探索 Kotlin 的隐性成本(Part 1)
Posted OSC开源社区
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了探索 Kotlin 的隐性成本(Part 1)相关的知识,希望对你有一定的参考价值。
点击图片报名参加广州&珠海源创会
2016年,杰克·沃顿(Jake Wharton)就 Java 的隐性成本进行了一系列有趣的演讲。 在同一时期,他也开始倡导使用 Kotlin 语言进行 android 开发,但除了推荐大家使用这门语言的内联函数特性之外,他几乎没有提到说使用该语言会产生什么隐藏成本。 现在 Kotlin 在 Android Studio 3 中得到了 Google 的正式支持,而我想着通过研究它所生成的字节码来写写这个方面的东西也许是个好主意。
Kotlin 是一种现代编程语言,与 Java 相比,它拥有更多的语法糖,而因此也会拥有更多藏起来的“黑魔法”,其中一些要用的话就会有不可忽略的成本,特别是对于那些年头比较久还有版本比较低的 Android 终端设备。
这里并不是要抵制 Kotlin: 我非常喜欢这门语言,它提高了生产效率,而我也相信作为一个好的开发也需要去了解语言特性内部是如何运作的,以此才能更加好的利用它们。Kotlin 功能强大,而正所谓:
“能力越强责任越大。”
这些文章只会关注 Kotlin 1.1 在 JVM/Android 的实现,不会涉及其 javascript 的实现。
Kotlin 字节码查看器
这是了解 Kotlin 如何被翻译成字节码的首选工具。只要在 Android Studio 安装好 Kotlin 插件,然后选择 “Show Kotlin Bytecode” 操作,来打开一个面板显示出当前 class 文件的字节码。然后你就能按下 “Decompile” 按钮来读取出对应的 Java 代码。
这里要特别提一下,我每次提到一个 Kotlin 特性都要涉及如下几个方面的内容:
装箱的原生类型,他们会分配给生存时间较短的对象。
实例化附加的对象不会直接在代码中显示出来。
生成附加方法。你也许会了解,在 Android 应用程序中,一个 dex 文件中方法的数量是有限制的,而且在上述情况下,考虑到多个 dex 会带来限制于性能损失的叠加影响,特别是在 Lollipop 之前版本的 Android 系统之上。
关于基准的说明
我特意选择不发布任何微基准,因为大部分都是没有意义的,或者有缺陷,或者两者皆有,并且不能应用于所有的代码变化和运行环境。 在循环或嵌套循环中使用相关代码时,通常会放大负面性能影响。
此外,执行时间并不是衡量的唯一事项:也必须把新增内存使用纳入考量,因为最终所有分配的内存都要回收,而垃圾收集的成本取决于诸多因素,如可用内存和平台所使用的 GC(Garbage Collection,垃圾收集)算法。
简而言之,如果你想知道一个 Kotlin 构造是否具有一些显著的速度或内存影响,那就要在你自己的目标平台上测量你自己的代码。
高阶函数与 Lambda 表达式
Kotlin 支持把函数赋值给变量并传递变量作为其他函数的参数。接受其他函数作为参数的函数称为高阶函数。一个 Kotlin 函数可以由它的名字加前缀 :: 而引用,或直接在代码块中声明一个匿名函数,或使用 lambda 表达式语法。此中第三种是描述一个函数的最紧凑的方式。
Kotlin 是给 Java 6/7 JVM 和 Android 提供 lambda 表达式支持的最佳方式之一。
考虑下面的实用函数,它在数据库事务中执行任意操作,并返回受影响行的数量:
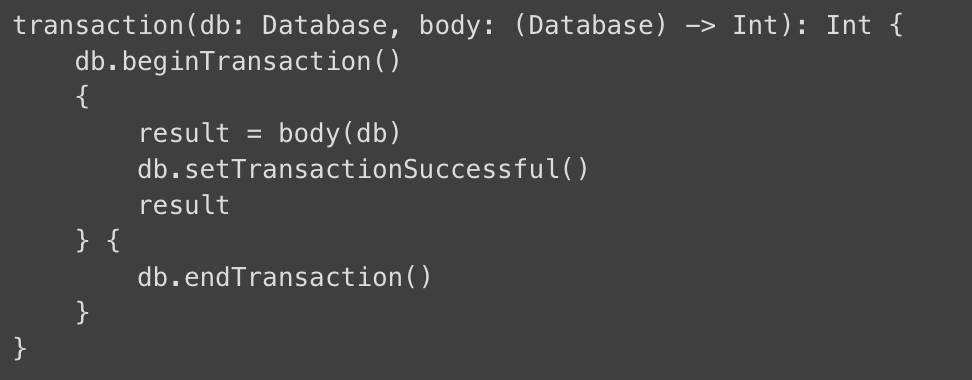
我们可以通过使用类似于 Groovy 的语法传递一个 lambda 表达式作为最后的参数:

但 Java 6 JVM 不直接支持 lambda 表达式。那么它们是如何转换成字节码的呢?也许正如你所期望的, lambda 表达式和匿名函数被编译为函数对象。
函数对象
这是 Lambda 表达式编译后对应的 Java 呈现。

在 Android dex 文件中,每个 Lambda 表达式都被编译成函数,实际上它会导致增加 3 到 4 个方法。
好消息是这些函数对象的新实例只会在必要的时候创建,这在实践中就意味着:
对于捕获(capturing)表达式,每次将 Lambda 作为参数传递的时候都会创建新的函数实现,它会在执行后被垃圾回收器回收;
对于非捕获(non-capturing)表达式(纯函数),则会创建一个单例函数实例,以便后面用到的时候可以复用。
[译者注:捕获 Lambda 表达式指在表达式内部访问了表达式外的非静态变量或者对象的表达式,非捕获 Lambda 表达式反之]
既然我们示例中的调用代码使用了非捕获 Lambda,它会被编译成单例而不是一个内部类:
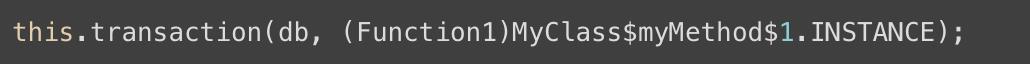
如果标准(非内联)的高阶函数调用捕获 Lambda,应该避免对其进行重复调用以减少垃圾回收器的压力。
装箱的开销
与 Java 8 不同,Java 8 大约有43 个不同的特定函数接口用于尽可能地避免装箱和拆箱。由 Kotlin 编译出来的函数对象只实现完全通用的接口,高效地将 Object 类型用于输入或输出值。

这表示在高阶函数中调用作为参数传入的函数,如果函数涉及基本类型(比如 Int 或 Long),实际上会对输入值和返回值有计划地装箱和拆箱。这可能会对性能产生不可忽视的影响,尤其是在 Android 中。
在我们上面编译的 Lambda 中,你可以看到结果是装箱成 Integer 对象的。调用者代码随后会对其进行拆箱操作。
在写一个函数作为参考的标准(非内联)高阶函数时,如果这个作为参数的函数使用的是基本类型的输入或输出值,那就要小心了。调用这个作为参数的函数会因为装箱和拆箱操作给垃圾收集器带来更大的压力。
用内联函数解决相关问题
幸好,在使用 Lambda 表达式的时候,Kotlin 有一个神奇的技巧来避免这些开销:将高级函数声明为 inline。编译器会将函数体直接内联到调用代码内部,完全避免了调用。对于高阶函数来说,更大的好处在于,作为参数的 Lambda 表达式也会被内联。实际的影响包括:
声明 Lambda 不会产生函数对象实例;
Lambda 的输入或输出有基本类型时,不会产生装箱或拆箱动作;
不会造成方法数量的增加;
没有实际调用函数。这对于需要多次调用而且重度使用 CPU 的代码来说可以提升性能。
我们在将 transaction() 函数声明为内联函数之后,调用代码的 Java 呈现就变成了:
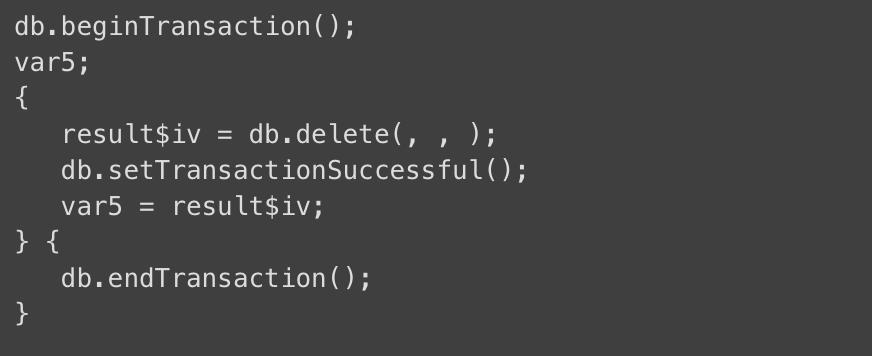
这个杀手锏有一些需要注意的地方:
内部函数不能调用自身,也不能通过其它内联函数调用自身。[译者注:简单地说就是不能用于内联的递归];
类中声明为 public 的内联函数只能访问这个类的公有函数和字段;
代码大小会有所增长。内联一个被使用多次的长函数会使生成的代码相当大,如果这个长函数引用了其它内联的长函数,就更不得了。
如果可能,就将高阶函数内联。保持简短,若有必要,可将大块代码搬到非内联函数中。
对于要求性能的代码所调用的函数,也可以声明内联。
我们会在以后的文章中讨论内联函数其它性能方面的优点。
伴生对象
Kotlin 的类没有静态字段或方法。取而代之,实例不相关的字段和方法可以在类中的一个伴生对象中声明。
从其伴生对象访问私有类字段
考虑下面的示例:

在编译时,一个伴生对象被实现为一个单件类。这意味着,就像需要从其他类访问任意 Java 类的私有字段,从伴生对象访问外层类的私有字段(或构造器)将会产生额外的合成的 getter 和 setter 方法。对类字段的每次读或写访问都将导致在伴生对象中的一次静态方法调用。

在 Java 中,我们会对这些字段使用 package 的访问权限来避免生成这些方法。然而,Kotlin 中没有 package 级别的访问权限。使用 public 或者 internel 代替的话将导致 Kotlin 产生默认的 getter 或者 setter 示例方法来使字段对外部世界可访问,并且,调用示例方法从技术上来说,比调用静态方法的成本更大。因此,不要因为优化而改变字段的访问权限。
如果你需要从伴侣对象中反复读或写以访问类字段,你可以将它的值缓存在本地的变量中来避免反复的隐性方法调用。
访问伴生对象中所声明的常量
在 Kotlin 中,你通常会在伴生对象中声明一个在类中使用的“静态”常量。

代码看起来是既整齐有简单,但底层做的事情那可是相当的挫。
由于跟之前所提到的相同的原因,访问伴生对象中声明的私有常量实际上会在伴随对象的实现类中额外再生成一个合成的 getter 方法。

而问题却是更加的严重。因为合成方法实际上并不返回值; 它调用的一个实例方法,实际就是由 Kotlin 生成的一个 getter:

当常量被声明为 public 而不是 private 的时候,这个 getter 方法就是公开的,可以被直接调用,因此不需要签署步骤的合成方法。 但是 Kotlin 仍然需要调用 getter 方法来读取一个常量。
那么,这样就可以了吗? 并不是!事实证明,为了存储常量值,Kotlin 编译器在主类里面,而不是在伴生对象里面,实实在在地生成了一个私有静态 final 域。 不过,由于静态域在类中被声明成了私有的,所以需要另外有一个合成方法来从伴生对象访问到它。

最终,合成方法读取的实际值如下:

换句话说,当你从 Kotlin 类的伴生对象中访问一个私有常量字段时,与 Java 直接读取静态字段不同,你的代码实际上将操作:
在伴生对象中调用静态方法
接着在伴生对象中调用示例方法
接着在类中调用静态方法
接着读取静态字段并返回值
以下是等同的 Java 代码:
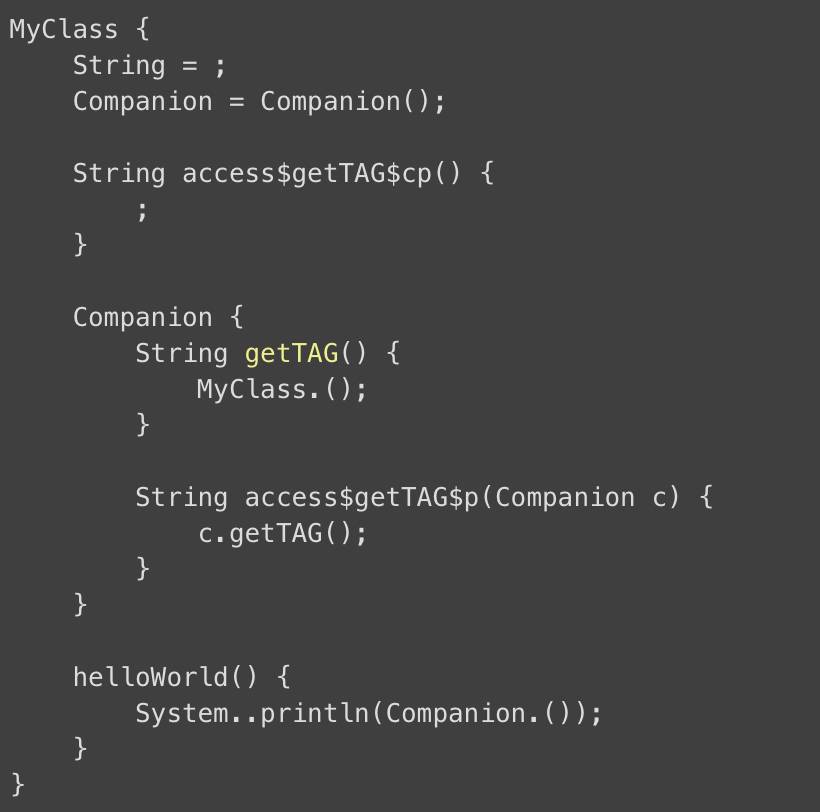
所以,我们能得到更简洁的字节码吗?答案是肯定的,但不是任何情况都可以。
首先,通过使用 const 关键字声明作为编译时常量的值,我们可以完全避免任何方法的调用。这将在代码调用时直接有效地内联这个值,但你只能在处理基础类型和字符串时才能使用。

其次,您可以在伴生对象的公共字段中使用 @JvmField 注释来指示编译器不会生成任何 getter 或 setter,并将其作为类中的静态字段公开,就像纯 Java 常量一样。 实际上,这个注释是为了兼容 Java 而创建的,如果您不需要使用常量来从 Java 代码访问,那么绝对不会建议您将美丽的 Kotlin 代码与模糊的交互注释相混淆。 而且,它只能用于 public 领域。 在 Android 开发的上下文中,您只能使用此注释来实现 Parcelable 对象:
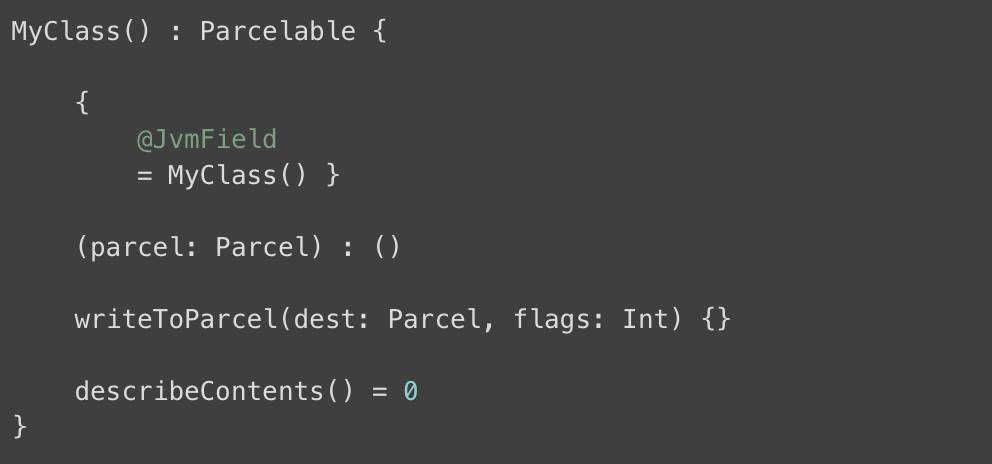
最后,您还可以使用 ProGuard 工具来优化字节码,并希望将这些链接的方法调用合并在一起,但绝对不能保证这将正常工作。
从伴生对象中读取一个“静态”常量,可以在 Kotlin 中添加两到三个间接级别,而对于 Java 来说每个这些常量,将会生成两到三个额外的方法。 始终使用 const 关键字声明原始类型和 String 常量来避免这种情况。 对于其他类型的常量,您不能这样做,所以如果您需要重复访问常量,您可能希望将值缓存在局部变量中。 此外,更喜欢将公共全局常量存储在自己的对象而不是伴生对象中。
这就是第一篇文章的全部了。 希望这能让您更好地了解 Kotlin 功能的含义。 记住这些,以便在保证代码可读性和性能的前提下,编写更智能的代码。
敬请期待第 2 部分:局部函数,空安全和可变参数。

以上是关于探索 Kotlin 的隐性成本(Part 1)的主要内容,如果未能解决你的问题,请参考以下文章