分布式事务
Posted xue_yun_xiang
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了分布式事务相关的知识,希望对你有一定的参考价值。
一、概述
1、事务四大特性
一致性:
转账例子 ,钱总金额 不变
原子性:
多条sql 语句 要么成功,要么都失败,如果有一条失败,其他成功的回滚
隔离性:
在一个事务中(sqlsession)能够看到另外一个事务的数据隔离级别:读未提交 读已提交 可重复读 序列化读
脏数据:脏读:一个事务可以看到另外一个事务未提交的数据
不可重复读:一个事务中执行查询同一行数据 ,两次结果不一致 针对 修改、更新
幻读:一个事务中执行查询同一个sql(select * from …tb) 多次,查询出来的总行数不一
致 针对增删
持久性:
服务器掉电不丢失
传播行为: 方法A开启事务调用 方法B 时,B是否开启事务
在B 方法上配置
required:必须有事务 如果A开始事务,方法B就是用A的事务
如果A没有开启事务,方法B自己开启事务
supports: 如果A开始事务,方法B就是用A的事务
如果A没有开启事务,方法B也不开启事务
requirs_new:
如果A开始事务,方法B也开启事务,使用新的事务
如果A没有开启事务,方法B自己开启事务
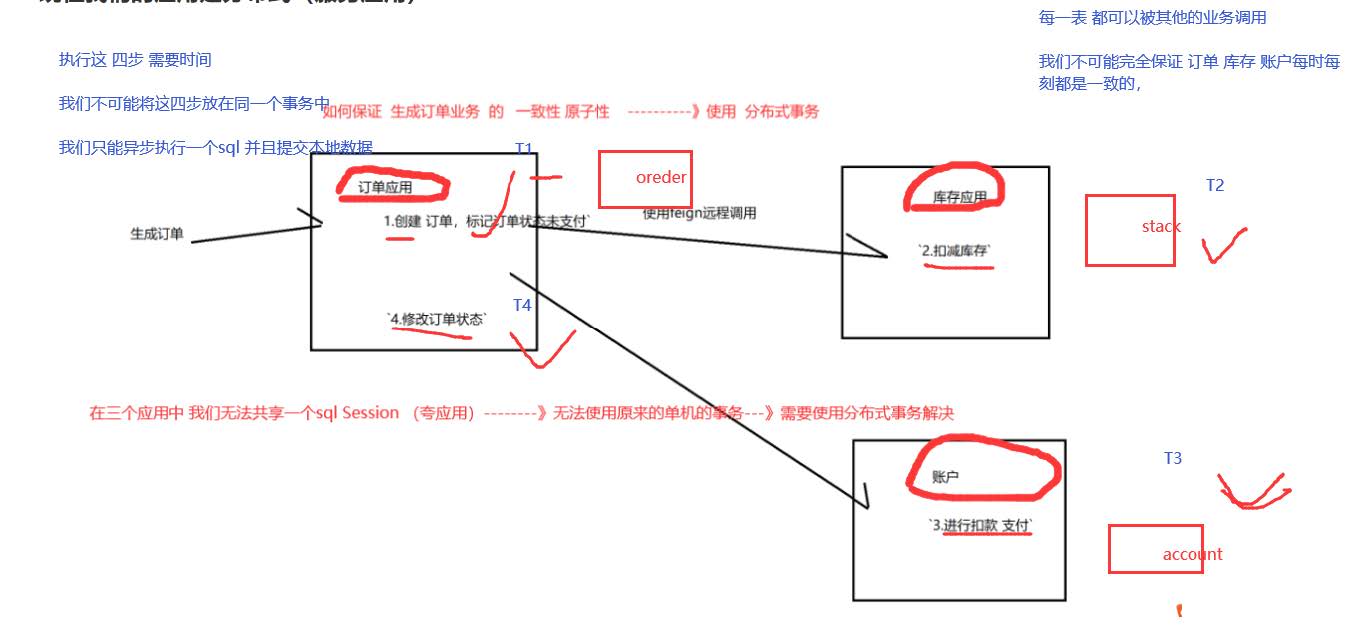
二、 实例:生成订单业务
1、之前的方法
开启事务就可以了
1.创建 订单,标记订单状态未支付
2.扣减库存
3.进行扣款 支付
4.修改订单状态
2、现在的方法:分布式
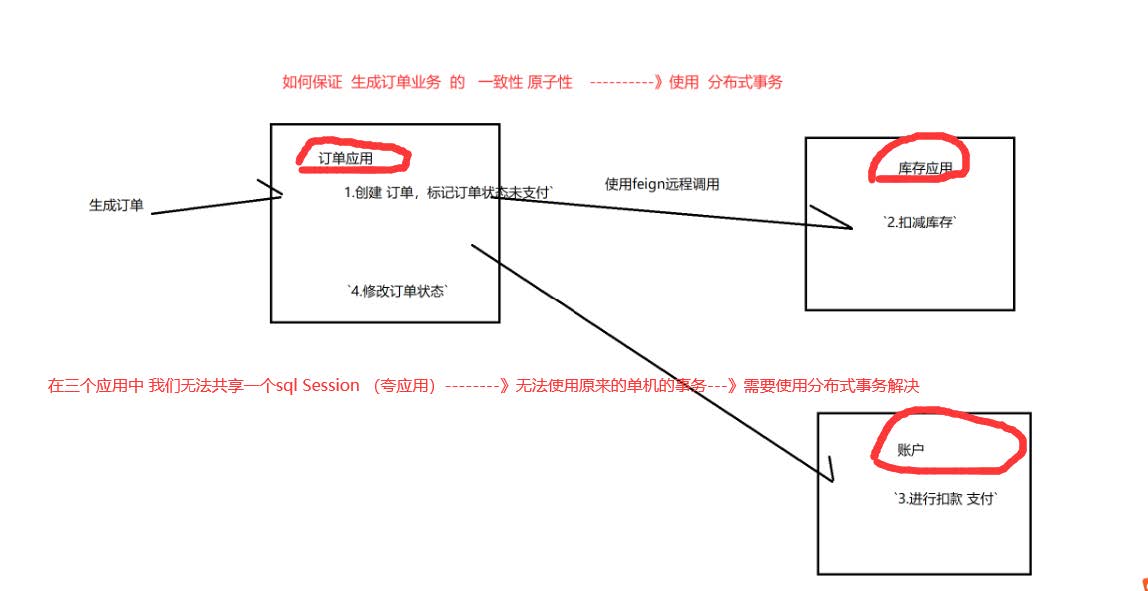
订单应用分析
发起远程调用库存服务
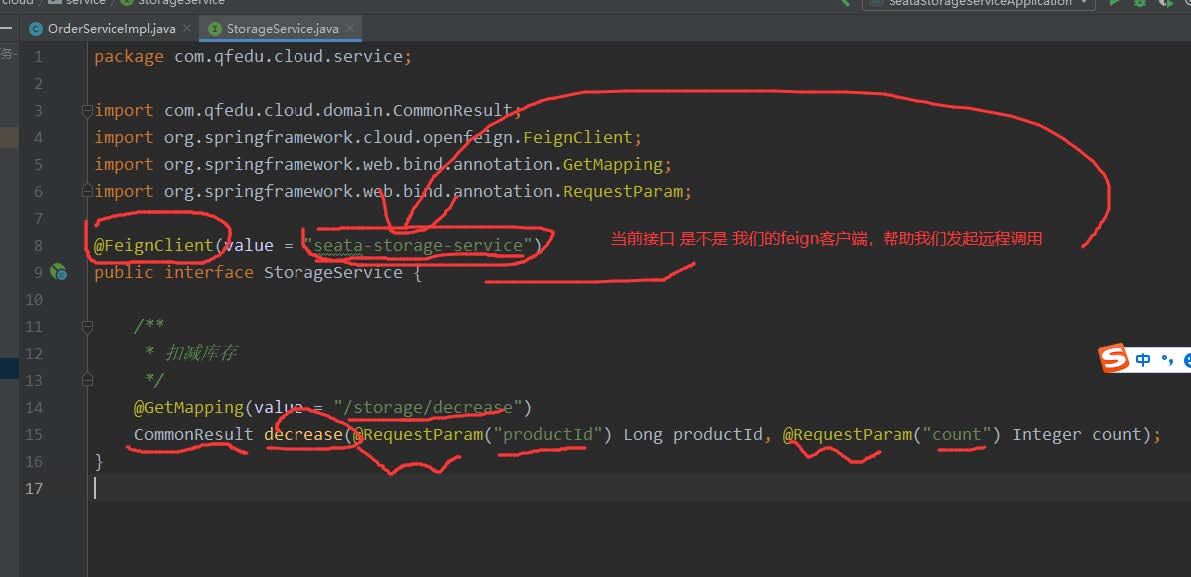
发起远程调用扣减金额服务
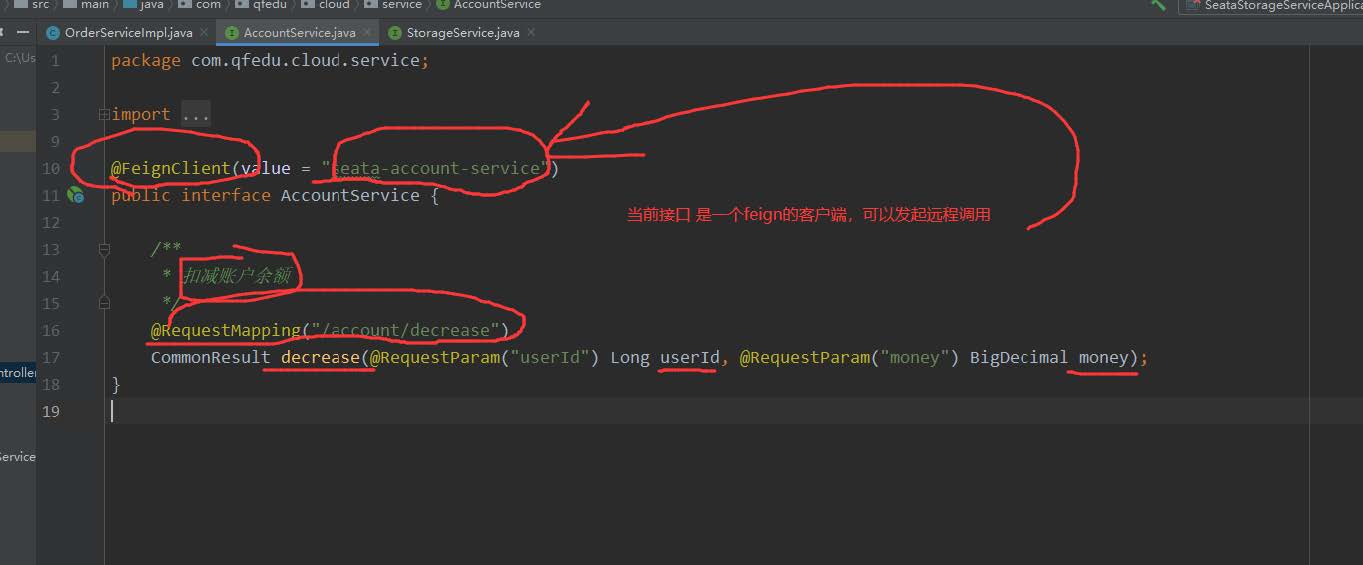
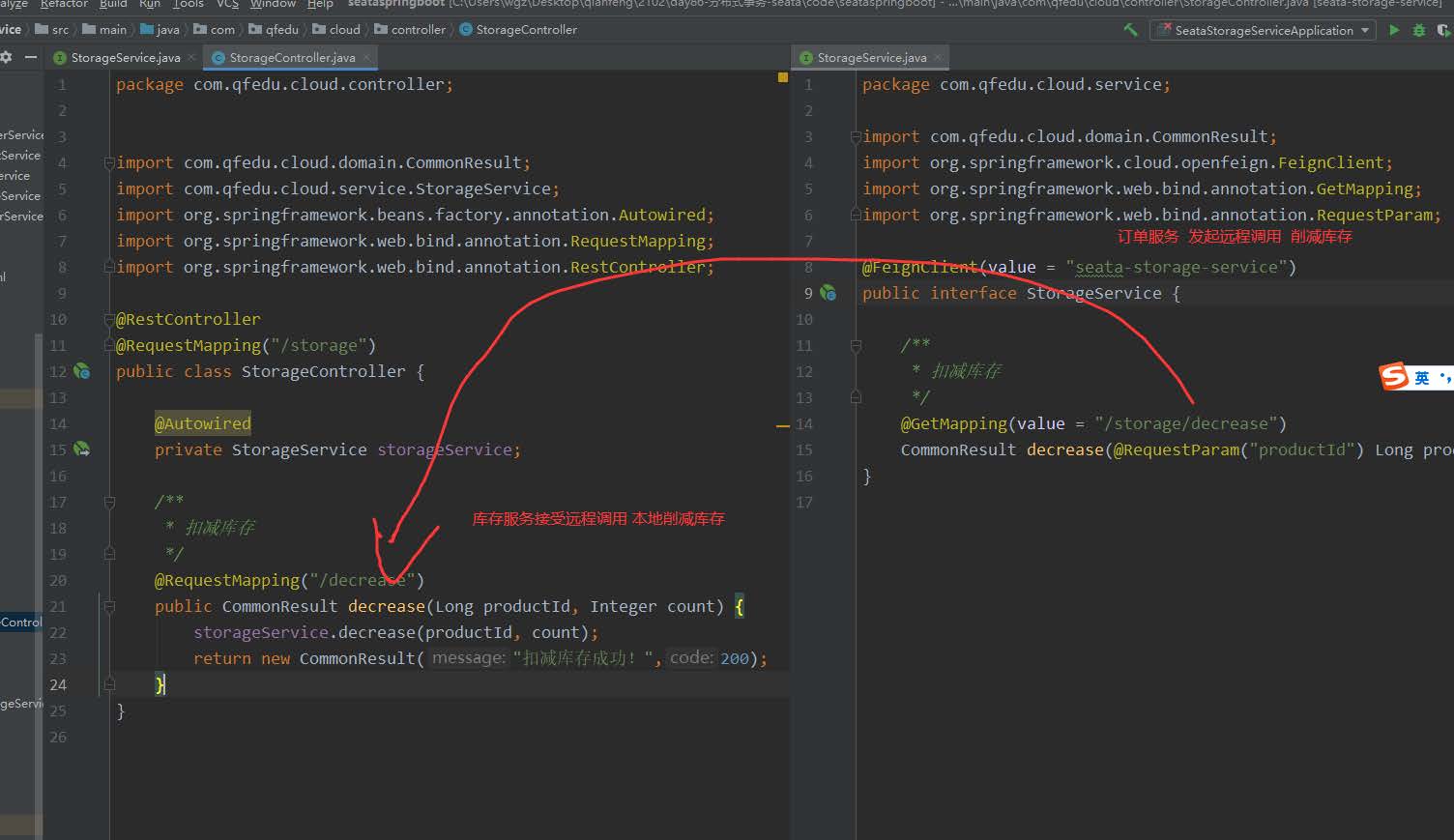
库存应用分析
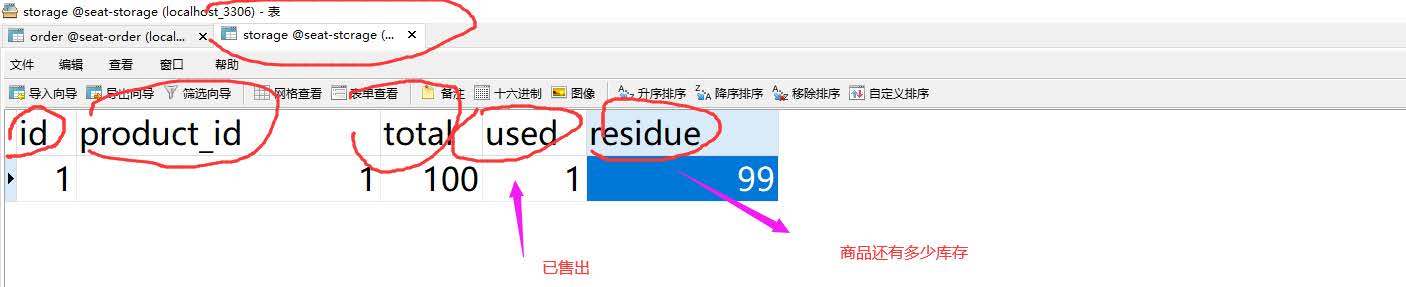
削减金额
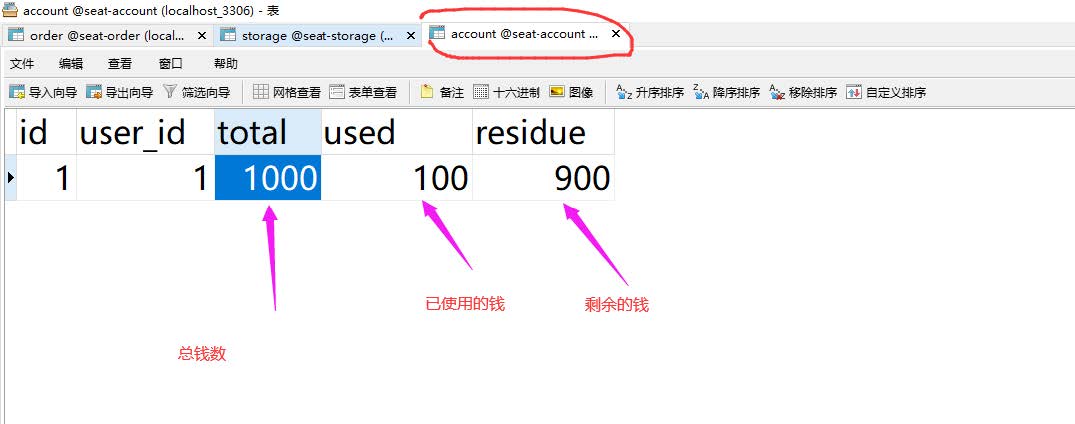
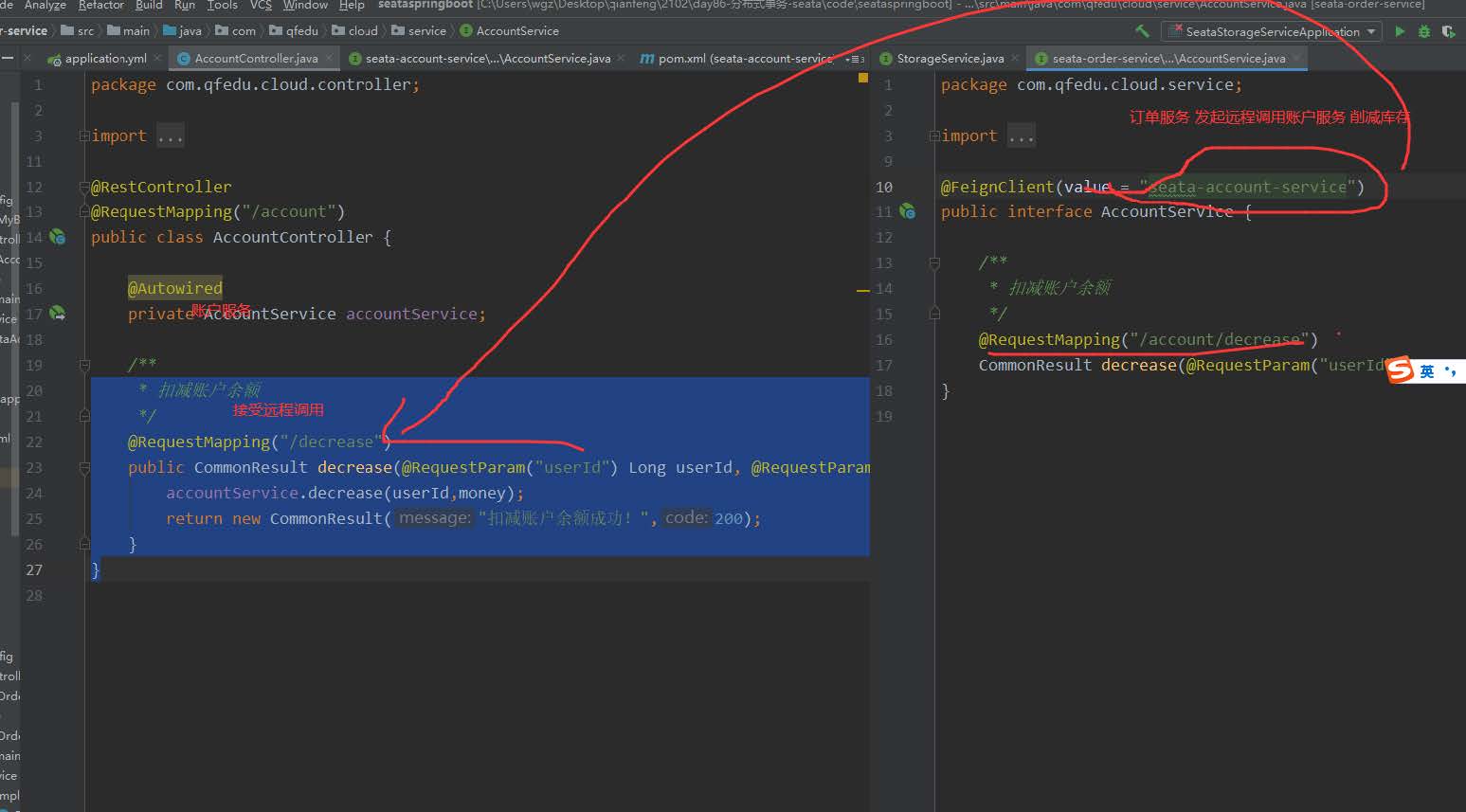
削减库存
三、启动工程
1、启动nacos注册中心
2、分别启动三个应用
启动顺序
1.启动账户服务
2.启动库存服务
3.启动订单服务
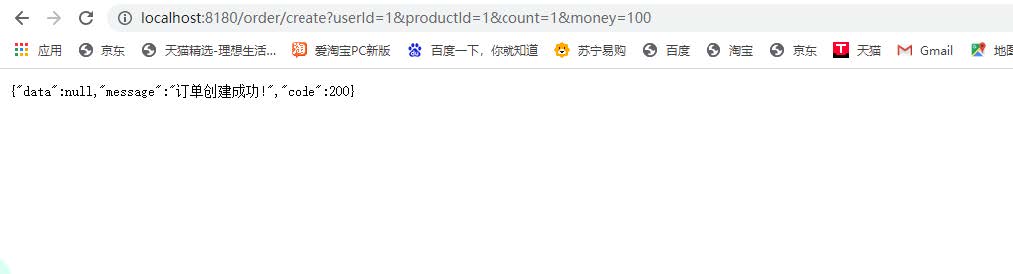
3、访问
http://localhost:8180/order/create?userId=1&productId=1&count=1&money=100
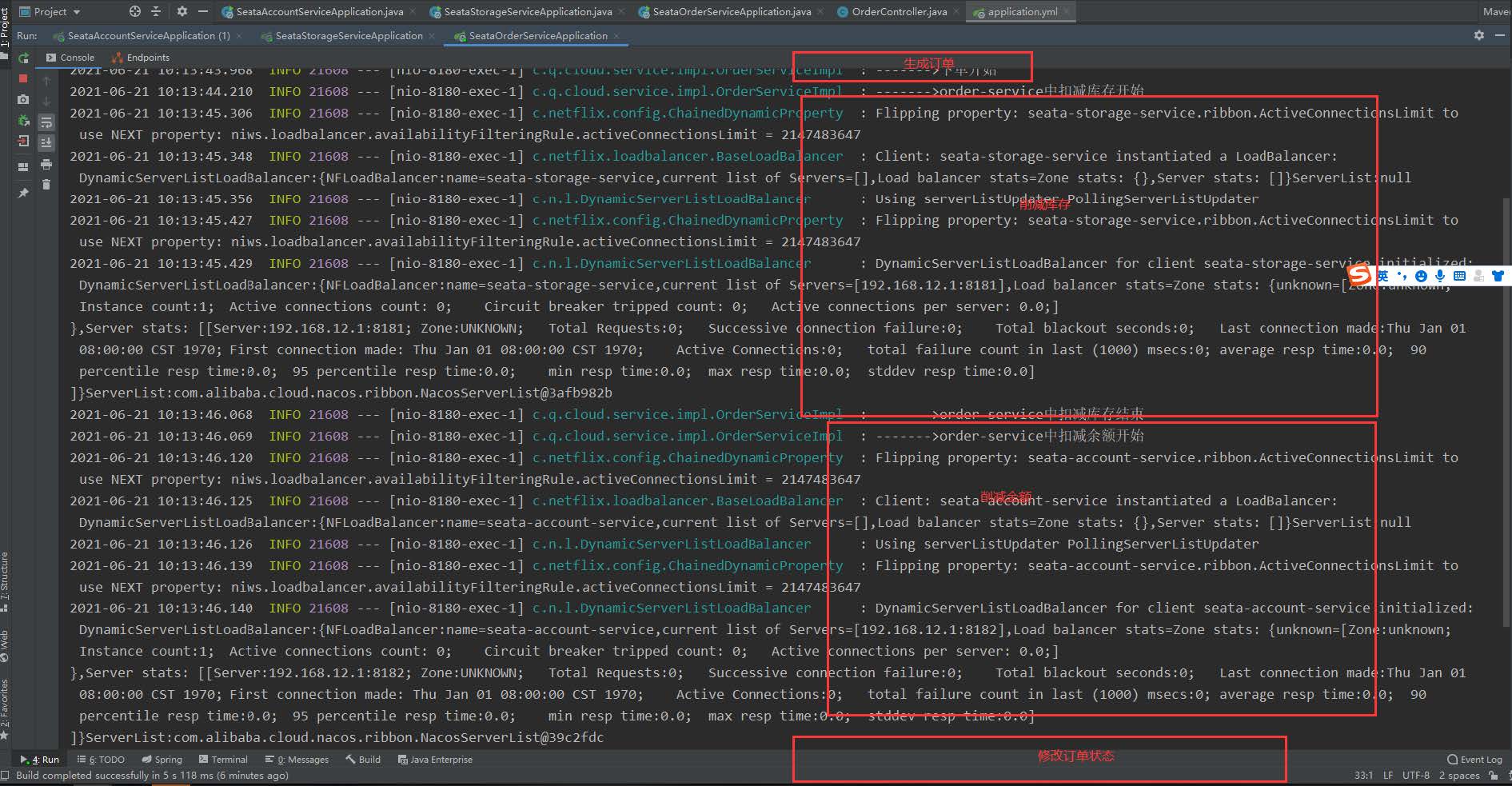
4、调试
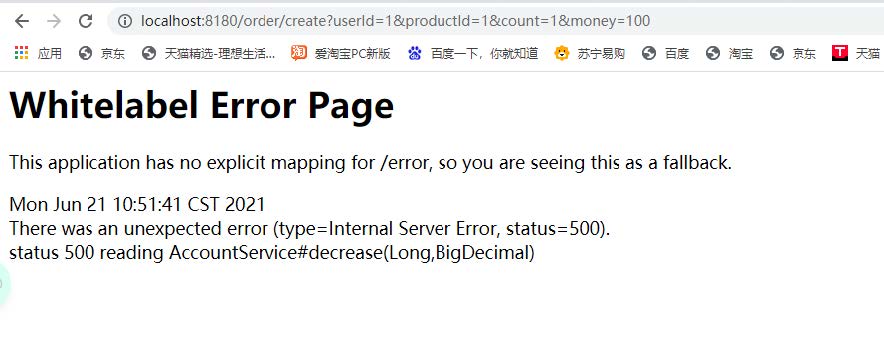
后续将如果某一父发生异常,我们数据一致性还能否保证 ?
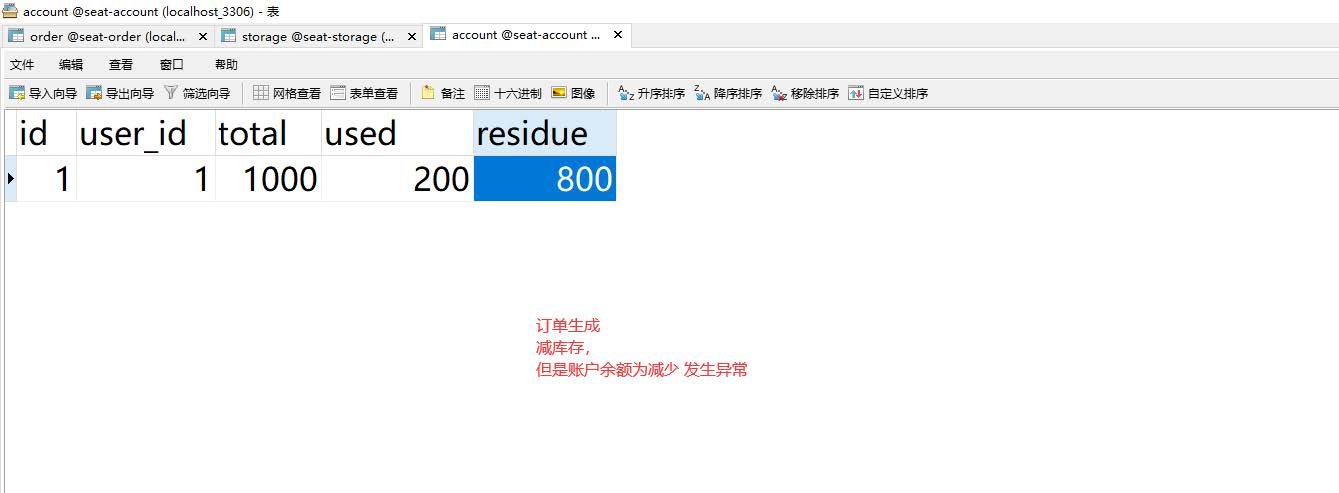
四、分布式事务
概述
分布式事务就是同一个业务处理多条sql,而多条sql发生在在多个应该中(或者多个数据源中),如何保证我们业务的一致性,原子性
CAP理论:C:一致性,A:可用性,P:分区容错性。
一致性(Consistency)、可用性(Availability)、分区容错性(Partition tolerance)
在分布式应用中,我们的业务不可能同时满足三个特性一致性,可用性,分区容错性;cap 理论是分布
式事务的 基础
cap 几乎不能满足组,分布式业务的要求,我就有了妥协
Base理论,BA:基本可用,S:中间状态,E:最终一致性。
CAP 理论的妥协,业务开始可以,没有一致性,先保证可用性,通过一定的时间,使用补偿机制到最后一致性
我们分布式业务无法满足cap三个特性,那我们就满足可用性,分区容错,达到基本可用的目的,通过一些后补的错谁最终完成 最终的一致性
先基本可用,不强调 强一致性,只强调最终的一致性我
分布式事务解决方案【重点】
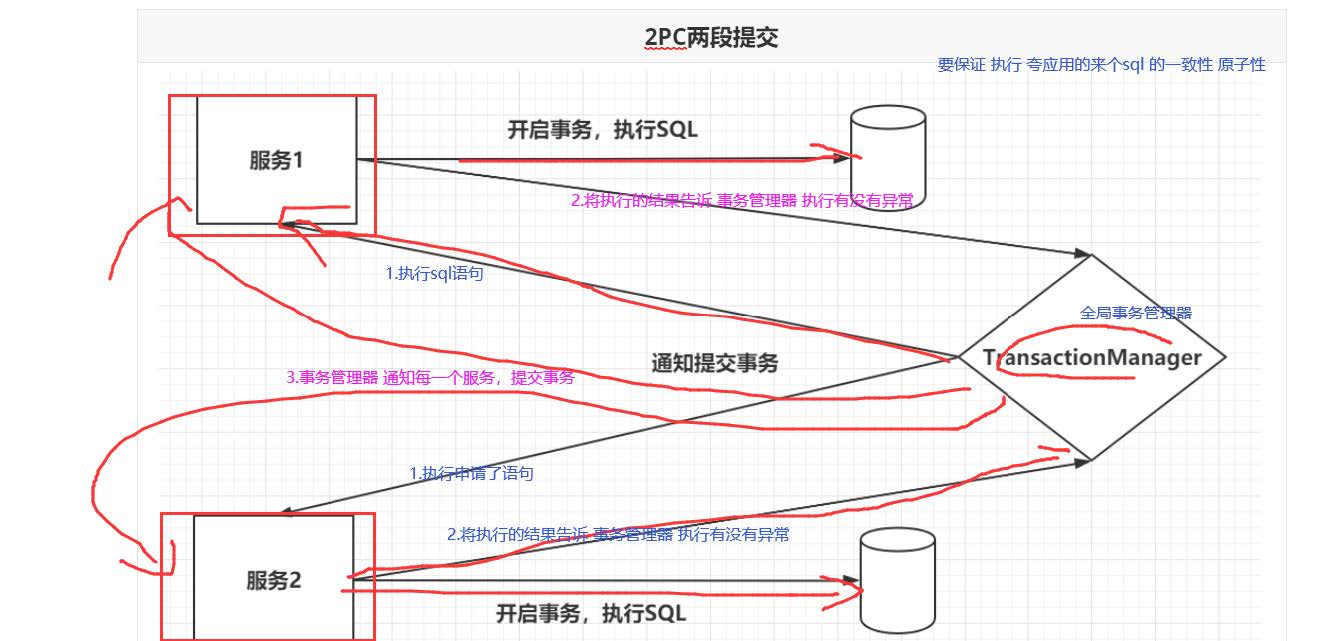
2pc(两阶段提交)
两段提交分为两个阶段:
第一个阶段是准备阶段,参与者需要开启事务,执行SQL,保证数据库中已经存在相应的数据。参
与者会向TransactionManager(全局事务管理器)准备OK。
1.开启本地事务 执行slq
2.将执行sql 结果告诉 全局事务管理器
第二个阶段当TransactionManager收到了所有的参与者的通知之后,向所有的参与者发送
Commit请求。
3.全局事务管理器如果 返现所有的子业务报告sql 没有异常,则让所有的子业务 提交事务,有异
常,所有的子业务对应的事务都回滚
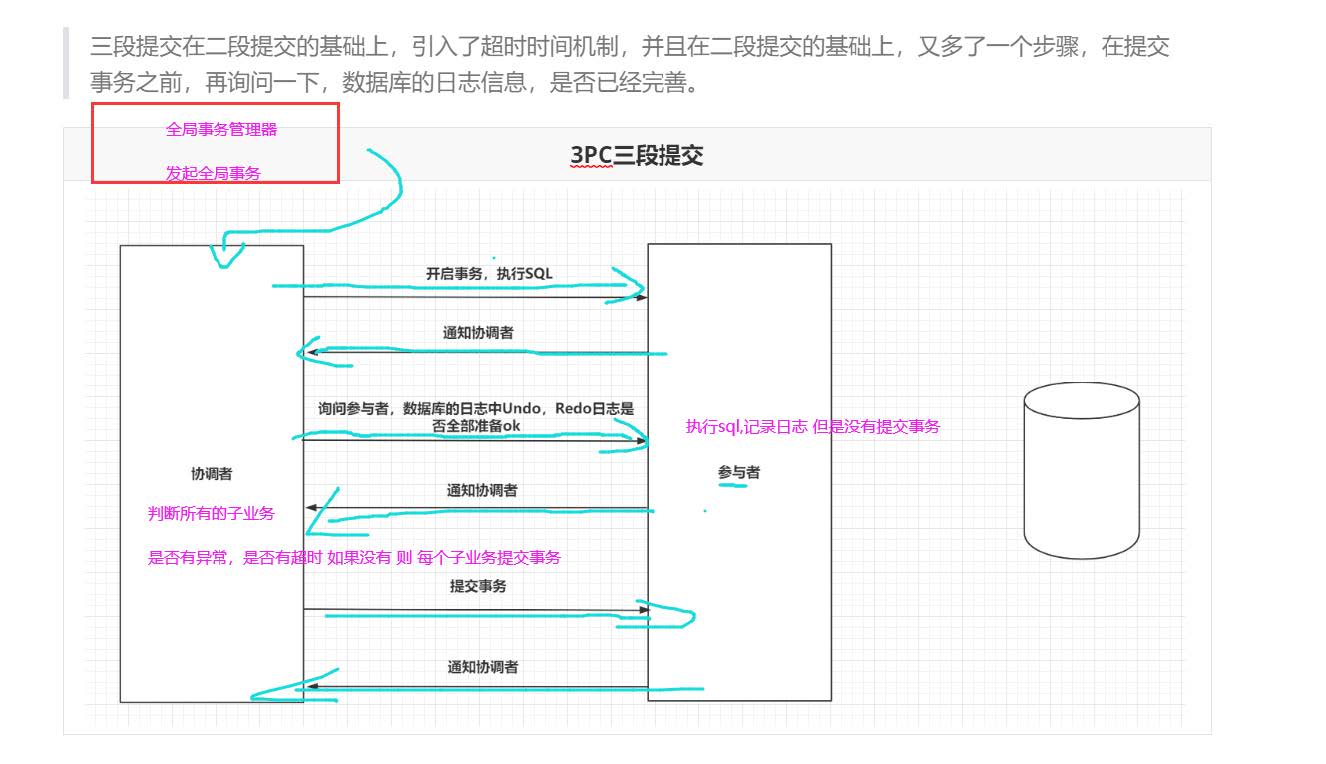
3pc(三阶段提交)
三阶段提交 其实就是在两阶段提交的基础上多个连个步骤
多了
1.对事务超时的判断 (假如如果有事务一直不执行,则将其他子业务执行的sql 通过undo 日志进行回
滚 )
2.对所有执行的sql 增加了 redo日志(执行的sql 记录下来) undo日志(课通过日志将数据复原)
2pc与3pc 的区别?
1.3pc 多了对事务超时的判断 (假如如果有事务一直不执行,则将其他子业务执行的sql 通过undo 日志进行回滚 )
2.3pc 多了对所有执行的sql 增加了 redo日志(执行的sql 记录下来) undo日志(课通过日志将数据复原)
TCC机制
Try,Confirm,Cancel 三个单词的缩写,他的执行需要和我们的代码耦合在一起
TCC(Try,Confirm,Cancel),和你的业务代码切合在一起。
Try:尝试去预执行具体业务代码。
try成功了:Confirm:再次执行Confirm的代码。
try失败了:Cancel:再次执行Cancel的代码。Try: 尝试执行业务代码,对资源检查 与执行sql 检查资源是否足够
Confirm:确认 提交各个子模块的事务
Cancel:如果sql 有异常或者 资源不够充沛 则回滚
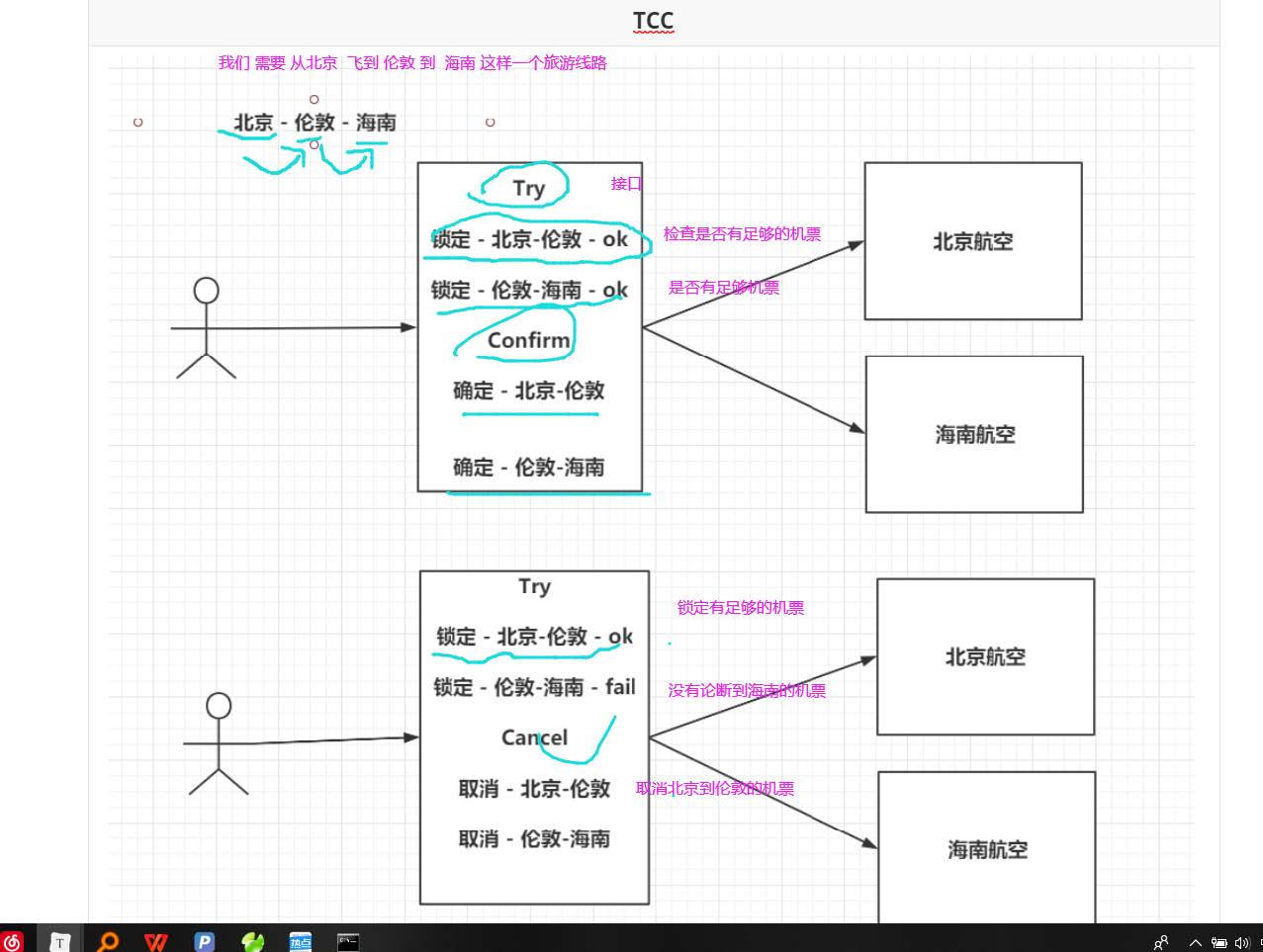
TCC机制 本质上和 2pc 流程基本上一致?
只不过TCC需要
1.将业务代码嵌套在 try 接口中 需要自己实现
2.需要检测资源是否可用
MQ分布式事务
使用消息队列(RabbitMQ)完成分布式事务
RabbitMQ在发送消息时,confirm机制,可以保证消息发送到MQ服务中,消费者有手动ack机
制,保证消费到MQ中的消息。这种模式全部需要自动手动来完成,非常的复杂,维护性很低
四种解决方法其实都是 2pc的变种,都是两阶段提交
五、seata
概述
Seata 是一款开源的分布式事务解决方案,致力于提供高性能和简单易用的分布式事务服务。Seata 将为用户提供了 AT、TCC、SAGA 和 XA 事务模式,为用户打造一站式的分布式解决方案。
地址https://seata.io/zh-cn/index.html
Seata 是springcloud alibaba 的一个组件,在使用是必须依赖springcloud alibaba 和注册中心(nacos)
控制器
Transaction Coordinator (TC): 事务协调器,维护全局事务的运行状态,负责协调并驱动全局事
务的提交或回滚;这是一个通讯员 负责协调各个子模块的事务
Transaction Manager(TM) : 控制全局事务的边界,负责开启一个全局事务,并最终发起全局
提交或全局回滚的决议;全局事务管理器是分布式全局事务的发起者,负责全局事务对额发起 和提交
Resource Manager (RM): 控制分支事务,负责分支注册、状态汇报,并接收事务协调器的指
令,驱动分支(本地)事务的提交和回滚。资源管理器,本地事务,负责本地事务的提交和回滚
原理
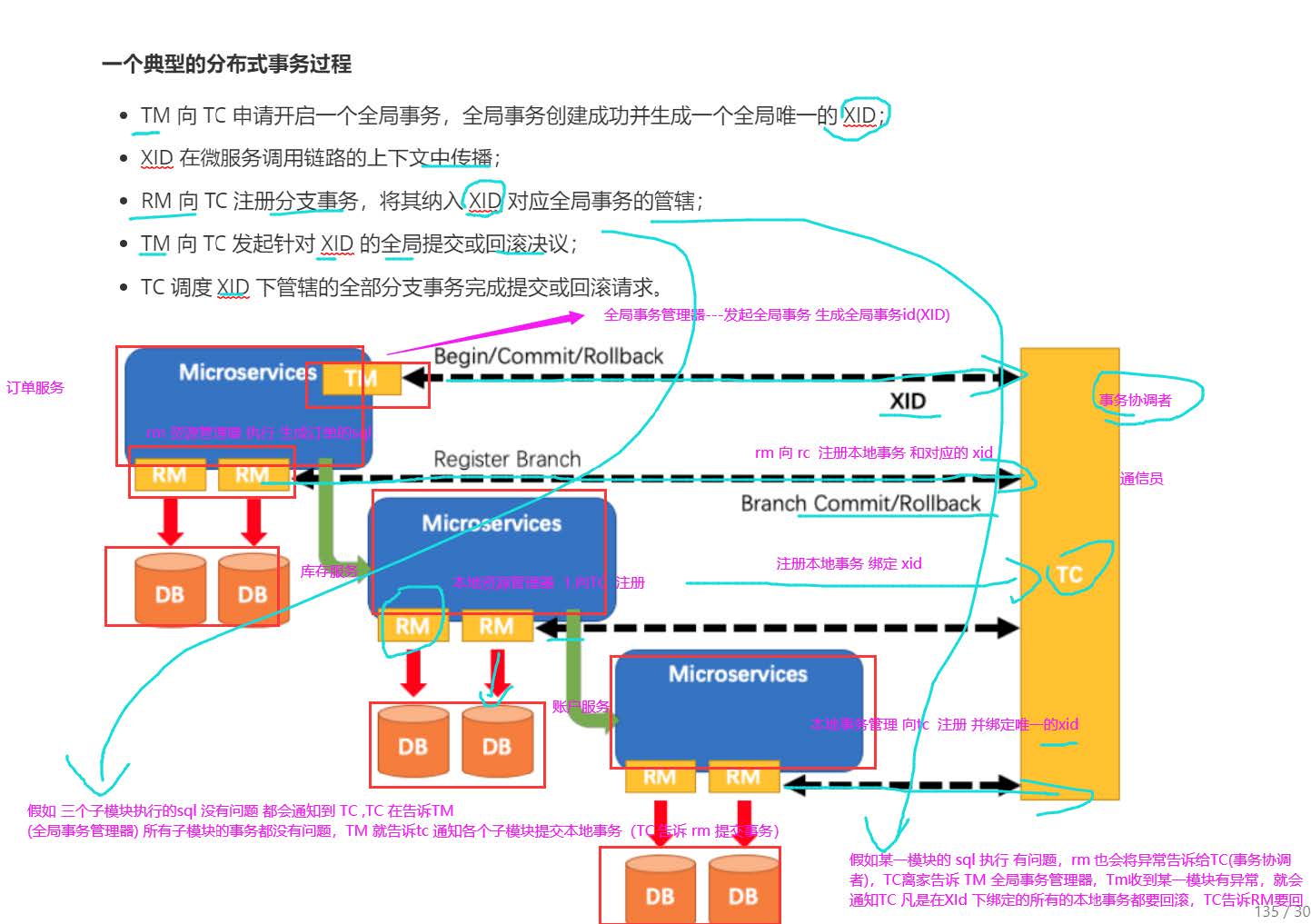
四种模式
AT
最简单的分布式事务模式,底层使用的 就是两阶段提交 ,使用seata 中的AT 只需要一个注解即可
两阶段提交协议的演变:
一阶段:业务数据和回滚日志记录在同一个本地事务中提交,释放本地锁和连接资源。
二阶段:提交异步化,非常快速地完成。回滚通过一阶段的回滚日志进行反向补偿。
TCC
TCC 模式,我们必须实现seata 为我们提供的TCC接口,所有的业务都需要自己实现,并且也要配合本地事务
好处:性能非常的好,但是需要工程师手写代码,难度稍微大一些
saga
长事务模式,适合在一个事务开启到提交耗费时间很长的场景
长事务:就是事务从开启到提交,时间耗费特别长的,一般长事务都特别耗费性能,并发能力非常低
XA
XA 模式其实就是AT模式的升级,更加的可靠,但是性能有所减低,使用起来也是很简单,只需要一条注解
六、实战
搭建seata服务
1、解压seata安装包
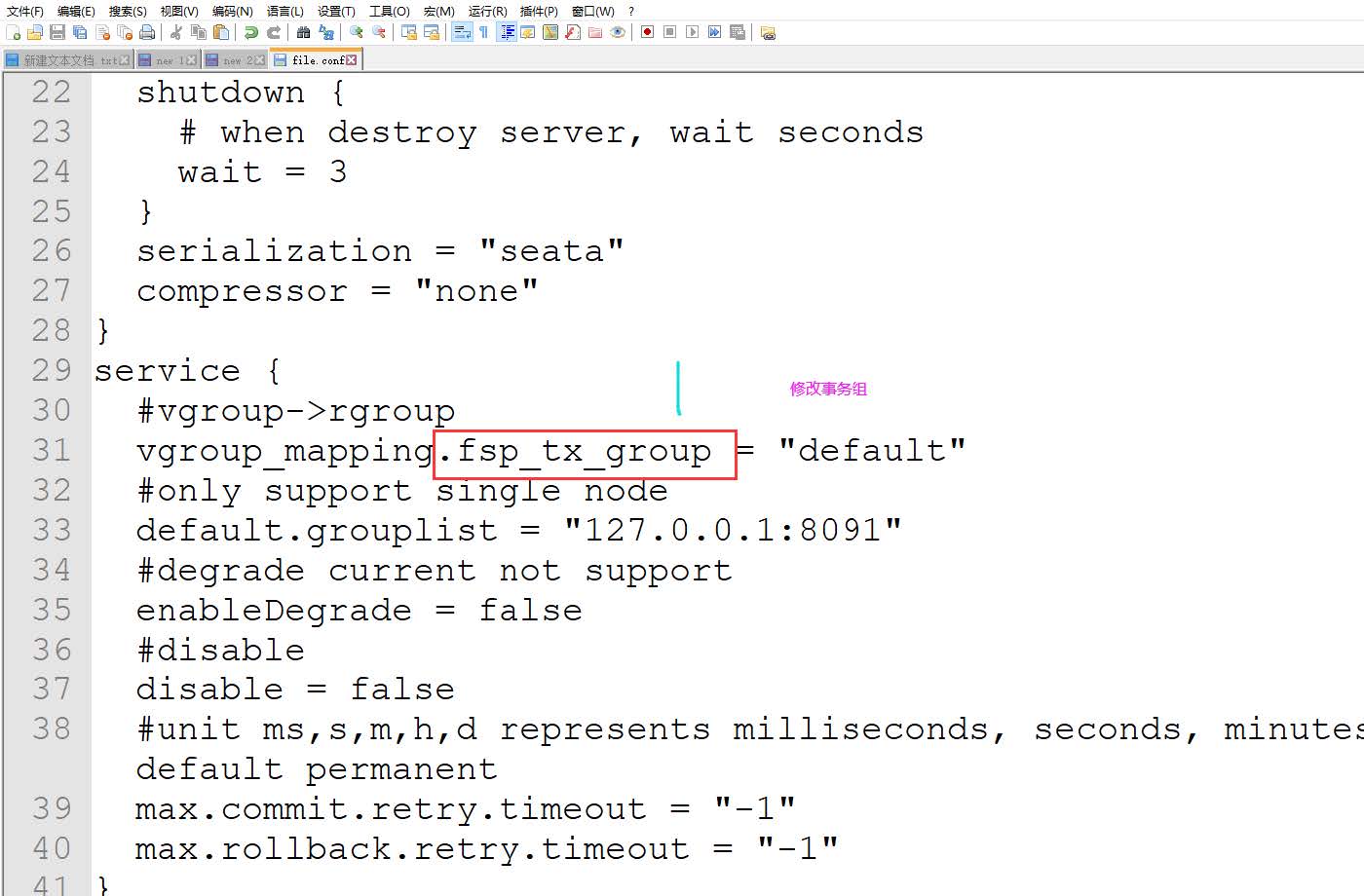
2、修改seata 配置文件
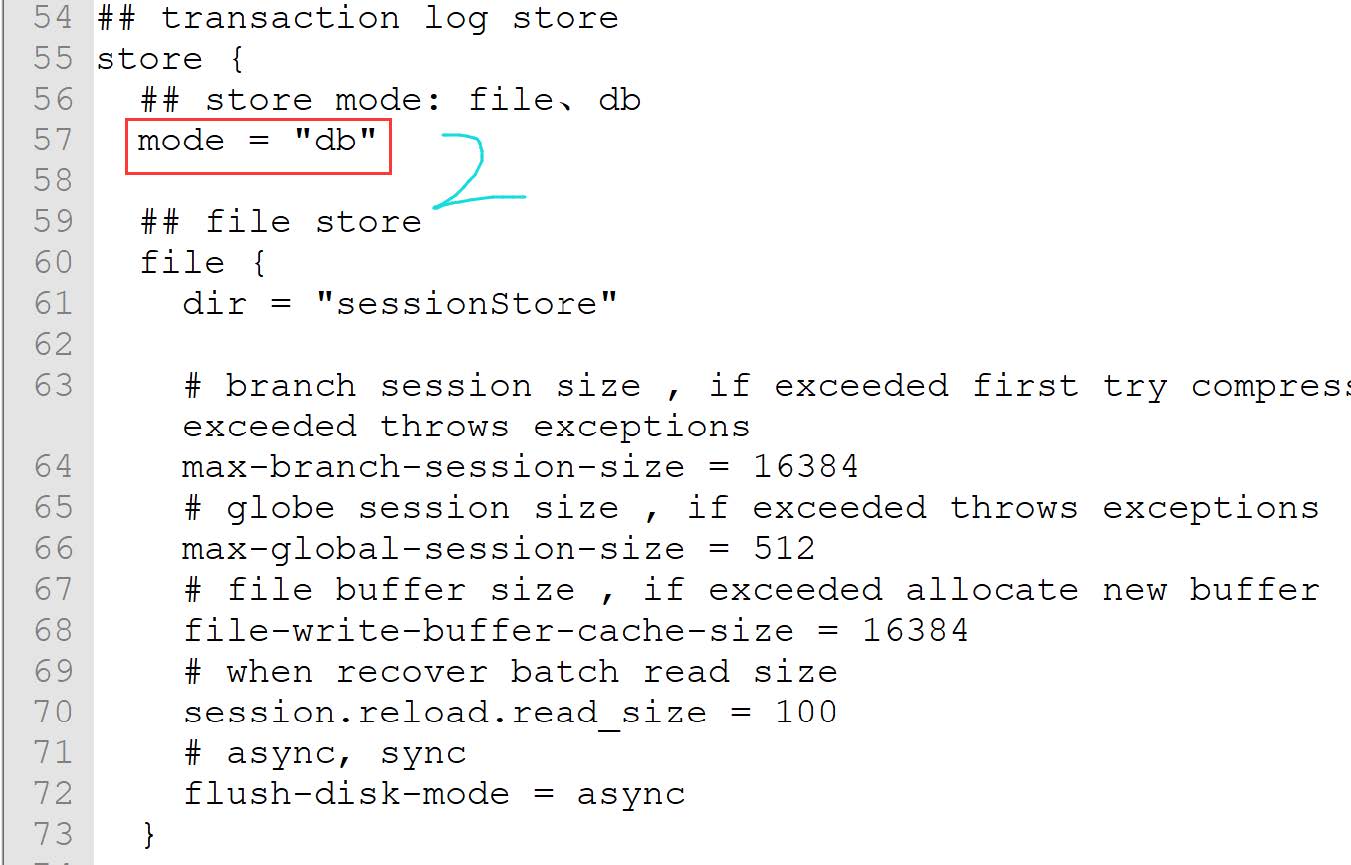
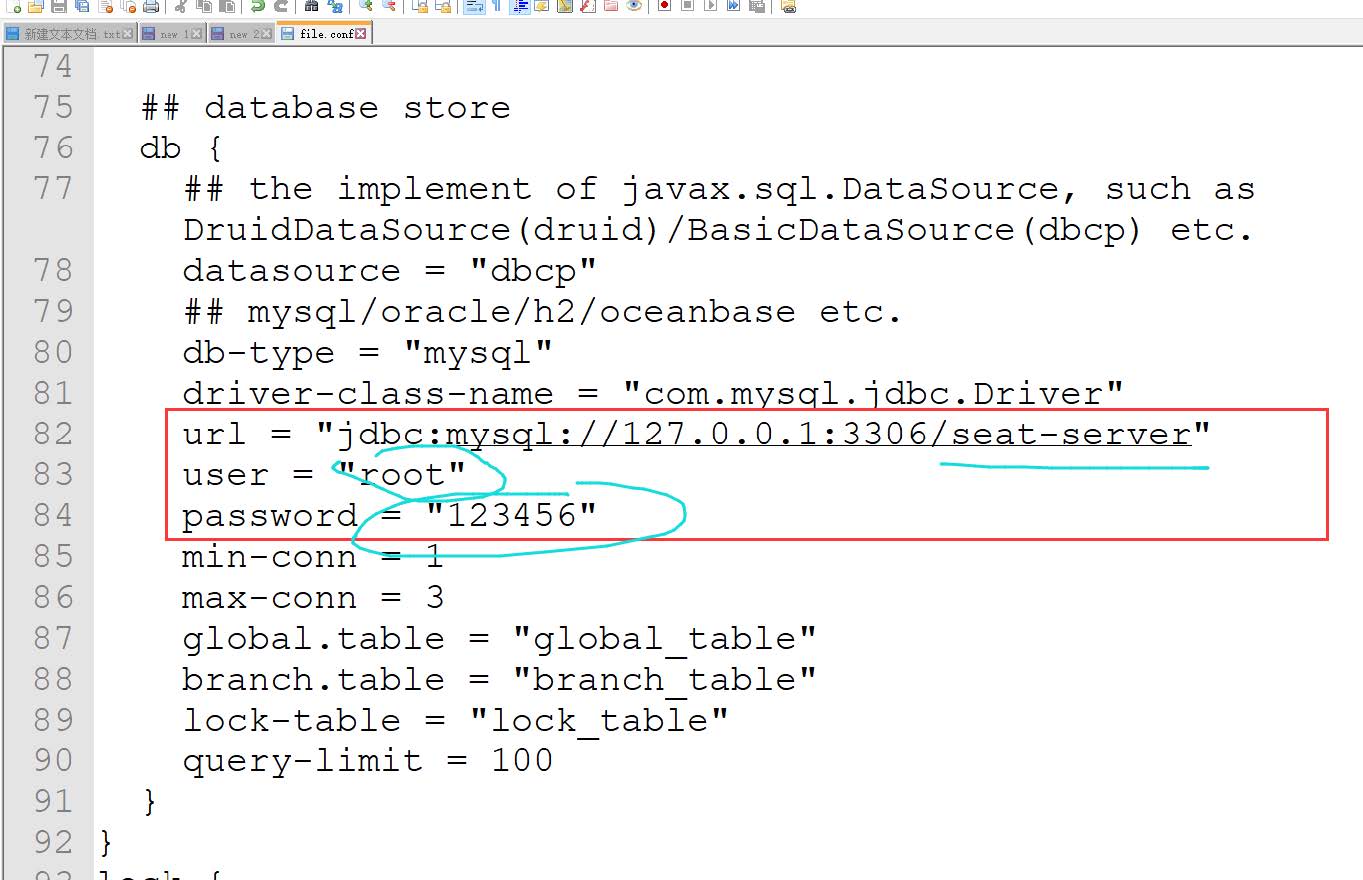
修改conf/file.conf
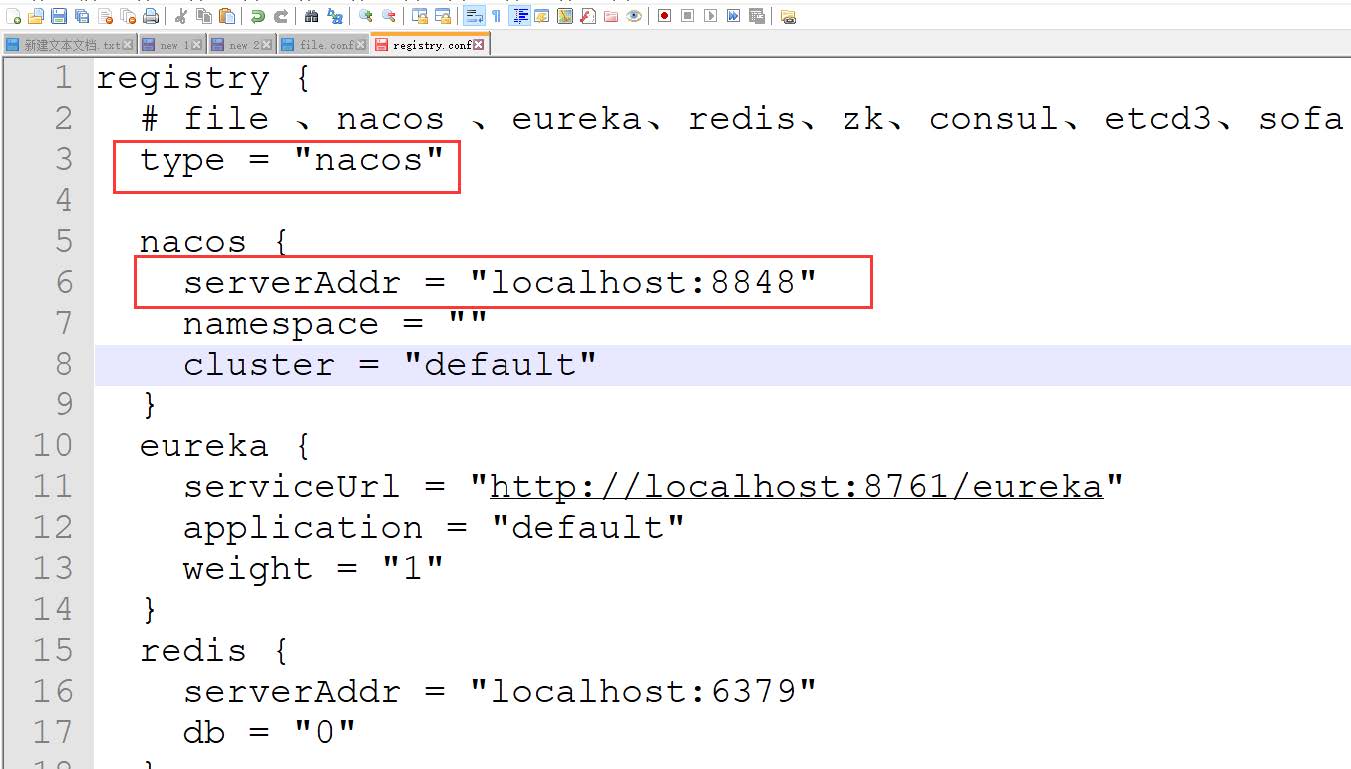
修改conf/registry.confseata
需要向nacos 进行注册
3、创建 seat-server 数据库,导入 conf/db_store.sql

4、启动seata服务
一定要在nacos 检查 一下
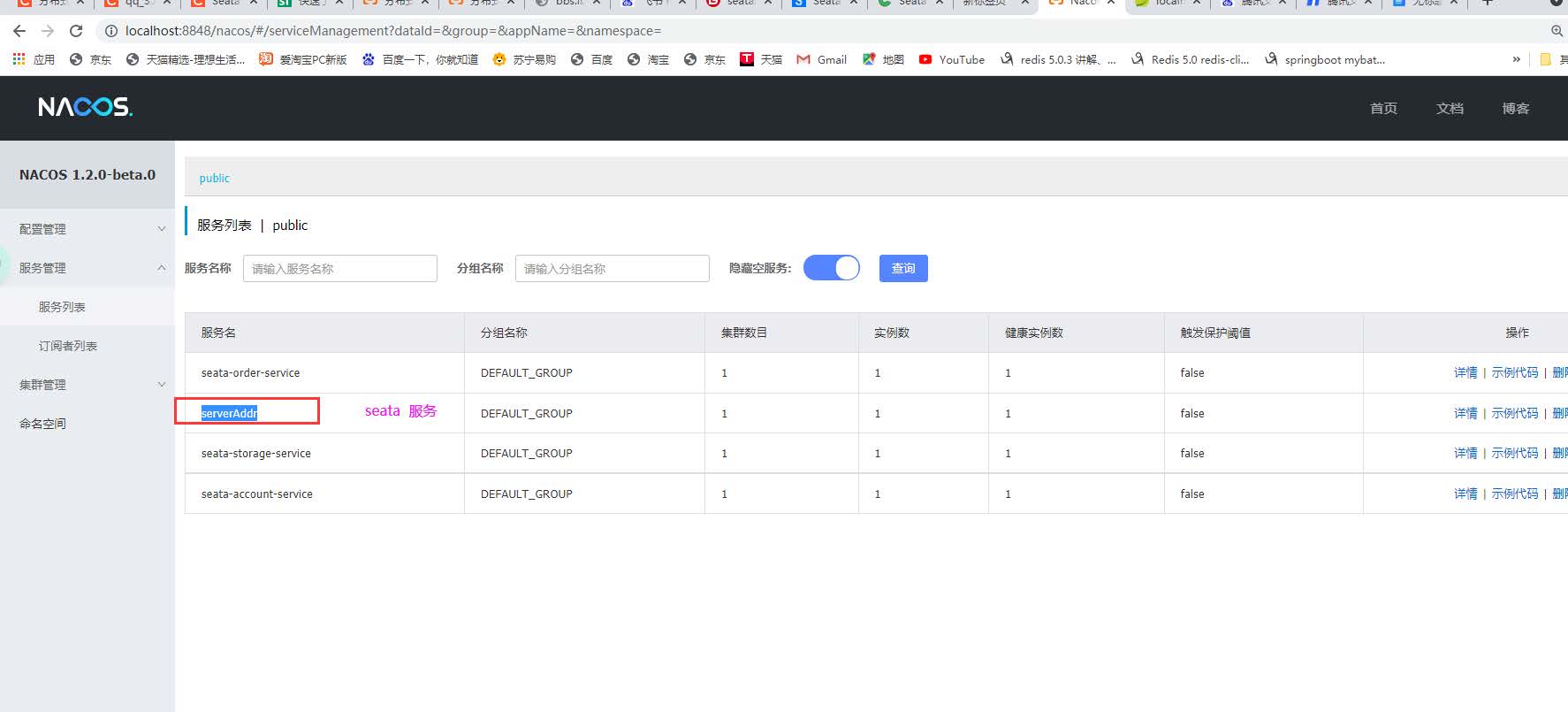
在生成订单为服务应用中使用开启seate 中的AT 事务
1、在订单的所有应用中的每一个数据库都导入conf/db_undo_log.sql
undo_log表就是为了 rm记录日志
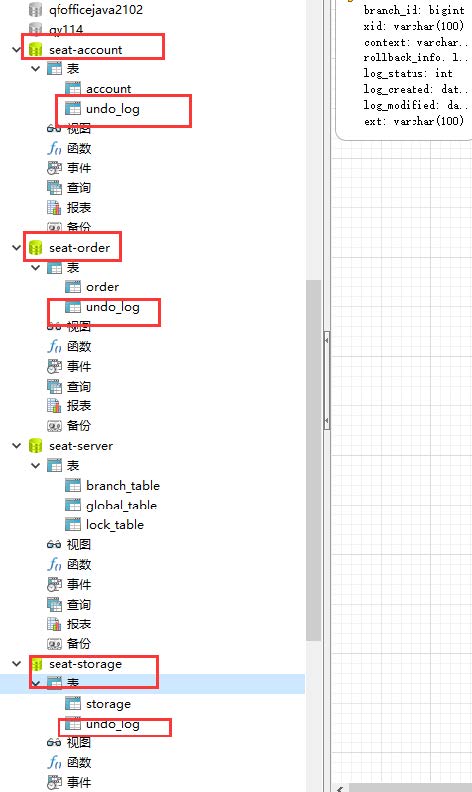
2、在三个订单的应用中都要加入seate 依赖
添加依赖
<!--seata-->
<dependency>
<groupId>com.alibaba.cloud</groupId>
<artifactId>spring-cloud-starter-alibaba-seata</artifactId>
<exclusions>
<exclusion>
<artifactId>seata-all</artifactId>
<groupId>io.seata</groupId>
</exclusion>
</exclusions>
</dependency>
<dependency>
<groupId>io.seata</groupId>
<artifactId>seata-all</artifactId>
<version>${seata.version}</version>
</dependency>
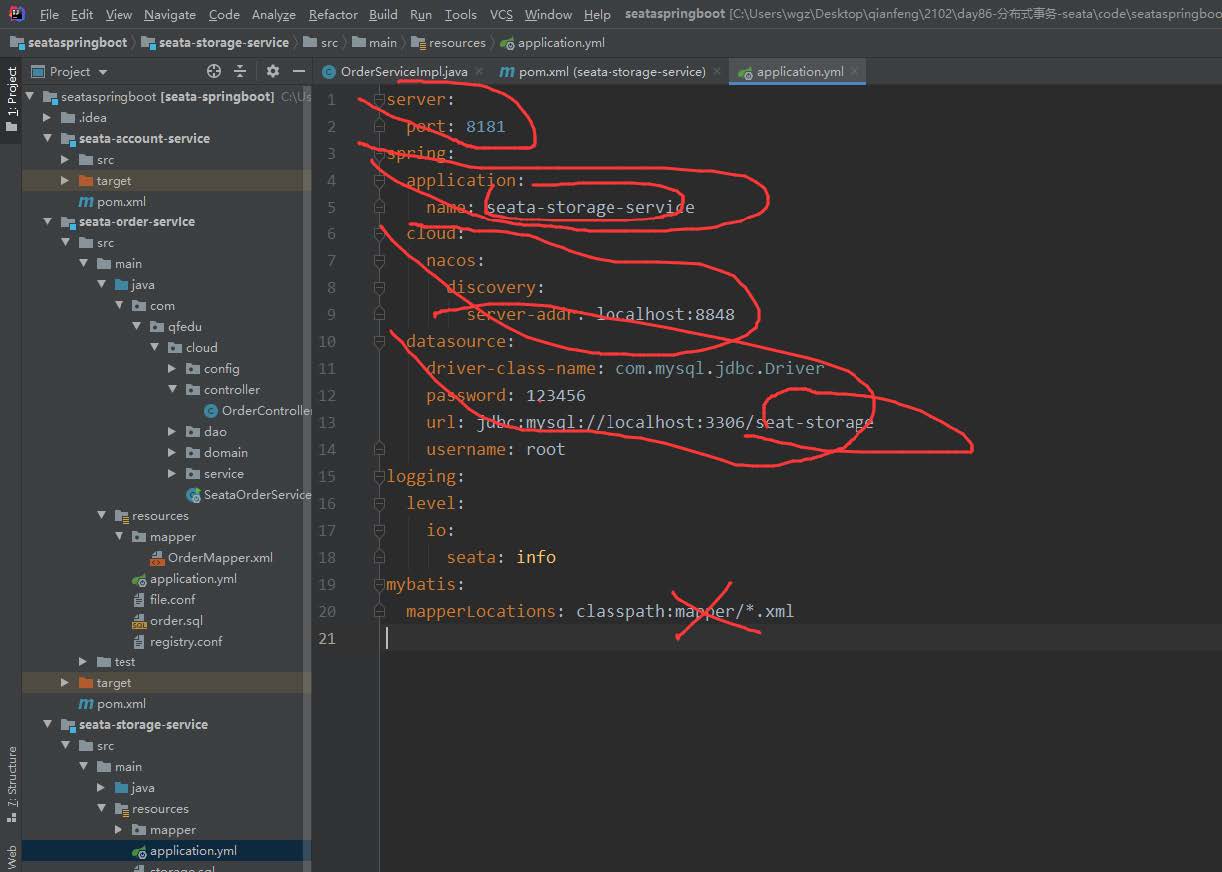
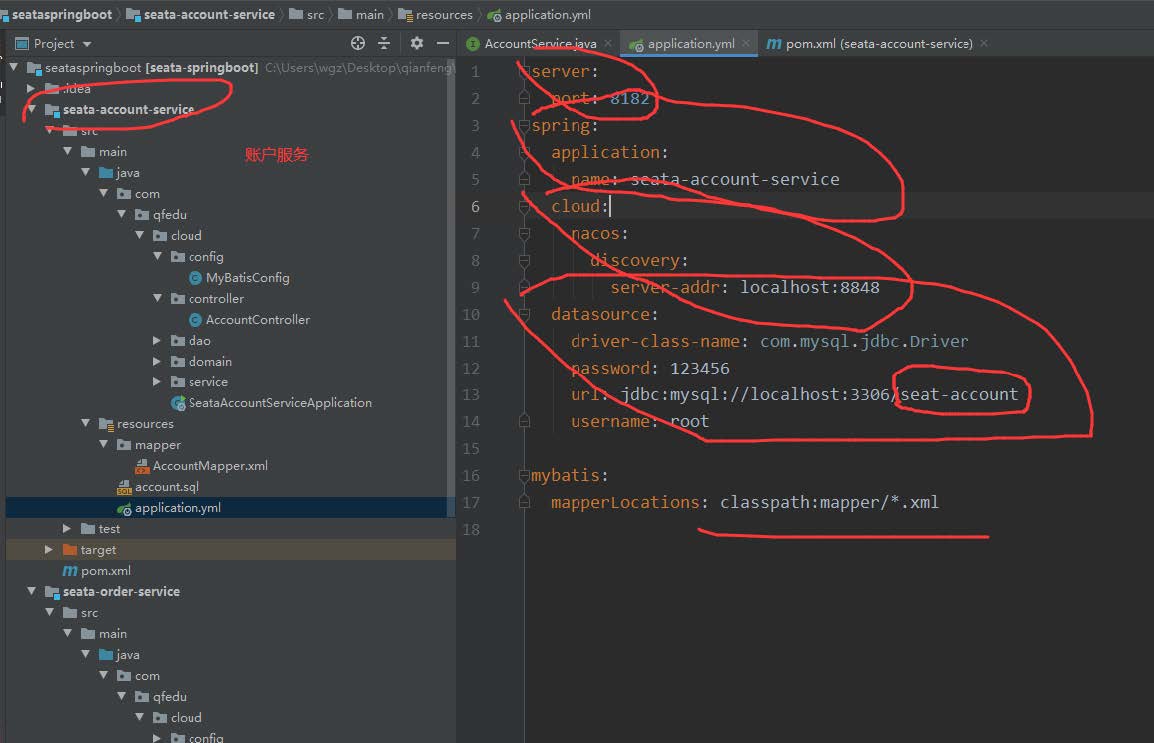
3、配置文件application.yaml增加
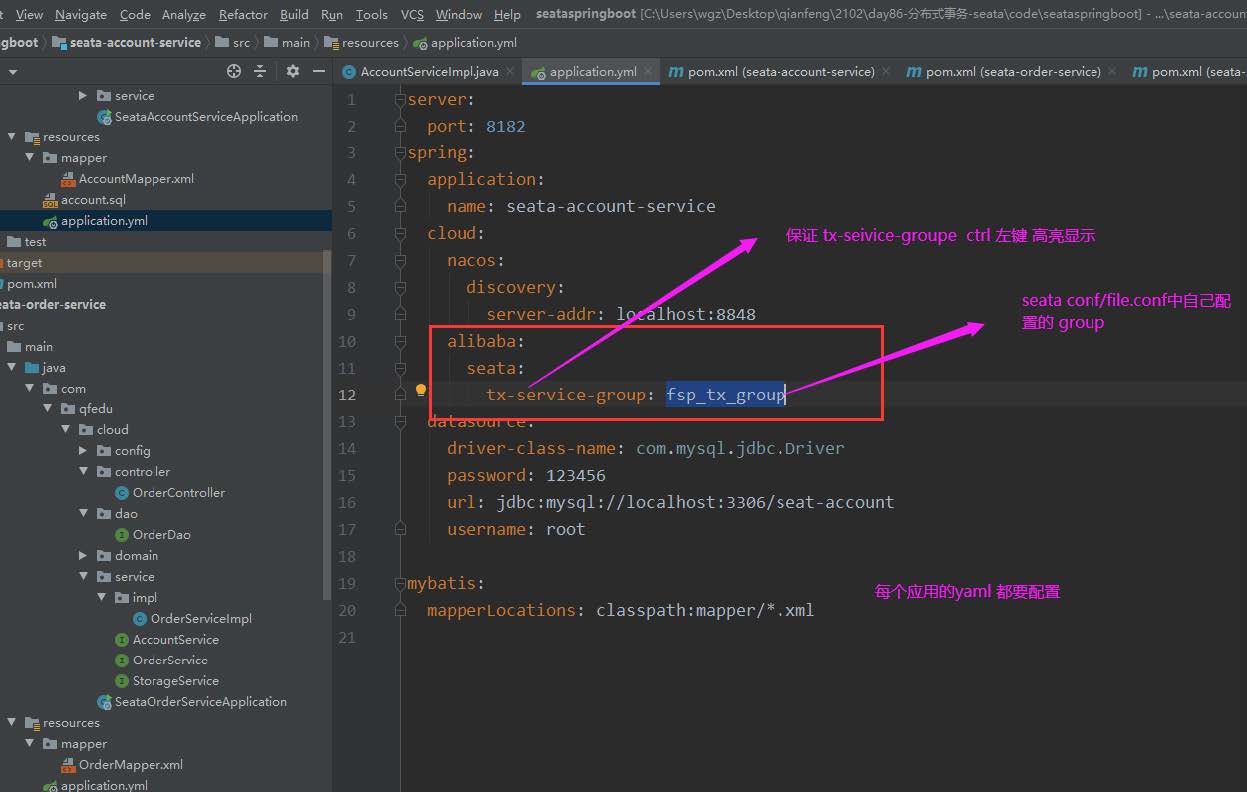
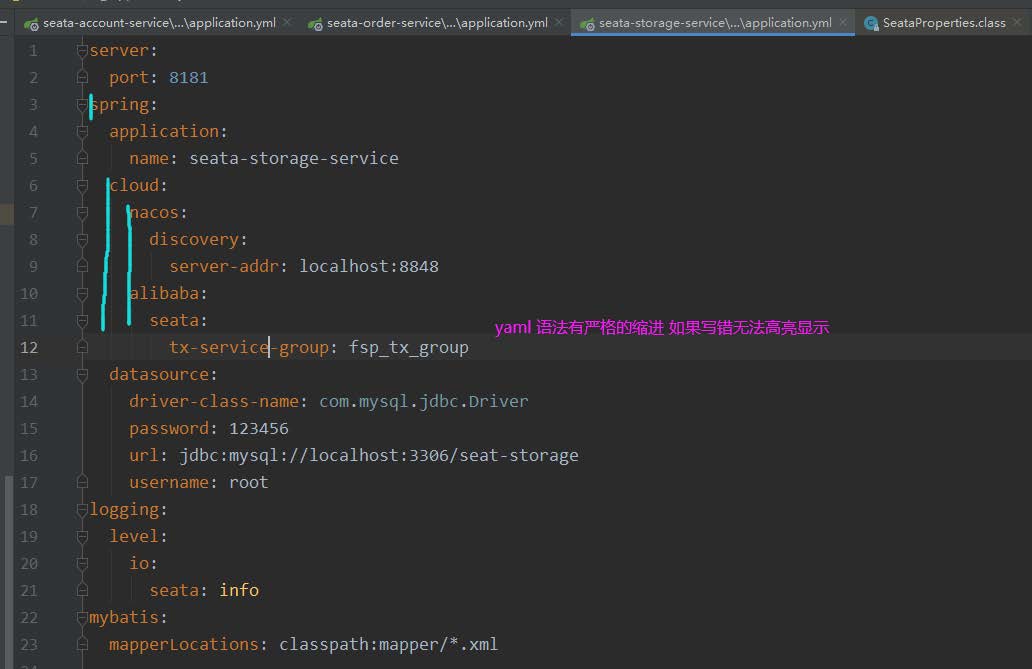
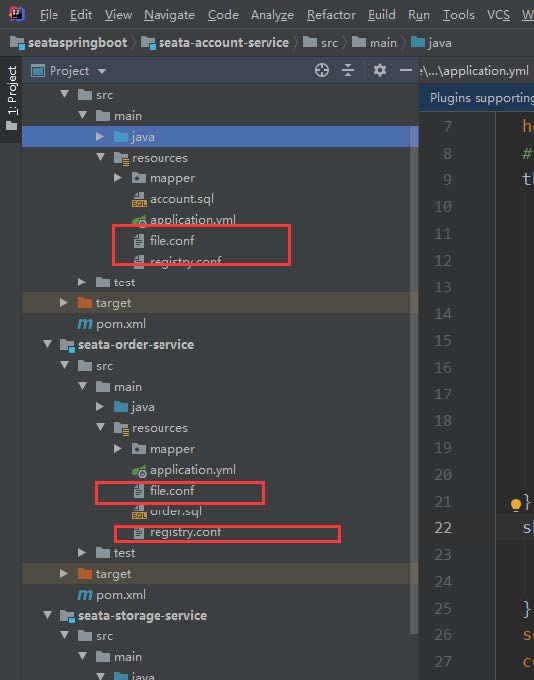
4、将seata conf/file.conf conf/registry.conf 分别拷贝到 三个应用的resource 中
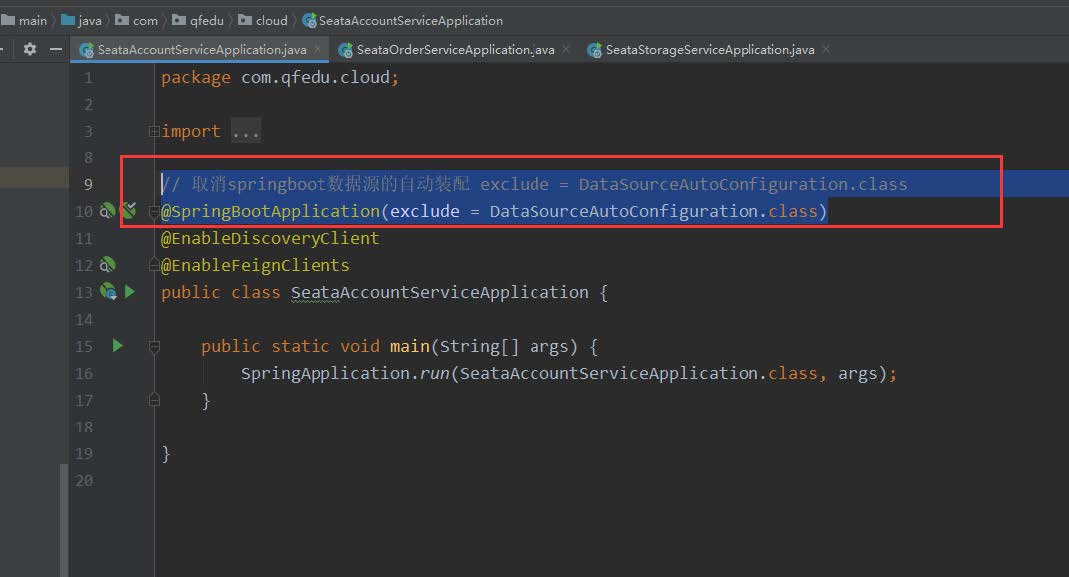
5、在三个应用中启动类都屏蔽 数据源自动装配
// 取消springboot数据源的自动装配 exclude = DataSourceAutoConfiguration.class
@SpringBootApplication(exclude = DataSourceAutoConfiguration.class)
6、在三个应用中配置自定义数据源 conf/DataSourceProxyConfig
import com.alibaba.druid.pool.DruidDataSource;
import io.seata.rm.datasource.DataSourceProxy;
import org.apache.ibatis.session.SqlSessionFactory;
import org.mybatis.spring.SqlSessionFactoryBean;
import org.mybatis.spring.transaction.SpringManagedTransactionFactory;
import org.springframework.beans.factory.annotation.Value;
import org.springframework.boot.context.properties.ConfigurationProperties;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.core.io.support.PathMatchingResourcePatternResolver;
import javax.sql.DataSource;
/**
*配置类:
* 作用就是转配数据源 将druid 数据源进行一个封装 代理
*/
@Configuration
public class DataSourceProxyConfig {
@Value("${mybatis.mapperLocations}")
private String mapperLocations;
/**
* 创建DruidDataSource druid数据源(连接池)
* @return
*/
@Bean
@ConfigurationProperties(prefix = "spring.datasource")
public DataSource druidDataSource(){
return new DruidDataSource();
}
/**
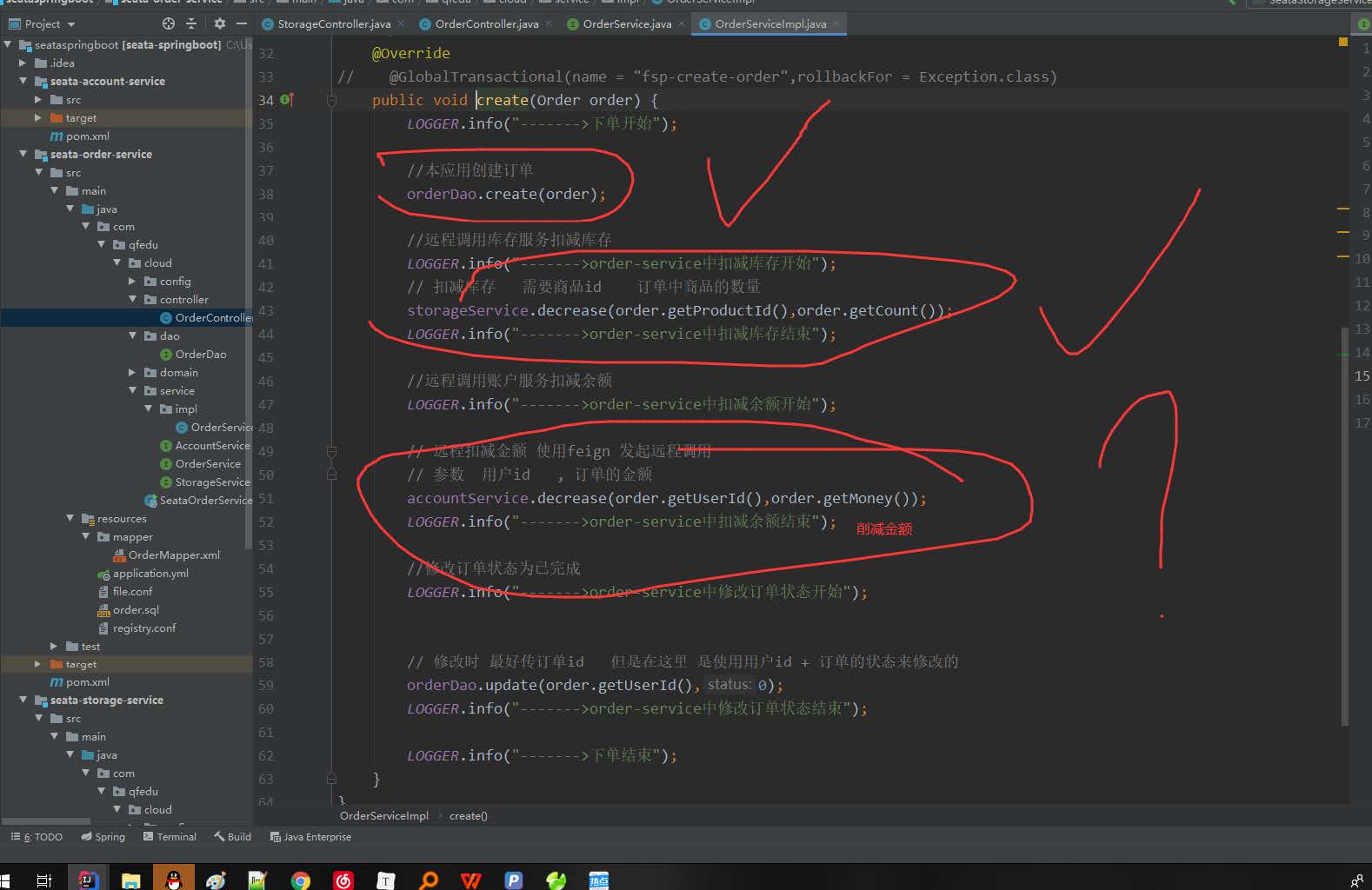
3.在订单服务中发起 分布式事务
@GlobalTransactional(name = "fsp-create-order",rollbackFor = Exception.class) // 开启seata 分布
式事务 // 默认情况下使用AT 模式开启分布式事务
* 创建 druid数据源 的代理
* @param dataSource
* @return
*/
@Bean
public DataSourceProxy dataSourceProxy(DataSource dataSource) {
return new DataSourceProxy(dataSource);
}
/**
* 配置自定义SqlSessionFactory 使用代理数据源创建SqlSession 所有分布式事务的提交
和回滚都通过 DataSourceProxy
* @param dataSourceProxy
* @return
* @throws Exception
*/
@Bean
public SqlSessionFactory sqlSessionFactoryBean(DataSourceProxydataSourceProxy) throws Exception {
SqlSessionFactoryBean sqlSessionFactoryBean = new
SqlSessionFactoryBean();
sqlSessionFactoryBean.setDataSource(dataSourceProxy);
sqlSessionFactoryBean.setMapperLocations(newPathMatchingResourcePatternResolver()
.getResources(mapperLocations));
sqlSessionFactoryBean.setTransactionFactory(new
SpringManagedTransactionFactory());
return sqlSessionFactoryBean.getObject();
}
}
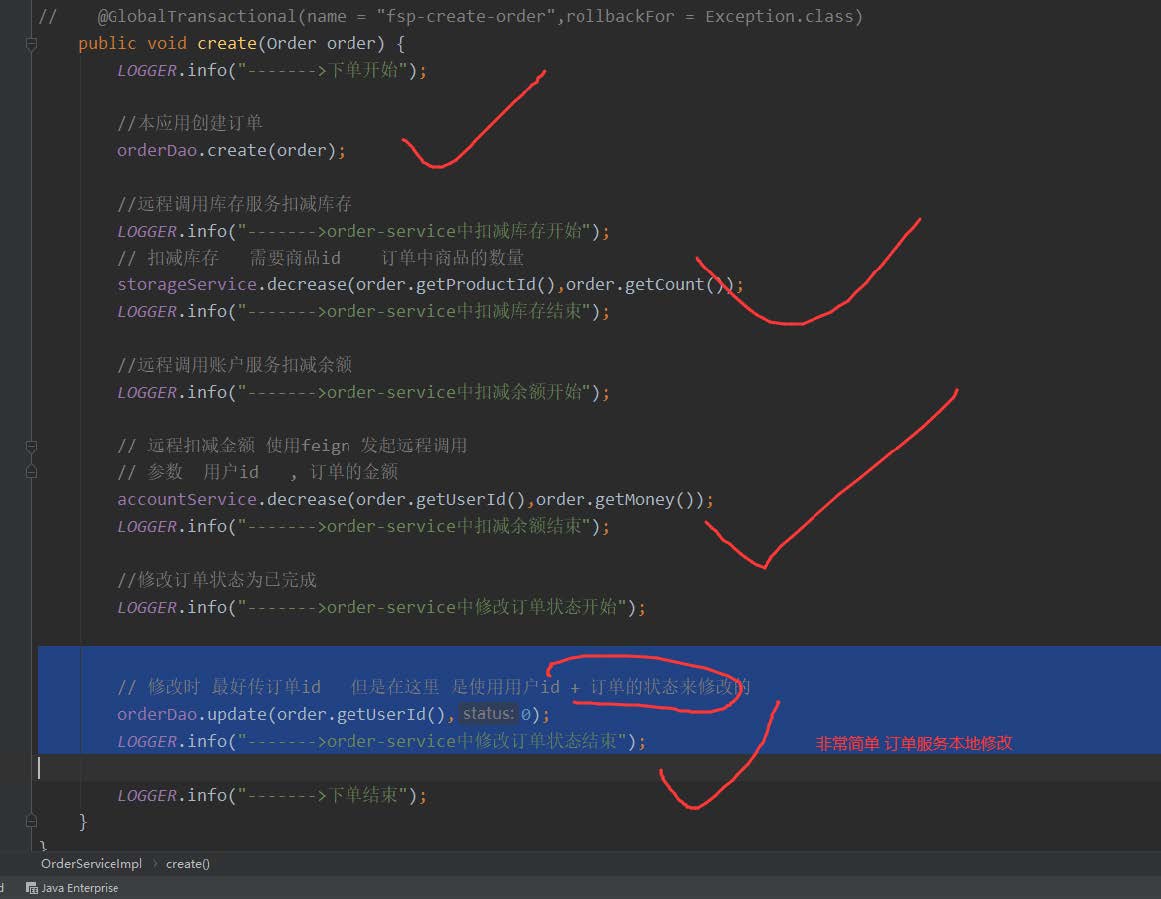
7、在订单服务中发起 分布式事务
@GlobalTransactional(name = “fsp-create-order”,rollbackFor = Exception.class) // 开启seata 分布式事务 // 默认情况下使用AT 模式开启分布式事务
@Override
@GlobalTransactional(name = "fsp-create-order",rollbackFor = Exception.class) //
开启seata 分布式事务 // 默认情况下使用AT 模式开启分布式事务
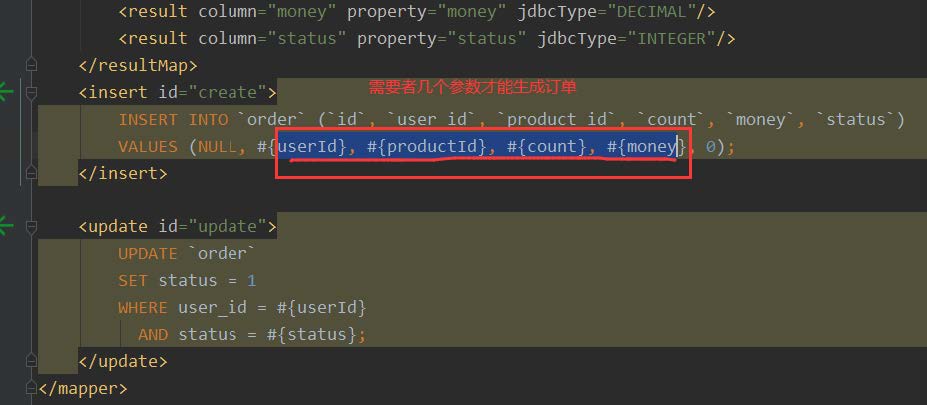
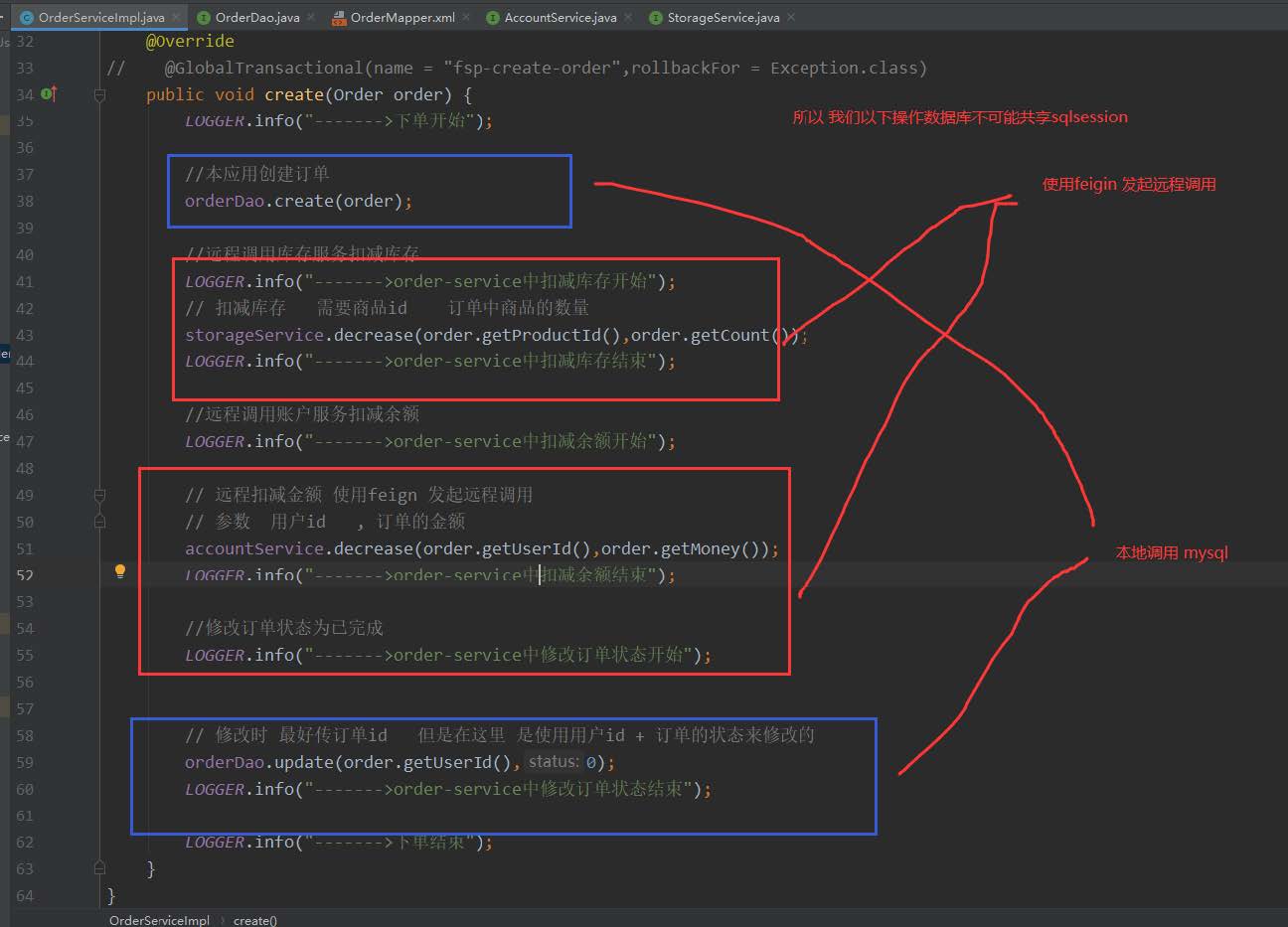
public void create(Order order) {
LOGGER.info("------->下单开始");
//本应用创建订单
orderDao.create(order);
//远程调用库存服务扣减库存
LOGGER.info("------->order-service中扣减库存开始");
// 扣减库存 需要商品id 订单中商品的数量
storageService.decrease(order.getProductId(),order.getCount());
LOGGER.info("------->order-service中扣减库存结束");
//远程调用账户服务扣减余额
LOGGER.info("------->order-service中扣减余额开始");
4.重新启动 订单的三个应用,并检查
5.测试
http://localhost:8180/order/create?userId=1&productId=1&count=1&money=100
// 远程扣减金额 使用feign 发起远程调用
// 参数 用户id , 订单的金额
accountService.decrease(order.getUserId(),order.getMoney());
LOGGER.info("------->order-service中扣减余额结束");
//修改订单状态为已完成
LOGGER.info("------->order-service中修改订单状态开始");
// 修改时 最好传订单id 但是在这里 是使用用户id + 订单的状态来修改的
orderDao.update(order.getUserId(),0);
LOGGER.info("------->order-service中修改订单状态结束");
LOGGER.info("------->下单结束");
}
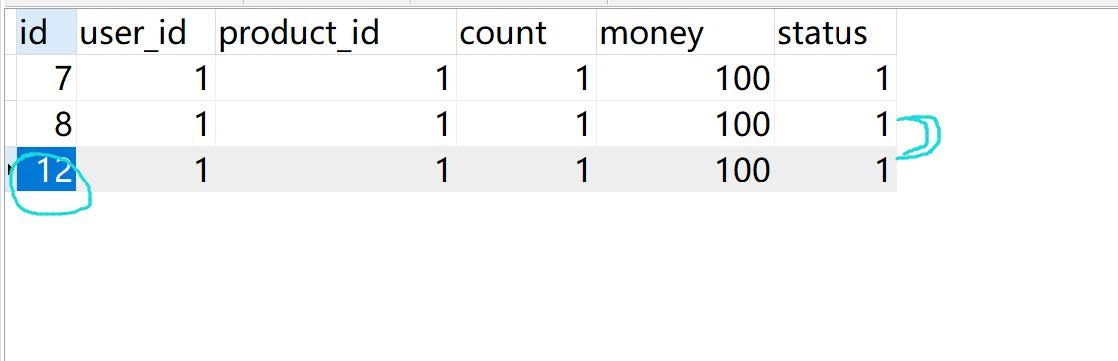
8、重新启动 订单的三个应用,并检查

9、测试
访问http://localhost:8180/order/create?userId=1&productId=1&count=1&money=100
以上是关于分布式事务的主要内容,如果未能解决你的问题,请参考以下文章