如何打造一个工业级水平的散列表?
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了如何打造一个工业级水平的散列表?相关的知识,希望对你有一定的参考价值。

散列表
散列表的英文叫“Hash Table”,我们平时也叫它“哈希表”或者“Hash 表”、
我们通过散列函数把元素的键值映射为下标,然后将数据存储在数组中对应下标的位置。当我们按照键值查询元素时,我们用同样的散列函数,将键值转化数组下标,从对应的数组下标的位置取数据。
散列表用的就是数组支持按照下标随机访问的时候,时间复杂度是 O(1) 的特性。
哈希函数
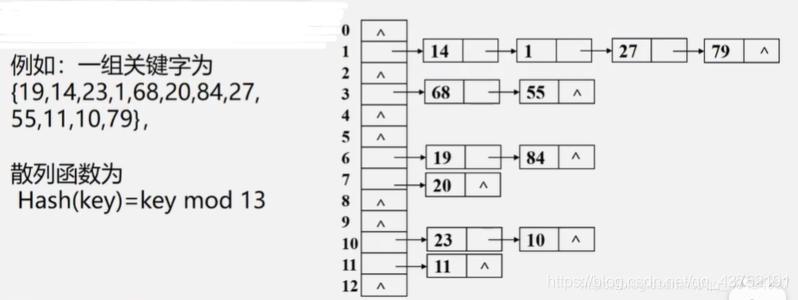
加载因子
无论如何,哈希表中,碰撞无法绝对避免。
当碰撞发生时,就不得不使用开链表法或再散列法存储冲突数据;而这必将影响哈希表的性能。
很容易想到,如果哈希表很大、里面却没存几条数据,那么它出现冲突(碰撞)的几率就会很小;反之,如果哈希表已经接近满了,那么每条新加入的数据都会产生碰撞。
哈希表实际所存数据量和哈希表最大容量之间的比值,叫做哈希表的“加载因子”。
加载因子越小,冲突的概率就越低,但浪费大量空间;加载因子越高,冲突概率越大,但空间浪费就越少。这是一个需要根据工程实践灵活选择的折衷值。很多语言的hash函数库允许你主动调节这个值。一般来说,一个较为平衡的加载因子大约是0.7~0.8左右。这样既不会浪费太多空间,也不至于出现太多冲突。
散列冲突
散列表的查询效率并不能笼统地说成是 O(1)。它跟散列函数、装载因子、散列冲突等都有关系。如果散列函数设计得不好,或者装载因子过高,都可能导致散列冲突发生的概率升高,查询效率下降。
在极端情况下,有些恶意的攻击者,还有可能通过精心构造的数据,使得所有的数据经过散列函数之后,都散列到同一个槽里。如果我们使用的是基于链表的冲突解决方法,那这个时候,散列表就会退化为链表,查询的时间复杂度就从 O(1) 急剧退化为 O(n)。
如何选择冲突解决方法?
开放寻址法:
开放寻址法的核心思想是,如果出现了散列冲突,我们就重新探测一个空闲位置,将其插入。比方说向后线性探测。我们可以将删除的元素,特殊标记为 deleted。当线性探测查找的时候,遇到标记为 deleted 的空间,并不是停下来,而是继续往下探测。
我不喜欢这种方法。但是当数据量比较小、装载因子小的时候,适合采用开放寻址法。这也是 Java 中的ThreadLocalMap使用开放寻址法解决散列冲突的原因。
开链表法:
看图:
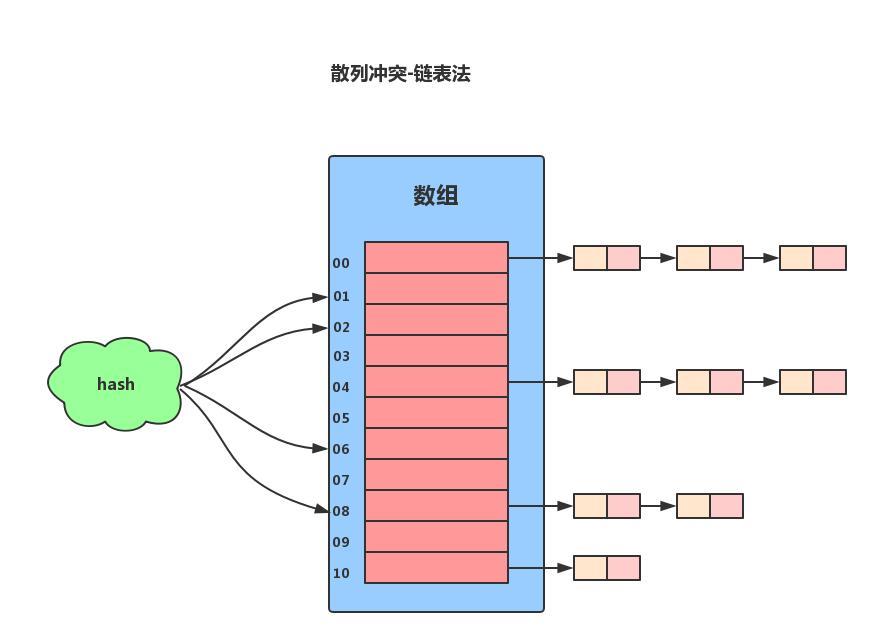
在散列表中,每个“桶(bucket)”或者“槽(slot)”会对应一条链表,所有散列值相同的元素我们都放到相同槽位对应的链表中。
链表法比起开放寻址法,对大装载因子的容忍度更高。开放寻址法只能适用装载因子小于 1 的情况。
本来呢,我是比较喜欢这个方法的,但是看看开头那个问题。
解决方法:
为了对 HashMap 做进一步优化,我们引入了红黑树。而当链表长度太长(默认超过 8)时,链表就转换为红黑树。我们可以利用红黑树快速增删改查的特点,提高 HashMap 的性能。当红黑树结点个数少于 8 个的时候,又会将红黑树转化为链表。因为在数据量较小的情况下,红黑树要维护平衡,比起链表来,性能上的优势并不明显。
总结
何为一个工业级的散列表?工业级的散列表应该具有哪些特性?
支持快速的查询、插入、删除操作;
内存占用合理,不能浪费过多的内存空间;
性能稳定,极端情况下,散列表的性能也不会退化到无法接受的情况。
如何实现这样一个散列表呢?
设计一个合适的散列函数;
定义装载因子阈值,并且设计动态扩容策略;
选择合适的散列冲突解决方法。
关于散列函数的设计,我们要尽可能让散列后的值随机且均匀分布,这样会尽可能地减少散列冲突,即便冲突之后,分配到每个槽内的数据也比较均匀。除此之外,散列函数的设计也不能太复杂,太复杂就会太耗时间,也会影响散列表的性能。
关于散列冲突解决方法的选择,我对比了开放寻址法和链表法两种方法的优劣和适应的场景。大部分情况下,链表法更加普适。而且,我们还可以通过将链表法中的链表改造成其他动态查找数据结构,比如红黑树,来避免散列表时间复杂度退化成 O(n),抵御散列碰撞攻击。但是,对于小规模数据、装载因子不高的散列表,比较适合用开放寻址法。
对于动态散列表来说,不管我们如何设计散列函数,选择什么样的散列冲突解决方法。随着数据的不断增加,散列表总会出现装载因子过高的情况。这个时候,我们就需要启动动态扩容。
以上是关于如何打造一个工业级水平的散列表?的主要内容,如果未能解决你的问题,请参考以下文章