golang源码之slice
Posted better_hui
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了golang源码之slice相关的知识,希望对你有一定的参考价值。
目录
一、数据结构
二、初始化 makeslice
golang中有很多初始化slice的方式,我们以make方式,来看一下slice在底层是如何初始化的。
func main(){
c := make([]int ,1)
c = append(c ,1)
fmt.Println(c)
}
转变一下汇编代码 , 命令如下:
go tool compile -S main.go
0x0042 00066 (main.go:9) CALL runtime.makeslice(SB)//初始化slice 0x006d 00109 (main.go:10) CALL runtime.growslice(SB)//append操作
我截取了部分核心代码,可以看到slice初始化的命令是调用了 runtime.makeslice方法,下面我们研究一下这个方法:
func makeslice(et *_type, len, cap int) unsafe.Pointer {
//根据类型的大小 和 容量大小 计算切片的所需的内存大小 并mallocgc内存分配
mem, overflow := math.MulUintptr(et.size, uintptr(cap))
//内存溢出 || 所需内存大于最大可申请内存 || len < 0 | len > cap
if overflow || mem > maxAlloc || len < 0 || len > cap {
// NOTE: Produce a 'len out of range' error instead of a
// 'cap out of range' error when someone does make([]T, bignumber).
// 'cap out of range' is true too, but since the cap is only being
// supplied implicitly, saying len is clearer.
// See golang.org/issue/4085.
// 计算一下实际长度的所需内存 根据实际情况抛出指定异常
mem, overflow := math.MulUintptr(et.size, uintptr(len))
if overflow || mem > maxAlloc || len < 0 {
panicmakeslicelen()
}
panicmakeslicecap()
}
// 申请内存
return mallocgc(mem, et, true)
}
MulUintptr函数源码:
func MulUintptr(a, b uintptr) (uintptr, bool) {
if a|b < 1<<(4*sys.PtrSize) || a == 0 {
return a * b, false
}
overflow := b > MaxUintptr/a
return a * b, overflow
}
简单来说,makeslice函数的工作主要就是计算slice所需内存大小,然后调用mallocgc进行内存的分配。计算slice所需内存又是通过MulUintptr来实现的,MulUintptr的源码我们也已经贴出,主要就是用切片中元素大小和切片的容量相乘计算出所需占用的内存空间,如果内存溢出,或者计算出的内存大小大于最大可分配内存,MulUintptr的overflow会返回true,makeslice就会报错。另外如果传入长度小于0或者长度小于容量,makeslice也会报错
三、添加 append
slice添加调用的growslice方法,我们直接上代码
func growslice(et *_type, old slice, cap int) slice {
if raceenabled {
callerpc := getcallerpc()
racereadrangepc(old.array, uintptr(old.len*int(et.size)), callerpc, funcPC(growslice))
}
if msanenabled {
msanread(old.array, uintptr(old.len*int(et.size)))
}
// 不允许缩容 会抛异常
if cap < old.cap {
panic(errorString("growslice: cap out of range"))
}
// 不能添加 nil值
if et.size == 0 {
// append should not create a slice with nil pointer but non-zero len.
// We assume that append doesn't need to preserve old.array in this case.
return slice{unsafe.Pointer(&zerobase), old.len, cap}
}
//计算扩容后的容量大小
newcap := old.cap
doublecap := newcap + newcap
// 如果传入的容量大于现在容量的2倍 , 以传入的cap为准
if cap > doublecap {
newcap = cap
} else {
// cap < 1024时 每次扩容为原来的2倍
if old.cap < 1024 {
newcap = doublecap
} else {
// Check 0 < newcap to detect overflow
// and prevent an infinite loop.
// 超过1024 每次 1.25倍扩容
for 0 < newcap && newcap < cap {
newcap += newcap / 4
}
// Set newcap to the requested cap when
// the newcap calculation overflowed.
if newcap <= 0 {
newcap = cap
}
}
}
/***********************************
上面是计算容量
下面择时添加了
************************************/
var overflow bool
var lenmem, newlenmem, capmem uintptr
// Specialize for common values of et.size.
// For 1 we don't need any division/multiplication.
// For sys.PtrSize, compiler will optimize division/multiplication into a shift by a constant.
// For powers of 2, use a variable shift.
switch {
case et.size == 1:
lenmem = uintptr(old.len)
newlenmem = uintptr(cap)
//内存对齐的方法 避免产生内存碎片
capmem = roundupsize(uintptr(newcap))
// 计算新容量是否会溢出 超过最大的可申请内存
overflow = uintptr(newcap) > maxAlloc
newcap = int(capmem)
case et.size == sys.PtrSize:
lenmem = uintptr(old.len) * sys.PtrSize
newlenmem = uintptr(cap) * sys.PtrSize
capmem = roundupsize(uintptr(newcap) * sys.PtrSize)
overflow = uintptr(newcap) > maxAlloc/sys.PtrSize
newcap = int(capmem / sys.PtrSize)
case isPowerOfTwo(et.size):
var shift uintptr
if sys.PtrSize == 8 {
// Mask shift for better code generation.
shift = uintptr(sys.Ctz64(uint64(et.size))) & 63
} else {
shift = uintptr(sys.Ctz32(uint32(et.size))) & 31
}
lenmem = uintptr(old.len) << shift
newlenmem = uintptr(cap) << shift
capmem = roundupsize(uintptr(newcap) << shift)
overflow = uintptr(newcap) > (maxAlloc >> shift)
newcap = int(capmem >> shift)
default:
lenmem = uintptr(old.len) * et.size
newlenmem = uintptr(cap) * et.size
capmem, overflow = math.MulUintptr(et.size, uintptr(newcap))
capmem = roundupsize(capmem)
newcap = int(capmem / et.size)
}
// The check of overflow in addition to capmem > maxAlloc is needed
// to prevent an overflow which can be used to trigger a segfault
// on 32bit architectures with this example program:
//
// type T [1<<27 + 1]int64
//
// var d T
// var s []T
//
// func main() {
// s = append(s, d, d, d, d)
// print(len(s), "\\n")
// }
// 内存溢出 或者内存容量超过了最大申请容量 则抛出异常
if overflow || capmem > maxAlloc {
panic(errorString("growslice: cap out of range"))
}
var p unsafe.Pointer
if et.ptrdata == 0 {
p = mallocgc(capmem, nil, false)
// The append() that calls growslice is going to overwrite from old.len to cap (which will be the new length).
// Only clear the part that will not be overwritten.
memclrNoHeapPointers(add(p, newlenmem), capmem-newlenmem)
} else {
// Note: can't use rawmem (which avoids zeroing of memory), because then GC can scan uninitialized memory.
p = mallocgc(capmem, et, true)
if lenmem > 0 && writeBarrier.enabled {
// Only shade the pointers in old.array since we know the destination slice p
// only contains nil pointers because it has been cleared during alloc.
bulkBarrierPreWriteSrcOnly(uintptr(p), uintptr(old.array), lenmem-et.size+et.ptrdata)
}
}
memmove(p, old.array, lenmem)
return slice{p, old.len, newcap}
}
内存对齐
_MaxSmallSize = 32768
smallSizeDiv = 8
smallSizeMax = 1024
largeSizeDiv = 128
_NumSizeClasses = 68
_PageShift = 13
func roundupsize(size uintptr) uintptr {
if size < _MaxSmallSize {
if size <= smallSizeMax-8 {
return uintptr(class_to_size[size_to_class8[divRoundUp(size, smallSizeDiv)]])
} else {
return uintptr(class_to_size[size_to_class128[divRoundUp(size-smallSizeMax, largeSizeDiv)]])
}
}
if size+_PageSize < size {
return size
}
return alignUp(size, _PageSize)
}
func divRoundUp(n, a uintptr) uintptr {
// a is generally a power of two. This will get inlined and
// the compiler will optimize the division.
return (n + a - 1) / a
}
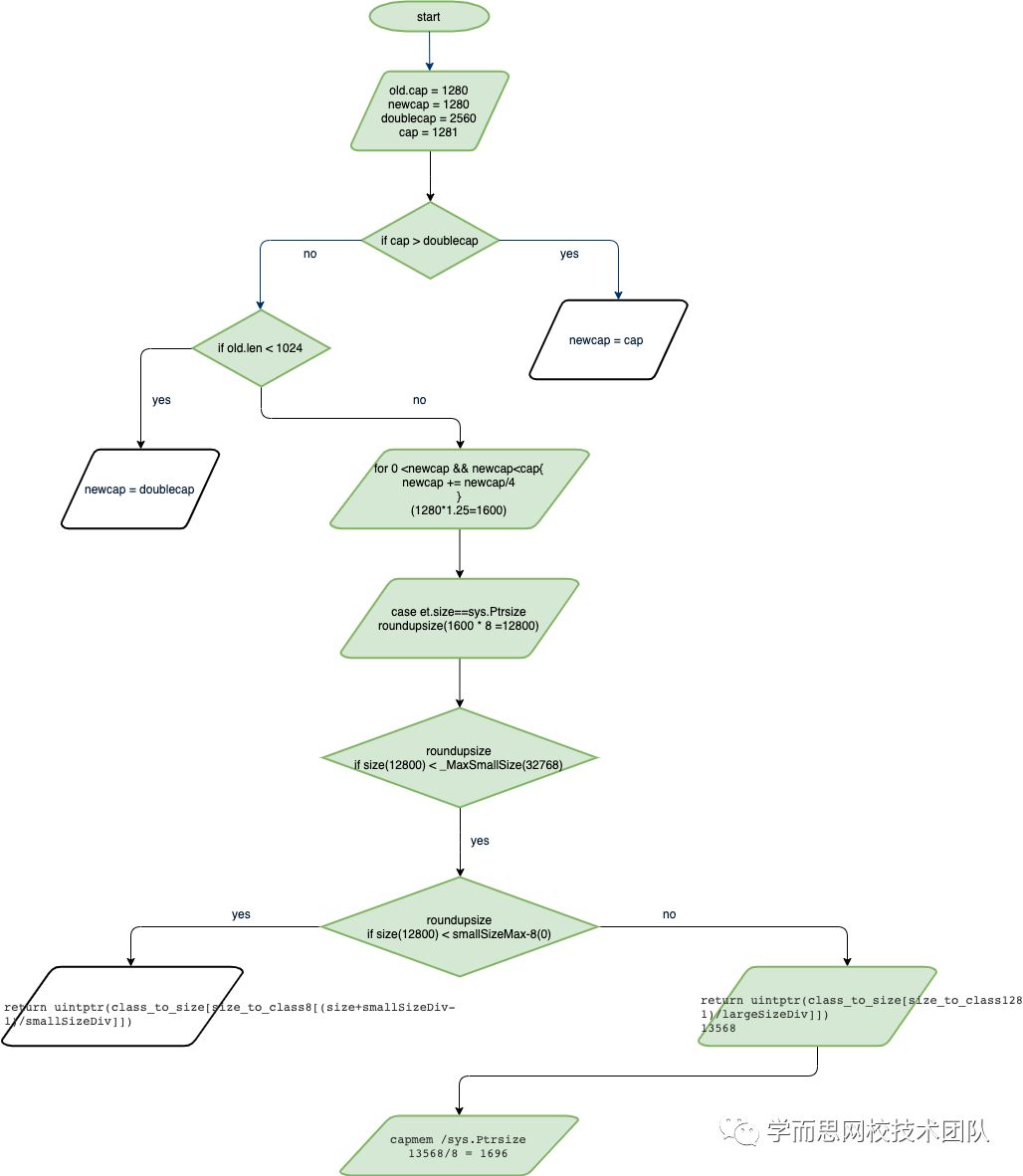
其实roundupsize是内存对齐的过程,我们知道golang中内存分配是根据对象大小来配不同的mspan,为了避免造成过多的内存碎片,slice在扩容中需要对扩容后的cap容量进行内存对齐的操作,接下来我们对照源码来实际计算下cap容量是否由1280变成了1696。
四、截取(浅拷贝)
slice的截取,底层仍然有可能共用原有的数据,但是也有可能不共用。
共用的情况
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:7]
fmt.Println("------------------------追加前的--------------------------")
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \\n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \\n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \\n", len(s2), cap(s2), s2)
s1 = append(s1 , 101)
fmt.Println("-------------------------追加后的-------------------------")
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \\n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \\n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \\n", len(s2), cap(s2), s2)
看下输出结果,更改了s1的数据 , 但是影响到了slice 和 s2 ,三个切片都出现了101
------------------------追加前的--------------------------
len=10 cap=10 slice=[0 1 2 3 4 5 6 7 8 9]
len=3 cap=8 s1=[2 3 4]
len=5 cap=6 s2=[4 5 6 7 8]
-------------------------追加后的-------------------------
len=10 cap=10 slice=[0 1 2 3 4 101 6 7 8 9]
len=4 cap=8 s1=[2 3 4 101]
len=5 cap=6 s2=[4 101 6 7 8]
再看下不共用的情况
slice := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
s1 := slice[2:5]
s2 := s1[2:7]
fmt.Println("------------------------追加前的--------------------------")
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \\n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \\n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \\n", len(s2), cap(s2), s2)
s1 = append(s1 , 101,102,103,104,105,106)
fmt.Println("-------------------------追加后的-------------------------")
fmt.Printf("len=%-4d cap=%-4d slice=%-1v \\n", len(slice), cap(slice), slice)
fmt.Printf("len=%-4d cap=%-4d s1=%-1v \\n", len(s1), cap(s1), s1)
fmt.Printf("len=%-4d cap=%-4d s2=%-1v \\n", len(s2), cap(s2), s2)
输出的结果:只有s1新增了我要追加的数据,why?s1新增的数据达到了阈值 ,触发了切片的扩容,重新分配了数组地址,所以这时 slice 和 s2 还是共用原来的数组 , 但是s1 底层指向了新的数组
------------------------追加前的--------------------------
len=10 cap=10 slice=[0 1 2 3 4 5 6 7 8 9]
len=3 cap=8 s1=[2 3 4]
len=5 cap=6 s2=[4 5 6 7 8]
-------------------------追加后的-------------------------
len=10 cap=10 slice=[0 1 2 3 4 5 6 7 8 9]
len=9 cap=16 s1=[2 3 4 101 102 103 104 105 106]
len=5 cap=6 s2=[4 5 6 7 8]
五、深拷贝
无所谓深拷贝或者浅拷贝 , 深拷贝实际上就是make 一个新的切片 , 然后将数据复制过去
slice1 := []int{0, 1, 2, 3, 4, 5, 6, 7, 8, 9}
slice3 := make([]int, 5)
copy_3 := copy(slice3, slice1)
0x009d 00157 (slice.go:11) MOVQ CX, 8(SP)
0x00a2 00162 (slice.go:11) MOVQ $40, 16(SP)
0x00ab 00171 (slice.go:11) CALL runtime.memmove(SB)
我们发现copy函数其实是调用runtime.memmove,其实我们在研究runtime/slice.go文件中的源码的时候,会发现有一个slicecopy函数,这个函数最终就是调用runtime.memmove来实现slice的copy的,我们看下源码:
func slicecopy(
toPtr unsafe.Pointer, //目标的切片地址
toLen int, //目标的长度
fromPtr unsafe.Pointer, //源切片地址
fromLen int, //源切片长度
width uintptr ) int {//切片元素大小
//如果目标切片或者源切片长度 = 0 ,不做拷贝 , 这也是为什么目标切片不初始化 , 是无法copy的
if fromLen == 0 || toLen == 0 {
return 0
}
//取两个切片 长度短的那个 , 作为copy的数据长度
n := fromLen
if toLen < n {
n = toLen
}
//如果切片内数据对象的长度 == 0 , 直接返回 , 因为无法计算指针偏移
if width == 0 {
return n
}
//计算目标切片需要的内存大小
size := uintptr(n) * width
if raceenabled {
callerpc := getcallerpc()
pc := funcPC(slicecopy)
racereadrangepc(fromPtr, size, callerpc, pc)
racewriterangepc(toPtr, size, callerpc, pc)
}
if msanenabled {
msanread(fromPtr, size)
msanwrite(toPtr, size)
}
if size == 1 { // common case worth about 2x to do here
// TODO: is this still worth it with new memmove impl?
// & 取地址 * 从地址里取值
// 如果只有一个元素 ,(*byte)(fromPtr) 类型强转 *(*byte)(fromPtr) 取数组地址的值 也就是第一个元素的值 , 然后赋值给 *(*byte)(toPtr)
*(*byte)(toPtr) = *(*byte)(fromPtr) // known to be a byte pointer
} else {
// 内存移动
memmove(toPtr, fromPtr, size)
}
return n
}
以上是关于golang源码之slice的主要内容,如果未能解决你的问题,请参考以下文章