使用python包faker生成仿真数据
Posted Data+Science+Insight
tags:
篇首语:本文由小常识网(cha138.com)小编为大家整理,主要介绍了使用python包faker生成仿真数据相关的知识,希望对你有一定的参考价值。
使用python包faker生成仿真数据
在编写程序过程中,我们常常需要用到很多数据来进行测试。如果要是手动制造数据的话,肯定要花费大把精力,这不合理。此时我们应该使用Faker这个Python库,用它来生成各种各样的伪数据。
Faker是一个Python包,它为你生成假数据。无论您需要引导数据库、创建美观的XML文档、填充持久性来对其进行压力测试,还是对从生产服务中获取的数据进行匿名化,Faker都是为您服务的。
Faker is a Python package that generates fake data for you. Whether you need to bootstrap your database, create good-looking XML documents, fill-in your persistence to stress test it, or anonymize data taken from a production service, Faker is for you.
faker的常用语言:
-
简体中文:zh_CN
-
繁体中文:zh_TW
-
美国英文:en_US
-
英国英文:en_GB
-
德文:de_DE
-
日文:ja_JP
-
韩文:ko_KR
-
法文:fr_FR
#安装
pip install faker
# !pip install faker
from faker import Faker
fake = Faker()
fake.name()
#使用faker生成仿真数据# 生成fake name
for _ in range(10):
print(fake.name())# 配置语言模式
fake = Faker("zh_CN")
print(fake.name())
print(fake.job())
print(fake.address())# 字典数据生成
#生成一个测试用的字典数据类型
fake.pydict(){'希望': 'CISxNWbHutsJorpOMFrA', '积分': 'QdburVSlfICUrdIbIrTF', '看到': datetime.datetime(2006, 9, 21, 8, 57, 38), '市场': 'uAYihpPSMDpvgCUfpULB', '完全': 5775, '发表': 'http://www.wen.com/category/', '组织': 'cuiyang@qianguo.org', '建设': datetime.datetime(1980, 5, 18, 2, 47, 11), '今年': 8802, '名称': 'ptfAdRAwfWpQCZOpDRFj'}
# 生成user_agent
#生成一个chrome的user_agent
fake.chrome()Gary Rodriguez Erin Brooks Willie Perez Chad Johnson Joseph Johnson Kim Cooper Kathy Valdez Daniel Evans Christopher Ortega James Edwards DDS
# 生成虚拟IP地址
#生成虚假的IP地址
from faker import Faker
from faker.providers import internet
fake = Faker()
fake.add_provider(internet)
print(fake.ipv4_private())# 配置多种语言格式
from faker import Faker
fake = Faker(['zh_CN', 'en_US', ''])
for _ in range(10):
print(fake.name())Jonathan Lopez Laura Diaz 何晶 张鑫 杨桂英 李利 Charles Murphy Alexis Frazier Matthew Roy 王丹丹
#
#生成一个人相关的详细信息,以字典的形式进行组织
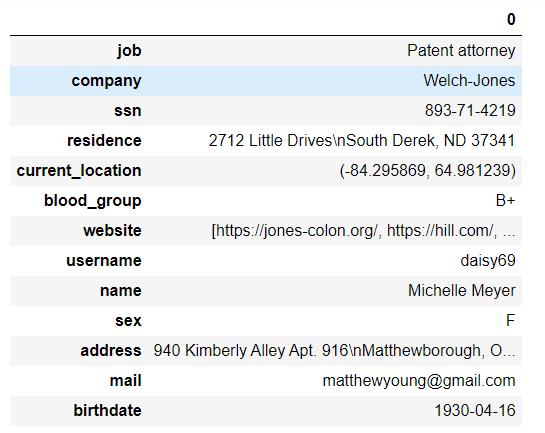
fake.profile()
# 生成字典并使用pandas读取
pd.DataFrame.from_dict(fake.profile(),orient = 'index')
# 获取dict的键
columns = list(fake.profile().keys())
columns
# pandas读取dict数据并进行转置
pd.DataFrame.from_dict(fake.profile(),orient = 'index').T

# 生成多条仿真数据并用pandas dataframe进行读取
#通过for循环把faker生成的数据组织起来存放在pandas dataframe中
# 生成list of dict
people_list = []
for i in range(10):
people_list.append(fake.profile())
df = pd.DataFrame(people_list)
df.head(1)
最后,一定要举一反三啊
通过在pypi仓库中输入faker我们发现不光有faker这个包,还有许多其他的包也可以生成仿真数据,例如可以生成elasticsearch的仿真数据,可以生成SQL数据库的仿真数据等。
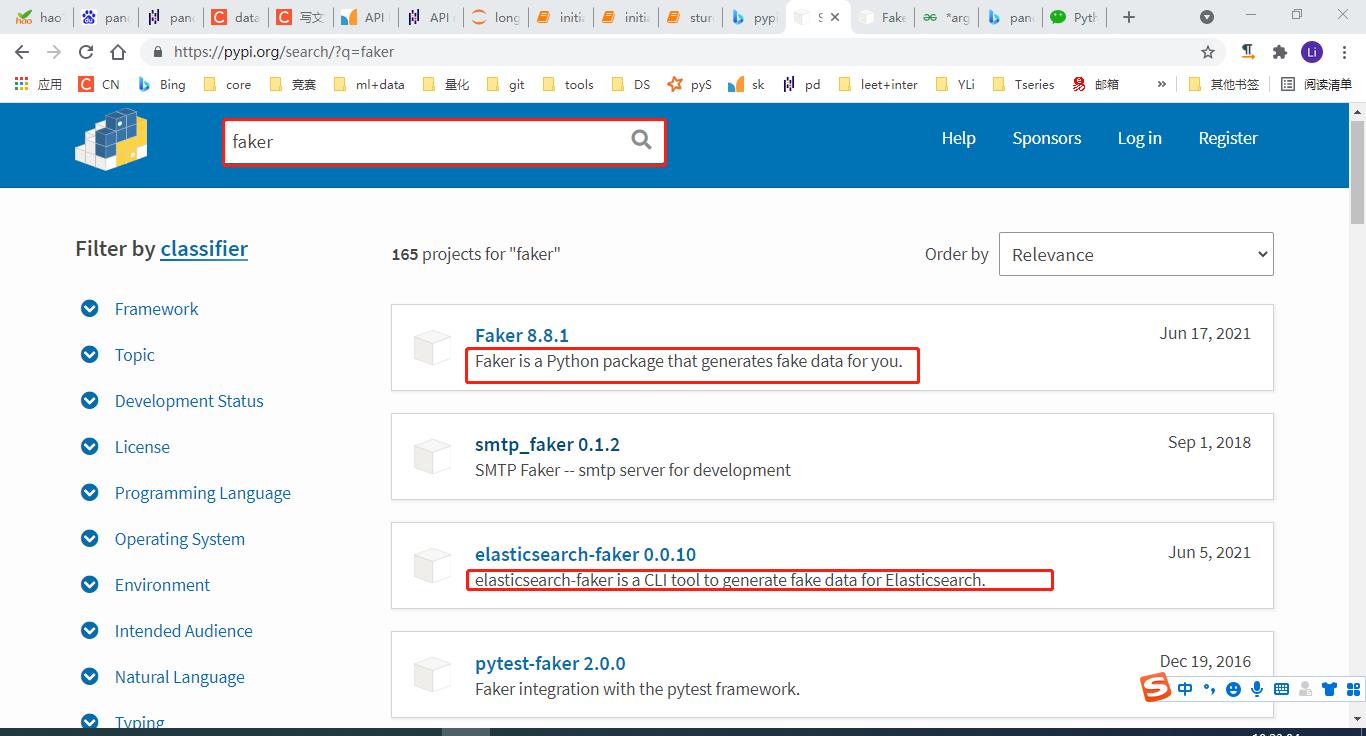
参考:pypi
参考:Python造假数据,用这个库
参考:faker
参考: Python库——Faker
以上是关于使用python包faker生成仿真数据的主要内容,如果未能解决你的问题,请参考以下文章