优化求解基于莱维飞行和随机游动策略改进灰狼算法matlab源码
Posted MatlabQQ1575304183
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了优化求解基于莱维飞行和随机游动策略改进灰狼算法matlab源码相关的知识,希望对你有一定的参考价值。
文章目录
一、理论基础
1、灰狼优化算法
灰狼隶属于群居生活的犬科动物,且处于食物链的顶层。灰狼严格遵守着一个社会支配等级关系。如图:
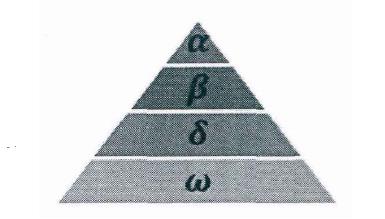
社会等级第一层:狼群中的头狼记为 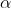 , 狼主要负责对捕食、栖息、作息时间等活动作出决策。由于其它的狼需要服从 狼的命令,所以 狼也被称为支配狼。另外, 狼不一定是狼群中最强的狼,但就管理能力方面来说, 狼一定是最好的。
, 狼主要负责对捕食、栖息、作息时间等活动作出决策。由于其它的狼需要服从 狼的命令,所以 狼也被称为支配狼。另外, 狼不一定是狼群中最强的狼,但就管理能力方面来说, 狼一定是最好的。
社会等级第二层: 狼,它服从于 狼,并协助 狼作出决策。在 狼去世或衰老后, 狼将成为 狼的最候选者。虽然 狼服从 狼,但 狼可支配其它社会层级上的狼。
狼,它服从于 狼,并协助 狼作出决策。在 狼去世或衰老后, 狼将成为 狼的最候选者。虽然 狼服从 狼,但 狼可支配其它社会层级上的狼。
社会等级第三层: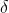 狼,它服从 、 狼,同时支配剩余层级的狼。 狼一般由幼狼、哨兵狼、狩猎狼、老年狼及护理狼组成。
狼,它服从 、 狼,同时支配剩余层级的狼。 狼一般由幼狼、哨兵狼、狩猎狼、老年狼及护理狼组成。
社会等级第四层: 狼,它通常需要服从其它社会层次上的狼。虽然看上去 狼在狼群中的作用不大,但是如果没有 狼的存在,狼群会出现内部问题如自相残杀。
狼,它通常需要服从其它社会层次上的狼。虽然看上去 狼在狼群中的作用不大,但是如果没有 狼的存在,狼群会出现内部问题如自相残杀。
GWO 优化过程包含了灰狼的社会等级分层、跟踪、包围和攻击猎物等步骤,其步骤具体情况如下所示。
1)社会等级分层(Social Hierarchy)当设计 GWO 时,首先需构建灰狼社会等级层次模型。计算种群每个个体的适应度,将狼群中适应度最好的三匹灰狼依次标记为 、 、 ,而剩下的灰狼标记为 。也就是说,灰狼群体中的社会等级从高往低排列依次为; 、 、 及 。GWO 的优化过程主要由每代种群中的最好三个解(即 、 、 )来指导完成。
2)包围猎物( Encircling Prey )灰狼捜索猎物时会逐渐地接近猎物并包围它,该行为的数学模型如下:

式中:t 为当前迭代次数:。表示 hadamard 乘积操作;A 和 C 是协同系数向量;Xp 表示猎物的位置向量; X(t) 表示当前灰狼的位置向量;在整个迭代过程中 a 由2 线性降到 0; r1 和 r2 是 [0,1] 中的随机向量。
3)狩猎( Hunring)
灰狼具有识别潜在猎物(最优解)位置的能力,搜索过程主要靠 、 、 灰狼的指引来完成。但是很多问题的解空间特征是未知的,灰狼是无法确定猎物(最优解)的精确位置。为了模拟灰狼(候选解)的搜索行为,假设 、 、 具有较强识别潜在猎物位置的能力。因此,在每次迭代过程中,保留当前种群中的最好三只灰狼( 、 、 ),然后根据它们的位置信息来更新其它搜索代理(包括 )的位置。该行为的数学模型可表示如下:

式中: 、
、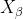 、
、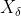 分别表示当前种群中 、 、 的位置向量;X表示灰狼的位置向量;
分别表示当前种群中 、 、 的位置向量;X表示灰狼的位置向量;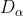 、
、 、
、 分别表示当前候选灰狼与最优三条狼之间的距离;当|A|>1时,灰狼之间尽量分散在各区域并搜寻猎物。当|A|<1时,灰狼将集中捜索某个或某些区域的猎物。
分别表示当前候选灰狼与最优三条狼之间的距离;当|A|>1时,灰狼之间尽量分散在各区域并搜寻猎物。当|A|<1时,灰狼将集中捜索某个或某些区域的猎物。
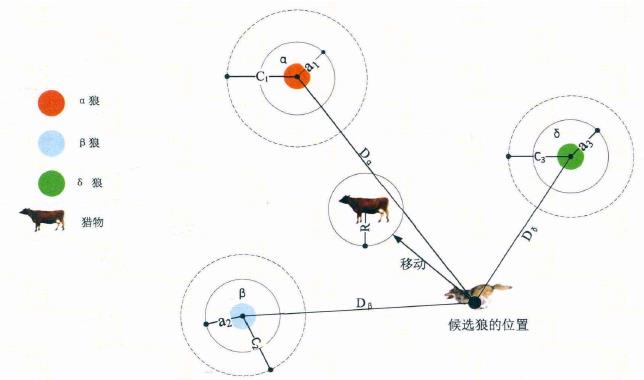
从图中可看出,候选解的位置最终落在被 、 、 定义的随机圆位置内。总的来说, 、 、 需首先预测出猎物(潜 在最优解)的大致位置,然后其它候选狼在当前最优兰只狼的指引下在猎物附近随机地更新它们的位置。
4)攻击猎物(Attacking Prey)构建攻击猎物模型的过程中,根据2)中的公式,a值的减少会引起 A 的值也随之波动。换句话说,A 是一个在区间[-a,a](备注:原作者的第一篇论文里这里是[-2a,2a],后面论文里纠正为[-a,a])上的随机向量,其中a在迭代过程中呈线性下降。当 A 在[-1,1]区间上时,则捜索代理(Search Agent)的下一时刻位置可以在当前灰狼与猎物之间的任何位置上。
5)寻找猎物(Search for Prey)灰狼主要依赖 、 、 的信息来寻找猎物。它们开始分散地去搜索猎物位置信息,然后集中起来攻击猎物。对于分散模型的建立,通过|A|>1使其捜索代理远离猎物,这种搜索方式使 GWO 能进行全局搜索。GWO 算法中的另一个搜索系数是C。从2)中的公式可知,C向量是在区间范围[0,2]上的随机值构成的向量,此系数为猎物提供了随机权重,以便増加(|C|>1)或减少(|C|<1)。这有助于 GWO 在优化过程中展示出随机搜索行为,以避免算法陷入局部最优。值得注意的是,C并不是线性下降的,C在迭代过程中是随机值,该系数有利于算法跳出局部,特别是算法在迭代的后期显得尤为重要。
2、改进灰狼优化算法
为了弥补传统灰狼算法收敛速度慢并且易陷入局部最优的缺陷,本文利用改进衰减因子来平衡灰狼算法的全局搜索能力和局部搜索能力;同时,分别利用莱维飞行策略和随机游动策略来提高算法全局和局部的搜索能力。
(1)分段可调节衰减因子

(2)莱维飞行和随机游动策略
使用莱维飞行策略进行全局探测,使灰狼个体广泛分布于搜索空间中,以提高全局寻优能力;使用随机游动策略,使灰狼在相对集中的区域内寻优,以提高局部寻优的能力。


二、LRGWO算法伪代码

图1 LRGWO算法伪代码
三、仿真实验与分析
为了验证本文算法(LRGWO)的有效性,将LRGWO[1]与标准GWO算法、PSO算法、IGWO[2]算法和CMGWO[3]算法( 修改控制参数C CC策略)进行对比,选取了8个标准测试函数进行仿真实验。表1列出了标准测试函数的相关信息。其中,F1~F5为单峰函数,用于测试算法的局部开发能力;F6~F8为多峰函数,用于测试算法平衡勘探与开发的能力。实验硬件条件为Inter® Core™ i7-7700处理器、8G运行内存,软件环境为Matlab R2018a。
表1 标准测试函数
实验结果如下图所示: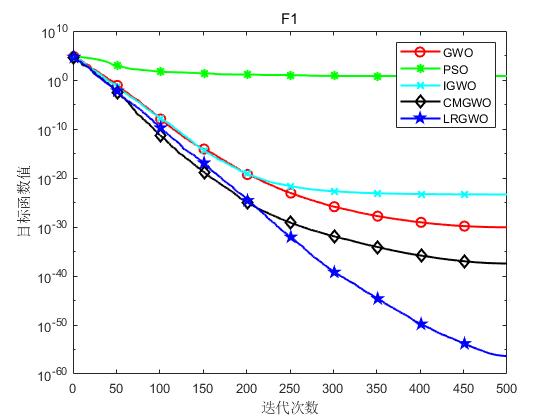
(a)F1
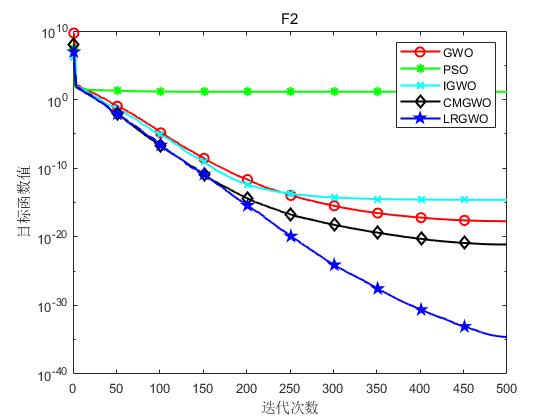
(b)F2
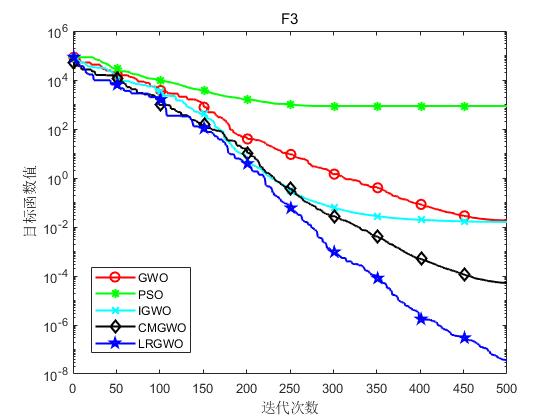
(c)F3
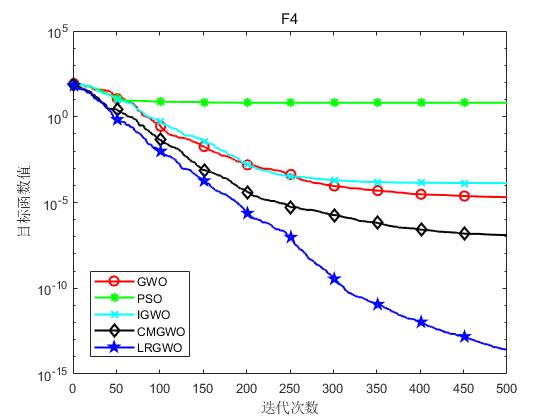
(d)F4
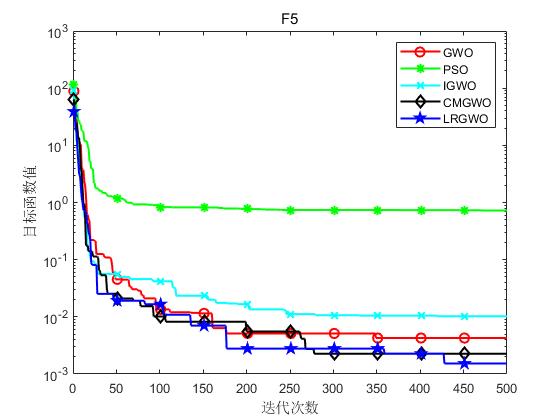
(e)F5
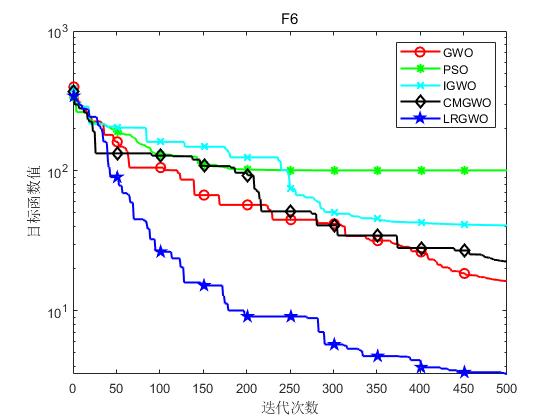
(f)F6
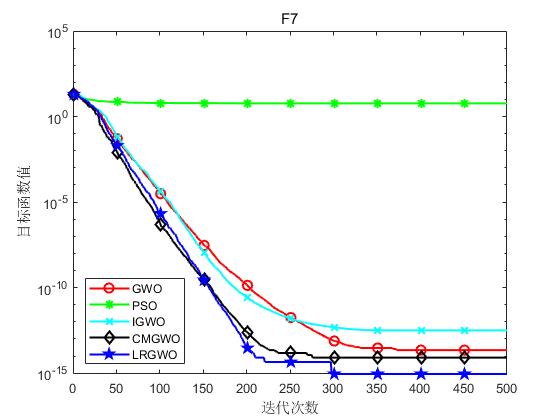
(g)F7
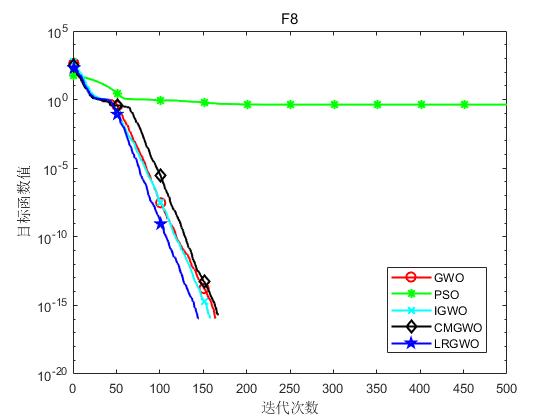
(h)F8
四、参考文献
[1] 李阳,李维刚,赵云涛,刘翱.基于莱维飞行和随机游动策略的灰狼算法[J].计算机科学,2020,47(08):291-296.
[2] 胡小平,曹敬.改进灰狼优化算法在WSN节点部署中的应用[J].传感技术学报,2018,31(05):753-758.
[3] 龙文,伍铁斌,唐明珠,徐明,蔡绍洪.基于透镜成像学习策略的灰狼优化算法[J].自动化学报,2020,46(10):2148-2164.
代码下载或者仿真咨询添加QQ1575304183
以上是关于优化求解基于莱维飞行和随机游动策略改进灰狼算法matlab源码的主要内容,如果未能解决你的问题,请参考以下文章
优化算法莱维飞行和随机游动策略的灰狼算法含Matlab源码 1500期
优化算法莱维飞行和随机游动策略的灰狼算法含Matlab源码 1500期