经验贴用最土的手法,最高调的绕过反爬
Posted 看,未来
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了经验贴用最土的手法,最高调的绕过反爬相关的知识,希望对你有一定的参考价值。

文章目录
缘起
哈喽大家好,我是“看,未来”,好久不见。或者说,好久不爬了。
但是今晚,重出江湖,“血雨腥风”不至于,拿了数据我就走。
这不要考试了嘛,想着拿一下平时的选择题来过一遍,加深一下印象。奈何那选择题都是被选过的了,答案的痕迹很明显,又不让复制粘贴。
简单的说呢,目标是这样的:
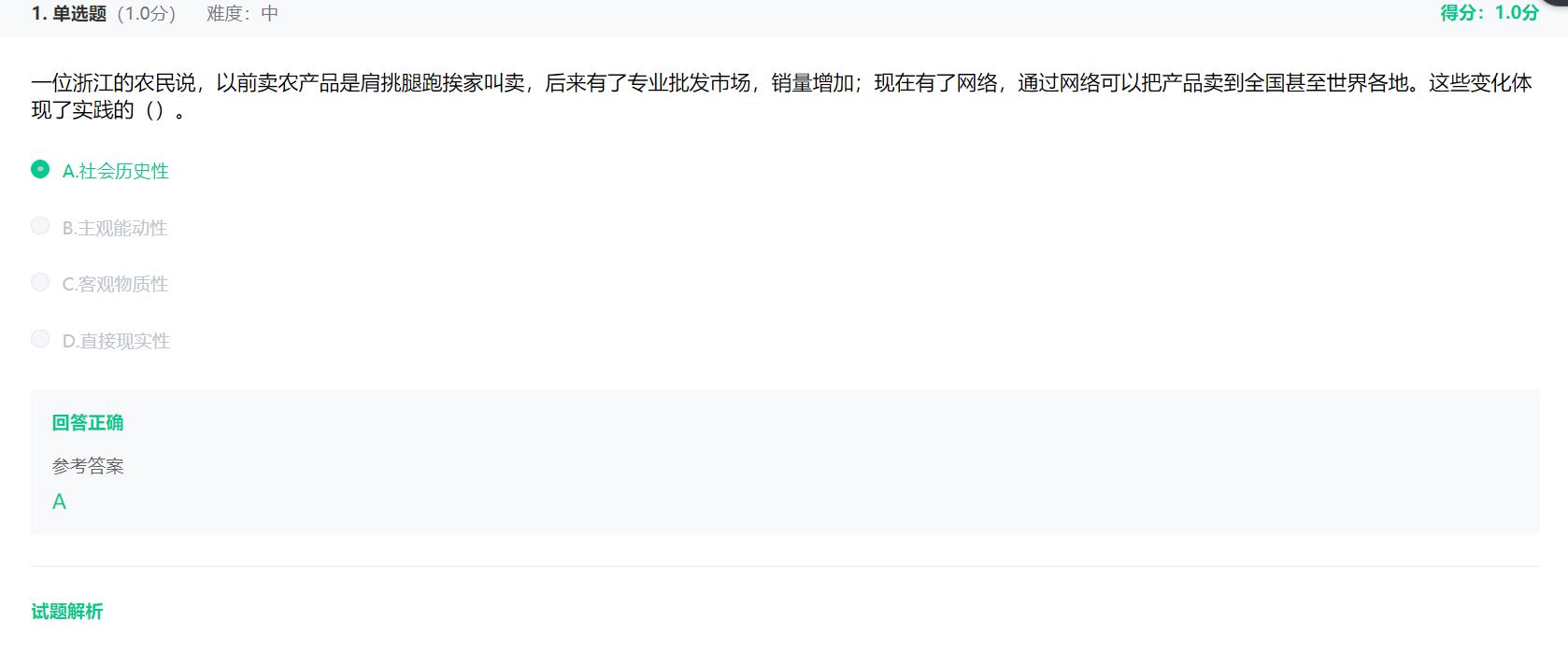
那你说这样的试题做起来有什么意思,难道我要说:“看不到看不到,我看不到答案”,骗谁呢。
而且吧,我这人有个癖好,我要打印出来看呐。
但是吧,题目可以直接复制,选项不让复制,这给我着急的啊。
第一次尝试:咱毕竟是懂技术的人,干的活儿那怎么能没有技术含量?
是吧,咱如果只会截图,提取文字,那和没学过爬虫的小白有什么两样?
我们有一个老师,给我们的题目都是纯英文的,每次做完还要我们从头到尾翻译一遍交上去。
没点技术,真得去把英语学得很六啊,不然百度翻译都麻烦?
于是我果断打开了网页源代码,这时候我可以介绍一下这套题目的规模了:
总共六套试题,平均每套试题有32道题目,这就是近200道题了,每道题有四个选项,个别多选题有五个。
也就是说,我如果用手去复制粘贴,要复制粘贴各1000下。
这事儿我能干吗?我复制粘贴了100下就果断放弃了,这事儿我干不了!!!

第二次尝试:算了,什么技术部技术的,土办法来吧
于是,我开始用截图。。。
是的,我又一次屈服了。。。
但是,就算截图,我也要与众不同,我长截图!!!
一套试卷我直接一张图分四段截下来,一段8题。到打印的时候,我成功的发现,打印出来,那字得用显微镜去看,可惜我暂时买不起。
于是,这条路又失败了。
第三次尝试:失败了?不,只是没调好参而已啦,再干!!!
缓了缓神儿,去考了场试回来,我深思熟路。
字太小,是不是我一次截太多题目了,那我一次截4题?
说干就干,吭哧坑次一小时又过去了,再打印,好家伙,字虽然小,终于可以看了,就是淡了点。
诶,不对,这答案怎么明显比较深色啊。
完了,又白干了。。。

于是我跟身边的好兄弟抱怨了一下:这复制粘贴简直要命。
他说:你可以花一个晚上。
我说:你开什么玩笑?这是一晚上能解决的事情?
他说:我的意思是,牺牲你睡觉的一晚上,弄完发我一份儿,我替你睡觉。
我当时锤爆他的心都有了,还是嘴硬:算了算了,我去爬吧。
第四场:给老子爬!!!
我想,要不我去把网页源码复制下来吧。
好家伙,复制不了。
看都不用看,这种要登录的,不交账号密码去post,根本不可能给你requests到源码的。
当时,post吧,又是加密过的。。。
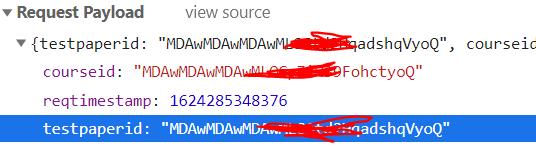
你说怎么po?
我本来对post也不熟。
于是我就想转json包,发现包里的网址也上不去。
很无奈。
重头戏来了,前面讲了那么多废话,重头戏来了
经验一:
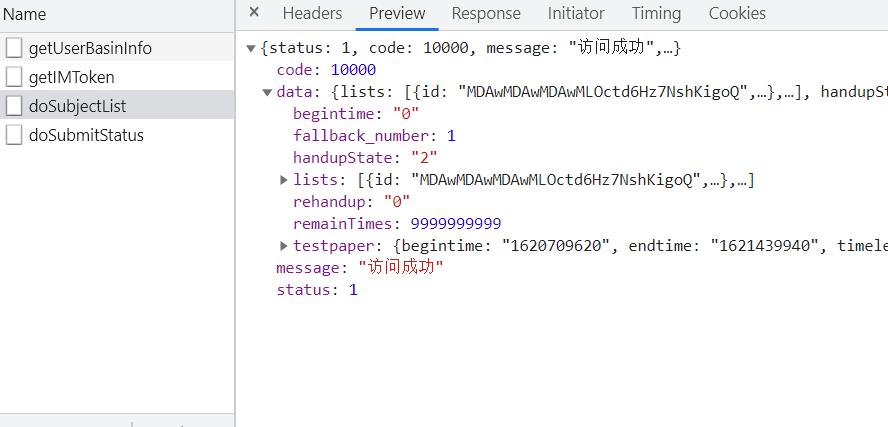
将鼠标放在数据上方,左击,有两个选项,选第一个:“copy value”,可以复制该作用域下数据。我选择的是“data”
就算json的网址无法打开(因为要登录),我们也可以通过这种方式来获取json的内部数据!!!
复制下来之后呢,放在txt文件里面,拖到浏览器打开浏览。
经验二:
这里我全程推荐用谷歌浏览器,Chrome。别问我为什么,以前讲过很多遍了。
经验三:
对于这种有很多双引号和单引号在内的数据,用三引号包起来。
但是,直接包是不行的,直接包,type是srt,但是转不了json。
会报这个错:“json.decoder.JSONDecodeError: Expecting ‘,‘ delimiter: line xx column xx (char xxx)”
问题原因:
将字符串作为字符串文字复制粘贴到Python源代码中,出现错误。
解决办法:
在这种情况下,\\n被解释为单个字符(换行符)。您可以通过使用原始字符串文本来修复它(r’’,使用三引号r’’’…’’'以避免在字符串文本中转义""引号)
经验四:
Python3报错:Non-UTF-8 code starting with '\\xe7’的错误
咱也不知道为啥,就是第一次可以,后面换了个字符串就行了,很迷。仔细比对了两个json字符串,没有什么区别啊。
Python3默认使用utf-8的编码格式,如果出现Non-UTF-8 code starting with '\\xe7’的错误,可以在程序的最顶部加上 # -- coding:utf-8 --即可。
放码过来
不好意思啊,我这个写的比较土一点,短短几行,写不出很长的代码来,见谅见谅。
def get_value(score):
'''
从json类型字符串提取目标标签下数据
:param score: 目标字符串
:return: null
'''
json_js = json.loads(score)
for data in json_js['lists']:
print(data['title'])
print("answer: " + data['answer'])
for option in data['options']:
print(option['id'] + ": " + option['title'])
print('-------------')
不要诧异为什么只是print,没有写入文件。
不要问,问就是懒得写,我直接cv到word里不好吗?
结语
代码不是重点,重点是这个思路。不管方法有多土,只要简单,且最快的实现目标,就行了,没人管我土不土,他们只要我的文档。
也有朋友知道后跟我说:你为什么不用selenium呢?或者直接将网页源码离线保存下来?
首先,selenium不比这个好写,而且,还慢。其实就是不好写。
网页源码离线保存,我试过了,到时候还要正则,再排版,在输入到文档中,更麻烦。
我的好朋友曾给我看过一个笑话,在他看来是笑话,但是却引起了我的深思,我分享给大家吧。
有个不大的公司,遭遇一个黑客勒索,黑客说,一天不交赎金,就按时给公司断电。然后,他做到了。公司老板很着急啊,就开始让技术部门排查,查了很久查不出来,又斥重金去外面请了安全专家来排查,还是没查出来。后来,偶然有一次,被发现黑客花了点钱买通了公司里的一个老大爷,老大爷每天按时去拉电闸。。。
批复是:真正厉害的手法,往往是最原始的。。。
一千个读者有一千个哈姆雷特吧,我还是忘不了那天中午,老师让我打开了淘宝,一块钱买了我一周的努力,这就是方法论,方向论,解决问题的路子要广,要野,思路要打开,怎么稳,怎么简单,怎么来。
以上是关于经验贴用最土的手法,最高调的绕过反爬的主要内容,如果未能解决你的问题,请参考以下文章