编译原理复习总结-耗子尾汁
Posted 吾仄lo咚锵
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了编译原理复习总结-耗子尾汁相关的知识,希望对你有一定的参考价值。

引论
- 编译程序运行框架
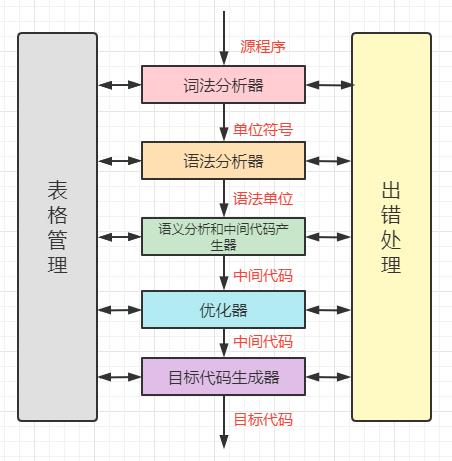
| 词法分析器 | 输入源程序,进行词法分析,输出单词符号。 |
|---|---|
| 语法分析器 | 对单词符号串进行语法分析,识别出各类语法单位 |
| 语义分析与中间代码产生器 | 按语义规则对归约出的语法单位进行语义分析并翻译成中间代码。 |
| 优化器 | 对中间代码进行优化处理 |
| 目标代码生成器 | 把中间代码翻译成目标程序 |
| 表格管理 | 登记源程序的各类信息和编译各阶段的进展情况 |
| 出错处理 | 对出现在源程序中的错误进行处理 |
- 编译前端和后端
- 前端
主要由与源语言有关但与目标机无关的那些部分(词法分析、语法分析、语义分析、中间代码产生)组成,有的代码优化工作也给包括在前端。 - 后端
包括编译程序中与目标机有关的那些部分(与目标机有关的代码优化、目标代码生成),后端通常依赖中间语言而不是源语言。
-
编译过程五个阶段
词法分析、语法分析、语义分析与中间代码产生、优化、目标代码生成。
前四个阶段与硬件无关,最后一个阶段与硬件有关。 -
汇编语言和高级语言的区别
汇编语言跟机器指令一一对应,高级语言不跟机器指令一一对应。
语法描述
- 乔姆斯基四型文法
乔姆斯基(Chomsky)把文法分成四种类型,即0型、1型、2型和3型。0型强于1型,1型强于2型,2型强于3型。这几类文法的差别在于对产生式加不同的限制。
| 0型 | 短语文法 | 能力相当于图灵机,都是递归可枚举的 |
|---|---|---|
| 1型 | 上下文有关法 | 即替换非终结符时考虑上下文 α \\alpha α和 β \\beta β, α A β → α γ β \\alpha A\\beta→\\alpha\\gamma\\beta αAβ→αγβ |
| 2型 | 上下文无关法 | 即无需考虑上下文 |
| 3型 | 右线性文法 | 另一种形式左线性文法,也称正规文法, A → B α A→B\\alpha A→Bα或 A → α A→\\alpha A→α |
-
上下文无关法
一个上下文无关法G是一个四元式 G = ( V T , V N , S , P ) G=(V_T,V_N,S,P) G=(VT,VN,S,P),其中
V T V_T VT:终结符集合(非空)
V N V_N VN:非终结符集合(非空),且 V T ∩ V N = ∅ V_T\\cap V_N=\\varnothing VT∩VN=∅
S S S:文法的开始符号, S ∈ V N S\\in V_N S∈VN
P P P:产生式集合(有限),每个产生式形式为 P → α , P ∈ V N , α ∈ ( V T ∪ V N ) ∗ P\\rarr\\alpha,P\\in V_N,\\alpha\\in (V_T\\cup V_N)^* P→α,P∈VN,α∈(VT∪VN)∗,开始符 S S S至少必须在某个产生式的左部出现一次。 -
句型、句子
假定G是一个文法,S是它的开始符号,称 S ⟹ ∗ α S\\overset{*}{\\implies}\\alpha S⟹∗α是一个句型,称仅含终结符的句型是一个句子。
btw,符号 ⟹ ∗ \\overset{*}{\\implies} ⟹∗指经过0步及以上推导;符号 ⟹ + \\overset{+}{\\implies} ⟹+指经过1步及以上推导;终结符指最终出现在程序中符号;非终结符是为了描述语法而创造出来的符号,不会出现在程序中。
例 ( i ∗ i + i ) (i*i+i) (i∗i+i)是文法G(E): E → i ∣ E + E ∣ E ∗ E ∣ ( E ) E→i|E+E|E*E|(E) E→i∣E+E∣E∗E∣(E)的一个句子,证明: E ⟹ ( E ) ⟹ ( E + E ) ⟹ ( E ∗ E + E ) ⟹ ( i ∗ E + E ) ⟹ ( i ∗ i + E ) ⟹ ( i ∗ i + i ) E\\implies(E)\\implies(E+E)\\implies(E*E+E)\\implies(i*E+E)\\implies(i*i+E)\\implies(i*i+i) E⟹(E)⟹(E+E)⟹(E∗E+E)⟹(i∗E+E)⟹(i∗i+E)⟹(i∗i+i) -
语言
文法G所产生的句子的全体就是一个语言,记为L(G), L ( G ) = { α ∣ S ⟹ + α & α ∈ V T ∗ } L(G)=\\{\\alpha|S\\overset{+}{\\implies}\\alpha\\&\\alpha\\in{V_{T}^{*}}\\} L(G)={α∣S⟹+α&α∈VT∗}。
例文法G1:A→c|Ab的语言L(G1)={cbn|n≥0};
文法G2:S→AB,A→aA|a,B→bB|b的语言L(G2)={ambn|m,n≥1}。
词法分析
- 用状态图和正规式描述标识符
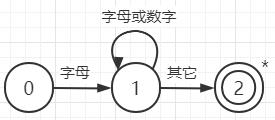
结点代表状态,用圆圈表示。状态之间用箭弧连结。箭弧上的标记(字符)代表在射出节点状态下可能出现得输入字符或字符类。
其中0为初态,2为终态(用双圈表示)。终态结上打个星号*意味着多读进了一个不属于标识符部分得字符,应把它退还给输入串。
令
Σ
=
{
A
,
B
,
0
,
1
}
\\Sigma=\\{A,B,0,1\\}
Σ={A,B,0,1}
| 正规式 | 正规集 |
|---|---|
| (A|B)(A|B|0|1)* | Σ \\Sigma Σ上“标识符”的全体 |
| (0|1)(0|1)* | Σ \\Sigma Σ上“数”的全体 |
-
确定有限自动机(DFA)
一个确定有限自动机M是一个五元式 M = ( S , Σ , δ , s 0 , F ) M=(S,\\Sigma,\\delta,s_0,F) M=(S,Σ,δ,s0,F),其中
S S S:有穷状态集
Σ \\Sigma Σ:输入字母表(有穷)
δ \\delta δ:状态转换函数,为 S × Σ → S S×\\Sigma\\rarr S S×Σ→S的单值部分映射, δ ( s , a ) = s ’ \\delta(s, a)=s’ δ(s,a)=s’表示:当现行状态为 s s s,输入字符为 a a a时,将状态转换到下一状态 s ’ s’ s’。我们把 s ’ s’ s’称为 s s s的一个后继状态。
s 0 ∈ S s_0\\in S s0∈S:初态(唯一)
F ⊆ S F\\sube S F⊆S:终态集(可空) -
非确定有限自动机(NFA)
一个非确定有限自动机M是一个五元式 M = ( S , Σ , δ , S 0 , F ) M=(S,\\Sigma,\\delta,S_0,F) M=(S,Σ,δ,S0,F),其中
S S S:有穷状态集
Σ \\Sigma Σ:输入字母表(有穷)
δ \\delta δ: S × Σ ∗ → 2 S S×\\Sigma^*\\rarr2^S S×Σ∗→2S
S 0 ⊆ S S_0\\sube S S0⊆S:初态集(非空)
F ⊆ S F\\sube S F⊆S:终态集(可空) -
LEX
LEX用来描述和自动产生所需的各种词法分析器,包括正规式定义和识别规则两部分,将LEX程序编译后所得结果程序记为L,其作用同有限自动机一样&#以上是关于编译原理复习总结-耗子尾汁的主要内容,如果未能解决你的问题,请参考以下文章