Java面试 —— Java基础
Posted Johnny*
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了Java面试 —— Java基础相关的知识,希望对你有一定的参考价值。
1、 == 与 equals
在说明上述两个的区别前,需要了解Java中基本数据类型和引用类型是如何存储的。
基本数据类型存放于栈帧中,存放的是变量的值。而引用变量类型在栈中存放的是引用的地址,内容是存放在堆中的。例如,int x = 12,由于x是基本数据类型,栈中存放的是变量的值12,。而String s = new Striing(“zs”)s是通过new运算符生成的,是对象,其栈存放的是"zs"在堆中的内存地址0x11。
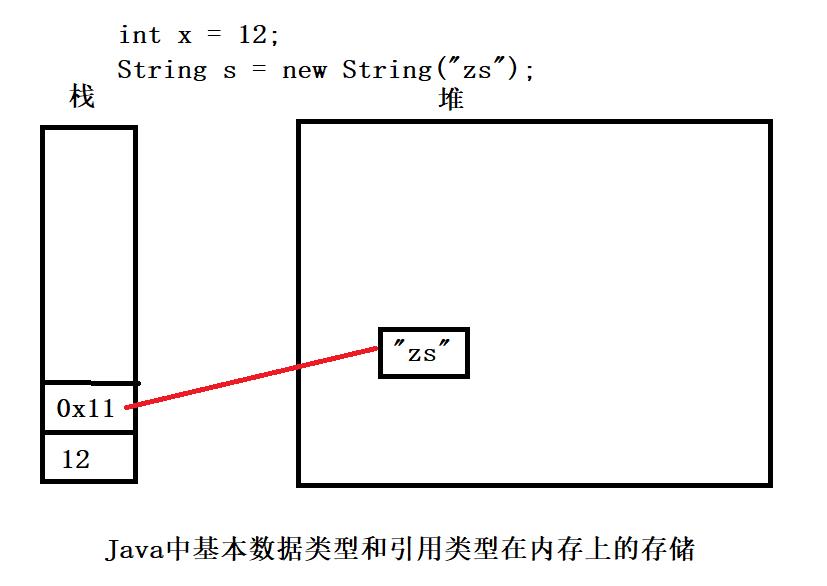
Java中的"=="有两种比较方式。对于基本类型来说,比较的是值,而对于引用类型来说,比较的是内存地址。
equals,默认是Objec的equals方法,该方法比较的是对象在内存中的地址,等价于通过"=="比较两个对象。源码如下:
public boolean equals(Object obj) {
return (this == obj);
}
一般,这并不是我们想要的,通过重写可以实现值比较。String的比较就重写了equals方法
import java.util.Scanner;
class Main{
public static void main(String args[]){
String s1 = new String("zs");
String s2 = new String("zs");
System.out.println(s1 == s2); //false
String s3 = "zs";
String s4 = "zs";
System.out.println(s3 == s4);//true
System.out.println(s3 == s1);//false
String s5 = "zszs";
String s6 = s3+s4;
System.out.println(s5 == s6);//false
final String s7 = "zs";
final String s8 = "zs";
String s9 = s7+s8;
System.out.println(s5 == s9); //true
final String s10 = s3+s4; //final 说明s10只能被赋值一次 但是是通过s3+s4相当于new
System.out.println(s5 == s10);//false
}
}
Java中通过"+"连接两个字符串常量会将其结果也转化为字符串常量。因此s9和s5都指向
final String s10 = s3+s4; final 说明s10只能被赋值一次 但是s10是通过两个字符串变量s3和s4+创建出来的,是一个对象。而 s5是字符串常量池的引用,两者是不同的。
Java传参问题
Java中数组作为参数传递的是引用。
package 第七届;
/**
* @author JohnnyLin
* @version Creation Time:2021年4月14日 下午7:42:01
数组是传值还 是传引用
*/
public class Test {
public static void fun(int []a) {//传递引用
a[0] = 1100;
}
public static void main(String[] args) {
int [] b = {1,2,3,4,5,6,7,8};
fun(b);
System.out.println(b[0]); //1100
}
}
package 第七届;
/**
* @author JohnnyLin
* @version Creation Time:2021年4月14日 下午7:42:01
*/
public class Test {
public static void fun_Basic(int a) {
a = 999;
}
public static void main(String[] args) {
int c = 456;
fun_Basic(c);
System.out.println(c);//456
}
}
从上面例子可以看出。
基本数据类型(int、long、double)作为函数参数传递,是按值传递。
引用类型(类对象、数组)作为函数参数传递,是按引用传递。
 本质上传递的都是值,只不过对于引用变量来说其值为引用地址。
本质上传递的都是值,只不过对于引用变量来说其值为引用地址。
2、ArrayList 和 LinkedList的区别
本质上与数组和双向链表的区别一样。
- 数据结构的实现上: ArrayList 是动态数组的实现。LinkedList是双向链表的数据结构实现。
- 随机访问的效率上:
按索引访问: ArrayList由于是基于数组实现的,地址是连续的。查找可根据索引计算偏移量,所以查找效率较高。
按值访问: 两者皆需遍历查找,效率一样。 - 增加和删除效率上:尾部增加和删除,两者的效率是不相上下的。 若是头部和中间位置的增加和删除,显而易见数组需要移动大量元素,效率比链表低。
- 线程安全: 二者都是不同步的,不保证线程安全。
- 空间占用: LinkedList比ArrayList更占内存。因为其每个节点不但存储数据还存储指向前一个节点和指向后一个节点的两个引用。
3、 ArrayList的扩容机制
ArrayList数组初始化容量为10。当数组容量不够时会进行扩容,扩容过程如下:
1、申请一个新的数组,该数组容量为原来的1.5倍。使用的是位运算
int oldCapacity = elementData.length;
int newCapacity = oldCapacity + (oldCapacity >> 1);
2、 将旧数组的元素赋值到新数组。 Arrays工具类。
elementData = Arrays.copyOf(elementData, newCapacity)
4、 HashSet的存储原理
HashSet的存储主要是保证其元素的唯一性。
HashSet底层是借助HashMap实现存储的的,其值作为HashMap 的key
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashMap保证key的唯一性本身借助了Hash算法。
什么是Hash算法呢?
按照常规操作,当往数组中添加元素,保证唯一性时,是遍历数组中的元素逐个比较。这种方法虽然可行,但是当数据量很大时就显得很低效。为此采取了新的方法也就是hash算法。
采用hash算法,通过计算存储对象的HashCode,然后在与数组长度-1做位运算,得到我们要存储在哪个下标下,如果此时计算的位置下没有元素,就直接存储,不做比较。
但是,随着数组元素的增多,就可能发生"Hash冲突"(“Hash碰撞”),这个时候我们就要用到equals来比较两个对象的内容是否相同。如相同则不插入,否则形成链表存储在该位置。这一点上,jdk1.8做了优化,当元素不断添加,同一位置形成的链表可能会越来越长,因此其优化为红黑树。
5、为什么重写equals要重写HashCode
HashMap是底层实现时数组加链表
A.当put元素时:
1.首先根据put元素的key获取hashcode,然后根据hashcode算出数组的下标位置,如果下标位置没有元素,直接放入元素即可。
2.如果该下标位置有元素(即根据put元素的key算出的hashcode一样即重复了),则需要已有元素和put元素的key对象比较equals方法,如果equals不一样,则说明可以放入进map中。这里由于hashcode一样,所以得出的数组下标位置相同。所以会在该数组位置创建一个链表,后put进入的元素到放链表头,原来的元素向后移动。
B.当get元素时:
根据元素的key获取hashcode,然后根据hashcode获取数组下标位置,如果只有一个元素则直接取出。如果该位置一个链表,则需要调用equals方法遍历链表中的所有元素与当前的元素比较,得到真正想要的对象。
可以看出如果根据hashcdoe算出的数组位置尽量的均匀分布,则可以避免遍历链表的情况,以提高性能。
所以要求重写hashmap时,也要重写equals方法。以保证他们是相同的比较逻辑。
hashmap什么时候需要重写equals和hashcode方法
6、 switch的参数类型
Java中switch语句所支持的参数类型有三类:
-
基本数据类型:byte、short、char、int
-
引用数据类型: Byte、 Short、 Character、Integer(即上述四种类型的包装类)、String、
-
枚举类型
其实switch只支持整型,其他数据类型都是转换成整型后才使用的switch。 -
byte、short、char(ASCII码)自动类型提升为int,而这四种基本类型所对应的封装类,因为自动拆箱机制也可以作为参数。
-
Switch借助hashCode()和equals()实现了对String的支持——先使用hashCode(还是整型类型的)进行初步判断,然后使用equal()进行二次校验。
7、 Integer和int类型的比较
Integer a = 1;
Integer b = 1;
Integer c = 500;
Integer d = 500;
System.out.print(a == b); //true
System.out.print(c == d); //false
System.out.print(a.equals(b)); //true
Integer类型,如果数值是在 -128 到127范围之间是会被缓存的。在这范围内,赋值是直接从缓存中取,不会有新的对象产生。也就是说,a和b实际上是指向同一个对象。Integer a = 1 是自动装箱会调用Integer。valueOf(int)方法. 该方法API解释如下:
public static Integer valueOf(int i)
Returns an Integer instance representing the specified int value. If a new Integer instance is not required, this method should generally be used in preference to the constructor Integer(int), as this method is likely to yield significantly better space and time performance by caching frequently requested values. This method will always cache values in the range -128 to 127, inclusive, and may cache other values outside of this range.
对应方法实现如下:
public static Integer valueOf(int i) {
if (i >= IntegerCache.low && i <= IntegerCache.high)
return IntegerCache.cache[i + (-IntegerCache.low)];
return new Integer(i);
}
而一旦超过这个范围,即使值相同也会创建一个新的对象。所以c和d是指向不同对象。
Integer类型的equals方法是被重写过的。会先比较类型是否相同,如果类型相同才比较值是否相等。如果类型相同且值也相等就返回true。因此a.equals(b)为true。
Integer i = 127; //自动装箱调用Integer.valueOf() 该值在内部类IntegerCache的属性中
Integer j = new Integer(127); //new产生一个对象 该对象的value属性被赋值为127
Integer k = new Integer(127); //new产生一个对象 该对象的value属性被赋值为127
System.out.println(i == j); //false
System.out.println(i.equals(j));//true
System.out.println(j == k); //不同堆对象 false
System.out.println(j.equals(k));//true
Integer的拆装箱问题:
int i=0;
Integer j = new Integer(0);
System.out.println(i==j); //false
System.out.println(j.equals(i)); //true
在jdk1.5之后,提供了拆装箱。
i== j,基本类型与封装类型在进行比较的时候,会自动将基本类型装箱。而Integer j = new Integer(0)产生一个新的对象,在堆中。两者的地址不一样,所以 i == j 的结果 为false。
j.equals(i)结果为true。
除此之外,Character封装类型也提供了缓存机制:
public static Character valueOf(char c) {
if (c <= 127) { // must cache
return CharacterCache.cache[(int)c];
}
return new Character©;
}
字符的值小于127就会被缓存。大于127就会重新构建一个对象
Character a = 'c';
Character b = 'c';
Character c = '等';
Character d = '等';
System.out.println(a==b); // true
System.out.println(c==d); // false
Float同Double , 没有缓存,所以每次就是直接new一个对象
Double a = 1.0;
Double b = 1.0;
Double c = 500.0;
Double d = 500.0;
System.out.println(a==b); // false
System.out.println(c==d); // false
8. ArrayList扩容机制
ArrayList初始容量为10,当超过容量时。会重新申请空间,申请的空间大小为原来的1.5倍。然后将旧数组赋值到新开辟的数组空间上。
9. 类型转换
类型转换包括两种,一种是自动转换,另一种是强制转换。
自动转换
- 范围小的类型可以自动转换为(赋值给)范围大类型。
- 范围小的类型遇到范围大的类型,自动转为范围大的类型。
int a = 1;
double b = a; // 1赋值给范围大的类型(double)
double d = a +3.14; //1遇上范围大的3.14
错误:
int a = 10 +3.14; //范围小的不能自动转为范围大的,需通过强转
各类型的范围大小:
char < int <整数<float<double<字符串
范围最大为字符串。
char c = 'A';
System.out.println(c);//输出 A
System.out.println(c+0); //输出字符A的ASCII码 65
System.out.println(0+c); //输出字符A的ASCII码 65
System.out.println(0+'0'); //输出字符0的ASCII码 48
System.out.println('0'+c); //输出AJ加上'0'的ASCII码值之和
强制转换
范围大的赋值给范围小的,必须强转。
通用写法:
范围小的 = (小类型) 范围大的;
特殊:
不能写成float f = 1.345;
原因是1.345为double类型,不能自动转为范围更大的double类型,但是float比较特殊也可以无需强转,只要在后面加上f标记即可,如下:
float x = 123.45f;
关于字符与整形之间的转换:
int x = 'a'; //小范围赋值给大范围 :自动转换
System.out.println('a');// a
System.out.println(x);//97
// 'a' + 3 -- >小范围'a'遇上大范围3自动变成97
System.out.println('a'+3); //100
System.out.println((char)('a'+3)); //d 范围大的转小的 强制转换
10、抽象类和接口
抽象类是从多个具体类中抽象出来的父类,抽象类就是一个模板,使用abstract关键字修饰。因此抽象类:
- 跟普通类一样,可以有存在成员变量,普通方法,构造方法,静态属性和静态方法。
- 抽象类中可以存在构造方法。因为抽象类中存在抽象方法所以不能被实例化。抽象类的构造器仅仅是提供给子类调用的,不能用于实例化。
- 抽象类可以被继承。继承的子类要么实现所有抽象方法,要么自己也被声明为抽象。
接口
- 在接口中只有方法的声明,没有实现体。
- 在接口中只有常量,任何成员变量的定义在编译时都会默认加上public static final
- 接口中的所有方法,永远都被public 修饰,且默认public abstract类型。
- 接口没有构造方法,也不能实例化接口。
注意:
JDK1.8中对接口进行了增强,接口可以有default、static方法。
public interface Haha {
default void haha() {
System.out.println("接口里也能有普通方法的,我去");
}
}
11、 Object类及其方法
Object类自带的方法
getClass(): 返回对象的运行时类(class<>)
package com.JavaSe.objectDemo;
class Father{}
public class Son extends Father {
public static void main(String[] args) {
Father father = new Son();
System.out.println( father.getClass()); //class com.JavaSe.objectDemo.Son
System.out.println( father.getClass().getName() ); //com.JavaSe.objectDemo.Son
}
}
与getClass()类似的方法还有两个:
一个是Class类中的forName()方法,也是在运行时,根据传入的类名区加载类,然后返回与类关联的Class对象。同时因为是动态加载,在 编译时可以没有这个类,也不会对类名进行校验,所以可能抛出ClassNotFoundException异常。
另一个是类名.class
与上面两种方法不同之处在于,它返回的是编译时类型。也就是在编译时,类 加载器将类加载到JVM中,然后 返回一个初始化的Class对象、
HashSet
Set<Integer> set = new HashSet<>();
System.out.println(set.add(11));
System.out.println(set.add(11));
第一次add时候
HashSet map.put(e, PRESENT)返回null
public boolean add(E e) {
return map.put(e, PRESENT)==null;
}
HashSet的add方法调用putVal(……)
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
第二次add的时候,HashMap的 final V putVal(int hash, K key, V value, boolean onlyIfAbsent,boolean evict) 会将旧值覆盖掉。返回该值。
字符常量和字符串常量的区别
- 形式上: 字符常量由单引号括起来的一个字符。字符串常量由双引号括起来若干个字符,可以为0个。
- 含义上:字符常量相当于一个整型值(ASCCII码)。而字符串常量是引用对象,存储的是引用地址。
- 占用大小上: 字符型常量大小为2个字节。字符串采用一种更灵活的方式进行存储,没有固定大小。取决于编码和字符(比如说是汉子还是 字母)。
既然有了字节流,为什么还要有字符流?
问题本质想问:不管是文件读写还是网络发送接收,信息的最小存储单元都是字节,那为什么 I/O 流操作要分为字节流操作和字符流操作呢?
Java中提供字符流是为了给字符操作提供更方便、更高效的方法。如果知道某个文本文件的编码类型那么可以使用字符流。比如说,全是中文的。那么如果按字节流的话,需要读两个才能成为一个中文字符,有了字符流之后,既保证了读数据的准确性又保证了效率。
本质上来说所有的读写操作都是以字节为单位进行。字符只是根据编码对字节流进行翻译的结果。
字节流用来处理二进制数据,比如图片数据。字符流用于处理字符和字符串
数据库基础
什么是事务?
事务(transaction)是作为一个单元的一组有序的数据库操作。如果组中的所有操作都成功,则认为事务成功。即使一个操作失败,事务也不会成功。如果所有操作成功则事务提交,其修改将作用于其他数据库进程。如果操作失败,则事务将回滚,该事务所有操作的影响都将被取消。
事务的特性:(ACID)
事务具有4个特征。分别是原子性、一致性、隔离性、持久性。简称事务的ACID特性
- 原子性(atomicity): 即不可分割性,事务要么全部执行,要么就全部不被执行。
- 一致性(consistency):事务的执行使得数据库从一种正确状态转换成另一种正确状态。如果数据库系统自运行过程中发生了故障,有些事务尚未完成就被迫中断,这些未完成的事务对数据库所做的修改有一部分已经写入物理数据库,这时数据库就处于一种不正确的状态,也就是不一致状态。
- 隔离性(isolation): 在事务正确提交之前不允许把该事务对数据的任何改变提交给任何其他事务。
- 持久性(durability):事务正确提交后,其结果将永久保存在数据库中,即使在事务提交后有了其他故障,事务的处理结果也会得到保存。
常用SQL 语句
使用mysql root -p 提示权限不够: Access denied for user 'ODBC'@'localhost' (using password: YES)
msyql -u root -p
use goodsadmin; -- 使用数据库
alter table person add column card_id int(12); --增加列card_id
create table IDCard(card_id int(12) primary key, card_code varchar(25)); --创建IDcard 表
alter table 表名 rename to 新表名; -- 修改表名
alter table 表名 character set 字符编码; --修改表格的字符编码
alter table person modify card_id varchar(16); --修改card_id的数据类型
alter table 表名 change 列名 新列名 新数据类型; --- 修改某一列的列名、数据类型
alter table 表名 drop 列名; --删除某一列
show tables; -- 查询当前数据的所有表
desc 表名; --查看表结构
-- 添加外键约束:alter table 从表 add constraint 外键(形如:FK_从表_主表) foreign key (从表外键字段) references 主表(主键字段);
alter table person add constraint fk_person_IDcard_card_id foreign key (card_id) references IDCard(card_id); --不加单引号
-- SELECT <字段名> FROM <表1> INNER JOIN <表2> [ON子句]
select p.* ,c.* from person p inner join idcard c on p.card_id = c.card_id where p.id = 1; --内连接查询
-- select <字段名> FROM<表1> LEFT JOIN <表2> [ON 子句]
-- 左连接 如果数据不存在,左表记录会出现,而右表为null填充
alter table person add column nation_id int(12);
create table nation(nation_id int(12) primary key, nation_name varchar(12));
alter table person add constraint fk_person_nation_nation_id foreign key (nation_id) references nation(nation_id);
---增加某列
ALTER TABLE skill ADD COLUMN createdTime TIMESTAMP not null DEFAULT now();
Truncate
TRUNCATE与DELETE的区别
1、DELETE FROM 表名 # 逐行删除每一条记录、
TRUNCATE [TABLE] 表名 # 先删除表后在重新创建 表(效率高)
2、 TRUNCATE不知道删除了几条数据,官方文档的说明是:通常的结果是“ 0行受到影响 ”,这应该被解释为“ 没有信息。”。 而DELETE知道。
3、 TRUNCATE 重置auto_increment的值,delete不会。
为了实现高性能,TRUNCATE绕过了删除数据的DML方法。因此它不能被回滚,不会导致ON DELETE 触发器触发,并且不能对InnoDB具有父子外键关系的表执行
1、 数据库的三大范式
第一范式: 属性不可分。关系中每一个数据不可再分(不能以集合/序列等作为属性),也就是关系中没有重复的列(比如电话号码这个属性既存在一个手机号又存在一个家庭号码,这种情况就不属于第一范式,除非把手机号作为一个列,家庭号码也作为单独一列。);
第二范式: 消除部分依赖。在1NF基础之上,消除非主属性对键的部分依赖,则称它为符合2NF;(把学生编号,课程标号,成绩单独拿出来作为一个表)。属性完全依赖于主键。
第三范式: 在2NF基础之上,消除非主属性对键的传递依赖,称为符合3NF;(要确定这个学生的院系,首先要经过学号来确定班级,通过班级来确定院系,所以院系对学号存在传递依赖;把院系拿出来单独作为一个表就可以了)。
使属性不依赖于其它非主属性。 也就是说, 如果存在非主属性对于码的传递函数依赖
线程
创建线程的方式的四种方式
- 继承Thread 类创建线程
- 实现Runable接口创建线程
- 通过Callable 和FutureTask创建线程
- 通过线程池创建线程
继承Thread类
这种方式是通过继承Thread类并重写run()方法,然后创建该类实例,调研该实例的start()方法。
package com.thread.createThread;
public class MyThread extends Thread {
@Override
public void run() {
System.out.println("继承Thread的线程创建");
}
public static void main(String[] args) {
MyThread thread = new MyThread();
thread.start();
System.out.println("执行main方法");
}
}
输出结果
执行main方法
继承Thread的线程创建
Thread类的start()方法
public synchronized void start() {
/**
以上是关于Java面试 —— Java基础的主要内容,如果未能解决你的问题,请参考以下文章