对 Java 的总结和思考系统化重学 Java 之集合篇
Posted 盛夏温暖流年
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了对 Java 的总结和思考系统化重学 Java 之集合篇相关的知识,希望对你有一定的参考价值。
打破舒适圈,经常对 Java 知识进行总结思考,才能保证自己不掉队。
系统化重学 Java 第二篇,来一起分析下 Java 集合中的常见疑问点吧。
第一问: 为什么 Java 1.7 中,LinkedList 底层不再使用循环链表?
在JDK 1.7 前(比如 JDK1.6),LinkedList 底层采用的是 headerEntry 实现的一个循环链表。
也就是先初始化一个空的 Entry,用来做 header,然后首尾相连,形成循环链表,如下图所示:

每次添加/删除元素都是默认在链尾操作,也就是在 header 前面操作,因为遍历是 next 方向的,所以在 header 前面操作,就相当于在链表尾操作。
对应代码如下:
//取自 JDK1.6 - LinkedList,有删改
private Entry<E> addBefore(Eo) {
Entry<E>newEntry = new Entry<E>(o,header,header.previous);
newEntry.previous.next = newEntry;
newEntry.next.previous = newEntry;
size++;
modCount++;
return newEntry;
}而在 JDK 1.7, JDK 1.6 的 headerEntry 循环链表被替换成了 firstEntry 和 lastEntry 组成的非循环链表。
添加一个元素的代码如下:
//取自 JDK1.7 - LinkedList,有删改
void linkLast(E e) {
final Node<E> l = last;
final Node<E> newNode =new Node<>(l, e,null);
last = newNode;
if (l ==null)
first = newNode;
else
l.next = newNode;
size++;
modCount++;
}相比于 1.6,代码看起来更加简单清晰一些。
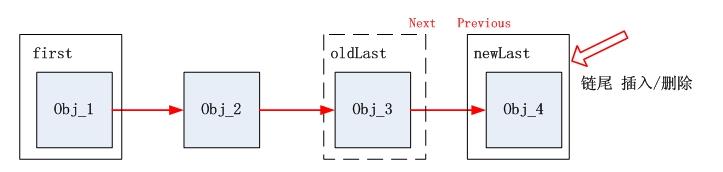
对比可以看出:
1. first / last 有更清晰的链头、链尾概念;
2. first / last 方式能节省 new 一个 headerEntry;
3. 在链头/尾进行插入/删除操作,first /last 方式更加快捷:
在中间插入/删除
两者类似,先遍历找到 index,然后修改链表 index 处两头的指针;
在两头插入/删除
对于循环链表来说,由于首尾相连,需要处理两头的指针;
对于非循环链表,只需处理一边 first.previous / last.next,所以理论上来说,非循环链表更高效。
一般情况下,两头(链头/链尾) 操作是最普遍的,所以 1.7 版本替换为非循环链表是个明智的选择。
参考原文链接:https://blog.csdn.net/tiwerbao/article/details/8227689
第二问: 为什么 ArrayList 要实现 RandomAccess 接口?
我们看源码时,会发现 ArrayList 实现了 RandomAccess 接口,而 LinkedList 没有实现。
而 RandomAccess 本身是一个空接口,既然是空的,那为什么还要去实现?
实际上,RandomAccess 是一个标记接口,官方的解释是,只要 List 实现这个接口,就能支持快速随机访问。
而什么是随机访问呢?
我们知道,Collections 是集合的一个工具类,就拿 Collections 源码中的二分搜索方法来举例:
public static <T>
int binarySearch(List<? extends Comparable<? super T>> list, T key) {
if (list instanceof RandomAccess || list.size()<BINARYSEARCH_THRESHOLD)
return Collections.indexedBinarySearch(list, key);
else
return Collections.iteratorBinarySearch(list, key);
}在 binarySearch 方法中,首先会判断 list 是否是 RandomAccess 的实例,如果是,则执行 indexedBinarySearch 方法,如果不是,则执行 iteratorBinarySearch 方法。
这两个方法的区别在于前者使用索引遍历,更适用于 ArrayList;后者使用迭代器遍历,更适用于 LinkedList 。
所以通过 RandomAccess 接口作为标记,可以判断采用哪一种搜索方案更加高效。
第三问: 为什么 ArrayList 中的对象数组 elementData 使用 transient 修饰,ArrayList 明明是可序列化的啊?
首先我们要知道 transient 的作用:
一旦变量被 transient 修饰,变量将不再是对象持久化的一部分,该变量内容在序列化后无法获得访问。
而 ArrayList 是动态扩容的,所以对象数组并不是都存储了数据的,如果外部对这个数组进行序列化,会把整个对象数组都序列化。
所以 ArrayList 为了提高性能,实现了私有的 writeObject 和 readObject 方法用于优化序列化和反序列化。
简单的说,使用 transient 修饰对象数组 elementData, 就是为了防止它被外部方法序列化。
第四问:实际测试的时候发现,新增元素时,LinkedList 的效率不一定高于 ArrayList,这是为什么?
测试 ArrayList 和 LinkedList 新增的性能时会发现,在不同位置对 ArrayList 和 LinkedList 进行操作,LinkedList 的效率不一定高于 ArrayList,和网上说的似乎不太一样,那这是为什么呢?
先来看测试结果(这里比较的是运行耗时):

也就是说,只有从集合头部新增元素的时候,LinkedList 的性能才高于 ArrayList,而从集合中间和尾部新增元素,LinkedList 的性能均低于 ArrayList。
原因如下:
1. 从集合头部新增元素
ArrayList 如果在头部新增元素,要对头部以后的数据进行复制重排,效率很低;
LinkedList 在添加元素时,首先会通过循环,查找到元素需要被添加的位置,如果位置处于 List 的前半段,就从前往后找;
若位置处于后半段,就从后往前找。
因此 LinkedList 添加元素到头部是非常高效的;
2. 从集合中间新增元素
ArrayList 在添加元素到数组中间时,同样有部分数据需要复制重排,效率不是很高;
LinkedList 将元素添加到中间位置,是添加元素效率最低的。
因为靠近中间位置,在添加元素之前的循环查找是遍历元素最多的操作,效率非常低;
3. 从集合尾部新增元素
ArrayList 在添加元素到尾部的时候,不需要复制重排数据,效率非常高;
而 LinkedList 虽然也不用循环查找元素,但 LinkedList 中多了 new 对象以及变换指针指向对象的过程,所以效率要低于 ArrayList;
第五问:JDK 1.8 后的 HashMap 底层中,树化的阈值是 8,链化的阈值是 6,为什么不保持一致呢?
好了,说人话,先来解释概念。
我们知道,HashMap 底层的数据结构是数组,数组中存放的是链表或红黑树。
当链表长度大于 8 时,会把链表转换成红黑树,这个就是树化;
而红黑树中的元素个数如果小于或等于 6 时,树又会退化成链表,这个就是链化;
为什么不是小于 8 就退化呢?比如说 7 的时候就退化,偏偏要小于或等于 6?
设想一下,如果阈值是 7 的话,删除一个元素红黑树就必须退化为链表,增加一个元素就必须树化,来回不断的转换结构无疑会降低性能,所以阈值才不设置的那么临界。
第六问:HashMap 的长度为什么是 2 的幂次方?
源码中用于计算需要插入元素的数组下标的方法 hash(key) ,会通过 (length - 1) & hash 的方式来计算结果,2的幂次方 - 1 转换为二进制的每一位都是1,从数值上来讲其实等价于对 length 取模。
这样一来,数据在数组上分布也相对离散,碰撞的几率也小,查询效率也会提高;
第七问:为什么在 JDK 1.8 中,HashMap 链表改成了尾插法?
我们知道,当出现 hash 冲突的时候,元素会以链表的形式存储,JDK 1.7 中元素插入链表是从头部插入,JDK 1.8 中是从尾部插入。
头插入法,在扩容时会改变链表中元素原本的顺序,以至于在并发场景下容易导致链表成环的问题。
而尾插入法,在扩容时会保持链表元素原本的顺序,就不会出现链表成环的问题了。
第八问:为什么在 JDK 1.8 中,要对 HashMap 数组扩容的存储位置计算方法进行优化?
两个版本对应的数组扩容的存储位置计算方法如下:
JDK 1.7:把所有数据打散,重新计算哈希值并进行存储,这个过程又叫 rehash,成本相当大;
JDK 1.8:是对数组中的元素进行重排序,要么在原位置,要么是原位置 + 原始容量;
除了性能低下,并发条件下的 JDK 1.7 的 rehash 操作还可能导致元素间形成循环链表的问题发生。
而 JDK 1.8 后解决了这个问题,不过我们还是不建议在多线程下使用 HashMap,因为多线程下使用 HashMap 还是会存在其他问题,比如数据丢失。
术业有专攻,并发条件下,推荐使用 ConcurrentHashMap 来解决问题。
以上是关于对 Java 的总结和思考系统化重学 Java 之集合篇的主要内容,如果未能解决你的问题,请参考以下文章