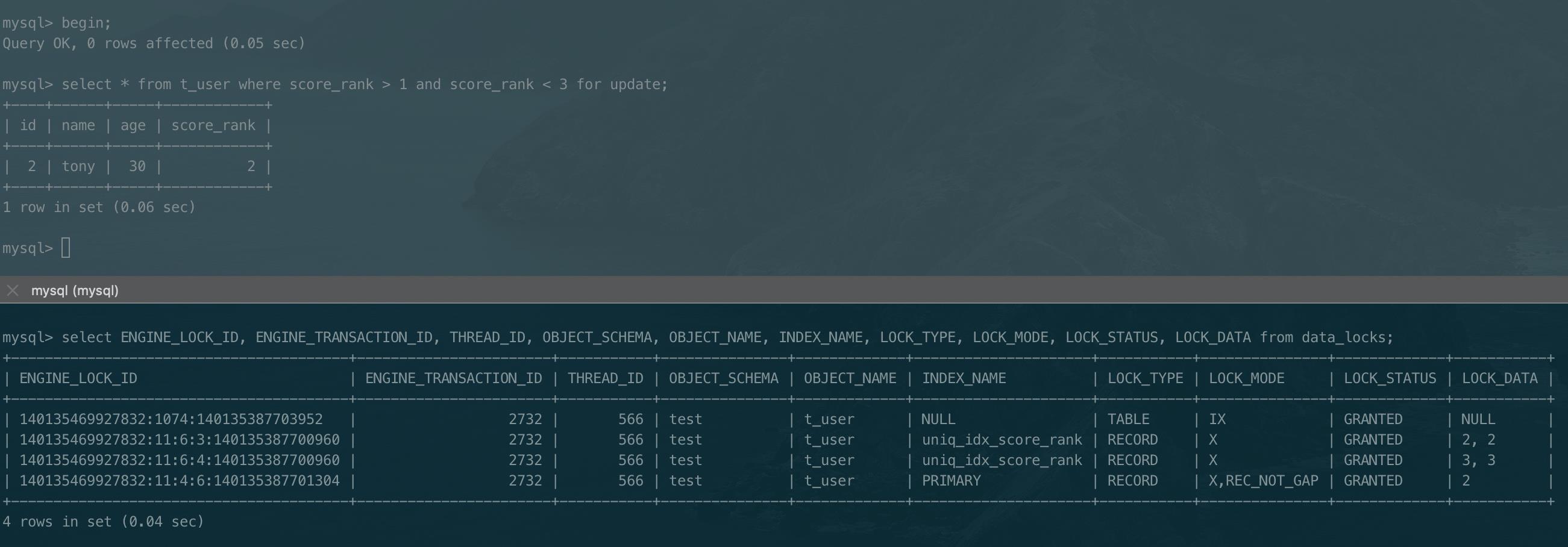 分析:略。
分析:略。
next-key lock是间隙锁和行锁加起来的结果
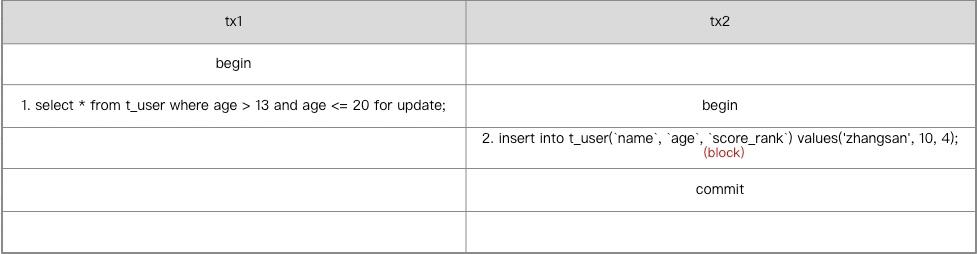
next-key lock加锁时分两步,先加间隙锁,再加行锁。 下面我们通过一个例子来说明这个结论。
 分析上面两个事务的执行情况(仅看普通索引
分析上面两个事务的执行情况(仅看普通索引idx_age的加锁情况):
-
tx1的语句1添加next-key lock (15, 20]和间隙锁(20, 30)。
-
tx2的更新语句2执行时,同样需要加next-key lock (15, 20]和间隙锁(20, 30)。 next-key lock加锁分两步走:先添加间隙锁(15, 20), 成功;由于
age=20的行X锁已经被tx1持有,所以tx2获取时会阻塞。 -
由于tx2阻塞在获取
age=20行X锁的步骤上,并未持有间隙锁(20, 30), 所以tx1的语句3可以成功插入。 -
tx1的插入语句4执行时发现tx2持有间隙锁(15, 20),陷入等待。此时tx1等待tx2释放间隙锁(15, 20); tx2等待tx1释放
age=20的行锁,死锁检测检测到死锁,直接将tx2回滚,所以tx1的语句4得以成功执行。
当一个事务需要获取锁受阻进入等待时,会根据参数
innodb_lock_wait_timeout决定等待的时间,默认是50s。如果发生死锁,相关事务都陷入等待,直到其中一个超时退出,其他事务再继续执行。请求阻塞50s, 这对于线上服务明显是不能接受的。针对死锁,mysql提供了
死锁检测,默认开启(innodb_deadlock_detect = on), 当检测到死锁时,数据库会主动回滚某一个事务,让其他事务得以继续执行。
插入意向锁
事务插入一行新数据,当检测到插入的目标区间当前没有间隙锁时,会先往区间添加插入意向锁。插入意向锁本质上是一种间隙锁。锁的对象也是数据/索引的间隙。
插入意向锁的目的是表明要往某个区间插入新数据的意图。与之前介绍的间隙锁保护间隙避免插入新值的目的是相反的,所以插入意向锁与间隙锁是互斥的。
为了提高插入并发,相同区间的插入意向锁不互斥。比如两个事务可以并发向idx_age索引的(20, 30)区间插入新数据而不会互相阻塞。
为什么需要插入意向锁,而不是检查到目标区间没有间隙锁便直接执行插入?这个问题在官方文档上没找到答案,也没有阅读过源码,这里仅说下个人观点:"检查是否有间隙锁"和"执行插入"不是原子性,为了避免在检查间隙锁和插入数据之间有新间隙锁添加,添加插入意向锁表明这个区间即将有新数据插入,阻塞其他事务获取新间隙锁。
MDL锁
上面介绍的锁的加锁对象都是数据本身或数据间隙。都属于数据锁,还有一种添加在元数据上的锁 - MDL(meta data lock), MDL也分读锁和写锁。
MDL不需要显示使用,在进行表操作时会自动加上。当对表进行增删改查时,会自动加上MDL读锁;当要对表进行加减字段的结构修改时,会自动加上MDL写锁。
读锁不互斥,意味着可以多个线程同时对一张表进行增删改查的操作。 写锁独占,进行结构修改前,要先等待其他所有的MDL锁释放了才能获取到MDL写锁。获取到写锁后,在写锁释放前,其他线程无法获取到MDL读锁和写锁。也就是说,修改一个表的结构过程中,会阻塞其他线程对表的操作。
MDL是为了保证数据的一致性。想象一下,假如没有MDL锁,一个查询在遍历表数据的过程中,另外一个线程执行了ALTER TABLE t DELETE COLUMN 'col_1'把col_1这一列删掉了,那查询结果就乱了,结果中是否应该有这一列数据?
死锁实战排查分析
死锁发生时,排查可以分两步走:分析死锁日志 -> 验证猜想。
分析死锁日志
主要通过命令show engine innodb status, 分析输出内容中LATEST DETECTED DEADLOCK部分,这里会记录数据库最后一次死锁中相关事务阻塞语句和锁的等待/持有情况。
------------------------
LATEST DETECTED DEADLOCK
------------------------
1. 2021-06-18 09:13:45 140135015667456
2. *** (1) TRANSACTION:
3. TRANSACTION 4965, ACTIVE 135 sec starting index read
4. mysql tables in use 1, locked 1
5. LOCK WAIT 5 lock struct(s), heap size 1136, 4 row lock(s)
6. MySQL thread id 2428, OS thread handle 140134872839936, query id 24616 111.206.145.52 root updating
7. update t_user set score_rank = 10 where id = 2
8. *** (1) HOLDS THE LOCK(S):
9. RECORD LOCKS space id 11 page no 5 n bits 72 index idx_age of table `test`.`t_user` trx id 4965 lock mode S
10. Record lock, heap no 1 PHYSICAL RECORD: n_fields 1; compact format; info bits 0
11: 0: len 8; hex 73757072656d756d; asc supremum;;
12. Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
13. 0: len 4; hex 8000001e; asc ;;
14. 1: len 4; hex 80000002; asc ;;
15. *** (1) WAITING FOR THIS LOCK TO BE GRANTED:
16. RECORD LOCKS space id 11 page no 4 n bits 80 index PRIMARY of table `test`.`t_user` trx id 4965 lock_mode X locks rec but not gap waiting
17. Record lock, heap no 6 PHYSICAL RECORD: n_fields 6; compact format; info bits 128
18. 0: len 4; hex 80000002; asc ;;
19. 1: len 6; hex 000000001361; asc a;;
20. 2: len 7; hex 020000023202a0; asc 2 ;;
21. 3: len 4; hex 746f6e79; asc tony;;
22. 4: len 4; hex 8000001e; asc ;;
23. 5: len 4; hex 80000002; asc ;;
24. *** (2) TRANSACTION:
25. TRANSACTION 4966, ACTIVE 177 sec inserting
26. mysql tables in use 1, locked 1
27. LOCK WAIT 4 lock struct(s), heap size 1136, 2 row lock(s), undo log entries 1
28. MySQL thread id 2427, OS thread handle 140134885521152, query id 24617 111.206.145.52 root update
29. insert into t_user (`name`, `age`, `score_rank`) values ('zhangsan', 25, 4)
30. *** (2) HOLDS THE LOCK(S):
31. RECORD LOCKS space id 11 page no 4 n bits 80 index PRIMARY of table `test`.`t_user` trx id 4966 lock mode S locks rec but not gap
32. Record lock, heap no 6 PHYSICAL RECORD: n_fields 6; compact format; info bits 128
33. 0: len 4; hex 80000002; asc ;;
34. 1: len 6; hex 000000001361; asc a;;
35. 2: len 7; hex 020000023202a0; asc 2 ;;
36. 3: len 4; hex 746f6e79; asc tony;;
37. 4: len 4; hex 8000001e; asc ;;
38. 5: len 4; hex 80000002; asc ;;
39. *** (2) WAITING FOR THIS LOCK TO BE GRANTED:
40. RECORD LOCKS space id 11 page no 5 n bits 72 index idx_age of table `test`.`t_user` trx id 4966 lock_mode X locks gap before rec insert intention waiting
41. Record lock, heap no 4 PHYSICAL RECORD: n_fields 2; compact format; info bits 0
42. 0: len 4; hex 8000001e; asc ;;
43. 1: len 4; hex 80000002; asc ;;
44. *** WE ROLL BACK TRANSACTION (2)
1: 记录死锁发生时间,可以通过这个时间戳与项目报错日志匹配。
3 & 25: 记录事务ID及事务存活时长
5 & 27: N row lock(s)表示事务持有了多少锁(注意不仅是行锁,还包括持有的表级意向锁等), undo log entries N 表示该事务有多少条undo log,可以变相理解为事务执行了多少条插入/删除/更新语句。通过undo log数量的多少可以推断事务的复杂性,帮助我们定位项目中事务代码位置。
6 & 28: thread id 表示事务所在的thread, 每个连接会对应一个thread_id, 与performance_schema.processlist中的id一致(processlist存储的是当前未断连接列表,所以可能找不到死锁事务的thread_id); 后面的111.206.145.52和root分别是该thread的客户端ip和使用的用户名。如果每个项目都使用不同的用户名,可以快速定位死锁涉及的服务。
7 & 29: 事务发生阻塞的语句。
8 - 23: 事务1持有和等待的锁信息。
-
9:
index idx_age of table test.t_user表示持有的是表test.t_user上索引idx_age的锁;lock mode S表示持有的是next-key lock,相关行锁是共享锁。 -
10 - 11: 持有的第一个
idx_age索引 next-key lock。 -
12 -14: 持有的第二个
idx_age索引 next-key lock。 -
16:
index PRIMARY of table test.t_user表示等待的是表test.t_user主键上的锁;lock_mode X locks rec but not gap表示等待的是行级排他锁。 -
17 - 23: 等待的行锁信息。
30 - 43: 略,同 8 - 23
44: 此次死锁,数据库回滚的是事务(2)。
下面具体说下 11 & 13 -14 & 18 - 23 & 33 - 38 & 42 - 43 具体锁的数据表示格式及内容;
每行分三部分,n: len m记录长度信息;hex xxxxxxx以16进制记录数据,当锁所在字段类型为数值类型时,忽略掉最高位,再进行换算,比如"hex 8000001e", 去掉最高位"8", 换算成10进制得到"30"。最后一部分asc ...., 当锁所在字段类型为字符串类型,才会展示字符串值, 或者next-key lock/间隙锁是最右区间,会展示"asc supremum"。
主键索引和非主键索引的锁展示的内容各不同。
主键索引以 18 - 23 为例:
-
(18行)
field 0表示主键id值, “hex 80000002” 换算10进制为"2"。 -
(19行)
field 1表示最后一次修改此行数据的事务id, “hex 000000001361” 换算10进制为"4961"。 -
(20行)
field 2是回滚指针。 -
(21 - 23行)从
field 3开始是该行的其他列数据。
非主键索引展示内容与performance_schema.data_locks中的LOCK_DATA相同。以13 - 14为例:
- (13行)
field 0表示索引值, “hex 8000001e” 去掉最高位换算成10进制为"30"。 - (14行)
field 1表示索引对应的主键索引id值, “hex 80000002” 去掉最高位换算成10进制为"2"。
尝试获取事务其他语句
一般情况下,通过连接ip、使用的用户名、事务复杂度、锁的持有/等待情况、阻塞语句及服务报错日志,基本上就能定位到代码位置了。从而得到完整的事务语句。当然,我们还能从其他途径尝试获取事务的其他语句。
performance_schema.events_statements_history获取连接最近执行的语句
表performance_schema.events_statements_history中会记录数据库当前未断连接最近N条语句。可以根据show engine innodb status中获取的事务thread id在performance_schema.events_statements_history中查询连接最近N条语句。有两点需要注意:
events_statements_history表中的thread_id并不是performance_schema.processlist的id,需要performance_schema.threads进行转换,所以最终查询语句应该是
SELECT * FROM performance_schema.events_statements_history WHERE thread_id = (SELECT THREAD_ID FROM performance_schema.threads WHERE PROCESSLIST_ID = <PROCESSID>)
performance_schema.events_statements_history、performance_schema.processlist、performance_schema.threads均仅是存储当前未断连接的相关信息, 所以通过这个方式获取完整事务语句的概率不高。
通过binlog日志查看
利用mysqlbinlog查看发生死锁时间点的binlog日志,可以分析得到完整语句。当然,binlog只会记录已经commit的事务日志,所以无法获取被回滚事务的语句。
mysqlbinlog -vvv --start-datetime=“2021-06-18 09:13:20” --stop-datatime=“2021-06-18 09:13:22” mysql-bin.0000xx
得到猜想
经过分析,我们找到了可能导致死锁的两个事务:
- tx1:
- select * from t_user where id = 2 lock in share mode;
- insert into t_user (
name,age,score_rank) values (‘zhangsan’, 25, 4)
- tx2:
- select * from t_user where age > 20 lock in share mode;
- update t_user set score_rank = 10 where id = 2;
验证猜想
得到可能的死锁事务语句后,我们接下来模拟事务语句执行顺序,通过performance_schema.data_locks和performance_schema.data_lock_waits观察语句执行时持有/等待锁信息进行死锁验证。 data_locks之前已经说过,我们现在介绍data_lock_waits各字段的含义:
-
REQUESTING_ENGINE_LOCK_ID: 等待获取锁的锁ID。
-
REQUESTING_ENGINE_TRANSACTION_ID: 等待获取锁所在的事务ID。
-
REQUESTING_THREAD_ID: 等待获取锁所在线程ID。
-
BLOCKING_ENGINE_LOCK_ID: 导致阻塞的锁ID,对应data_locks表的ENGINE_LOCK_ID列。
-
BLOCKING_ENGINE_TRANSACTION_ID:导致阻塞的事务ID。
-
BLOCKING_THREAD_ID:导致阻塞的线程ID。
每一行可以理解为事务REQUESTING_ENGINE_TRANSACTION等待事务BLOCKING_ENGINE_TRANSACTION释放BLOCKING_ENGINE_LOCK锁,以便获取REQUESTING_ENGINE_LOCK锁。
以下是我们猜想的并发死锁场景:

时刻t2:

tx1执行语句1,持有锁:
- 表
t_user的共享意向锁(IS)。 - 主键行级共享锁(S, REC_NOT_GAP), 对应行id = 2;
此时未发生锁等待,所以data_lock_waits为空。
时刻t3:
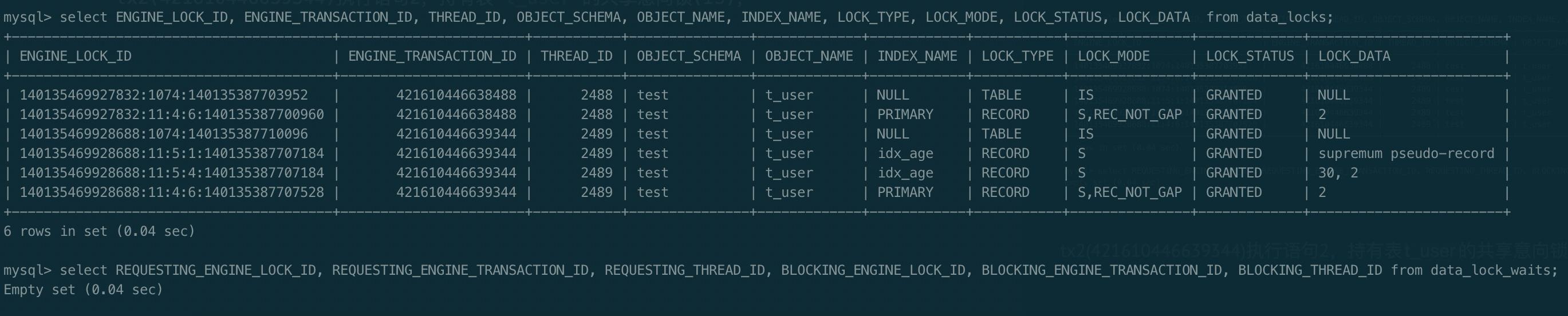
tx2执行语句2,持有锁:
- 表
t_user的共享意向锁(IS)。 - 索引
idx_age上age = 30所在的next-key lock: (20, 30]。对应行锁为共享锁。 - 索引
idx_age上最右边的next-key lock: (30, +∞]。 - 主键行级共享锁(S, REC_NOT_GAP), 对应行id = 2;
此时未发生锁等待,所以data_lock_waits为空。
时刻t4:
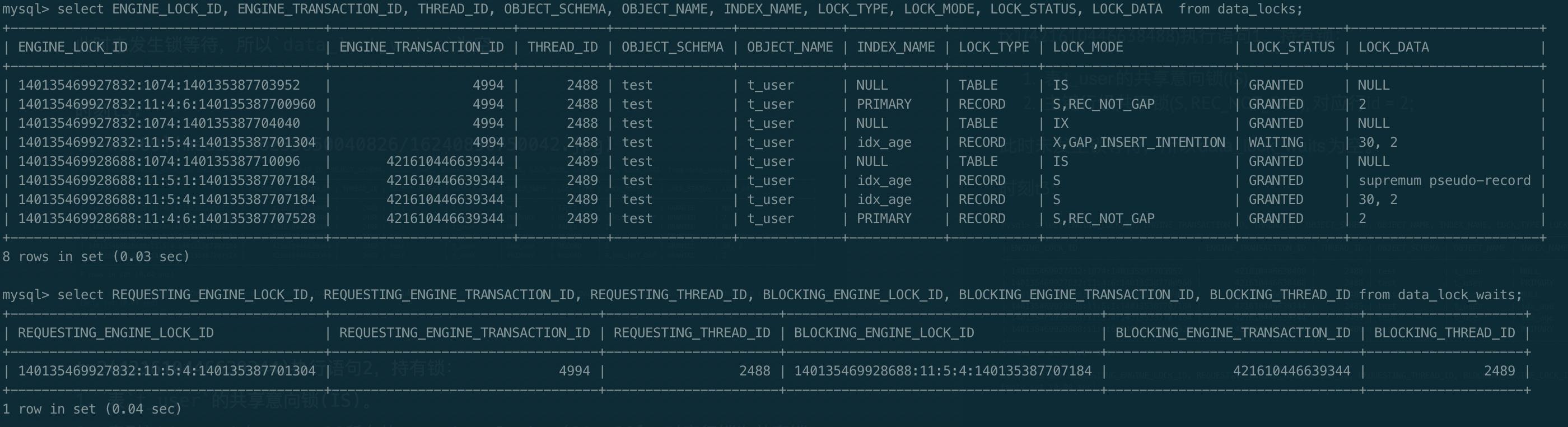
tx1执行语句3,添加了表t_user的排他意向锁(IX)。等待获取索引idx_age上区间(20, 30)的插入意向锁。
从data_lock_waits可以发现,tx1正等待tx2上id = 140135469928688:11:5:4:140135387707184的锁释放,反查data_locks得到造成阻塞的是tx2在索引idx_age上添加的(20, 30]的next-key lock。
时刻t5:

tx2执行语句4时需要获取主键上id = 2的行锁,该行锁已在时刻t2被tx1持有。tx1和tx2互相阻塞,导致死锁,数据库将tx2进行回滚,同时tx1的语句3得以往下执行。
到此,之前的猜想得到验证。
预防死锁
死锁大部分情况都是我们在开发时使用姿势不对造成的,以下提几点避免死锁的小建议:
-
尽量避免大事务。锁的生命周期是从加锁到事务提交才会释放,所以事务越大,其持有的锁越多,更容易造成死锁。
-
合理设计索引。区分度较高的提到联合索引前面,使查询通过索引定位到更少的行,减少加锁范围。反例:“update … where name = ‘xxx’”, name 字段上没有索引,这个语句将会对全表加锁。
-
统一执行顺序。不仅是加锁访问不同表数据的顺序要一致,对同一个表的加锁访问也得一致。而且比较容易忽视。
_, err = eng.Transaction(func(session *xorm.Session) (ret interface{}, err error) {
userIDScoreRankMap := map[int]int64{
1: 1,
2: 2,
}
for userID, scoreRank := range userIDScoreRankMap {
_, err = session.Table(new(TUser)).ID(userID).Update(map[string]interface{}{"score_rank": scoreRank})
if err != nil {
return nil, err
}
}
return
})
userIDScoreRankMap是一个map结构,在循环map时,其key的顺序是不确定的,容易导致死锁。
- 对热点数据尽量放在事务后面,减少加锁时间,减少锁冲突,提高并发。
写在最后
一篇神文档就把java多线程,锁,JMM,JUC和高并发设计模式讲明白了
最后给大家分享一篇一线开发大牛整理的java高并发核心编程神仙文档,里面主要包含的知识点有:多线程、线程池、内置锁、JMM、CAS、JUC、高并发设计模式、Java异步回调、CompletableFuture类等。

首先,咱们先来看目录
下面是详细的目录





其次咱们来看每个小节都有哪些内容
多线程原理与实战;
Java内置锁的核心原理;
CAS原理与JUC原子类;
可见性与有序性的原理;
JUC显式锁的原理与实战;
AQS抽象同步器的核心原理;
JUC容器类;
高并发设计模式;
高并发核心模式之异步回调模式;
CompletableFuture异步回调;
因为文章内容实在是太多了,不能够给大家一一体现出来,每个章节都有更加细化的内容。大家需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于万字长文实战分析MySQL死锁的主要内容,如果未能解决你的问题,请参考以下文章
六万字长文!让你懂透编译原理——第七章 语义分析和中间代码产生
肝了三天-建议收藏实战-万字长文-带你刨析MySQL乱码字符集和比较规则
半万字长文学习 MySQL 主从复制原理,面试必问,建议收藏!