[Python从零到壹] 十.Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
Posted Eastmount
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了[Python从零到壹] 十.Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)相关的知识,希望对你有一定的参考价值。
欢迎大家来到“Python从零到壹”,在这里我将分享约200篇Python系列文章,带大家一起去学习和玩耍,看看Python这个有趣的世界。所有文章都将结合案例、代码和作者的经验讲解,真心想把自己近十年的编程经验分享给大家,希望对您有所帮助,文章中不足之处也请海涵。Python系列整体框架包括基础语法10篇、网络爬虫30篇、可视化分析10篇、机器学习20篇、大数据分析20篇、图像识别30篇、人工智能40篇、Python安全20篇、其他技巧10篇。您的关注、点赞和转发就是对秀璋最大的支持,知识无价人有情,希望我们都能在人生路上开心快乐、共同成长。
前一篇文章讲述了Selenium基础技术,涉及基础入门、元素定位、常用方法和属性、鼠标操作、键盘操作和导航控制。本文将结合具体实例进行深入地分析,通过三个基于Selenium技术的爬虫,爬取Wikipedia、百度百科和互动百科消息盒的例子,从实际应用出发来学习利用。基础性文章,希望对您有所帮助。
在线百科是基于Wiki技术的、动态的、免费的、可自由访问和编辑的多语言百科全书的Web2.0知识库系统。它是互联网中公开的、最大数量的用户生成的知识库,并且具有知识面覆盖度广、结构化程度高、信息更新速度快和开放性好等优势。其中被广泛使用的三大在线百科包括Wikipedia、百度百科和互动百科。
文章目录
下载地址:
前文赏析:
第一部分 基础语法
- [Python从零到壹] 一.为什么我们要学Python及基础语法详解
- [Python从零到壹] 二.语法基础之条件语句、循环语句和函数
- [Python从零到壹] 三.语法基础之文件操作、CSV文件读写及面向对象
第二部分 网络爬虫
- [Python从零到壹] 四.网络爬虫之入门基础及正则表达式抓取博客案例
- [Python从零到壹] 五.网络爬虫之BeautifulSoup基础语法万字详解
- [Python从零到壹] 六.网络爬虫之BeautifulSoup爬取豆瓣TOP250电影详解
- [Python从零到壹] 七.网络爬虫之Requests爬取豆瓣电影TOP250及CSV存储
- [Python从零到壹] 八.数据库之MySQL基础知识及操作万字详解
- [Python从零到壹] 九.网络爬虫之Selenium基础技术万字详解(定位元素、常用方法、键盘鼠标操作)
- [Python从零到壹] 十.Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)
作者新开的“娜璋AI安全之家”将专注于Python和安全技术,主要分享Web渗透、系统安全、人工智能、大数据分析、图像识别、恶意代码检测、CVE复现、威胁情报分析等文章。虽然作者是一名技术小白,但会保证每一篇文章都会很用心地撰写,希望这些基础性文章对你有所帮助,在Python和安全路上与大家一起进步。
一.三大在线百科
随着互联网和大数据的飞速发展,我们需要从海量信息中挖掘出有价值的信息,而在收集这些海量信息过程中,通常都会涉及到底层数据的抓取构建工作,比如多源知识库融合、知识图谱构建、计算引擎建立等。其中具有代表性的知识图谱应用包括谷歌公司的Knowledge Graph、Facebook推出的实体搜索服务(Graph Search)、百度公司的百度知心、搜狗公司的搜狗知立方等。这些应用的技术可能会有所区别,但相同的是它们在构建过程中都利用了Wikipedia、百度百科、互动百科等在线百科知识。所以本章将教大家分别爬取这三大在线百科。
百科是指天文、地理、自然、人文、宗教、信仰、文学等全部学科的知识的总称,它可以是综合性的,包含所有领域的相关内容;也可以是面向专业性的。接下来将介绍常见的三大在线百科,它们是信息抽取研究的重要语料库之一。
1.Wikipedia
“Wikipedia is a free online encyclopedia with the aim to allow anyone to edit articles.” 这是Wikipedia的官方介绍。Wikipedia是一个基于维基技术的多语言百科全书协作计划,用多种语言编写的网络百科全书。Wikipedia一词取自于该网站核心技术“Wiki”以及具有百科全书之意的“encyclopedia”共同创造出来的新混成词“Wikipedia”,接受任何人编辑。
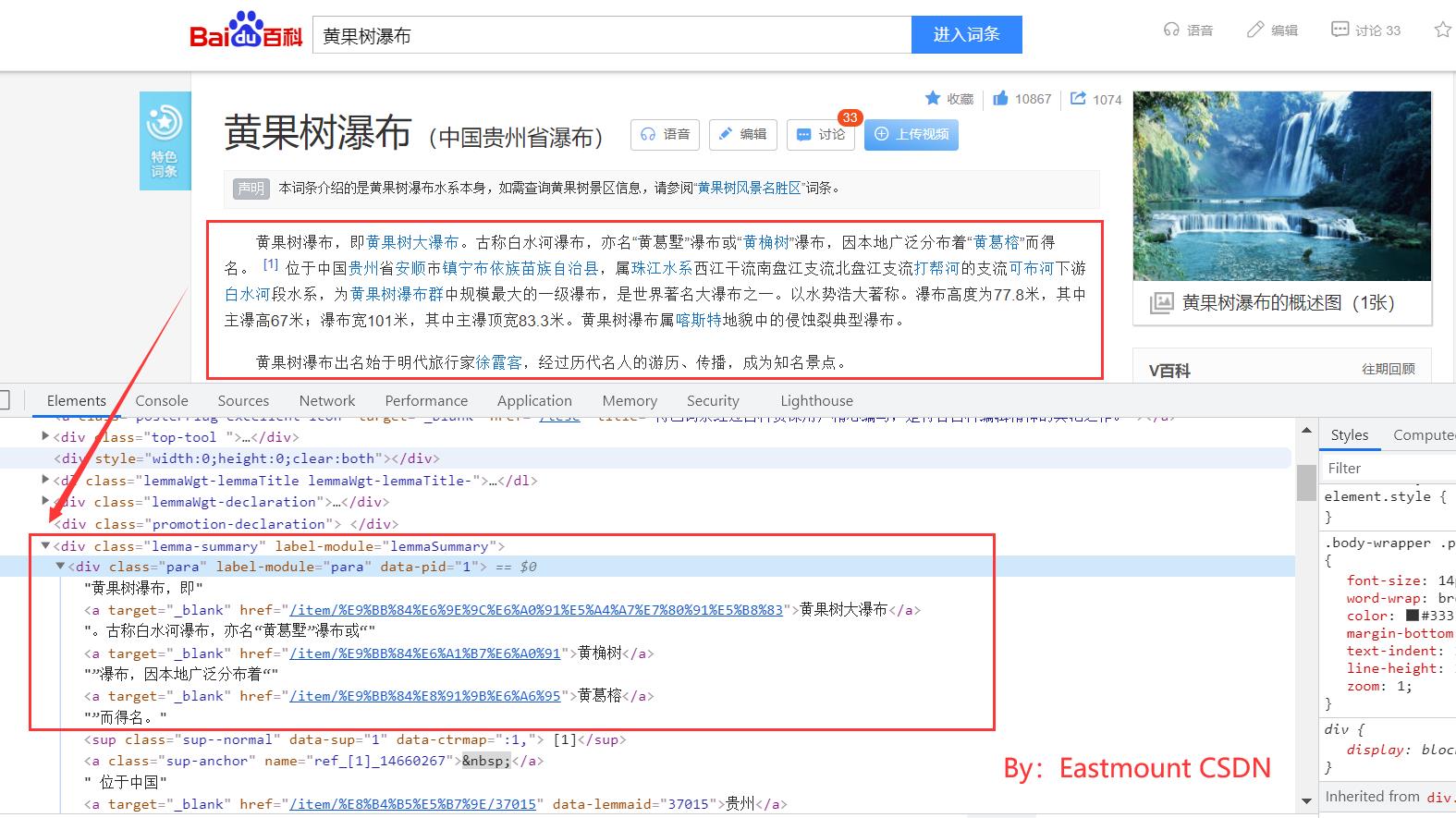
在所有在线百科中,Wikipedia知识准确性最好,结构化最好,但是Wikipedia本以英文知识为主,涉及的中文知识很少。在线百科页面通常包括:Title(标题)、Description(摘要描述)、InfoBox(消息盒)、Categories(实体类别)、Crosslingual Links(跨语言链接)等。Wikipedia中实体“黄果树瀑布”的中文页面信息如图1所示。
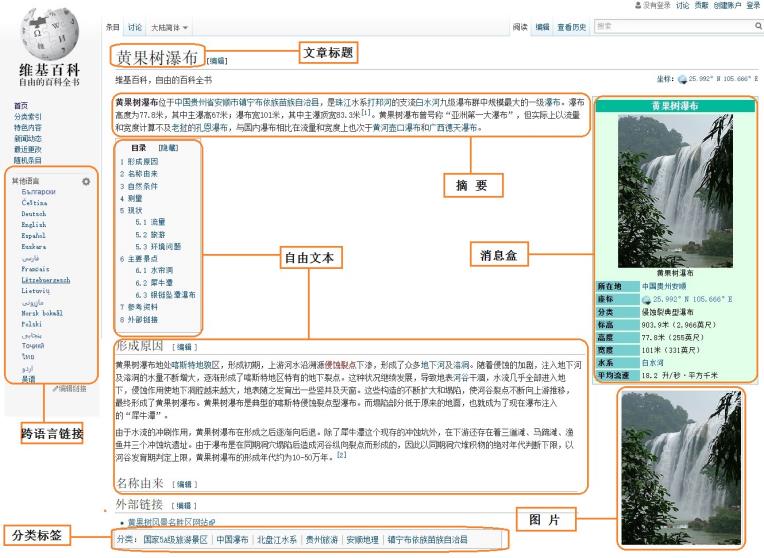
图1所示的Wikipedia信息主要包括:
- 文章标题(Article Title):唯一标识一篇文章(除存在歧义的页面),即对应一个实体,对应图中的“黄果树瀑布”。
- 摘要(Abstract):通过一段或两段精简的信息对整篇文章或整个实体进行描述,它具有重要的使用价值。
- 自由文本(Free Text):自由文本包括全文本内容和部分文本内容。全文本内容是描述整篇文章的所有文本信息,包括摘要信息和各个部分的信息介绍。部分文本内容是描述一篇文章的部分文本信息,用户可以自定义摘取。
- 分类标签(Category Label):用于鉴定该篇文章所属的类型,如图中“黄果树瀑布”包括的分类标签有“国家5A级旅游景区”、“中国瀑布”、“贵州旅游”等。
- 消息盒(InfoBox):又称为信息模块或信息盒。它采用结构化形式展现网页信息,用于描述文章或实体的属性和属性值信息。消息盒包含了一定数量的“属性-属性值”对,聚集了该篇文章的核心信息,用于表征整个网页或实体。
2.百度百科
百度百科是百度公司推出的一部内容开放、自由的网络百科全书平台。截至2017年4月,百度百科已经收录了超过1432万的词条,参与词条编辑的网友超过610万人,几乎涵盖了所有已知的知识领域。百度百科旨在创造一个涵盖各领域知识的中文信息收集平台。百度百科强调用户的参与和奉献精神,充分调动互联网用户的力量,汇聚广大用户的头脑智慧,积极进行交流和分享。同时,百度百科实现与百度搜索、百度知道的结合,从不同的层次上满足用户对信息的需求。
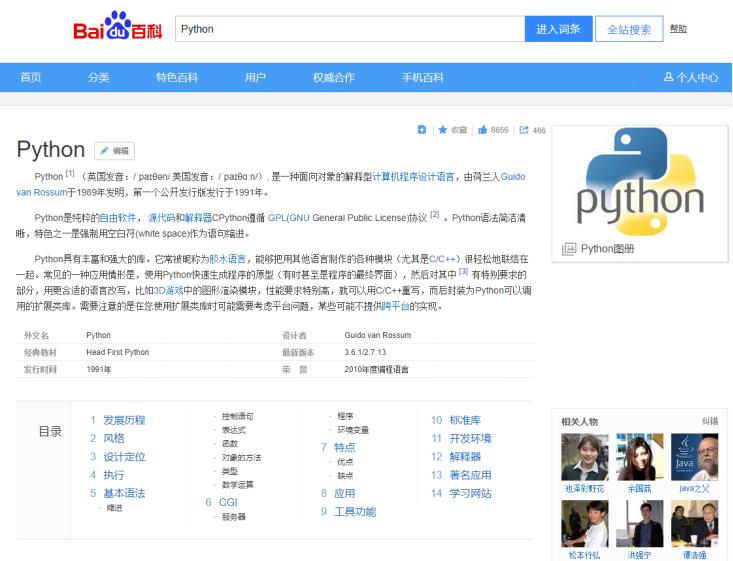
与Wikipedia相比,百度百科所包含中文知识最多最广,但是准确性相对较差。百度百科页面也包括:Title(标题)、Description(摘要描述)、InfoBox(消息盒)、Categories(实体类别)、Crosslingual Links(跨语言链接)等。图2为百度百科“Python”网页知识,该网页的消息盒为中间部分,采用键值对(Key-value Pair)的形式,比如“外文名”对应的值为“Python”,“经典教材”对应的值为“Head First Python”等。
3.互动百科
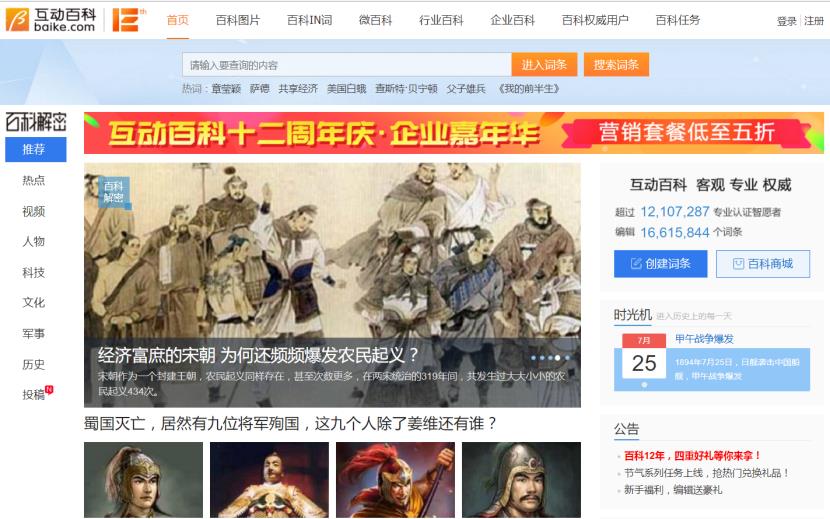
互动百科(www.baike.com)是中文百科网站的开拓与领军者,致力于为数亿中文用户免费提供海量、全面、及时的百科信息,并通过全新的维基平台不断改善用户对信息的创作、获取和共享方式。截止到2016年年底,互动百科已经发展成为由超过1100万用户共同打造的拥有1600万词条、2000万张图片、5万个微百科的百科网站,新媒体覆盖人群1000余万人,手机APP用户超2000万。
相对于百度百科而言,互动百科的准确性更高、结构化更好,在专业领域上知识质量较高,故研究者通常会选择互动百科作为主要语料之一。图3显示的是互动百科的首页。
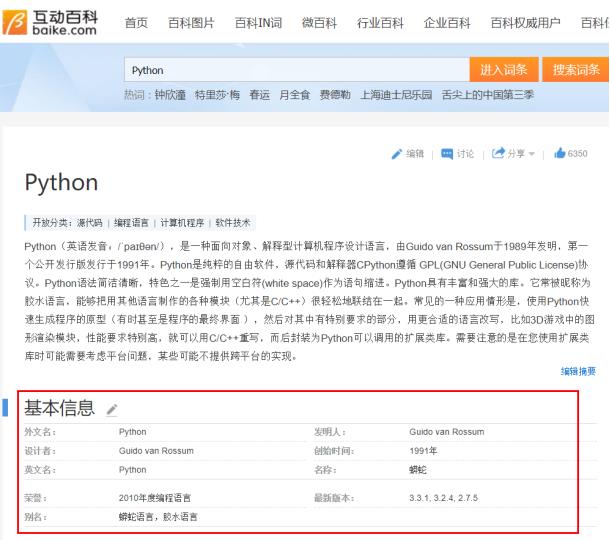
互动百科的信息分为两种形式存储,一种是百科中结构化的信息盒,另一种是百科正文的自由文本。对于百科中的词条文章来说,只有少数词条含有结构化信息盒,但所有词条均含有自由文本。信息盒是采用结构化方式展现词条信息的形式,一个典型的百科信息盒展示例子如图4,显示了Python的InfoBox信息,采用键值对的形式呈现,比如Python的“设计人”为“Guido van Rossum”。
下面分别讲解Selenium技术爬取三大在线百科的消息盒,三大百科的分析方法略有不同。Wikipedia先从列表页面分别获取20国集团(简称G20)各国家的链接,再依次进行网页分析和信息爬取;百度百科调用Selenium自动操作,输入各种编程语言名,再进行访问定位爬取;互动百科采用分析网页的链接url,再去到不同的景点进行分析及信息抓取。
二.Selenium爬取百度百科知识
百度百科作为最大的中文在线百科或中文知识平台,它提供了各行各业的知识,可以供研究者从事各方面的研究。虽然词条的准确率不是最好,但依然可以为从事数据挖掘、知识图谱、自然语言处理、大数据等领域的学者提供很好的知识平台。
1.网页分析
本小节将详细讲解Selenium爬取百度百科消息盒的例子,爬取的主题为10个国家5A级景区,其中景区的名单定义在TXT文件中,然后再定向爬取它们的消息盒信息。其中网页分析的核心步骤如下:
(1) 调用Selenium自动搜索百度百科关键词
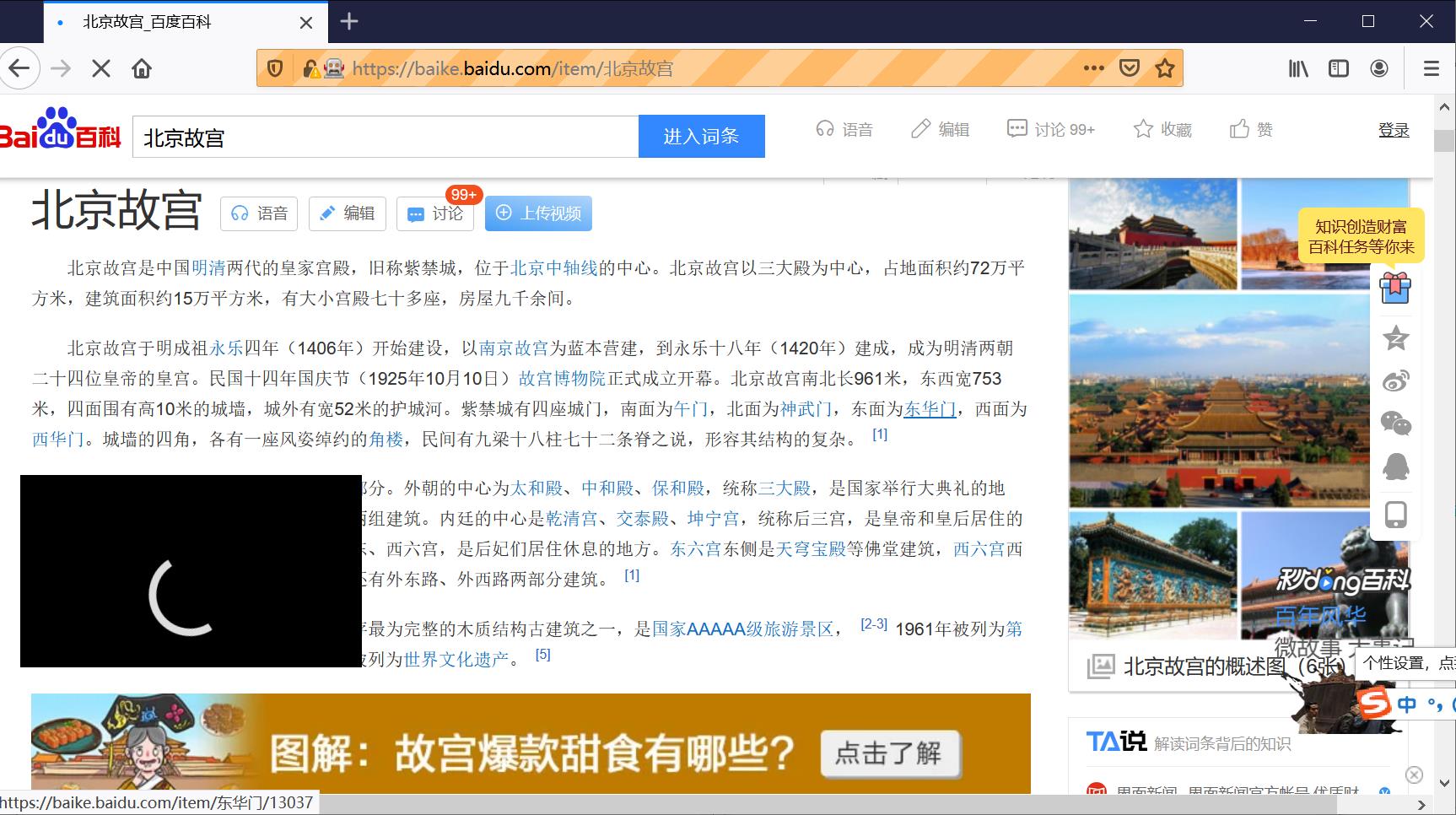
首先,调用Selenium技术访问百度百科首页,网址为“https://baike.baidu.com”,图5为百度百科首页,其顶部为搜索框,输入相关词条如“故宫”,点击“进入词条”,可以得到故宫词条的详细信息。
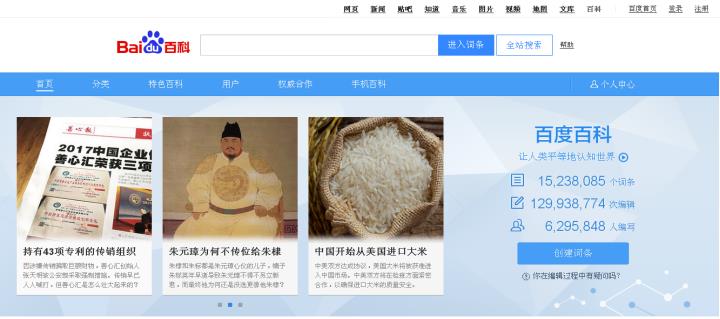
然后,在浏览器鼠标选中“进入词条”按钮,右键鼠标点击“审查元素”,可以查看该按钮对应的html源代码,如图6所示。注意,不同浏览器查看网页控件或内容对应源代码的称呼是不同的,图中使用的是360安全浏览器,称呼为“审查元素”,而Chrome浏览器称为“检查”,QQ浏览器称为“检查”等。
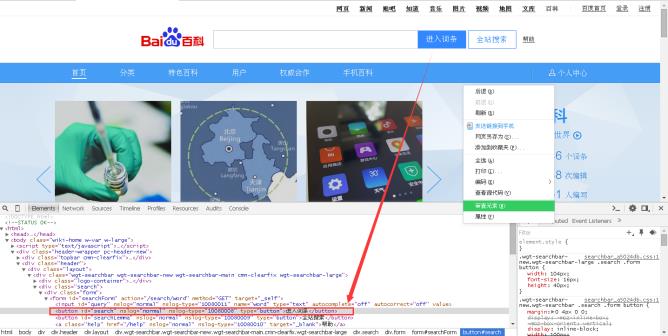
“进入词条”对应的HTML核心代码如下所示:
<div class="form">
<form id="searchForm" action="/search/word" method="GET">
<input id="query" nslog="normal" name="word" type="text"
autocomplete="off" autocorrect="off" value="">
<button id="search" nslog="normal" type="button">
进入词条
</button>
<button id="searchLemma" nslog="normal" type="button">
全站搜索
</button>
<a class="help" href="/help" nslog="normal" target="_blank">
帮助
</a>
</form>
...
</div>
调用Selenium函数可以获取输入框input控件。
- find_element_by_xpath("//form[@id=‘searchForm’]/input")
然后自动输入“故宫”,获取按钮“进入词条”并自动点击,这里采用的方法是在键盘上输入回车键即可访问“故宫”界面,核心代码如下所示:
driver.get("http://baike.baidu.com/")
elem_inp=driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
(2) 调用Selenium访问“故宫”页面并定位消息盒
第一步完成后,进入“故宫”页面然后找到中间消息盒InfoBox部分,右键鼠标并点击“审查元素”,返回结果如图7所示。
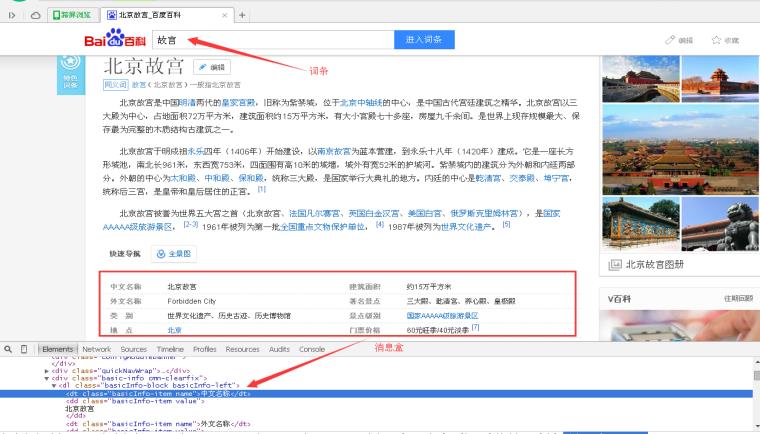
消息盒核心代码如下:
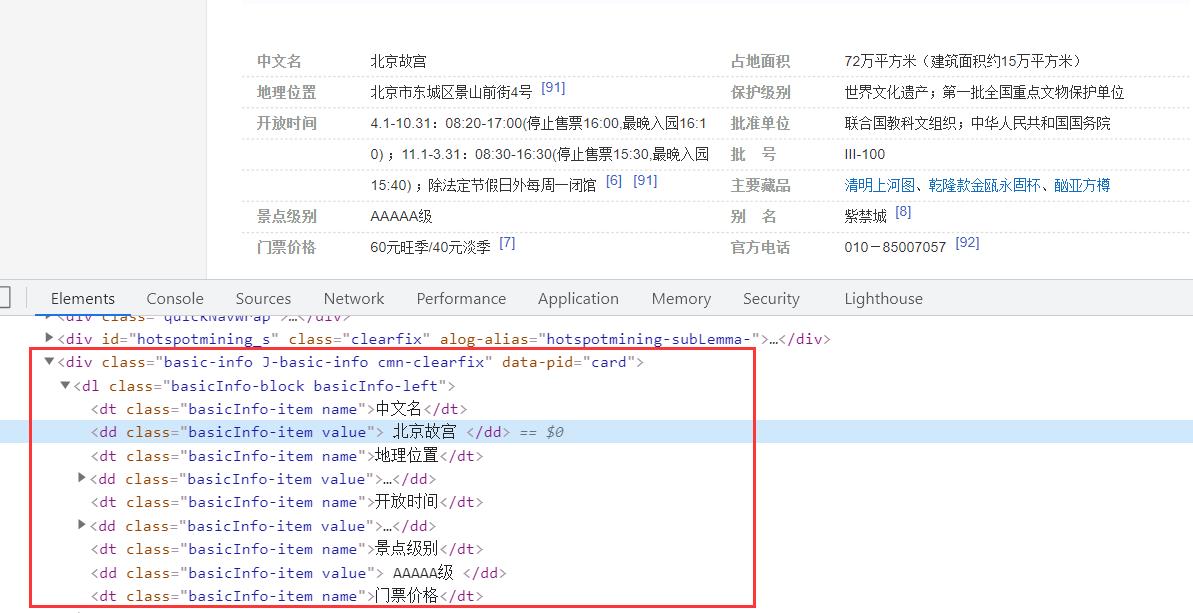
消息盒主要采用<属性-属性值>的形式存储,详细概括了“故宫”实体的信息。例如,属性“中文名称”对应值为“北京故宫”,属性“外文名称”对应值为“Fobidden City”。对应的HTML部分源代码如下。
<div class="basic-info J-basic-info cmn-clearfix">
<dl class="basicInfo-block basicInfo-left">
<dt class="basicInfo-item name">中文名称</dt>
<dd class="basicInfo-item value">
北京故宫
</dd>
<dt class="basicInfo-item name">外文名称</dt>
<dd class="basicInfo-item value">
Forbidden City
</dd>
<dt class="basicInfo-item name">类 别</dt>
<dd class="basicInfo-item value">
世界文化遗产、历史古迹、历史博物馆
</dd>
</dl>
...
<dl class="basicInfo-block basicInfo-right">
<dt class="basicInfo-item name">建筑面积</dt>
<dd class="basicInfo-item value">
约15万平方米
</dd>
<dt class="basicInfo-item name">著名景点</dt>
<dd class="basicInfo-item value">
三大殿、乾清宫、养心殿、皇极殿
</dd>
</dl>
...
</div>
整个消息盒位于< div class=“basic-info J-basic-info cmn-clearfix” >标签中,接下来是< dl >、< dt >、< dd >一组合HTML标签,其中消息盒div布局共包括两个< dl >…</ dl >布局,一个是记录消息盒左边部分的内容,另一个< dl >记录了消息盒右部分的内容,每个< dl >标签里再定义属性和属性值,如图8所示。

注意:使用dt、dd最外层必须使用dl包裹,< dl >标签定义了定义列表(Definition List),< dt >标签定义列表中的项目,< dd >标签描述列表中的项目,此组合标签叫做表格标签,与table表格组合标签类似。
接下来调用Selenium扩展包的find_elements_by_xpath()函数分别定位属性和属性值,该函数返回多个属性及属性值集合,再通过for循环输出已定位的多个元素值。代码如下:
elem_name=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dt")
elem_value=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dd")
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
此时,使用Selenium技术爬取百度百科国家5A级景区的分析方法就讲解完了,下面是这部分完整的代码及一些难点。
2.代码实现
注意,接下来我们尝试定义多个Python文件相互调用实现爬虫功能。完整代码包括两个文件,即:
- test10_01_baidu.py:定义了主函数main并调用getinfo.py文件
- getinfo.py:通过getInfobox()函数爬取消息盒
test10_01_baidu.py
# -*- coding: utf-8 -*-
"""
test10_01_baidu.py
定义了主函数main并调用getinfo.py文件
By:Eastmount CSDN 2021-06-23
"""
import codecs
import getinfo #引用模块
#主函数
def main():
#文件读取景点信息
source = open('data.txt','r',encoding='utf-8')
for name in source:
print(name)
getinfo.getInfobox(name)
print('End Read Files!')
source.close()
if __name__ == '__main__':
main()
在代码中调用“import getinfo”代码导入getinfo.py文件,导入之后就可以在main函数中调用getinfo.py文件中的函数和属性,接着我们调用getinfo.py文件中的getInfobox()函数,执行爬取消息盒的操作。
getinfo.py
# coding=utf-8
"""
getinfo.py:获取信息
By:Eastmount CSDN 2021-06-23
"""
import os
import codecs
import time
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
#getInfobox函数: 获取国家5A级景区消息盒
def getInfobox(name):
try:
#访问百度百科并自动搜索
driver = webdriver.Firefox()
driver.get("http://baike.baidu.com/")
elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input")
elem_inp.send_keys(name)
elem_inp.send_keys(Keys.RETURN)
time.sleep(1)
print(driver.current_url)
print(driver.title)
#爬取消息盒InfoBox内容
elem_name=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dt")
elem_value=driver.find_elements_by_xpath("//div[@class='basic-info J-basic-info cmn-clearfix']/dl/dd")
"""
for e in elem_name:
print(e.text)
for e in elem_value:
print(e.text)
"""
#构建字段成对输出
elem_dic = dict(zip(elem_name,elem_value))
for key in elem_dic:
print(key.text,elem_dic[key].text)
time.sleep(5)
return
except Exception as e:
print("Error: ",e)
finally:
print('\\n')
driver.close()
比如爬取过程Firefox浏览器会自动搜索“故宫”页面,如下图所示:
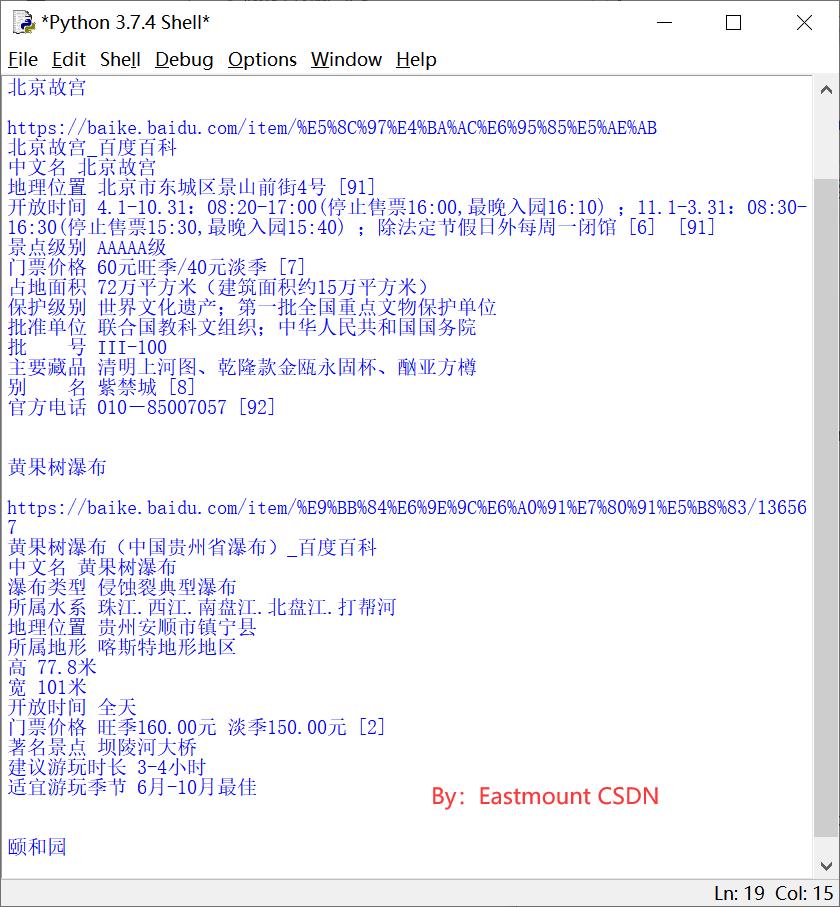
最终输出结果如下图所示:
内容如下:
https://baike.baidu.com/item/北京故宫
北京故宫_百度百科
https://baike.baidu.com/item/%E5%8C%97%E4%BA%AC%E6%95%85%E5%AE%AB
北京故宫_百度百科
中文名 北京故宫
地理位置 北京市东城区景山前街4号 [91]
开放时间 4.1-10.31:08:20-17:00(停止售票16:00,最晚入园16:10) ;11.1-3.31:08:30-16:30(停止售票15:30,最晚入园15:40) ;除法定节假日外每周一闭馆 [6] [91]
景点级别 AAAAA级
门票价格 60元旺季/40元淡季 [7]
占地面积 72万平方米(建筑面积约15万平方米)
保护级别 世界文化遗产;第一批全国重点文物保护单位
批准单位 联合国教科文组织;中华人民共和国国务院
批 号 III-100
主要藏品 清明上河图、乾隆款金瓯永固杯、酗亚方樽
别 名 紫禁城 [8]
官方电话 010-85007057 [92]
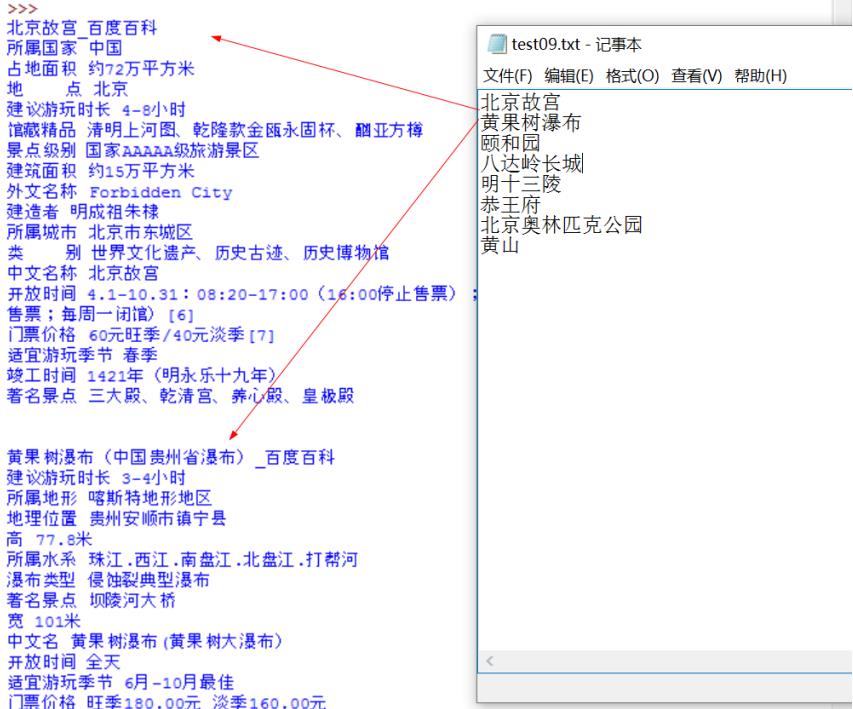
Python运行结果如下所示,其中data.txt文件中包括了常见的几个景点。
- 北京故宫
- 黄果树瀑布
- 颐和园
- 八达岭长城
- 明十三陵
- 恭王府
- 北京奥林匹克公园
- 黄山
上述代码属性和属性值通过字典进行组合输出的,核心代码如下:
elem_dic = dict(zip(elem_name,elem_value))
for key in elem_dic:
print(key.text,elem_dic[key].text)
同时,读者可以尝试调用本地的无界面浏览器PhantomJS进行爬取的,调用方法如下:
webdriver.PhantomJS(executable_path="C:\\...\\phantomjs.exe")
课程作业:
- 作者这里教大家爬取了消息盒,同时百科知识的摘要及正文也非常重要,读者不妨尝试分别爬取。这些语料都将成为您后续文本挖掘或NLP领域的必备储备,比如文本分类、实体对齐、实体消歧、知识图谱构建等。
三.Selenium爬取Wikipedia
在线百科是互联网中存在公开的最大数据量的用户生成数据集合,这些数据具有一定的结构,属于半结构化数据,最知名的三大在线百科包括Wikipedia 、百度百科、互动百科。首先,作者将介绍Selenium爬取Wikipedia的实例。
1.网页分析
第一个实例作者将详细讲解Selenium爬取20国家集团(G20)的第一段摘要信息,具体步骤如下:
(1) 从G20列表页面中获取各国超链接
20国集团列表网址如下,Wikipedia采用国家英文单词首写字母进行排序,比如“Japan”、“Italy”、“Brazil”等,每个国家都采用超链接的形式进行跳转。
- https://en.wikipedia.org/wiki/Category:G20_nations
首先,需要获取20个国家的超链接,然后再去到具体的页面进行爬取。选中一个国家的超链接,比如“China”,右键鼠标并点击“检查”按钮,可以获取对应的HTML源代码,如下所示。
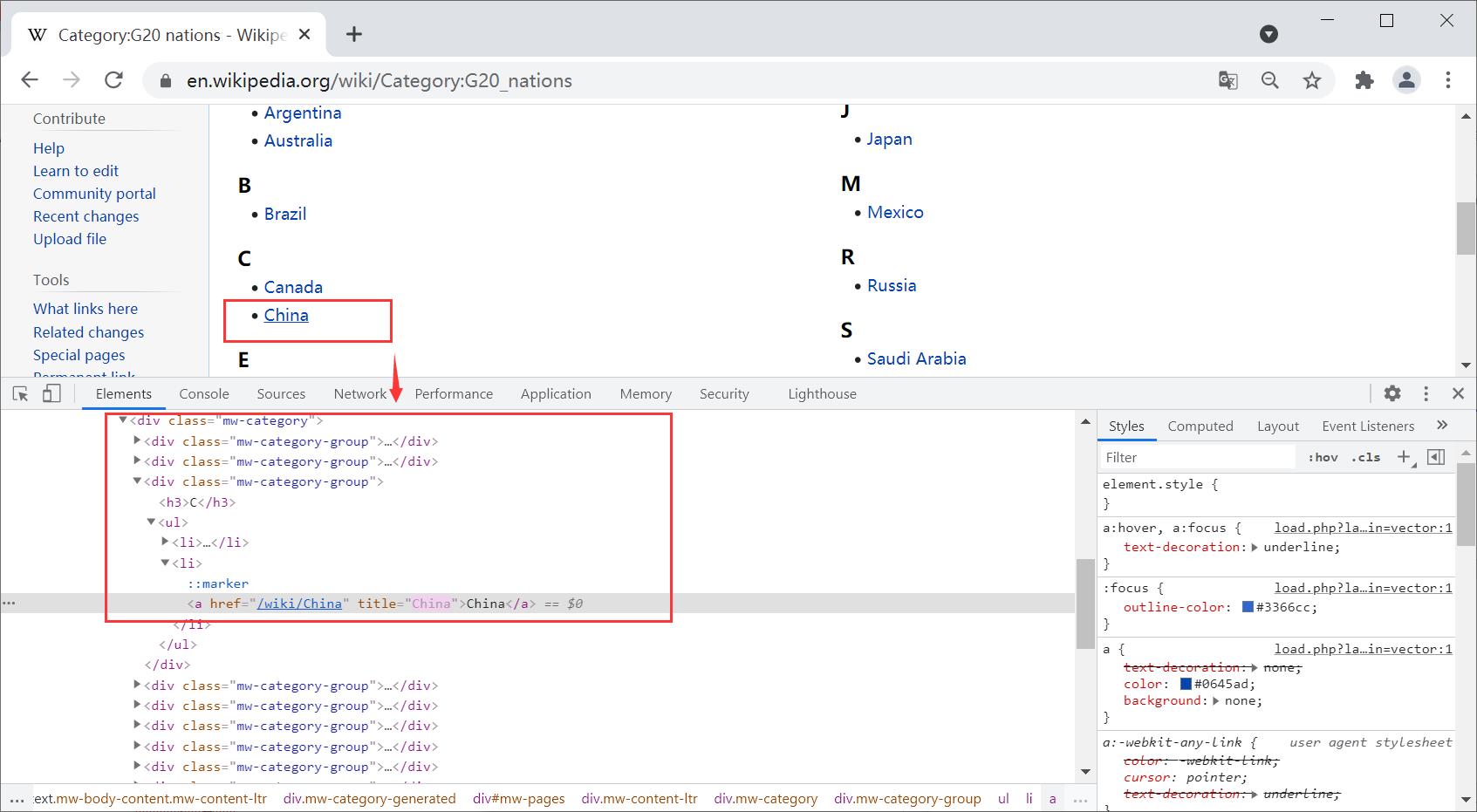
其中超链接位于< div class=“mw-category-group” >布局的< ul >< li >< a >节点下,对应代码:
<div class="mw-pages">
<div lang="en" dir="ltr" class="mw-content-ltr">
<div class="mw-category">
<div class="mw-category-group">
<h3>C<h3>
<ul><li>
<a href="/wiki/China" title="China">China</a>
</li></ul>
</div>
<div class="mw-category-group">...</div>
<div class="mw-category-group">...</div>
...
</div>
</div>
</div>
调用Selenium的find_elements_by_xpath()函数获取节点class属性为“mw-category-group”的超链接,它将返回多个元素。定位超链接的核心代码如下:
driver.get("https://en.wikipedia.org/wiki/Category:G20_nations")
elem=driver.find_elements_by_xpath("//div[@class='mw-category-group']/ul/li/a")
for e in elem:
print(e.text)
print(e.get_attribute("href"))
函数find_elements_by_xpth()先解析HTML的DOM树形结构并定位到指定节点,并获取其元素。然后定义一个for循环,依次获取节点的内容和href属性,其中e.text表示节点的内容,例如下面节点之间的内容为China。
<a href="/wiki/China" title="China">China</a>
同时,e.get_attribute(“href”)表示获取节点属性href对应的属性值,即“/wiki/China”,同理,e.get_attribute(“title”)可以获取标题title属性,得到值“China”。
此时将获取的超链接存储至变量中如下图,再依次定位到每个国家并获取所需内容。

(2) 调用Selenium定位并爬取各国页面消息盒
接下来开始访问具体的页面,比如中国“https://en.wikipedia.org/wiki/China”,如图所示,可以看到页面的URL、标题、摘要、内容、消息盒等,其中消息盒在途中右部分,包括国家全称、位置等。
下面采用<属性-属性值>对的形式进行描述,很简明精准地概括了一个网页实体,比如<首都-北京>、<人口-13亿人>等信息。通常获取这些信息之后,需要进行预处理操作,之后才能进行数据分析,后面章节将详细讲解。
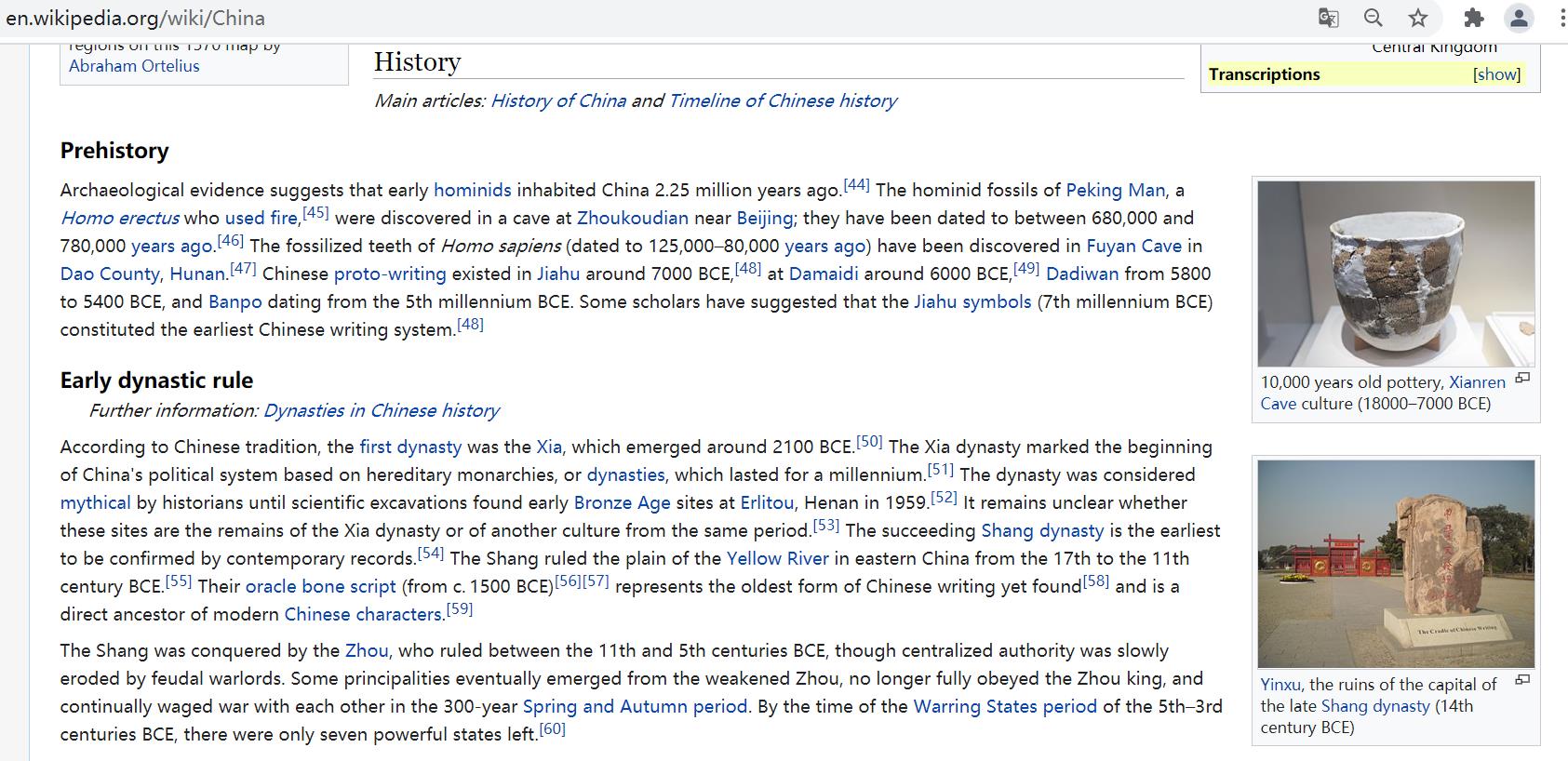
访问到每个国家的页面后,接下来需要获取每个国家的第一段介绍,本小节讲解的爬虫内容可能比较简单,但是讲解的方法非常重要,包括如何定位节点及爬取知识。详情页面对应的HTML核心部分代码如下:
<div class="mw-parser-output">
<div role="note" class="hatnote navigation-not-searchable">...</div>
<div role="note" class="hatnote navigation-not-searchable">...</div>
<table class="infobox gegraphy vcard">...</table>
<p>
<b>China</b>
, officially the
<b>People’s Republic of China</b>
....
</p>
<p>...</p>
<p>...</p>
...
</table>
</div>
</div>
</div>
浏览器审查元素方法如图所示。
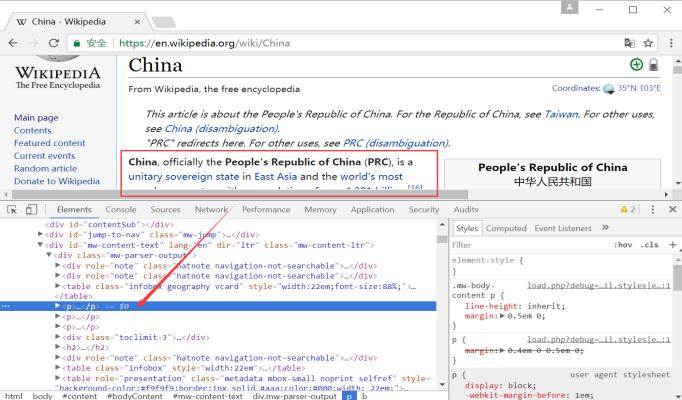
正文内容位于属性class为“mw-parser-output”的< div >节点下。在HTML中,< P >标签表示段落,通常用于标识正文,< b >标签表示加粗。获取第一段内容即定位第一个< p >节点即可。核心代码如下:
driver.get("https://en.wikipedia.org/wiki/China")
elem=driver.find_element_by_xpath("//div[@class='mw-parser-output']/p[2]").text
print elem
注意,正文第一段内容位于第二个< p >段落,故获取p[2]即可。同时,如果读者想从源代码中获取消息盒,则需获取消息盒的位置并抓取数据,消息盒(InfoBox)内容在HTML对应为如下节点,记录了网页实体的核心信息。
<table class="infobox gegraphy vcard">...</table>
2.代码实现
完整代
以上是关于[Python从零到壹] 十.Selenium爬取在线百科知识万字详解(NLP语料构造必备技能)的主要内容,如果未能解决你的问题,请参考以下文章