自用文本分类->词嵌入模型
Posted 王六六的IT日常
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了自用文本分类->词嵌入模型相关的知识,希望对你有一定的参考价值。
前言
根据我们组大神发给我的学习资料做成的一个笔记,方便自己进行复习~~~~~~~
[2013]基于词向量的特征提取模型(word2vec)
参考:word2vec详解(一)、浅谈Word2vec、分层softmax_Hierarchical softmax(分层softmax)简单描述.
word2vec不是一个算法,它仅仅是一个工具包,将词转换为稠密的向量,它主要是包括以下两个内容:
两个模型:CBow和skip-gram
两种优化方式:hierarchical softmax和negative sampling(负采样)
1. CBow 模型
CBow 模型全称 Continuous Bag-of-Words Model,是在Bow基础上改进的连续型词袋模型。
结构图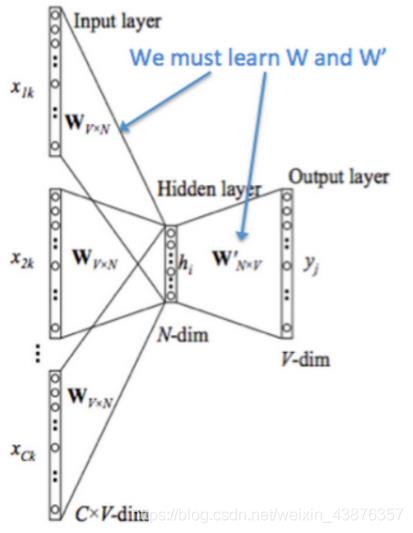
模型运算步骤
(1)以c为窗口大小(c一般为5),在一句话中从头到后依次滑动,每次取得c个词。将它们对应的向量(one-hot、随机生成或其它方法皆可)组成c个向量X1 X2…Xc-1 Xc送入输入层。X的尺寸为方便理解设为为Wo*c(Wo为词语总数,即词语向量空间维度);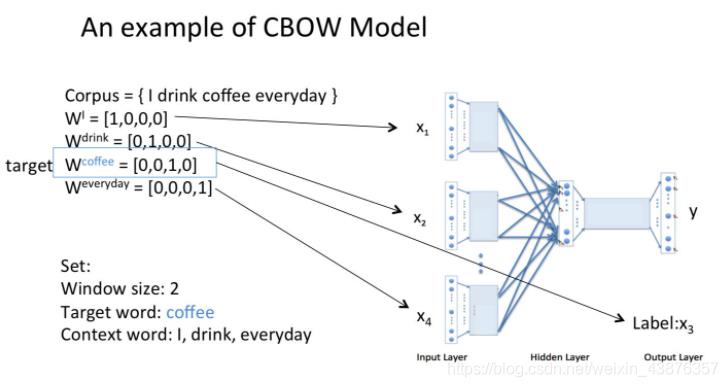
(2)将c个向量最中间的那个向量送给输入层用于训练,用剩下的c-1个向量分别右乘以矩阵W(N*Wo,N为人为设定数),获得模型中的词向量映射,得到V(N*(c-1));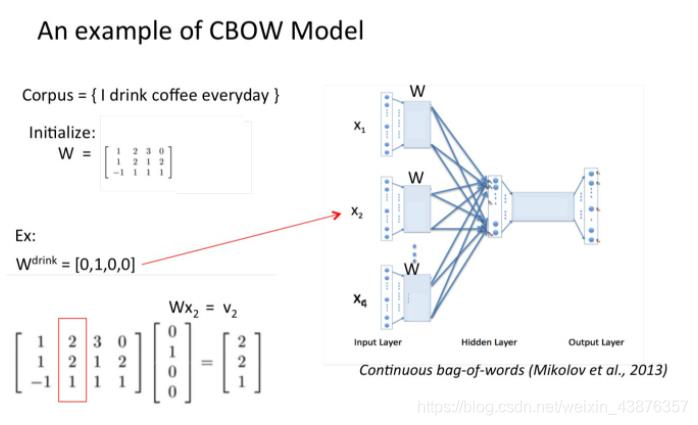
(3)将这c-1个向量对应元素相加除以c-1获得一个N*1的向量;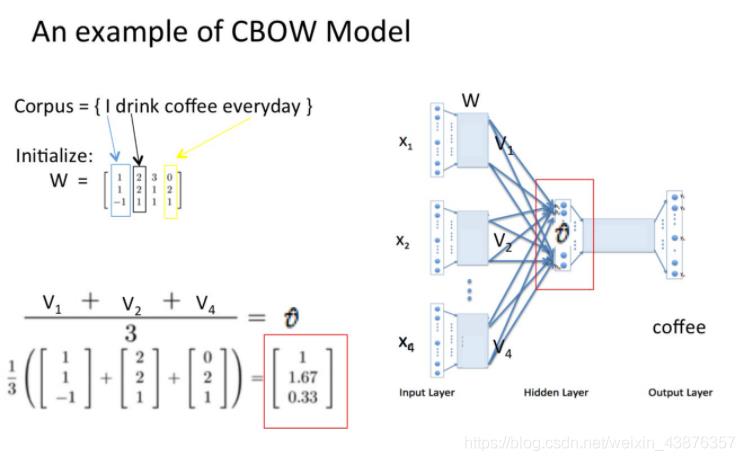
(4)将W’(Wo*N)与上一步骤获得的N*1向量相乘,得到一个新的向量U(Wo*1),但此时的向量没有进行任何处理。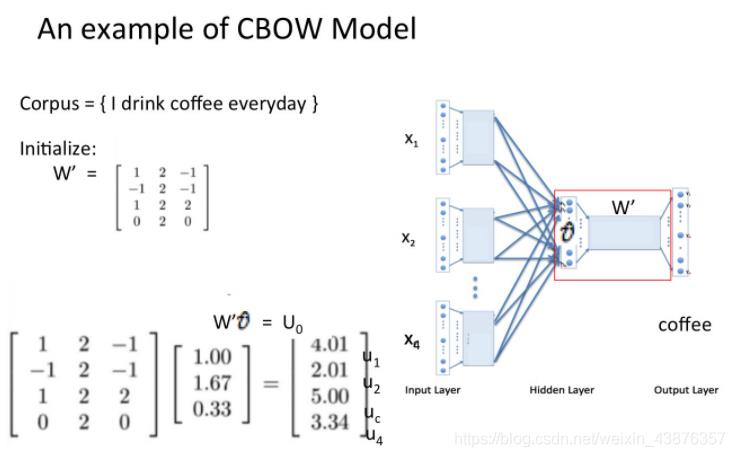
(5)将U(Wo*1)进行softmax处理,得到输出y。将y与第2步骤得到的向量计算loss,然后反向传播,迭代更新得到一个最合适的W和W’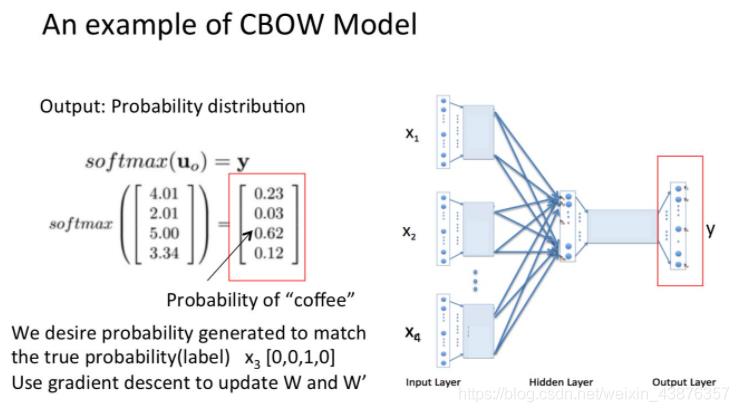
结论
输出层的输出和W‘只是副产物,我们真正需要的是W,有了W就可以获得词语向量空间中所有词语的向量映射。
2. skip-gram 模型
skip-gram可以看作CBow的逆向使用: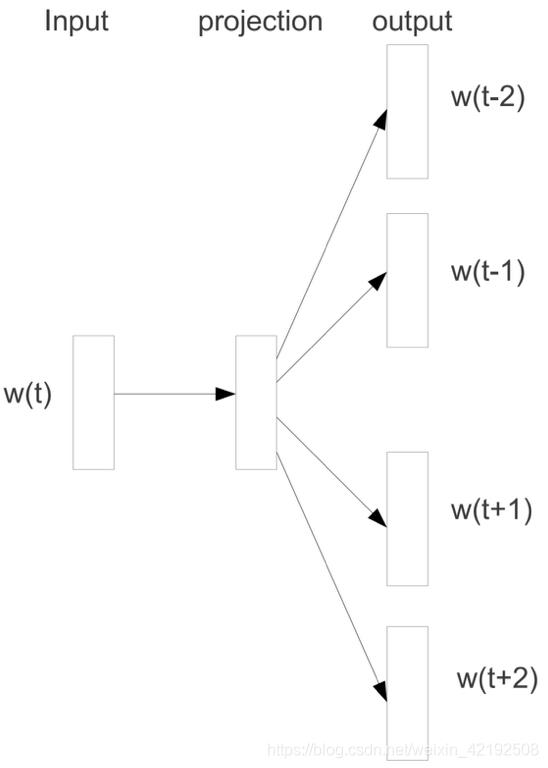
将一个词向量输入,然后获取该词的上下文,与CBow的效果大同小异。
2.4.3 hierarchical softmax 算法
hierarchical softmax实际上是fastText中设计的一种算法,其目的是优化softmax时间复杂度:softmax在求解的时候,它的时间复杂度和词表总量V一样,是性线性的,从它的函数方程式中,我们也可以很容易得出:
softmax: f(x) = e^x / sum( e^x_i ) ;
它需要对所有的词 e^x 求和。所以当V非常大的时候,哪怕时间复杂度是O(V),这个求解的过程耗时也比较“严重”。而hierarchical softmax算法则是去构造一棵哈夫曼树,其依据训练样本数据中的单词出现的频率,构建起来。频率越高,节点越短。
此时,当我们知道了目标单词x,之后,我们只需要计算root节点,到该词的路径累乘即可,不需要去遍历所有的节点信息,时间复杂度变为O(log2(V))
视频:https://www.bilibili.com/video/BV1ab411p7k7
具体如何工作后看论文再补
视频:https://www.bilibili.com/video/BV1ab411p7k7
后看论文再补
优点
(1)由于 Word2vec 会考虑上下文,跟之前的Embedding方法相比,效果要更好(但不如18年之后的方法);
(2)比之前的Embedding方法维度更少,所以速度更快;
(3)通用性很强,可以用在各种NLP任务中。
局限性
(1)由于词和向量是一对一的关系,所以多义词的问题无法解决;
(2)word2vec是一种静态的方式,虽然通用性强,但是无法针对特定任务做动态优化。
2.5 [2014] GloVe 模型
参考:[论文] GloVe: Global Vectors for Word Representation [4a6n]
GloVe全称Global Vectors for Word Representation(全局词向量),该模型核心思想是训练出蕴含共现矩阵所蕴含信息的词向量。
主要思路如下:
(1)暂借第三个词发掘某两个词的关系
GloVe模型统计大量语句,建立共现矩阵X。根据统计学和共现矩阵的知识可得:
矩阵单词i那一行的和
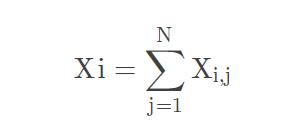
单词k出现在单词i语境中的概率
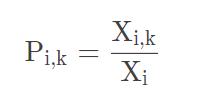
两个条件概率的比率
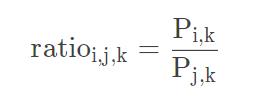
可以看出,公式中考虑到了三个词向量:i、j和k。至于引入ratio的目的是可以看到i和j各自与k的关系,即k出现时i和j出现的概率。可以看出,如果k出现的同时i和j出现的概率都大,ratio将会趋近于1,可得i和j的含义相近。比如‘好’出现时,‘非常’和‘很’出现的概率都大,那么ratio必将趋近于1,也就表示‘非常’和‘好’有着相近的含义。其余情况见下图:
需要注意的是,上图中‘很大’是远远大于1的,而‘很小’是相对趋近于0的。
在训练词向量前,ratio已经提供了识别同义词的必要条件,至于如何训练词向量将在下几个步骤讲解。
(2)定义代价函数,实现模型雏形
为了方便表示,将ratio设成函数g
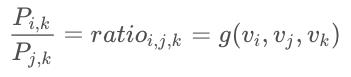
根据神经网络的简单思想,可应用差方获得损失函数再借助梯度下降来逐渐更新词向量i、j和k
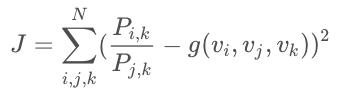
在不断的更新后,会获得一组符合ratio也就是共现矩阵的词向量。
尽管上图式子括号中的两项在数值上相等,但两项中的变量并不一样。前者是基于词频统计得来的,而后者是随机生成再训练而来的。能让这两项在数值上相等,这对ratio(g)有一定要求。在之前,ratio(g)一直被描述为“符合共现矩阵蕴含信息”的函数。而现在,尽可能地确定ratio(g)的形式极其重要,这将在下面介绍。
以上是关于自用文本分类->词嵌入模型的主要内容,如果未能解决你的问题,请参考以下文章