MySQL 主从复制
Posted Javachichi
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了MySQL 主从复制相关的知识,希望对你有一定的参考价值。
本文主要讨论 mysql 主从复制的内容,以及基于
binlog如何实现异步复制。
主从复制方式
目前 MySQL 支持两种复制方式:
- 传统方式:
基于主库的 binlog 将日志事件和事件位置复制到从库,从库再加以应用来达到主从同步的目的。
GTID方式(MySQL>=5.7推荐使用):
基于 GTID 的复制中,从库会告知主库已经执行的事务的 GTID 的值,然后主库会将所有未执行的事务的 GTID 的列表返回给从库,并且可以保证同一个事务只在指定的从库执行一次。
多种复制类型
- 异步复制
一个主库,一个或多个从库,数据异步同步到从库。
- 同步复制
在MySQL cluster中特有的复制方式。
- 半同步复制
在异步复制的基础上,确保任何一个主库上的事物在提交之前至少有一个从库已经收到该事物并日志记录下来。
- 延迟复制
在异步复制的基础上,人为设定主库和从库的数据同步延迟时间,即保证数据延迟至少是这个参数。
主从复制实战
配置主从数据库服务器参数
Master 服务器参数:
[mysqld]
log-bin = /www/server/data/mysql-bin
binlog_format = mixed
server-id = 100
#expire_logs_days = 10 #日志过期时间
#max_binlog_size = 200M #日志最大容量,可以不设置,有默认值,设置后MySQL无法重启,我遇到情况
binlog_do_db = test
#binlog_do_db 指定记录二进制日志的数据库,即需要复制的数据库名,如果复制多个数据库,重复设置这个选项即可
Slave 服务器参数:
[mysqld]
log-bin = /www/server/data/mysql-bin
binlog_format = mixed
server-id = 200
#expire_logs_days = 10 #日志过期时间
#max_binlog_size = 200M #日志最大容量,可以不设置,有默认值,设置后MySQL无法重启,我遇到情况
relay_log = /www/server/data/relay-bin
#指定relay_log日志的存放路径和文件前缀 ,不指定的话默认以主机名作为前缀
read_only = on
skip_slave_start = on
#下面两个参数是把主从复制信息存储到innodb表中,默认情况下主从复制信息是存储到文件系统中的,如果从服务器宕机,很容易出现文件记录和实际同步信息不同的情况,存储到表中则可以通过innodb的崩溃恢复机制来保证数据记录的一致性
master_info_repository = TABLE
relay_log_info_repository = TABLE
在 Master 服务器上建立复制账号
需要设置 REPLICATION SLAVE 权限:
CREATE USER '账号'@'2.7.4.5' IDENTIFIED BY '密码';
GRANT REPLICATION SLAVE ON *.* TO 'repl'@'1.1.1.1';
flush privileges; #刷新权限
在 Slave 服务器的操作
查看 Master 的 binlog 的文件名和 binlog 偏移量
show master status; # 查看 Master 的 binlog 的文件名和 binlog 偏移量
- 配置slave服务器:
CHANGE MASTER TO
MASTER_HOST='1.1.1.1',
MASTER_USER='账号',
MASTER_PASSWORD='密码',
MASTER_LOG_FILE='mysql-bin.00001',
MASTER_LOG_POS=66;
# 注意,这里的 master_log_file,就是 binlog 的文件名,输入上图中的 mysql-bin.00001,每个人的都可能不一样。
# 注意,这里的 master_log_pos 是 binlog 偏移量。
Master 和 Salve 数据库的数据保持一致(主库已经有数据的解决方案)
主从数据库的数据要保持一致,不然主从同步会出现 bug
主库已经有数据的解决方案
第一种方案是选择忽略主库之前的数据,不做处理。这种方案只适用于不重要的可有可无的数据,并且业务上能够容忍主从库数据不一致的场景。
第二种方案是对主库的数据进行备份,然后将主数据库中导出的数据导入到从数据库,然后再开启主从复制,以此来保证主从数据库数据一致。
下面是第二种方案的操作:
- 锁定主数据库,只允许读取不允许写入,这样做的目的是防止备份过程中或备份完成之后有新数据插入,导致备份数据和主数据数据不一致。
flush tables with read lock;
通过 MySQL 主服务器上的全备初始化从服务器上数据:
cd /data/db_backup/
mysqldump -uroot -p --master-data=1 --single-transaction --routines --triggers --events --all-databases > all.sql
解锁主数据库
unlock tables;
然后把数据全量导入 Slave 数据库,保证主从数据一致
开始主从同步
start slave; # 开启从同步
show slave status; # 查看从节点状态
注意事项
如果出现IO线程一直在Connecting状态,可以看看是不是俩台机器无法相互连接,如果可以相互连接,那么有可能是Slave账号密码写错了,重新关闭Slave然后输入上面的配置命令再打开Slave即可。
如果出现SQL线程为NO状态,那么有可能是从数据库和主数据库的数据不一致造成的,或者事务回滚,如果是后者,先关闭stop slave,然后先查看master的binlog和position,然后输入配置命令,再输入set GLOBAL SQL_SLAVE_SKIP_COUNTER=1;,再重新start slave;即可,如通过是前者,那么就排查一下是不是存在哪张表没有被同步,是否存在主库存在而从库不存在的表,自己同步一下再重新配置一遍即可。
Could not find first log file name in binary log index file
如果查看从库状态发现此问题,请查看主库状态,将其中的File和Position字段通过在从库中执行以下SQL语句写入从库配置中。
change master to master_log_file='mysql-bin.000001', master_log_pos=3726;
ERROR 1872 (HY000): Slave failed to initialize relay log info structure from the repository
如果启动slave时出现此错误,主要可能是因为保存着以前slave用的relay-log,可以执行以下语句来启动slave。
reset slave;
start slave;
写在最后
一篇神文档就把java多线程,锁,JMM,JUC和高并发设计模式讲明白了
最后给大家分享一篇一线开发大牛整理的java高并发核心编程神仙文档,里面主要包含的知识点有:多线程、线程池、内置锁、JMM、CAS、JUC、高并发设计模式、Java异步回调、CompletableFuture类等。

首先,咱们先来看目录
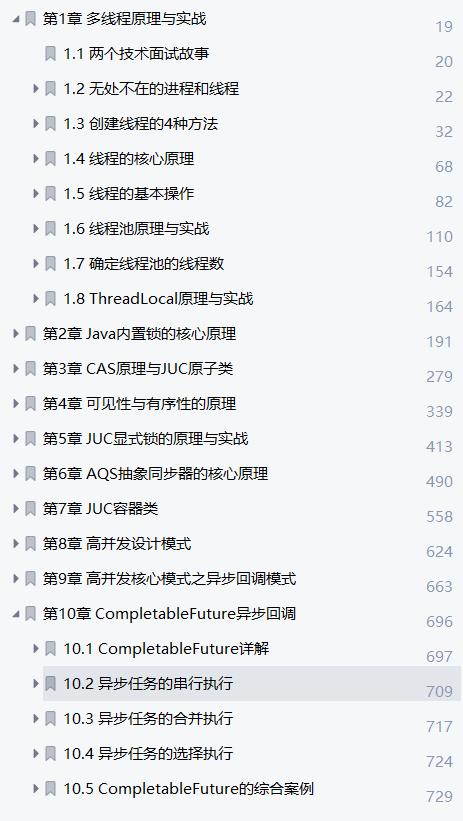
下面是详细的目录





其次咱们来看每个小节都有哪些内容
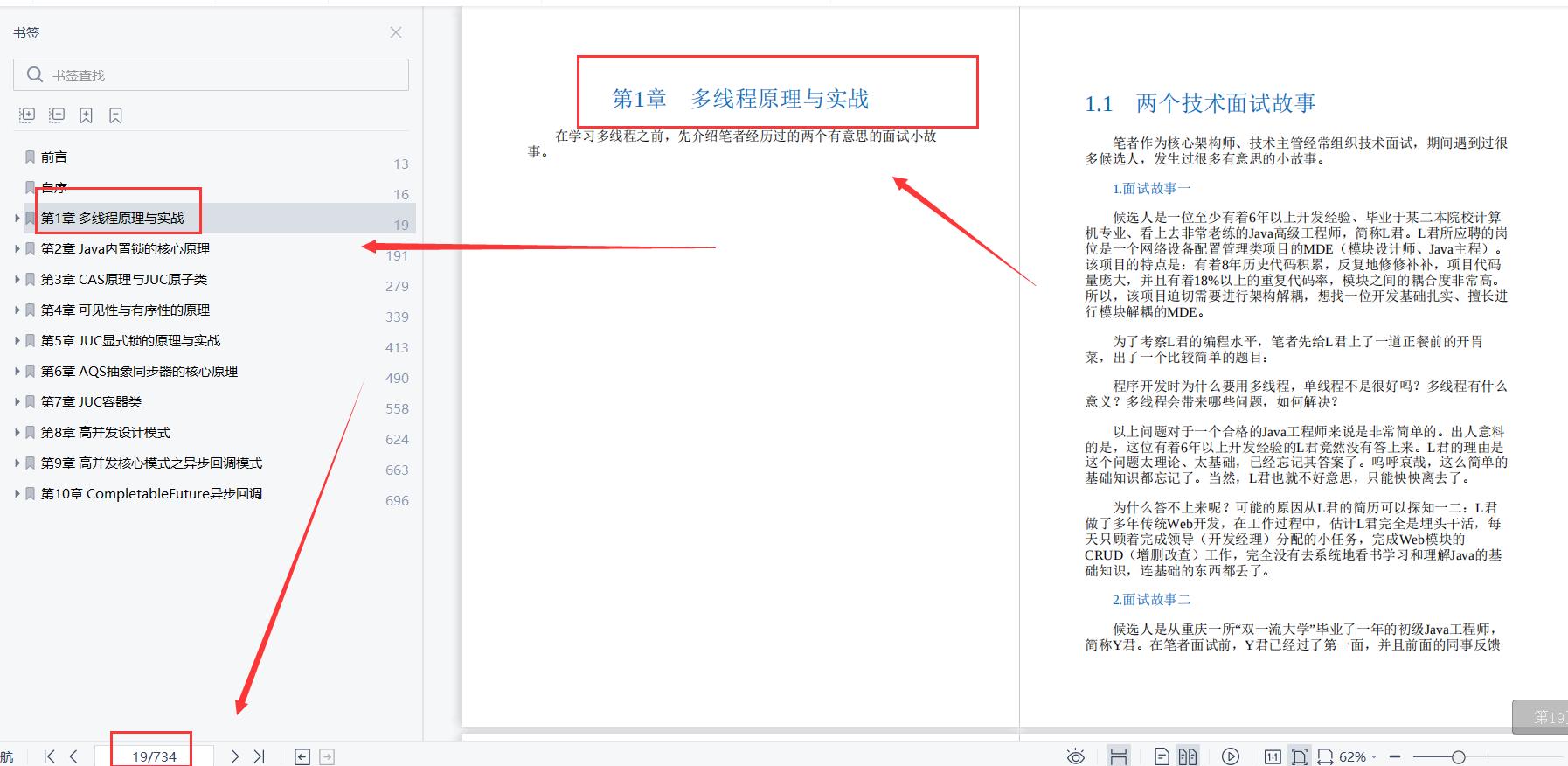
多线程原理与实战;
Java内置锁的核心原理;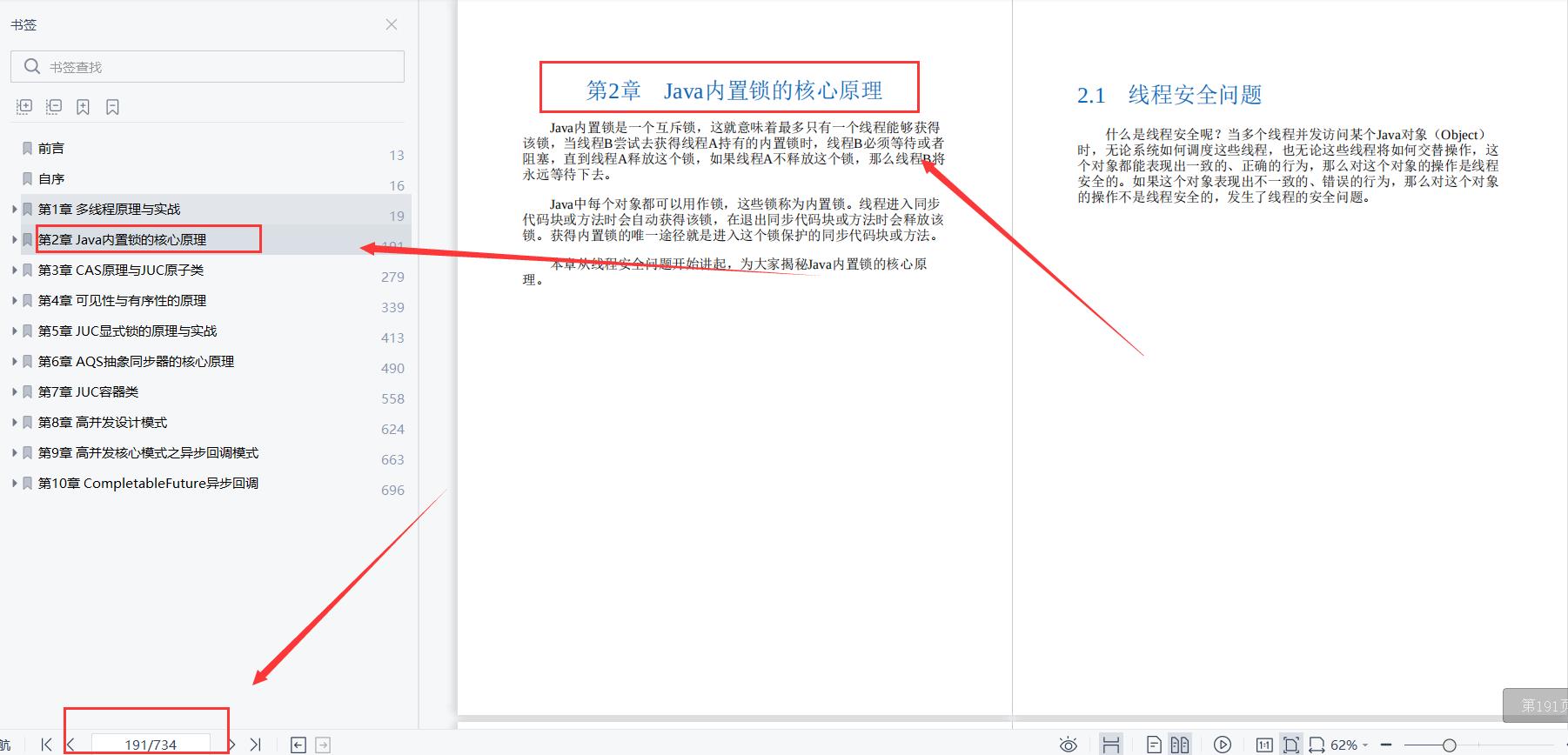
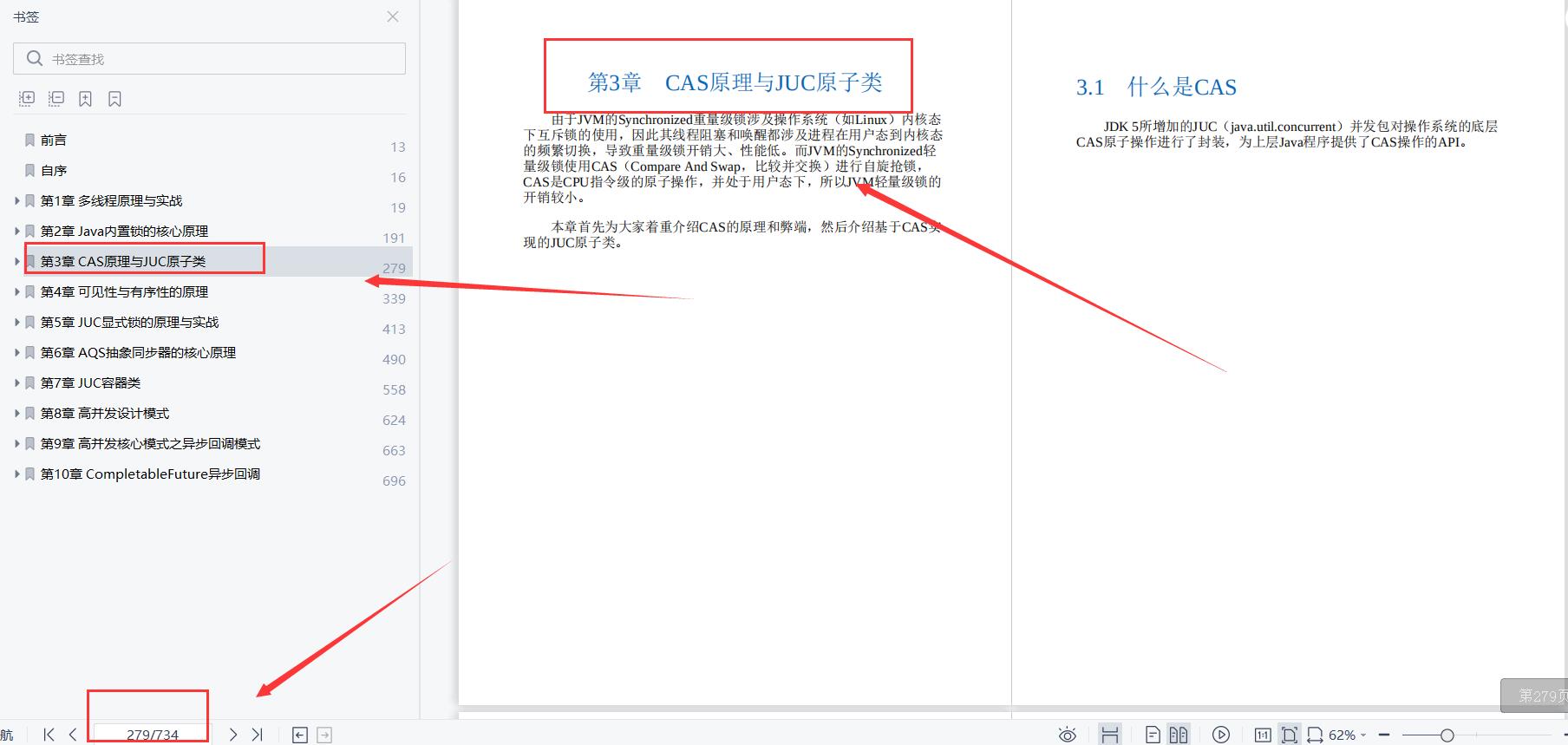
CAS原理与JUC原子类;
可见性与有序性的原理;
JUC显式锁的原理与实战;
AQS抽象同步器的核心原理;
JUC容器类;
高并发设计模式;
高并发核心模式之异步回调模式;
CompletableFuture异步回调;
因为文章内容实在是太多了,不能够给大家一一体现出来,每个章节都有更加细化的内容。大家需要完整版文档的小伙伴,可以一键三连,下方获取免费领取方式!

以上是关于MySQL 主从复制的主要内容,如果未能解决你的问题,请参考以下文章