深度学习focal loss介绍
Posted 超级无敌陈大佬的跟班
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了深度学习focal loss介绍相关的知识,希望对你有一定的参考价值。
目录
一、focal loss解决的问题:
因此针对类别不均衡问题,作者提出一种新的损失函数:focal loss
这个损失函数是在标准交叉熵损失基础上修改得到的。可以通过减少易分类样本的权重,使得模型在训练时更专注于难分类的样本。
1.1 普通交叉熵
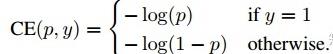
1.2 交叉熵基本改进版
接下来介绍一个最基本的对交叉熵的改进,也将作为本文实验的baseline,既然one-stage detector在训练的时候正负样本的数量差距很大,那么一种常见的做法就是给正负样本加上权重,负样本出现的频次多,那么就降低负样本的权重,正样本数量少,就相对提高正样本的权重。因此可以通过设定a的值来控制正负样本对总的loss的共享权重。a取比较小的值来降低负样本(多的那类样本)的权重。
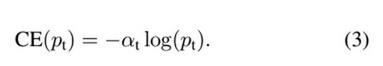
1.3 交叉熵进一步改进版
显然前面的公式3虽然可以控制正负样本的权重,但是没法控制容易分类和难分类样本的权重,于是就有了focal loss:
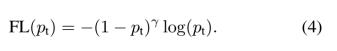
这里的γ称作focusing parameter,γ>=0。
1.4 focal loss版本
结合了公式3和公式4,这样既能调整正负样本的权重,又能控制难易分类样本的权重
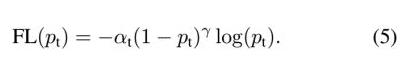
其中![]() 称为调制系数(modulating factor)。
称为调制系数(modulating factor)。
二、focal loss的两个重要性质:
1、关于调制系数
- 当一个样本的概率得分pt很小时,调制因子(1-Pt)越大且接近1,此时调制系数也趋近于1,损失函数的权重基本没有减少;
- 当一个样本的概率得分pt很大趋近于1时,调制因子(1-Pt)接近0,此时调制系数也趋近于0,导致损失函数的权重降低到接近0。那么分的比较好(概率得分高)的样本的loss的权值就被调低了。
- 原理:正常交叉熵loss的权重为1,而focalloss通过调制系数控制loss的权重,难样本(得分低)的权重趋近于1,而简单样本(得分高)的权重会被缩放到很小。难样本loss权重不变,减小简单样本loss权重,也就相当于增大了难样本权重。
2、参数γ的取值
- 当γ=0的时候,focal loss就是传统的交叉熵损失,当γ增加的时候,调制系数也会增加。 专注参数γ平滑地调节了易分样本调低权值的比例。
- γ增大能增强调制因子的影响,实验发现γ取2最好。直觉上来说,调制因子减少了易分样本的损失贡献,拓宽了样例接收到低损失的范围。
- 当γ一定的时候,比如等于2,一样easy example(pt=0.9)的loss要比标准的交叉熵loss小100+倍,当pt=0.968时,要小1000+倍,但是对于hard example(pt < 0.5),loss最多小了4倍。这样的话hard example的权重相对就提升了很多。也就增加了那些误分类样本的重要性。
focal loss的两个性质算是核心,其实就是用一个合适的函数去度量难分类和易分类样本对总的损失的贡献。
指数函数图像:即为focalloss中的调制系数函数图像(主要看x坐标0~1范围)
图1 focalloss中的调制系数函数图像
-log对数函数图像:
以上是关于深度学习focal loss介绍的主要内容,如果未能解决你的问题,请参考以下文章