动态调度的“诅咒”| 原有深度学习框架的缺陷③
Posted OneFlow深度学习框架
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了动态调度的“诅咒”| 原有深度学习框架的缺陷③相关的知识,希望对你有一定的参考价值。

为什么要重新设计一个像OneFlow这样的分布式深度学习框架?
一个显而易见的出发点是,我们看到了原有的主流深度学习框架的本质不足。尤其在抽象层面和API层面,它们的设计有种种不足,导致开发者在使用时造成极大不便,尽管他们正在试图解决一些缺陷,但有些重要问题依然被忽视了。
为此,我们将推出数篇系列文章,详细论述原有主流深度学习框架的运行时系统的“诅咒”,此为第3篇内容(点击查看第1、2篇)。本文从分配线程池这一关键问题出发,介绍了计算图调度机制,重点探讨原有框架使用动态调度的缺陷以及设置最优线程数的烦恼,并阐述了OneFlow实现的更优雅的方案。
撰文 | 袁进辉
1
分配线程池的问题
在上一篇《资源依赖的“诅咒》中,我们曾讨论过这样一个例子:一个算子因为申请不到足够的显存资源而阻塞了所在的线程,导致这个线程不能去调度和执行另外一个原本满足执行条件的算子。
为克服这一不足,一种解决办法是视需求去创建另外的线程来调度和执行那个原本可执行的算子。可是调度计算图或执行算子还可能因为其它原因阻塞所在的线程。若令线程数大于等于任务的并行度,可以避免上述稳定性的风险。不过,线程作为一种系统资源,创建和管理都有不可忽略的代价,总是按照最大的需求去创建线程肯定存在浪费。
这引出一个新问题,到底该设置多少个线程才合适?
虽然这个问题看上去很简单,但原有框架的实现策略并不好:要么是实现一个固定大小的线程池,要么是一个可以动态变化大小的线程池。由此可能导致不稳定漏洞的出现,或是损害运行效率。
在这篇文章中,让我们深挖一下这个问题的本质,并讨论如何优雅地去解决。
2
计算图的调度机制
与主流的大数据处理系统一样,基于静态图的深度学习框架都使用数据流(dataflow)模型来描述任务和调度算子。
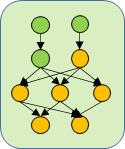
图1:数据流和有向无环图
如上面的有向无环图(DAG)所示,每个节点表示一个算子(可以是计算也可以是数据搬运操作),节点之间的边由生产者指向消费者,代表了数据的流动方向。调度器依照DAG的拓扑顺序把算子发射到合适的硬件资源上去执行。
以上图为例,绿色的节点表示已经执行完成,而黄色节点表示还没有执行,显然,下一时刻,只有第2行的黄色节点满足执行条件,当该节点执行完成之后,第3行的3个黄色节点就满足执行条件了。
使用数据流模型描述分布式并发任务的好处是,DAG图完全显式地展示了程序的并行可能性。同样以上图为例,如果底层硬件资源允许,第1行的两个节点是可以同时执行的;当第2行的两个节点都执行完成之后,第3行的3个节点也是可能并行执行的。正是这一优点,使得数据流模型被广泛应用于分布式大数据处理、函数式模型、编译器并行分析、CPU乱序执行等场景。
我们定义一个计算任务的最大并行度(maximum degree of parallelism)为理论上最大可并行执行的算子数量。例如,图1的最大并行度是3。
计算图的并行度只代表理论上最好的并行可能性,实际并行度取决于每个时刻系统可用的硬件资源的数量以及调度器的实现机制。
给定一个计算图可用的硬件资源,调度器需要不断地做决策:下一步启动哪个算子,以及把这个算子安排(映射)到哪个硬件资源上去。按“最优”的方式搞定从算子到硬件资源的映射,这就是调度器和执行引擎的看家本领了。
3
动态调度和静态调度的谱系
把算子映射到特定硬件的特定时间槽上,有两种实现理念,一种是所谓的静态调度,一种是所谓的动态调度。
所谓静态调度,是指在运行之前的编译期就把这个映射关系分析出来,在运行时按照这个规则执行即可;所谓动态调度,是指在运行之前不做“预案”,完全靠运行时在线的状态“随机应变”,在可接受的时间内找到可行的映射方案并落实,“走一步看一步”。
从完全的动态调度到完全的静态调度形成一个谱系,现实的系统通常介于中间状态,可能同时存在编译期完成的一部分映射,也存在运行期完成的一部分映射。
专用AI芯片可以理解成一种完全静态的映射,譬如,卷积算子和激活层都有专门的部件去完成,算子和硬件的对应关系可能是完全固化的。显然,完全静态调度可能降低灵活性。
传统的大数据系统(譬如Hadoop)通常是完全动态调度的,调度器实时跟踪计算图的进度以及集群内所有硬件资源的使用状态(CPU,memory等),在线决定把算子或任务分发到哪个节点以及该节点的哪个CPU core上去。动态调度的灵活性是最高的。
深度学习框架的实践表明,完全动态调度不可行。深度学习算子的执行时间太短,通常是数十毫秒,瞬息万变,而调度器求解最优的映射方案也要花时间,可能来不及在线动态求解。而且,求解较优的策略需要很多上下文信息,更青睐中心化的调度器,把所有的压力都施加到中心调度器也不现实。
应该说,原有的框架处于动态和静态中间的位置,既有一些是静态预置好的,也有一些是动态决定的。
不过,静态调度具有更多优势:简洁的运行时系统实现(当然,复杂度转移至编译期),高效率和高稳定性。静态调度并不至于损害灵活性,因为软件框架可以为每一个不同的计算任务都在编译期生成不同的映射策略,只不过在运行期同一个任务使用静态的映射策略。
我们将会看到,如何为线程池设置最优线程数量的烦恼是动态调度特有的。
4
硬件资源的抽象
深度学习框架执行引擎涉及几个和硬件资源有关的概念。算子(operator) 用来做功能描述,而在特定硬件上的具体实现称为核函数(kernel),算子的状态被操作系统的内核级线程(OS thread)管理。每种硬件资源被抽象成一种任务队列,在运行期,kernel(即算子的实现)被派发到任务队列里,硬件的调度器按先入先出(FIFO)的规则从队列中取出kernel并在硬件资源上执行。
以Nvidia GPGPU为例,CUDA stream就是一种任务队列。其它硬件资源,包括CPU和网络也可以被抽象成任务队列,我们统一把这样的队列称为stream。
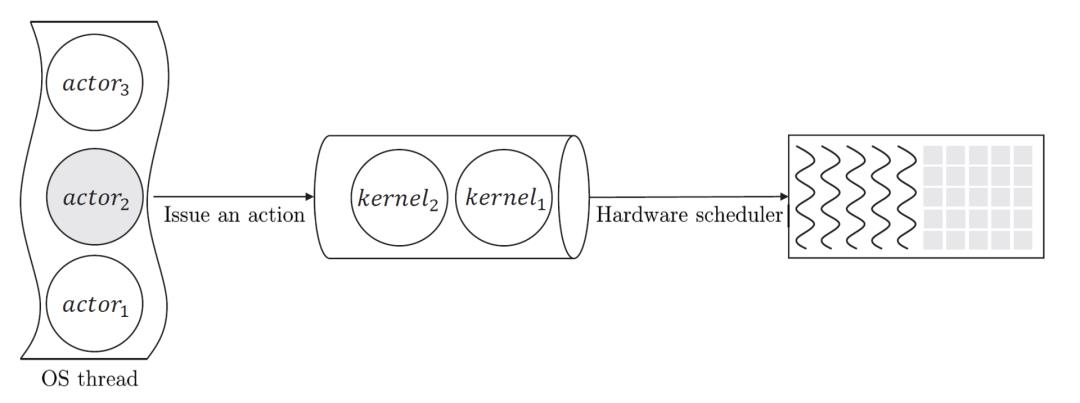
图3:算子、任务队列和硬件资源之间的关系
如图3所示,在OneFlow里,每个actor管理一个算子(Op),一个内核级线程可能负责调度和执行多个算子,调度器通过把满足执行条件的算子所对应的kernel 放到队列(CUDA stream)中去,硬件调度器以FIFO的规则来执行队列里的kernel。
调度器所要解决的从算子到硬件资源的映射问题,可以分解成算子与线程的映射、线程和stream的映射、stream和硬件资源的映射这三个子问题。下面,我们沿着硬件资源、stream、线程、算子这样的顺序来逐一解决。
5
一个GPU该创建多少个stream?
stream是一个异步的任务队列,队列里的任务按先进先出(FIFO) 的顺序执行。基于这个事实,可以得到一些推论:
对两个原本可独立运行的硬件资源,如果共享一个stream,那么这两个硬件资源只能串行执行,而不能并行执行。譬如Nvidia GPGPU的DMA引擎(copy host to device, copy device to host, etc)和计算核心是两种不同的硬件资源,如果让传输和计算共享一个stream,那么这个GPU上的数据拷贝和计算就不可能重叠执行,所以不同的底层硬件资源应该用不同的stream。
对两个原本没有依赖关系且可以并行执行的算子,如果被派发到同一个stream,那么这两个原本可能并行执行的算子会因为共享一个stream而只能先后顺序执行。譬如GPU上有1024个core,如果每个算子只需要使用不到一半的core,且这两个算子被调度到不同的两个stream,那么这两个算子有可能基于不同的core并行执行,所以看上去stream 不能太少;但是如果每个算子在执行时都可以把1024个core用满,那么即使被发射到不同的两个stream上去,这两个算子本质上也只能串行执行。
两个原本有依赖关系的算子,如果被发射到两个不同的stream上去,那么,必须等一个stream里的生产者算子执行完毕,才可以向第二个stream发射消费者算子,也就是不同的stream之间需要同步(或等待),协调多个stream通常是比较复杂的。如果这两个算子被发射到同一个stream,那么消费者算子不需要等待生产者算子执行完毕,就可以被发射到stream里去,这是因为stream的FIFO特性会确保第一个算子执行完毕后,第二个算子才会开始执行,使用一个stream具有简化stream管理复杂性的好处。
总结一下就是:
不同的硬件资源应该使用不同的stream;
有依赖关系的算子最好发射到同一个stream,无依赖关系的算子最好使用不同的stream;
同一个硬件资源创建多个stream利弊各半,同一个硬件资源只创建一个stream利弊各半,那怎么办呢?
一种激进的策略是,根据该设备上计算图的最大并行度来设置compute stream数量;一种保守的策略是,每个设备只创建一个compute stream,这个设备上的所有算子都在stream里排队顺序发生。
对于常见的训练任务来说,算子的粒度通常比较大,通常每个GPU一个compute stream就够了。对于推理来说,batch size比较小,在高端显卡上,只创建一个stream,一个算子是没有办法把显卡用满的,创建多个stream,让多个算子同时执行可能更优。还有一种是通过编译器来解决的办法,MSRA在OSDI 2020上发表的Rammer (nnfusion at GitHub)提出了一种巧妙的解决办法,可以将推理中的细粒度算子融合成大的算子来把GPU资源用满。
6
线程模型:一个stream需要多少个线程?
接下来让我们来研究一下内核线程(如无特别注明,以下简称“线程”)的角色分工。一个线程可能需要执行两种角色,计算图的调度和算子的执行。
所谓调度功能就是线程管理(更新和检查)计算图中每个算子的依赖条件,如果发现有的算子的全部先决条件都已得到满足,就把该算子放到一个就绪队列(ready set)里。
所谓执行功能,就是执行计算图中的算子,可以是计算或数据搬运操作,执行一个算子可能需要一段时间,也可能把算子异步地卸载(offload)到如GPGPU一样的加速器或其他工作者线程上去。
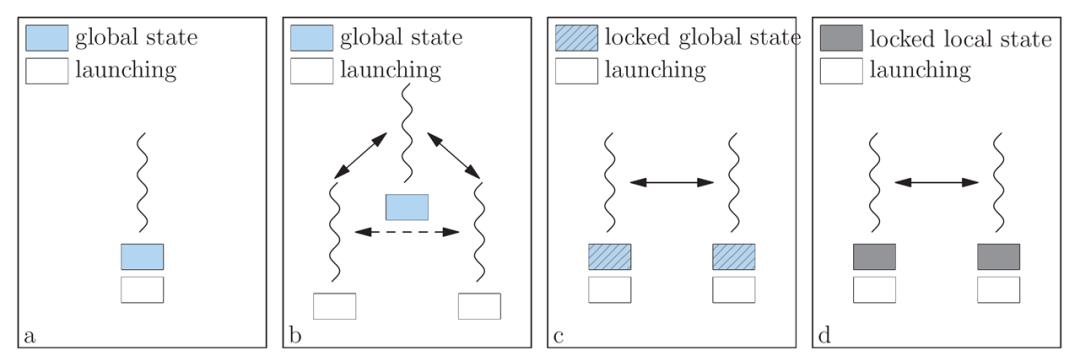
图4:四种线程模型
图4 展示了四种用于调度和算子执行的线程模型。
使用单个线程同时来做计算图调度和算子执行,这个线程访问和修改计算图的状态,但算子可能被派发到多个不同的设备上去。需要注意的是,每次向一个设备派发任务时,需要提前为这个设备初始化设备上下文,当向另一个设备派发任务时,就需要相应的切换设备上下文,切换设备环境会带来一定的开销。
把计算图调度和算子执行的角色分开,有一个线程专门用来管理计算图,但该线程不允许执行算子,也就是并不直接启动CUDA核函数。相反地,算子的启动和执行被派发到不同的工作者线程(worker thread)上去,而且每个工作者线程都只为一个特定的设备服务。
在这种情况下,每个工作者线程只为一个设备服务,不需要切换设备上下文。同时,计算图只被调度线程访问,不需要考虑多线程并发读写的问题。
但是,算子之间的状态更新必须以调度线程为中介才能完成,譬如情况b所示,生产者算子和消费者算子在不同的工作者线程上,生产者算子执行完成后,会通知调度线程更新计算图,调度者线程更新完计算图之后才会影响消费者算子所在的工作者线程。如果生产者算子和消费者算子可以直接对话,就不需要额外地引入和中介角色的调度线程来回交互的开销。
为了消除情况b引入的代理开销,可以允许同一个线程既做计算图的调度也做算子执行,每个线程仅调度和执行某一个特定设备上的算子(从而避免设备上下文的切换),每个线程都可以访问和修改计算图的状态,处于不同线程上的、具有上下游生产消费关系的算子之间可直接对话。
这种方法可消除生产者、消费者之间的调度线程作为中介引入的额外开销,但是,因为多个线程并发访问计算图的状态,这个全局状态必须使用锁来保护,需要尽可能减小并发访问引起的竞争开销。如果锁的临界区界定的范围过大(譬如整个计算图被一个粗粒度锁保护),可能会严重损害系统的性能。
为了尽量减少c情况中的竞争开销,观察到计算图的算子状态是局部的,可以通过算子对计算图的状态解耦,从而可以使用细粒度的锁(例如,每个算子的状态有一个专门的锁来保护)降低竞态条件引入的开销。但在一般的并发系统里,通过缩小锁的粒度(临界区的范围)来优化程序性能是很复杂的问题。
总之,线程模型的选择需要考虑到设备上下文切换的开销,生产者算子和消费者算子之间状态交互的开销,以及多线程竞争访问共享状态引入的开销等因素。一个较好的实践是:每个线程只服务于一个固定的设备或stream,把算子执行内联(inline)到调度计算图的线程上,并尽可能缩小锁的临界区范围。
至此,我们知道一个线程最好只服务于一个stream,并且尽可能不引入中介或代理角色的线程。不过,这依然没有回答一个stream应该创建多少个线程的问题。
7
最优线程数:一个线程服务于多少个算子?
让我们回到最开头讨论的“该设置多少个线程”的问题, 这个问题等价于“一个线程服务于多少个算子”,也就是算子和线程之间的映射关系的问题,这个映射关系可以是静态规划好的,也可以是运行时动态决定的。
显然,让线程数大于等于计算图的并行度,而且以round-robin的方式来把算子分配给这些线程,即使一个算子阻塞了一个线程也不会影响另一个算子的执行。
这相当于一种“饱和式救援”:任一时间段,每个线程只服务于一个算子,只有服务完一个算子才可以服务另一个算子。不过,通常深度学习训练中的算子数量是非常大的,可能需要创建很多的线程才行。
如果线程数小于计算图并行度,而又无法保证算子不阻塞,就不可能避免死锁的风险。
但是,按最大需求设置线程数可能是一种浪费。假如就一个stream,实际上无论计算图有多少并行度,最终都是要顺序执行的。设置多个线程,仅仅是出于稳定性的考虑,并不会提高效率,因为算子最终还是在stream里排队顺序执行。换句话说,很多线程是多余的(内核线程的创建和管理开销都是不可忽略的,占用系统资源、内核上下文切换开销以及并发访问的竞争开销等)。
如果不需要考虑稳定性问题,让线程数等于stream数就是最优选择。有没有让线程数等于stream数,又不影响稳定性的办法呢?
问题的关键是:是否允许计算图的调度或算子的执行阻塞所在的线程。如果确保计算图的调度和算子执行一定不阻塞所在线程,那么让一个线程服务于多个算子也是安全的。
8
异步执行、状态保存和恢复
在原有的深度学习框架中,很多算子都是卸载(offload)到加速器上异步执行,即使是在CPU上执行的算子,也可以被委托到另外的工作者线程上进行模拟异步执行,这比较容易实现。
计算图的每个算子可能有多个依赖条件,每个事件可能只影响到一个依赖条件,其余依赖条件还没有得到解决,这个算子还不能开始执行,如果调度器让这个算子“傻傻地”等待其它依赖条件并阻塞当前线程,不能解决多个算子共享一个线程的安全问题。
因此,必须实现一种完全异步的计算图调度机制:每当一个算子的一个依赖条件得到解决,调度器检查该算子是否就绪,如果不就绪,就仅仅保存当前算子的状态并出让线程资源(yield),让线程去处理其它算子的事情,当剩余的依赖条件在未来得到解决时,再恢复该算子的状态并继续检查是否就绪,如果就绪,就可以异步的把算子发射出去。
一个算子无论是否就绪,都不会占用线程太长时间。
对Golang里goroutine或者coroutine等所谓用户级线程(user thread)概念熟悉的朋友应该对上述机制有似曾相识的感觉,道理非常接近。这些原理被广泛应用于高并发网络服务框架,譬如百度开源的bRPC,以及腾讯开源的Flare等。
但很可惜,在OneFlow之前,没有其它深度学习框架意识到这个问题,并在执行引擎采用类似的机制。
OneFlow通过一种actor机制实现了完全异步的计算图调度和算子执行,从而可以放心地让一个线程服务于多个算子。TensorFlow正在研发的新版runtime ,他们也注意到这个问题,并在运行时系统的设计里强调了纯异步执行的重要性(Asynchrony as a first-class citizen in runtime)。
9
总结
为了让从算子到底层硬件资源的映射方法既保证高效运行,又保证安全稳定,我们提出了一种静态调度的方案,完成了从设备、stream、线程到算子的逐级映射和绑定。
根据实际可用的硬件资源配置stream和线程,在同一个stream上执行的算子绑定到同一个线程上,线程数是推导出来的固定数值,与计算图的并行度无关,不存在多余线程,运行期的决策机制也是最简的。
这种静态映射可行的关键是,让计算图调度和算子执行都完全异步,特别是支持算子状态上下文的保存和恢复。
原有框架多使用动态调度,理论上灵活性很强,不需要提前对资源使用情况做静态调度这么深入的分析,但要么存在稳定性的缺陷,要么无法充分利用硬件资源,为了克服这些问题,系统实现就非常复杂。
注:题图源自Pixabay
近期文章
点击“阅读原文”,欢迎下载体验OneFlow新一代开源深度学习框架

以上是关于动态调度的“诅咒”| 原有深度学习框架的缺陷③的主要内容,如果未能解决你的问题,请参考以下文章